大数据技术在稿件采用统计系统的应用研究
2015-03-15孙振中
文|孙振中
1 引言
伴随着互联网的发展,各大企业产生的相关数据爆炸式的增长,为了更深入的挖掘数据价值,大数据技术应运而生。作为国家耳目喉舌的新华通讯社也同样在经历一场数据风暴,特别是新华社正处于战略转型的关键时期,面对得用户正在发生转变,如何在“数据为王”的时代紧紧抓住数据的关键节点,向数据要价值,以数据为导向,更好的服务于终端用户,进一步拓宽和占领市场、更好的传播中国声音,成了我们迫切需要关注和解决的问题。而作为向新华社编辑记者提供落地数据参考的稿件采用统计系统同样面临改造和升级,为了更好的为战略转型、为国传建设提供更有价值的数据,亟需借助先进的技术理念和框架,特别是大数据框架进行改造,为系统地长远发展奠定基础。
2 面临的挑战
随着战略转型,用户开始从媒体为主向直接面对终端受众拓展,同时,为了更好的体现新华社的影响力,亟需拓宽网媒的统计范围,并进一步把新兴媒体纳入统计范围,为了实现这些目标,需对系统做彻底的升级。
1)改变统计方式
现在主要以手工统计为主,这样大大制约了统计范围的扩展,亟需能够通过自动解版、自动抓取、自动比对等一系列自动化流程实现稿件统计的自动化,特别是框架需要具备良好的扩展能力。
2)解决大数据量、多类型数据造成的存储问题
现在数据存储主要依赖关系型数据库,现在系统有上亿条的采用落地数据,如何能够提高并发吞吐量,打破硬件I/O瓶颈,是我们需解决的问题。
3)解决性能问题
现在系统遇到的性能问题尤其突出,主要体现在以下两个方面:
未来的方案可尝试分表存储或者分布式存储,并且,事务操作和分析型操作数据对象分开存放,这样会减少相互间的影响,大幅提升操作效率。
分析型应用查询效率问题:特殊情况下,领导需要统计数据较强的实时性,这对系统计算能力特别是数据库方面的查询性能提出了更高的要求,并行计算和分布式计算是可选方案。
为了更好的提升效率、扩展统计范围,把相互影响力将到最低,亟需对采集、后期处理分布式处理。
3 关键技术
为了解决系统所面临的问题,所需的技术框架需满足以下要求:
1)数据能够分布式存储,能够支撑海量数据,存储框架应该具有良好的扩展性和存储数据类型的多样性。
2)能够同时提供事务操作和查询分析型操作,支持并发量的扩展。解决系统主要面临的性能问题
3)能够复用老设备,提高资产利用率。现在的老设备型号不一,购买的年份有早有晚,需能够重复利用。
4)能够兼容java框架,易于实施和后期维护。
综合以上要求,现在主流的大数据框架hadoop是我们很好的选择。
3.1 大数据技术
Hadoop作为当前炙手可热的大数据处理平台,是Apache的开源项目,它实现了分布式文件系统和分布式数据库系统。它的优点是可以使用廉价设备甚至pc机建成计数机集群组为我们提供高效得云存储和管理。重要的是,现在各大IT巨头都已经相继推出了支持Hadoop的产品,包括计算平台和数据库产品,并且都有整体解决方案,这也为我们系统的部署和实施提供借鉴和保障。综合评估现有的大数据技术,选择以下几个技术:
1)HDFS(Hadoop Distributed FileSystem):是为Hadoop项目开发的分布式文件系统,支持流读取,是分布式计算的存储基础,它具有高容错性,对硬件设备要求不高,不用磁盘寻址,并行的读写提供了数据的高吞吐率。
2)MapReduce:是一种专门为大数据而设计的并行计算框架,其突出优势是具有很好的扩展性和可用性,特别适用于海量的结构化、半结构化及非结构化数据的混合处理。
3)HBase:是一个分布式的、面向列的开源数据库。用于网媒和新媒体抓取稿件的存储和进一步的处理。
4)Apache Sqoop:该工具用于项目中关系型数据库跟Hadoop之间的数据交换。
5)Hive:基于Hadoop的分布式数据仓库,优势在数据的分析和展示。可用于统计数据的抽取和最终的分析展现。
3.2 数据采集
稿件统计系统的源头,需要采集各类数据,从中过滤比对出是否采用新华社稿件的信息:
1)部分纸质媒体落地数据的人工采集:该部分数据还必须采用人工的方式进行,除非能够收集到该纸媒的电子版。
2)纸媒电子版:该部分主要依赖解版技术把电子版解析成为结构化的稿件信息。
3)网媒和纸媒网站:主要采集新闻信息网站的新闻信息稿件,从现在采集的200家扩展到2000家左右的规模。该部分主要依赖爬虫工具,其中稿件的属性信息需要精确抓取。它支持稿件正文、图片、音频、视频等文件或附件的采集,附件与正文可以自动关联、抓取到的稿件以文件形式存放到Hbase数据库中。
4)社交媒体和新媒体信息采集:主要针对微薄、微信、新闻客户端,该部分主要通过网站公开的API请求采集。从采集的数据中比对新华社稿件被转发、被评论、被点赞的次数。
5)各类交易的日志数据采集:如Hadoop的Chukwa等,该采集工具采用分布式架构,能满足每秒数百MB的日志数据采集和传输需求。从日志中获取终端受众点击、下载新华社稿件的真实情况。
外在认知负荷(Extraneous Cognitive Load)主要是由于不恰当的教学设计所致,可以通过优化学习材料的呈现形式来控制外在认知负荷.外在认知负荷是由与学习过程无关的活动引起的,不是学习者建构图式所必须的,因而又称无效认知负荷(Ineffective cognitive load).认知负荷理论者认为,外部认知负荷主要由教学设计引起,如果学习材料的设计和呈现方式不当,就容易给学生带来较高的外在负荷,干扰其学习.
3.3 数据库设计
数据库设计的原则是把不同的类型的数据分别使用不同的数据库存放,传统数据库跟Hadoop数据库结合,配以数据仓库,搭建一个真正的数据库平台,为系统提供完整的数据服务,充分发挥各种数据库的优势。具体如下:
1)使用oracle数据库用来存储结构化数据,最终的采用数据和稿件数据,数据分表存储,用于支撑事务性操作。充分发挥数据一致性好的优势。
2)使用Hive 作为数据仓库,用于数据维度的抽取和分析型应用。
3)HBase用于海量存储,其中大量的抓取数据,直接入Hbase数据库,其它的文件数据存放到HDFS文件系统中,分布式存放,易于扩展,并具有高读取速率。
4)使用Sqoop工具从Hbase数据库向关系型数据库作数据转移。
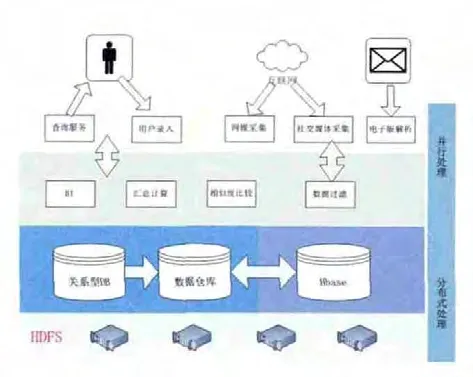
3.4 系统整体架构
1)存储层:以HDFS分布式存储为基础
2)持久层:在HDFS基础上上搭建HBase数据库,以及用于事务操作的关系型数据库和用于维度抽取形成的数据仓库。
3)应用层:提供数据的清洗和过滤、分布式处理、各种缓存计算以及采用查询模块。
4)数据收集和展现层:用于各种数据的采集和为终端用户提供查询服务。
整体结构图如下图;
系统的整体设计主要从理论层面展开,首先从Hadoop的技术框架出发,结合传统技术和大数据框架的优点,解决了稿件采用统计系统中遇到的疑难问题,同时兼顾了事务操作要求的实时性强,大数据采集和处理计算能力大的特点,提出最终的解决方案。
