关于Logistic增长模型参数估计方法的再探讨
2015-02-18杨益民付必谦
杨益民,付必谦
(1.北京工商大学 理学院,北京,100084;2.首都师范大学 生命科学学院,北京100084)
0 引言

是描述有限环境条件下生物种群S-型增长的最基本和最常用的模型,在种群数量动态研究中占有十分重要的地位。
在利用式(1)定量研究种群动态时,必须依据实验观测数据估计式中的K、r和a。较早提出且目前仍然十分常用的方法是将式(1)移项取对数后,转化为线性方程

先根据原始数据和经验预先给定K,然后再利用一元线性回归估计r和a[1~3]。后来一些学者认为线性化方法主观色彩较浓或遗漏“最优”参数估计值的可能性较大,提出采用一些非线性最优化方法如麦夸法和单纯形加速法等[4,5],也有作者对利用数值方法拟合进行了一些探讨[6]。但是,无论是利用线性化还是非线性化方法(包括直接调用统计软件包),在Logistic模型参数估计中均存在一些共同的需要特别重视的问题。此外,对现有线性化方法进行改进,探讨一种既简便易行又客观准确的线性化方法,对于缺乏较深数学基础的实际工作者仍不失一种较好的选择。
本文对目前Logistic模型参数估计中的问题进行了分析,并对线性化方法进行了再探讨,提出了一种新的线性化方法——“最佳”观测点数定向搜索法。将该方法应用于实例的分析,获得了满意的拟合效果。
1 Logistic增长模型中a的估计方法
对于Logistic增长模型的拟合,绝大多数作者均将式(1)中的a、K和r作为3个独立的参数进行估计。在统计软件包相关教程中,Verhulst模型的表达式也为y=b1/(1+b3exp(-b2x)),其中bi(i=1,2,3)为待估计的参数[7]。利用这些方法估计参数,计算得到的理论初值常与实测初值不等,甚至差异很大。虽然唐启义等[8]曾对上述作法提出过质疑,但似乎并未引起重视。
因此,Logistic模型参数估计所必须解决的一个重要问题是:能将a作为与K和r一样的独立的参数估计吗?经过拟合得到的理论初值是否应与实测初值N0相同?
为探讨上述问题,将Logistic增长模型:



则待拟合的方程应为式(6)而非式(2)。
1 利用线性回归分析估计参数K和r的新方法:“最佳”观测点数定向搜索法
关于参数K和r的估计,许多线性化方法是首先估计一个K值,然后将其代入式(2)估计r,因此r的估计在很大程度上依赖于K的估计精度并受回归分析采用的观测点数目的影响。若K值估计精度不够高或不确定性较大或选择的观测点数目不恰当,均可能严重影响最终拟合结果。万昌秀和梁中宇[3]提出的枚举选优法将种群达到平衡后的最大和最小观测值作为K的上、下界,分别将该范围内的每个整数作为K值,并对每个K值均分别从全部观测值中选取前m个观测值(m=4,5,6,…,n;n为观测值总数)进行回归分析估计可能的r值,然后逐一比较各组参数估计值对应的SSe,以SSe最小为标准确定最终参数估计值。该方法考虑全面、稳妥可靠,明显提高了拟合优度;但因计算量大(种群数量很大和观测数据很多的实验数据尤其如此)而需编制专门的计算机程序,并难以处理非整数型数据或种群未达平衡状态便终止实验的不完整的观测数据。
针对上述问题,在提出利用式(6)作为拟合方程的基础上,本文提出一种新的线性化方法——“最佳”观测点数定向搜索法。该方法的要点为:(1)首先确定适当的K值初始搜索区间;(2)利用该区间端点和中值确定一个在整个K值搜索过程中进行线性回归分析时均可采用的适宜的观测点数目,从而不必对每个K值均选取前m个观测值进行分析;(3)利用黄金分割法定向搜索K的最优估计值。
1.1 K值初始搜索区间[Ka,Kb]的确定
1.1.1 完整实验数据初始搜索区间的确定
对于实验数据相对完整、有多个观测值围绕平衡数量波动的情况,一般来讲,参数K的最优估计值K*应在这些观测值的平均值(Km)附近,因此可直接将Km作为初始搜索区间的中值Kmid来确定初始搜索区间[Ka,Kb](Kmid=(Ka+Kb)/2)。若在这些数据中存在个别观测值明显偏大或偏小,可去除这些观测值后再计算Km。初始搜索区间应稍大一些,最好包括围绕平衡数量波动的所有观测值(异常值除外)。
1.1.2 不完整实验数据初始搜索区间的确定
若种群未达平衡状态便终止了实验,则无法依据上述方法确定Kmid和初始搜索区间,而需预先估计一个搜索区间,然后再行调整。
(1)初始搜索区间的预估。对于增长曲线上端已经明显变缓的实验数据,可直接通过目测预估初始搜索区间[K'a,K'b],计算中值K'mid。若实验数据明显不完整,难以估计上渐近线的大致位置,则可随机选取3组等时间间距观测数据依据Pearl和Reed的三点法十分方便地估计3个K值,计算其均值Km,以Km作为区间中值K'mid初步估计初始搜索区间[K'a,K'b]。初始搜索区间应包括上述3个K值并向上、下有一定延伸;对于增长曲线上端已出现转折的实验数据,还应包括转折段的观测值,以减小遗漏K*的可能性。
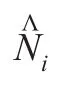
1.2 回归分析采用的“最佳”观测点数(M★)的确定
在K值搜索过程中,若初始搜索区间[Ka,Kb]设置比较合理,K*一般应位于区间中值Kmid附近,搜索过程中(尤其后期)大多数探测点的K值往往也距Kmid相对较近,因此可利用区间端点和中值探测一个在整个K值搜索过程中进行回归分析时均可采用的适宜观测点数(“最佳”观测点数M*)。具体方法如下:
(1)对于初始搜索区间[Ka,Kb],分别根据式(6)计算端点Ka、Kb及中值Kmid对应的Y值,在同一图中作3个K值对应的Y-t折线,然后在图中找到符合下列条件的一点:在该点和该点之前,不仅3条Y-t折线的线性关系均较强且比较类似,而且包括的观测点数目尽可能多,使依据这些观测数据估计r时能够利用更多实验数据的信息和获得更高的拟合优度。可以看到,该点一般对应于3条Y-t折线呈明显“Y”形分离的分叉点(将其对应的观测点数记为ms),但有时也可能为分叉点之前或之后的一点,因此比较适宜的观测点数分别为ms-1、ms和ms+1。

本方法的关键在于以Ka、Kb及Kmid对应的3条Y-t折线确定ms,因此可称为“三线定点法”。
“三线定点法”的合理性证明:
在初始搜索区间[Ka,Kb]中,设 Kc=Ka+ΔK(0≤ΔK≤Kb-Ka),则对于任一Kc,均有


因此,在Y-t图中,随着观测点数目的变化(反映N的变化),不仅特定K值对应的Yc值的变化趋势、而且不同K值对应的Yc值彼此之间的大小关系均可能发生明显改变,由此必然影响参数r的估计结果。随着N的增加,各个Kc=Ka+ΔK对应的Y-t折线将按照ΔK的大小依次向下发生转折,直至Kc大于全部N值。在区间[Ka,Kb]中,Ka最小,因此在N<Ka的数据范围内,各个K值对应的Y-t折线不仅均处于上升段而且位于两端点对应的Y-t折线之间。若以区间中值Kmid对应的Y-t折线作为参照线,则在Ka、Kb和Kmid对应的3条Y-t折线均呈较强线性关系的观测点范围内,其他任一Kc值对应的Y-t折线也应保持类似关系,因此可在整个K值搜索过程中以同样的观测点数目进行回归分析估计r。
以Gause(1934)双小核草履虫种群增长实验(添加一环细菌)[9]为例。该实验数据完整,有多个观测值围绕平衡数量上下波动,因此可直接以这些观测值的平均值(Km=448)作为中值Kmid确定初始搜索区间「418,478」。为了更加清晰地反映不同K值对应的Y-t折线之间的关系,避免实测值在平衡数量附近的波动对图形的影响,首先以唐启义等[16]的预测值代替实测值进行分析(图1左图)。在预测值中,N7=409<Ka,N8=429>Ka,Nmax=N16=439。由图可见,在前8个观测点范围内,所有Kc=Ka+ΔK(0<ΔK≤Kb-Ka)对应的Yc-t折线均位于Ya-t折线之下且与Ya的偏离程度随△K的增大而增大。在该范围之后,对于所有KC<Nmax=439,其对应的Yc-t折线均随N的增加依次向下转折,最终的Yc值随ΔK的增大而增大。而对于其他Kc值,因KC>Nmax,其对应的Yc值单调增加直至稳定,且随ΔK的增大而减小。各条Y-t折线明显“Y”形分叉点对应的观测点数ms=7。
若直接以实验观测值计算Yc,则得图1右图。实验观测值N8=396<Ka,N9=443>Ka。由图可见,尽管该图右部各Y-t折线波动剧烈,但在前9个观测点范围内,Y-t折线的排列却十分有序,Yc与Ya的偏离程度随ΔK的增大而增大。各条Y-t折线明显“Y”形分叉点对应的观测点数也为ms=7。
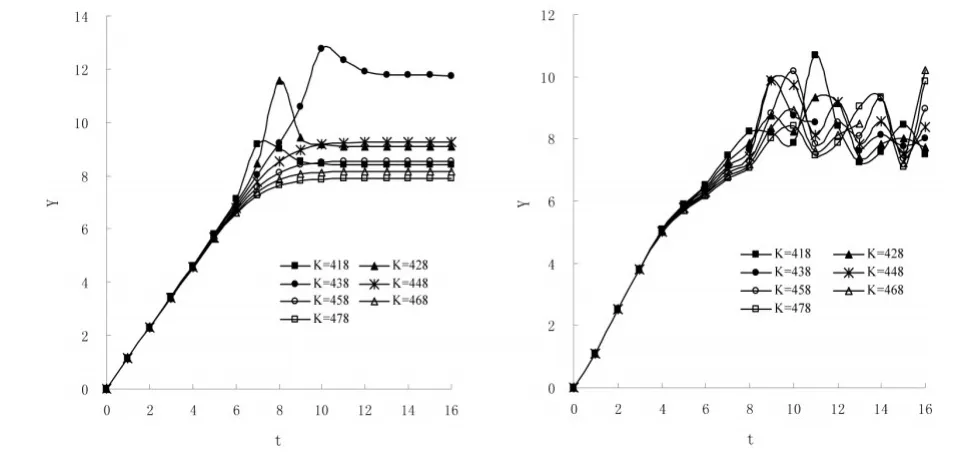
图1 “三线定点法”示意图。依据Gause(1934)双小核草履虫种群增长数据(添加一环细菌)[9]作图。左:利用唐启义等预测值[8]计算Y;右:利用Gause实测值计算Y。
1.3 K的“最优”估计值(K★)的定向搜索
黄金分割法是运筹学中单变量非线性最优化的重要方法[18],该法具有搜索方向明确、收敛速度快、计算简单且计算量小的优点,而且适用于整数型或非整数型观测数据。利用该法搜索K*的具体作法如下:
(1)对于初 始搜索区间[Ka,Kb],搜索区间 长度L=Kb-Ka。在搜索区间内距两个端点各0.382 L处对称插入两个内插点Kc和Kd,下内插点Kc=Ka+0.382L,上内插点Kd=Kb-0.382L=Ka+0.618L。分别将Kc和Kd代入式(6),选取前M*个观测数据进行回归分析估计r,然后计算对应的SSe。
(2)比较两内插点对应的SSe,若下内插点Kc的SSe较大,则舍弃下端点Ka,将Kc作为新区间的端点,并在上内插点Kd与上端点Kb之间插入一个新的上内插点;反之,若上内插点Kd的SSe较大,则舍弃上端点Kb,将Kd作为新区间端点,并在Kc与Ka之间插入新的下内插点。仍按照(ⅰ)中的方法计算新内插点的K值(此时L应为缩小后的搜索区间长度)。
(3)多次重复步骤(ⅱ),通过不断舍弃端点来逐渐缩小搜索范围(第n次搜索后,搜索长度将缩小为初始长度L的0.618n倍),同时不断插入新内插点以加大对重点区域的搜索密度。当SSe下降十分缓慢或达到实验要求的精度时,即可将此时的K值作为“最优”估计值K*。
1.4 方法小结
综上所述,“最佳”观测点数定向搜索法的主要分析步骤如下:
(1)完整实验数据的拟合。
①实验观测数据的预处理。若原始实验数据的初始时间t0≠0,则以t'=t-t0代替t。
②选取围绕平衡数量波动的观测值计算其平均值Km,以Km作为中值Kmid,确定初始搜索区间[Ka,Kb]。。
③利用“三线定点法”确定一个在整个K值搜索过程中进行线性回归时均可采用的“最佳”观测点数M*。
④利用黄金分割法定向搜索参数K的“最优”估计值K*和相应的r值。
⑤此外,搜索到K*值之后,还可对其进一步调整回归分析采用的观测点数目,以提高参数r的估计精度、获得更好的拟合效果。
⑥将K*和最终获得的r估计值r*代入式(6)或式(1)(积分常数a据K*和实测初值N0由式(5)解出),即可获得Logistic增长模型。
(2)不完整实验数据的拟合。
若实验数据不完整,则需首先预估一个K值搜索区间(具体方法见1.1.2步骤(ⅰ)),作该区间端点和中值对应的Y-t图,确定ms;然后分别将端点和中值代入式(6)估计r(因两个端点的K值往往相差较大,一般直接由前ms个观测数据进行回归分析即可),计算3个K值对应的SSe。若一侧端点的SSe最低,则以该端点作为新区间的中值,将搜索区间向该侧平移。重复上述调整过程,直至中值的SSe最低,最终确定初始搜索区间[Ka,Kb]。
其他步骤与上述完整实验数据的分析相同。
2 实例分析及结果
利用“最佳”观测点数定向搜索法对7个实例进行了分析。其中,Gause(1934)草履虫种群增长实验[9]是种群生态学中最为经典和重要的实验。
2.1 完整实验数据的分析过程
仍以Gause(1934)双小核草履虫种群增长实验(添加一环细菌)[9]为例。由前面分析可知,本例初始搜索区间[418,478],Kmid=448,ms=7。取Kmid=448,分别以前6、7、8个观测数据估计r。3个r值对应的SSe分别为17436、14504和14970。ms=7对应的SSe最小,因此确定M*=7。以前7个观测数据进行回归分析估计r,经8次搜索(表1),得K*=438,r*=1.1532。

表1 Gause(1934)双小核草履虫实验数据(添加一环细菌)[9]K值搜索过程
2.2 不完整实验数据初始搜索区间的确定
以王振中和林孔勋花生锈病显症动态试验(Ⅰ)前19天的实验数据[12]为例。该例观测时间为第9-19天,相应的观测值(孢子堆数目)依次为79、126、257、625、1856、4000、7389、12133、16057、18898和22361。首先将原观测时间转换为 t=0~10 ;然后分别选取t=(0,5,10)、(1,5,9)和(2,5,8)对应的观测值,按照三点法[1]计算K值,得K=21564、17843和19204。将3个K值的均值Km=19537作为K'mid,分别向上、下各延伸4000预估初始搜索区间,得[15537,23537]。分别作K=15537、19537和23537对应的Y-t图,3条折线的明显“Y”形分叉点对应于ms=7。选取前7个观测数据进行回归分析估计3个K值对应的r值,计算SSe,分别为107790143、33024912和4105099。由于上端点K=23537对应的SSe最低,因此将其作为新区间的中值,将初始搜索区间平移至[19537,27537]。对新区间进行类似分析,得ms=8;选取前8个观测数据估计r,以中值对应的SSe最小,因此确定初始搜索区间为[19537,27537]。
2.3 个实例的分析结果
表2给出了7个实例的分析结果,相应的Y-t折线图分别见图1-图7。获得“最优”估计值K*后,均对其进一步调整m值,以期提高参数r的估计精度,但最终均以m=M*对应的 SSe最低。
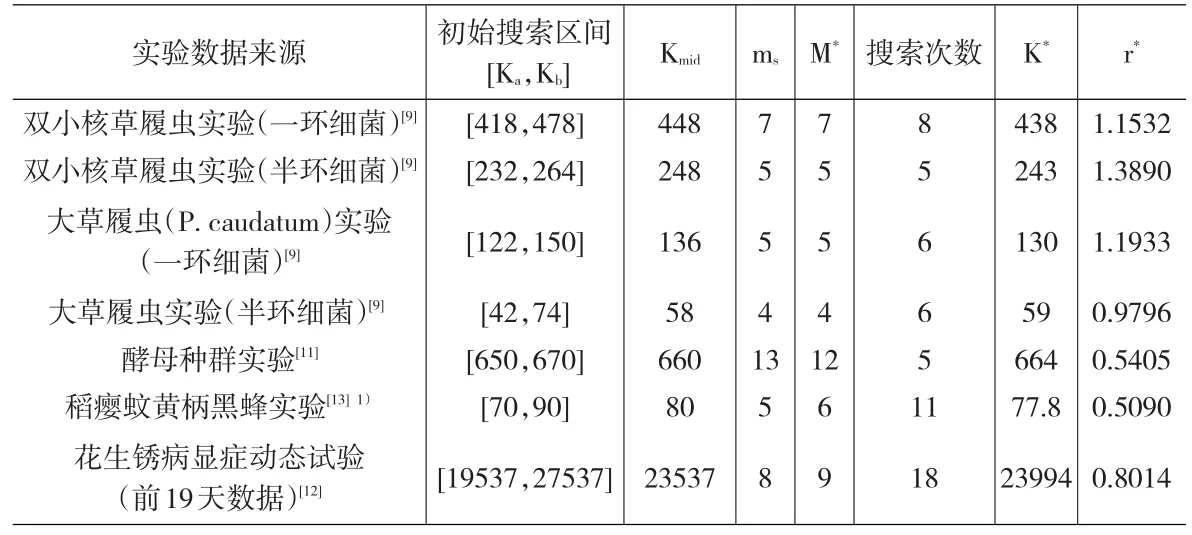
表2 “最佳”观测点数定向搜索法应用实例分析
周赛花[13]误将邬祥光[4]第17天的实测值23.50看作28.50,因此拟合结果存在一定偏差。但为与周赛花提出的逐次加密
搜索法进行比较,本文仍按其给出的数据进行拟合。
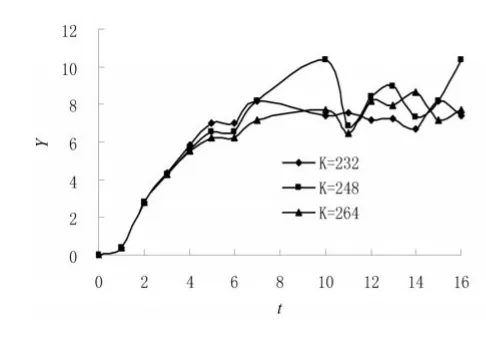
图2 Gause(1934)双小核草履虫(添加半环细菌)[17]Y-t图

图3 Gause(1934)大草履虫(添加一环细菌)[17]Y-t图

图4 Gause(1934)大草履虫(添加半环细菌)[17]Y-t图
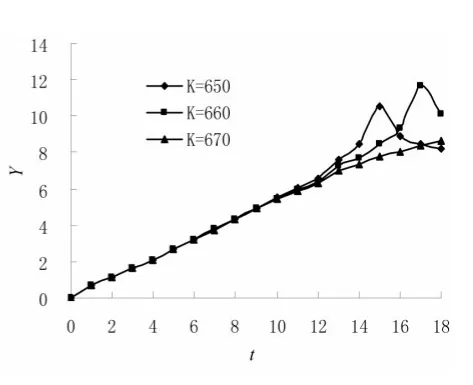
图5 Carlson(1913)酵母种群[19]Y-t图
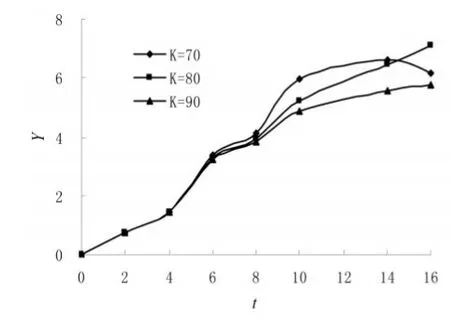
图6 稻瘿蚊黄柄黑蜂[8]Y-t图

图7 花生锈病显症动态试验Ⅰ(前19天数据)[7]Y-t图
3 与其他作者拟合结果的比较


表3 Gause(1934)双小核草履虫种群增长实验数据[17]拟合结果的比较*
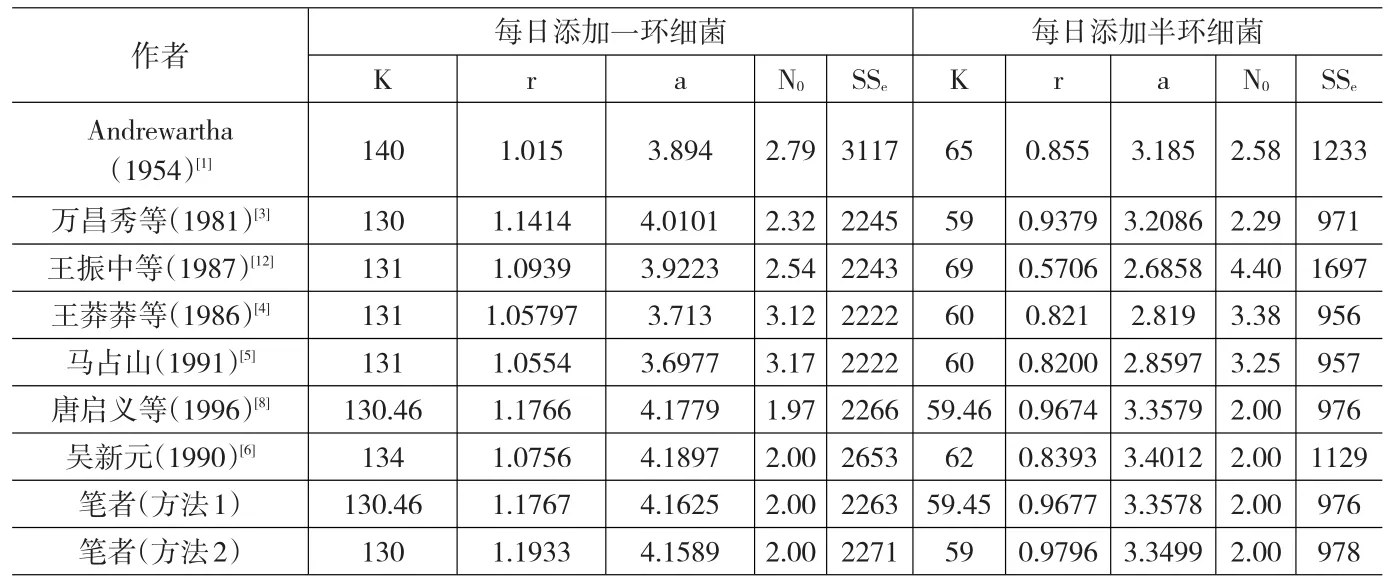
表4 Gause(1934)大草履虫种群增长实验数据[17]拟合结果的比较*
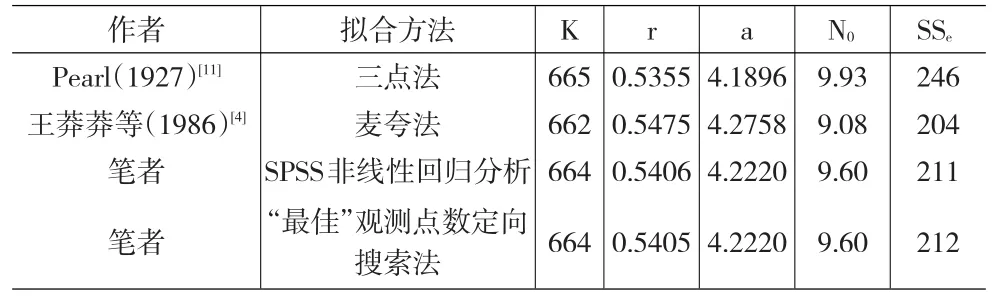
表5 Carlson(1913)酵母种群增长实验数据[19]拟合结果的比较*

表6 稻瘿蚊黄柄黑蜂种群增长数据[8]拟合结果的比较*
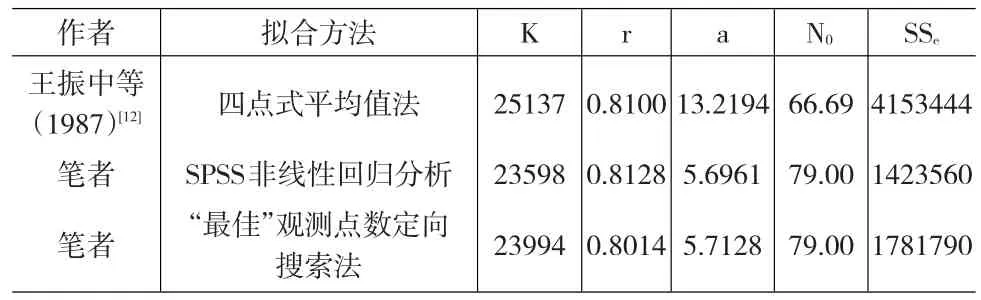
表8 花生锈病显症动态试验(Ⅰ)前19天实验数据[7]拟合结果的比较*
由上可见,与其他拟合方法比较,本文提出的“最佳”观测点数定向搜索法具有如下优点:
(1)不仅可以满足Logistic增长模型的初值条件,保证理论初值与实测初值相等,使参数K和r的估计更为客观准确,而且能够获得理想的拟合效果,拟合优度与唐启义等[16]以及SPSS非线性回归模块(依据式(4))采用麦夸法的结果十分接近。
(2)每一步的分析结果都比较明确,最终拟合结果的不确定性小。
(3)可用于完整或不完整、整数型或非整数型实验数据的拟合,适用范围较之前的很多线性化方法明显拓广。
(4)原理简单,计算量小,仅靠Excel即可轻松完成全部计算,很适于不熟悉统计软件包的研究者利用。
[1]Andrewartha H G,Birch L G.The Distribution and Abundance of Animals[M].Chicago:University of Chicago Press,1954.
[2]考克斯.普通生态学实验手册[M].蒋有绪译.北京:科学出版社,1979.
[3]万昌秀,梁中宇.逻辑斯谛曲线的一种拟合方法[J].生态学报,1983,3(3).
[4]王莽莽,李典谟.用麦夸方法最优拟合逻辑斯谛曲线[J].生态学报,1986,6(2).
[5]马占山.单纯形加速法拟合生态学中的非线性模型[J].生物数学学报,1992,7(2).
[6]吴新元.逻辑斯谛曲线拟合的一种数值方法[J].生物数学学报,1990,5(1).
[7]陆纹岱.SPSS for Windows统计分析[M].(第3版).北京:电子工业出版社,2006.
[8]唐启义,胡国文,冯明光,胡阳.Logistic方程参数估计中的错误与修正[J].生物数学学报,1996,11(4).
[9]Gause G F.The struggle for existence[M].Baltimore:Williams and Wilkins,1934.
[10]瓦格纳.运筹学原理与应用(第2版)[M].邓三瑞等译.北京:国防工业出版社,1992.
[11]Pearl R.The Growth of Populations[J].Quarterly Review of Biology.1927.
[12]王振中,林孔勋.逻辑斯谛曲线K值的四点式平均值估计法[J].生态学报,1987,7(3).
[13]周赛花.逻辑斯谛方程中参数的估计[J].数理统计与管理,1992,11(5).
[14]邬祥光.昆虫生态学的常用数学分析方法(修订版)[M].北京:农业出版社,1985.
