带有退火和杂交变异思想的改进粒子群算法
2015-02-27黄炜霖刘建军吕照明
黄炜霖 ,刘建军 ,张 明 ,吕照明 ,伍 建
1.中国石油大学(北京)理学院,北京 102249
2.中国石油大学(北京)油气资源与探测国家重点实验室,北京 102249
3.中国石油大学(北京)CNPC物探重点实验室,北京 102249
1 引言
粒子群优化算法(PSO)是由Kennedy和Eberhart在1995年提出的一种新型进化计算方法[1-2]。PSO算法原理简单且易实现,迭代运算的参数少,具有较快的收敛速度。近年来的研究表明,该算法在许多优化问题中表现优秀,已被成功应用到参数辨识、模式识别、网络优化等许多领域[3-6]。
但是,基本PSO算法在求解复杂函数优化问题时,求解过程中易出现“早熟现象”,进而无法找到全局最优解,同时搜索的精度不高。针对算法的这些不足,很多学者将其他优化算法思想融入PSO算法中,Lovbjerg等人提出了带交叉算子的PSO算法[7];Liu等人将混沌算法的思想引入PSO算法中[8];Holden等人混合PSO算法和蚁群算法[9]等等[10-16]。为了解决PSO应用中出现的早熟现象,本文首先应用信息熵算法产生分布更为均匀的初始群体,然后基于模拟退火算法中依概率接受劣解,和遗传算法中杂交变异产生新解的思想,提出了粒子群算法的一种新改进算法。
2 基本粒子群算法
PSO优化算法将待优化的参数组合成群体,再利用个体(粒子)的适应度使其向好的区域移动,每个粒子代表问题的一个可能解,每个粒子具有位置和速度两个特征[1-2]。在D维搜索空间中,第i个粒子的位置可以表示成Xi,其速度表示成Vi,粒子位置坐标对应的目标函数值即可作为该粒子的适应度,算法依据适应度来衡量粒子的优劣。算法首先初始化一群随机粒子,然后通过迭代找到最优解。在每次迭代中,粒子的更新是通过跟踪两个“极值”:一个是粒子本身经历过的最优解,即个体极值pbesti;另一个是整个粒子群经历过的最优解,即全局极值gbest,最后输出的gbest就是算法得到的最优解。第i个粒子从第k代进化到第k+1代时,根据下面两个公式更新速度与位置:
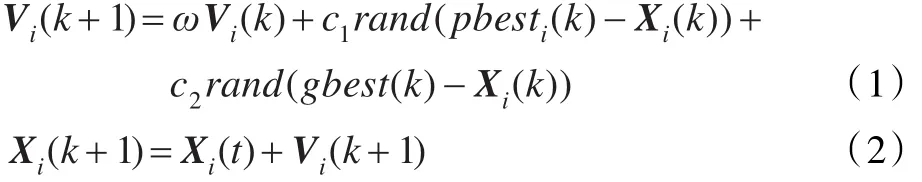
其中,ω为惯性权重,其作用是维护全局和局部搜索能力的平衡;c1和c2为加速因子,作用是控制粒子向pbesti和gbest移动的速度大小;rand为[0,1]范围内的随机数。
粒子群优化算法具有结构简单,运行速度快的优点。在算法搜索过程中,某粒子发现一个当前最优位置,其他粒子便会迅速向其靠拢。但是,如果该最优位置为一局部最优点时,算法很容易陷入局部最优,粒子群就无法在解空间内重新搜索,出现了所谓的早熟收敛现象。
3 基于信息熵控制初始群体的生成
若初始群体没有较均匀的分布在解空间,那么群体的多样性将降低,导致算法全局搜索能力减弱。对此应用信息熵来提高初始群体的多样性[17-18]。
在信息论中,熵通常也称做信息熵或Shannon熵,它主要采用数值形式表达随机变量取值的不确定性程度,或一个系统的混乱性、遍历性、随机性[19-21]。设初始群体由N个D维个体组成,并用X=(X1,X2,…,XD)来表示(每个分量为N维列向量),则第j维分量的信息熵Hj表示为:
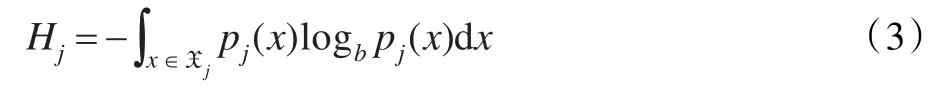
其中,pj(x)为随机变量Xj的概率密度函数,Xj为第j维分量的取值范围。
整个系统的信息熵H表示为:

其中,Qj为信息熵确定的权重。
对于概率密度函数,采取高斯核函数方法[22-23]来近似估计:
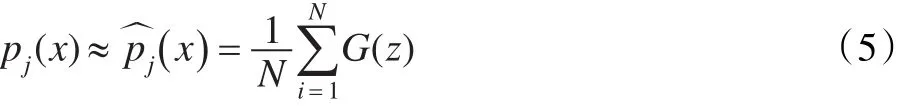
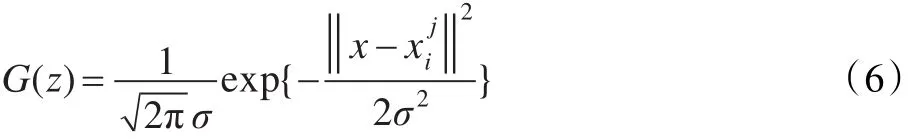
其中,为第j维分量的第i个值,σ为核函数的宽度。
由式(4)可知,熵值H越大,群体多样性越好,即个体间差异越大,相反熵值H越小,群体多样性越低,即个体间差异越小,当熵值H为零时,个体间无差异。因此,可以用熵值H来控制群体的生成,生成多样性较好、遍历性较高的初始群体,如图1所示。
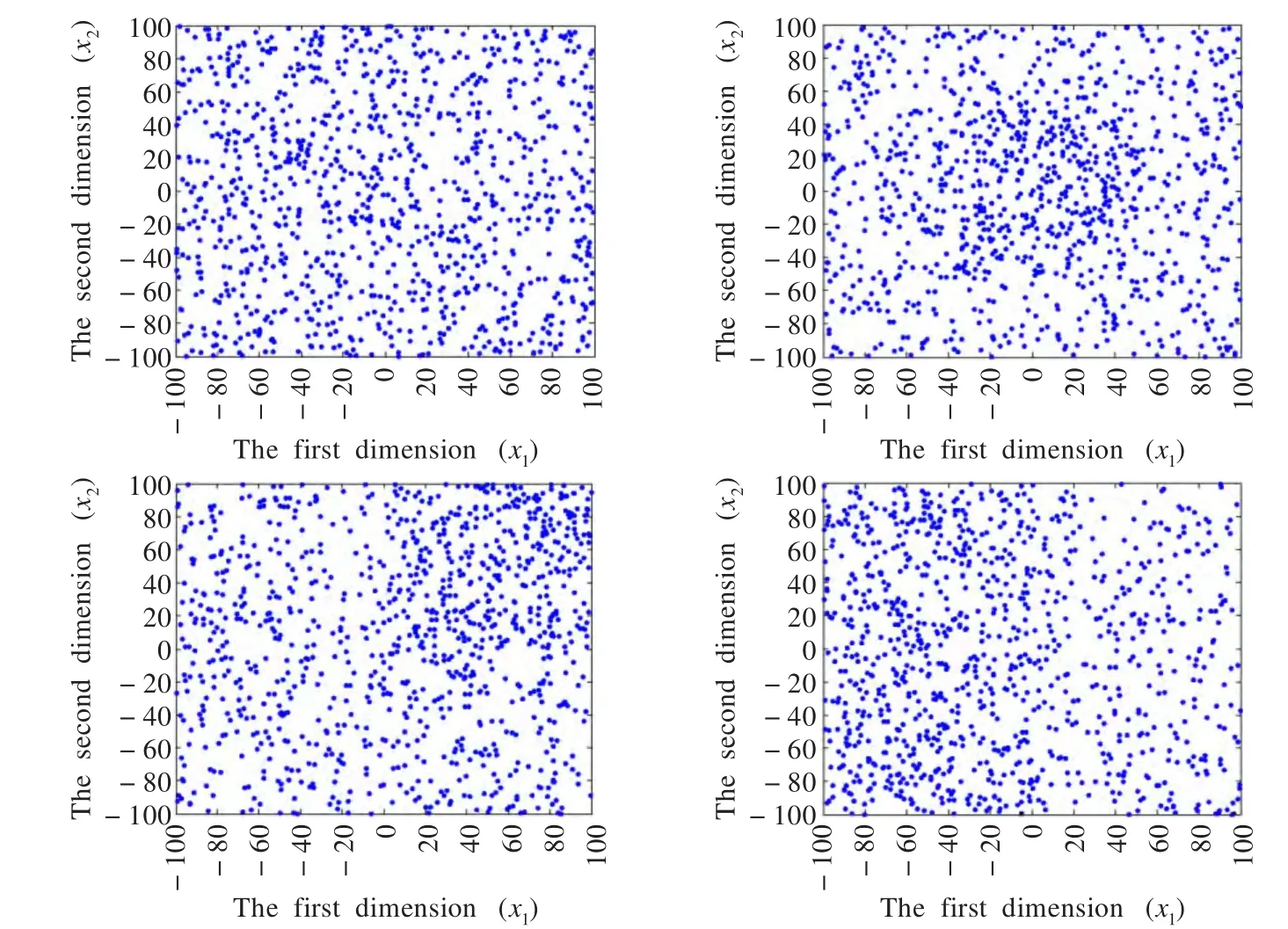
图1 不同熵值H对应的初始种群分布
由于混沌序列具有混沌运动的遍历性、随机性和规律性等特点,能在一定范围内按自身的规律不重复地遍历所有状态,所以很多学者用混沌映射来生成初始群体[24-25]。混沌模型有很多,最常用的是logistic映射,即:

其中,n=0,1,…,0≤y(n)≤1,u是控制参量,当u=4时,上述系统处于完全混沌状态。
由于logistic映射生成的粒子分布在区间两头的概率远大于中间,而中间分布较均匀,所以这里只取落在区间[0.1,0.9]里面粒子,舍弃其他粒子。
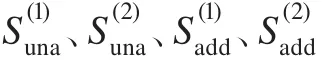
4 带有模拟退火和杂交变异思想的粒子群算法4.1 杂交变异思想
遗传算法中杂交算子能使个体间交换信息,而变异算子能使某些个体发生基因突变,使个体具有更大的遍历性[26-27]。本文借鉴这个思想,通过杂交和变异来产生多样性更好的后代。
图2 二维粒子分布和每维上的分布情况比较(100个)
4.1.1 杂交
在PSO算法迭代中,选取一定数目的粒子放入杂交池中,池中的粒子随机进行杂交,然后产生同样数目的子代粒子(child),再用子代粒子替换父代粒子(parent)。子代粒子由父代粒子算术交叉得到:
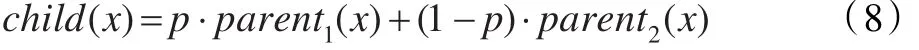
其中,p是0到1之间的随机数。
4.1.2 变异
在PSO算法迭代中,以一小概率μ选取粒子,并随机选取其某一维或者几维,将它的值改变,改变的值为搜索范围内的随机数。这个概率μ可以是固定的,也可以是以某种方式下降的。
杂交和变异的操作,目的是增加群体的多样性,帮助算法跳出局部最优,防止算法“早熟”。
4.2 退火思想
借鉴模拟退火算法搜索过程中具有概率突跳的能力,且不但接受好解,还以一定的概率接受劣解,同时这种概率受到温度参数的控制[27-28]。本文对其进行修改,将这种思想融合到粒子群算法中。在4.1.1小节所述的杂交操作中,是以这样的步骤选取粒子放入杂交池中:
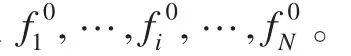
步骤2计算初始温度:

其中fmax、fmin分别表示最大的适应值和最小的适应值。
步骤3计算杂交比例:

其中λ为取值在0到1之间的比例系数,作用是控制比例大小,k为当前迭代步数,M为最大迭代步数。
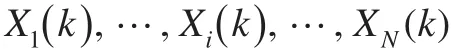
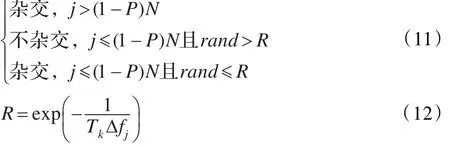
其中rand表示0到1之间的一个随机数,Δfj表示第j个粒子的适应值与全局最优点适应值之差。
步骤5降温:

其中μ为降温系数,作用是控制温度下降的快慢。
上述过程可以这样理解:当j>(1-P)N,就进行杂交,相当于模拟退火算法中接受收好解的过程,这里是接受劣解进入杂交池;当j≤(1-P)N,就依概率R来判断是否杂交,相当于模拟退火算法中依概率接受劣解,这里是依概率接受好解进入杂交池,且粒子越好,进入杂交池的可能性就越小。
上述操作的目的有二:一是加速算法的收敛速度,越到迭代后期,杂交比例P和接受好解进入杂交池的概率R越小;二是使算法具有突跳能力,能有效的跳出局部极小点。
4.3 算法步骤
步骤1给定一个临界熵值H0,随机产生初始群体并按式(3)、(4)、(5)、(6)计算他的熵值H,若H>H0则随机初始化该初始群体的速度,转步骤2;否则重新随机产生初始群体直到满足H>H0为止。
步骤2评价每个粒子的适应度,将当前各粒子的位置和适应值存储在各粒子的pbesti中,将所有pbesti中适应值最优个体的位置和适应值存储在gbest中。
步骤3按式(9)计算初始温度T0。
步骤4按式(1),(2)更新每个粒子的速度和位置。
步骤5对粒子群体进行变异操作。
步骤6计算每个粒子的目标函数值,按式(10)、(11)、(12)计算出放入杂交池的粒子,以及保留的粒子。
步骤7将步骤6中杂交池中的粒子按式(8)随机进行杂交,然后产生同样数目的子代粒子,再用子代粒子替换父代粒子。
步骤8更新每个粒子的pbesti以及群体的gbest。
步骤9若满足停止条件(精度或者迭代次数等),搜索停止,输出结果;否则转步骤10。
步骤10按式(12)进行降温操作,转步骤4。
5 仿真实验
下面通过4个典型函数优化问题(求解最小值)来测试本文提出的算法的性能。
测试函数1,Sphere函数:

其中-100<xi<100,最优状态和最优值为:
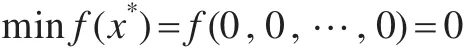
测试函数2,Rastrigin函数:
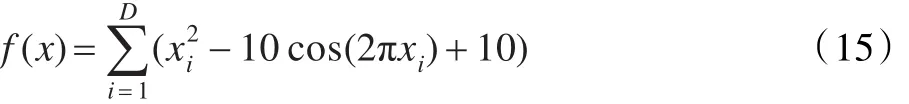
其中-5.12<xi<5.12,最优状态和最优值为:
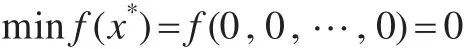
测试函数3,Ackley函数:
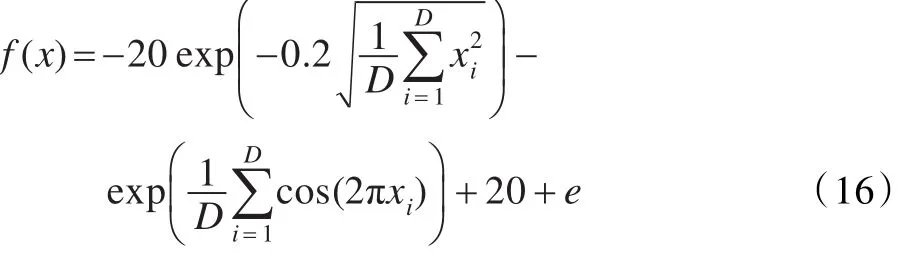
其中-32<xi<32,最优状态和最优值为:
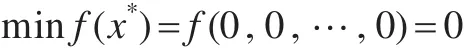
测试函数4,Griewank函数:
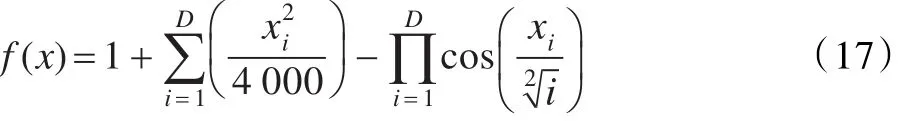
其中-600<xi<600,最优状态和最优值为:
对每个测试函数,分别采用标准粒子群算法(PSO)、遗传粒子群算法(GAPSO)[29-30]和本文所提出的带有模拟退火和杂交变异思想的粒子群算法(SAHMPSO)进行测试。
为了保证实验的客观性,对于基本参数的设定,3种算法均为:种群大小N为40;函数维数D分别为10、20、30;加速因子c1=c2=1.4;惯性权重ω=0.65;最大迭代次数为5 000。对于每个测试函数,每种算法运行100遍,其中Avg表示运行100次的结果的平均值,Var表示运行100次的结果的方差,Best表示运行100次的结果的最小值。运算结果如表1所示。
为了分析算法的收敛性能,将3种算法在4个测试函数上的最优值best记录下来,以横坐标为迭代次数,纵坐标为函数的对数值,作出图形如图3所示(仅展示10维情况)。
Sphere函数为连续的单峰函数,自变量之间互相独立,Rastrigin、Ackley、Griewank这3个函数为复杂的非线性多峰函数,存在大量局部极小值。从表1可以看到,本文提出的算法,无论是在搜索精度还是在稳定性都明显的高于其他两种算法。
Sphere函数常用于测试算法的收敛速度,Rastrigin函数常用于测试算法的全局搜索性能。由图3(a)和(b)看到,在迭代早期,3种算法的收敛速度基本相当,而在迭代的中后期,由于PSO算法的“早熟”使得算法停滞不前,陷入了局部极小,而GASPSO算法虽然找到了比PSO算法更好的解,但很快也陷入了局部极小。而SAHMPSO算法由于杂交,变异操作,在保持收敛速度的同时,大大地加强了抗“早熟”的能力。
Ackley函数常用于测试算法跳出局部极值的能力。由图3(c)可以看到,PSO算法和GASPSO算法很快就陷入局部极值难以跳出,而SAHMPSO算法能一直保持着一个较快的速度下降,即使陷入局部极值,在若干次迭代后仍可跳出。
Griewank函数常用于测试算法对全局与局部搜索能力的平衡性能。由于本文算法融入了退火的思想,使得算法在兼顾局部搜索能力的同时,在迭代后期加快全局收敛速度,由图3(d)可以看到,PSO算法同样是在迭代次数不到100的时候就已经停滞不前了,而SAHMPSO算法在迭代前期保持了种群较大的多样性,强化了算法的全局搜索能力,在迭代后期降低种群的多样性,加快收敛,强化了算法的快速下降搜索能力。而信息熵控制的方法产生了均匀性良好的初始群体,加强了群体的多样性,是算法的较高收敛性能的基础。
6 结论
本文提出的改进算法中,利用信息熵控制生成初始群体,保证了初始群体的多样性,为后续进化提供了基础。改进算法中融入了模拟退火算法中的退火方法和遗传算法中的杂交、变异算子,使得算法不仅保持了PSO算法前期函数值的快速下降性,还克服了原算法的“早熟”缺点,从而使算法的搜索性能得到很大的提高。通过数值实验可以发现,本文的改进算法在抗“早熟”、搜索精度和稳定性方面均优于PSO及GAPSO,本文算法可进一步应用到实际问题中。
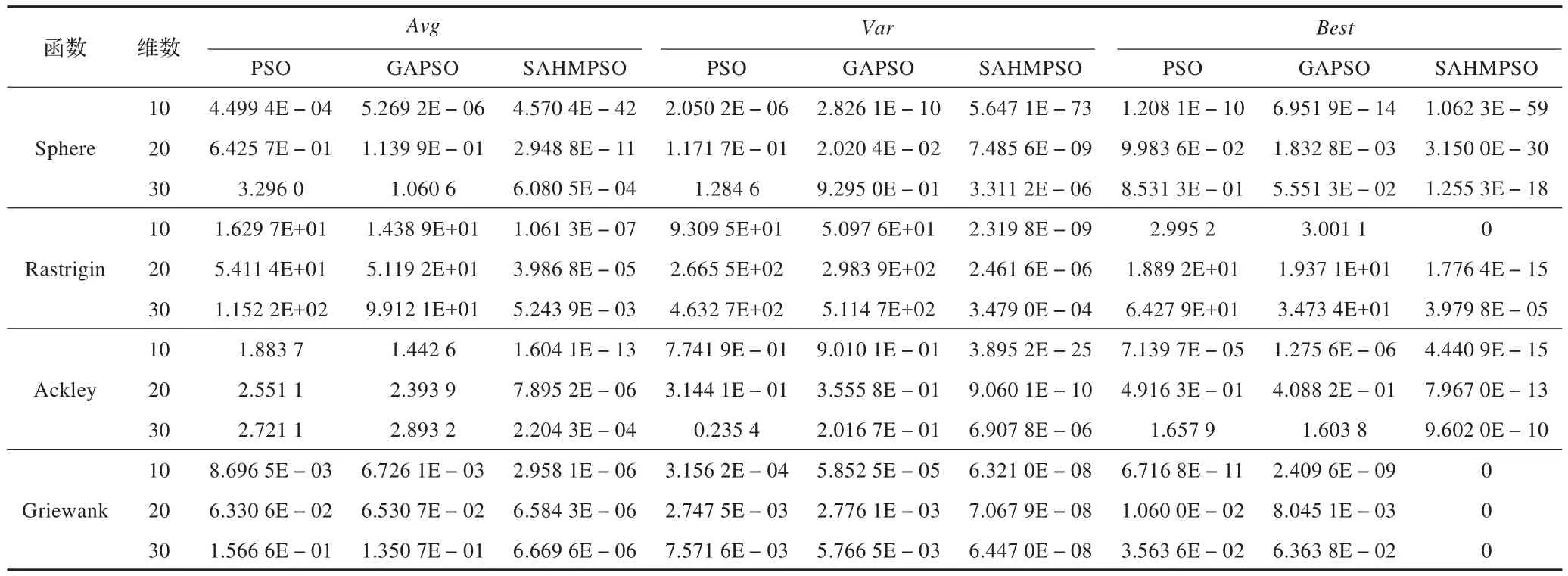
表1 3种算法针对4个函数在10、20和30维下的实验结果(运行100次)
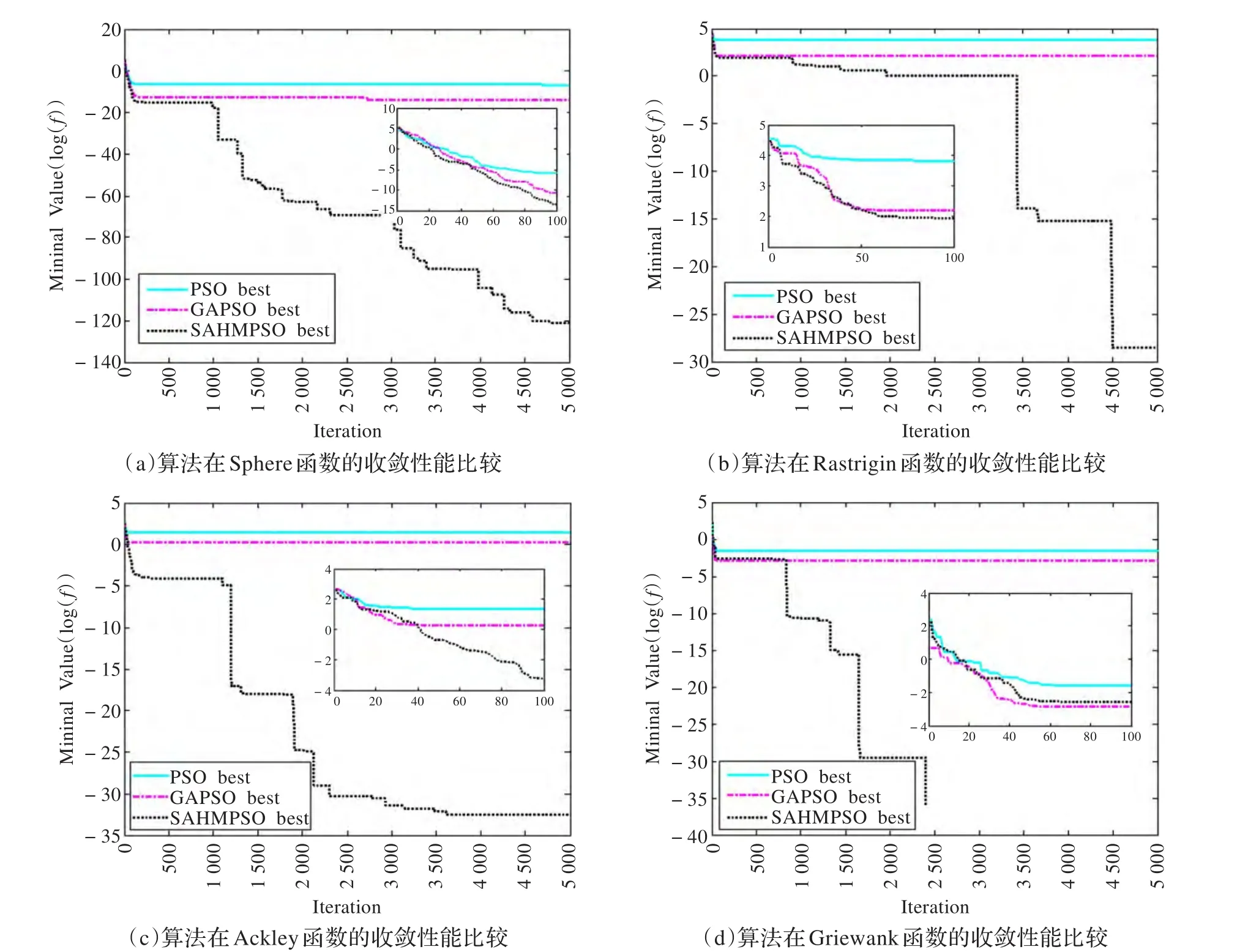
图3 3种算法优化4个函数的收敛性能比较(小图为前100步的迭代情况放大)
[1]Kennedy J,Eberhart R C.Particle swarm optimization[C]//Proc of the 1st IEEE International Conference on Neural Networks,Perth,Australia,1995:1942-1948.
[2]Eberhart R C,Kennedy J.A new optimizer using particle swarm theory[C]//Proc of 6th Int Symp Micro Machine and Human Science,Nagoya,Japan,1995:39-43.
[3]戴运桃.粒子群优化算法研究及其在船舶运动参数辨识中的应用[D].哈尔滨:哈尔滨工程大学,2010.
[4]Yoshida H,Kawata K,Fukuyama Y,et al.A particle swarm optimization for reactive power and voltage control considering voltage security assessment[J].IEEE Transactions on Power Systems,2001,15(4):1232-1239.
[5]Sousa T,Silva A,Neves A.Particle swarm based data mining algorithms for classification tasks[J].Parallel Computing,2004,30(5/6):767-783.
[6]He Z,Wei C,Yang L,et al.Extracting rules from fuzzy neural network by particle swarm optimization[C]//Proceedings of IEEE Congress on Evolutionary Computation,Anchorage,Alaska,USA,1998.
[7]Lovbjerg M,Rasmussen T K,Krink T.Hybrid particle swarm optimizer with breeding and subpopulation[C]//Proceedings of Genetic and Evolutionary Computation Conf.San Francisco:Morgan Kaufmann Publishers Inc,2001:469-476.
[8]Liu Bo,Wang Ling,Jin Yihui,et a1.Improved particle swann optimization combined with chaos[J].Chaos,Solitons and Fractals,2005,25(5):1261-1271.
[9]Holden N,Freitas A A.Hybrid particle swarm,ant colony algorithm for the classification of hierarchical biological data[C]//Proc of the IEEE Swarm Intelligence Symposium,Delhi,India,2005:100-107.
[10]胥小波,郑康锋,李丹,等.新的混沌粒子群优化算法[J].通信学报,2012(1):24-30.
[11]李季,孙秀霞,李士波,等.基于遗传交叉因子的改进粒子群优化算法[J].计算机工程,2008(2):181-183.
[12]杨俊杰,周建中,喻菁,等.基于混沌搜索的粒子群优化算法[J].计算机工程与应用,2005,41(16):69-71.
[13]Kiel R T,Thiemo K.Improved hidden Markov model training for multiples equence alignment hybrid[J].Bio-systems,2003,72(1/2):5-17.
[14]Ji M J,Tang H W.Application of chaos in simulated annealing[J].Chaos,Solitons and Fractals,2004,21:933-941.
[15]张顶学.遗传算法与粒子群算法的改进及应用[D].武汉:华中科技大学,2007.
[16]潘昊,侯清兰.基于粒子群优化算法的BP网络学习研究[J].计算机工程与应用,2006,42(16):41-43.
[17]Chun J,Kim M.Shape optimization of electromagnetic devices using immune algorithm[J].IEEE Trans on Magnetics,1997,33(3):1876-1879.
[18]袁晓辉,袁艳斌,王乘,等.一种新型的自适应混沌遗传算法[J].电子学报,2006(4):708-712.
[19]Cover T M,Thomas J A.Elements of information theory[M].New York:Wiley,1991.
[20]Cover T M,Thomas J A.信息论基础[M].阮吉寿,张华,译.北京:机械工业出版社,2005:9-28.
[21]张妍,杨志峰,何孟常,等.基于信息熵的城市生态系统演化分析[J].环境科学学报,2005(8):1127-1134.
[22]Parzen E.On estimation of a probability density funcion and mode[J].Annals of Math Statistics,1962,33:1065-1076.
[23]Beirlant J,Dudewicz E J,Gyorfi L,et al.Nonparametric entropy estimation:An overview[J].International Journal of the Mathematical Statistics Sciences,1997,6:17-39.
[24]Tavazoei M S,Haeri M.An optimization algorithm based on chaotic behaviorand fractalnature[J].Journalof Computational and Applied Mathematics,2007,206(2):1070-1081.
[25]周燕,刘培玉,赵静,等.基于自适应惯性权重的混沌粒子群算法[J].山东大学学报:理学版,2012(3):27-32.
[26]Holland J H.Adaptation in natural and artificial systems[M].Cambridge,Massachusetts:MIT Press,1992:87-95.
[27]邢文训,谢金星.现代优化计算方法[M].北京:清华大学出版社,1999:90-183.
[28]Metropolis N,Rosenbluth A.Rosenbluth metal,equation of state calculations by fast computing machines[J].Journal of Chemical Physics,1953,56(21):1087-1092.
[29]龚纯,王正林.精通MATLAB最优化计算[M].2版.北京:电子工业出版社,2012:273-311.
[30]彭晓波,桂卫华,黄志武,等.GAPSO:一种高效的遗传粒子混合算法及其应用[J].系统仿真学报,2008,20(18):5025-5027.
