人力资源统计数据异常的数据挖掘检验
2015-02-18唐雪莲王姗姗
唐雪莲,王姗姗
(1.宁波大红鹰学院 经济管理分院,浙江 宁波315175;2.浙江工商大学 杭州商学院,杭州 310018)
0 引言
数据挖掘,是指从大量数据中找出具有潜在价值的、可理解的、新颖的、有效知识的整个过程,从而为决策者提供可靠的决策支持。数据挖掘共分为确定目标、准备数据、建立模型、模型评估四个操作环节。在数据挖掘技术基础上发展起来的数据异常检测,是为了检测出数据中与绝大部分数据有差异的对象,通常将这些对象称为离群点。这些差异对象的产生,可能与数据来源不可靠、数据发生自然变异、数据收集误差、数据测量不当等因素有关。在数据挖掘问题中,绝大部分都认为离群点是噪声,认为其影响非常小,甚至还会直接忽略其影响。但是在实际问题中,这些离群点的作用可能比普通节点更为重要,如欺诈检测中的离群点就有可能是欺诈行为,所以在数据挖掘中进行离群点检测是一项有意义的研究。
在数据异常检测方面,国际上的研究成果较多,海量分布式数据库就是在传统异常检测中融入新兴技术的典范。在现实生活中,数据异常检验技术的应用十分广泛,如网络入侵、欺诈行为检测以及医疗病例分析等。国内的数据挖掘技术起步较晚,在研究方法方面尚不成熟,在政府数据统计工作中也较少应用该项技术,统计工作中应用较多的就是OLAP方法。近年来,国内也有政府部门逐渐开始应用厂商生产的基于数据挖掘的统计信息系统,如马克威统计系统。目前,上海市统计局已经开始使用该产品,用于分析人口变化、劳动力情况、城镇化进程、经济状况等。然而,我国的中低层政府统计部门都还没有引入这些商业化数据挖掘统计软件,也就是说,我国绝大部分的统计部门都还没有完全采纳数据挖掘这项技术。为此,在政府统计工作中应用数据挖掘技术,开发出一套使用方便、经济性好、真正满足统计工作者需要的统计系统,提高异常数据检出率,提升统计数据质量是一项具有重要现实意义的课题。
1 基于数据挖掘技术的数据异常检验方法
近年来,国外有相关研究人员提出了基于聚类的数据异常检测法,该方法是通过聚类数据集,根据相关标准将其生成的簇划分为异常簇和正常簇两类。训练数据集是传统检测方法的应用前提,而聚类法则突破了这一限制,在无训练数据集时,也能够应用聚类法进行异常检测。实际中,在应用聚类算法时,需要注意对象先后位置、初始值、算法复杂度、参数影响、最优解等问题。在进行数据挖掘时,常会涉及到分割簇形状的能力、异常数据影响、算法可伸缩性、输入参数简单性、对不同类型数据的处理能力、聚类结果直观性、解决多维数据的能力等方面。
1.1 K-means聚类
K-means聚类,是将一个涵盖多个数据对象的数据集的分为若干份(即“簇”),将所得的簇数量(k)作为输入参数。先选取k个初始聚类中心,每个对象都被指派到最近的聚类中心,而指派到一个中心的点集为一个簇,再根据每个簇中的点,对簇的聚类中心进行更新,如此重复更新、划分,直至聚类中心无变化。K-means算法具有较高的聚类效率,是大规模数据聚类的常用算法,其作为一种经典的聚类算法,在理论上具有步骤简单、快速可靠的优点,尤其是对海量数据的处理,更能体现其高效特点。但是,该算法也存在一定的局限性,具体体现在:一是该算法的使用必须满足簇平均值可定义的条件,不适用于非数值属性数据;二是必须事先确定簇的生成数目值,然而在实际中,对于无先验分类信息的数据,是很难准确给出一个k值的,所以该算法容易产生不同簇数;三是初始聚类中心选择任意,这种方法容易造成聚类结果极值化;四是K-means算法对离群点和噪声十分敏感,即便是少量离群点,也容易对均值造成较大的影响。
1.2 DBSCAN聚类
DBSCAN算法可识别数据集中的特殊数据对象,并且还适用于任意形状簇,但该算法的聚类结果会受到初始值MinPts、Eps的极大影响,由于该算法过于依赖MinPts、Eps,所以造成了其聚类结果的不稳定性,其在实际工作中难以发挥出实质性作用。另外,由于难以定义多维数据中的密度,所以会增加该算法的计算量,从而降低海量数据的处理效率。
2 统计数据异常的自适应检测
在政府的人力资源数据统计中,异常检测具有重要的应用价值,特别是在统计部门甄别统计对象虚假、错误数据方面,其对于提高人力资源统计数据质量具有重要作用。从上文分析可以看出K-means聚类和DBSCAN聚类异常检测法均具有一定的局限性,故本文在应用这两种聚类算法优点的基础上,提出了一种可自动计算合适参数的自适应检测法。
2.1 自适应异常检测概述

假设两个簇(Ci、Cj),其中Cj簇中所有数据对象到簇质心的最大距离为maxJ,若Cj簇中有某一数据对象(m)与Cj簇质心距离≤maxJ,则需要对这两个簇进行合并(如图2所示)。簇合并应用DBSCAN算法中的小簇合并法,最终获得的聚类结果以k表示。

图1 簇划分示意图
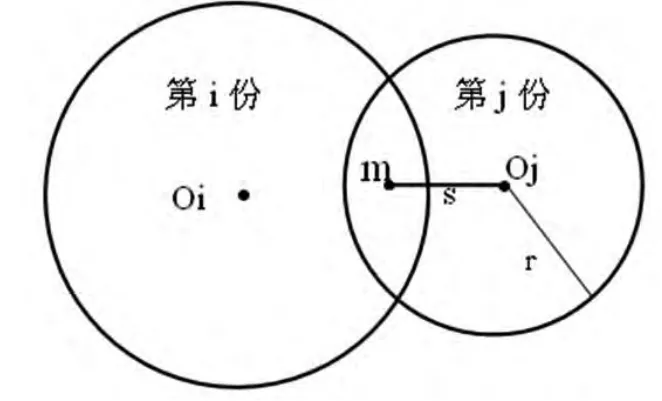
图2 簇合并示意图
2.2 改进K-means算法描述
输入数据集:I={i1,i2,…,in}
输出簇集:U={u1,u2,…,uk}

2.3 MinPts、Eps计算及二次聚类
MinPts、Eps参数会对聚类效果产生直接影响,这两项参数的确定也是DBSCAN算法最大的局限性。应用K-means算法聚类后,得到了簇集U,要获得离群点,就可应用簇集U确定MinPts、Eps值,再运用DBSCAN算法获得离群点。为减小离群点对算法的影响,需要筛选聚类结果,本文选取数据对象数量≥4的簇,获得簇集R={N1,N2,…,Np},Ri∈U,p≤k。
MinPts、Eps计算:先计算出每个簇(Ri)中数据对象间的平均距离(di),再计算每个簇所得的di值进行加和,求平均值,即Eps值;先统计周围距离≤Eps值的数据对象个数,再取平均值,即MinPts。
在获得MinPts、Eps值后,应用DBSCAN算法做二次聚类,最终检测出离群点。自适应异常检测法是一种结合了DBSCAN和K-means算法的混合聚类算法,通过分阶段聚类,排除人为干预因素,从而提高检测的自动化水平,提高估值的准确性。如图3所示为自适应数据异常检测法的流程图。

图3 自适应检测流程
3 自适应检测实验与异常检测系统设计
3.1 自适应检测实验设计
3.1.1 数据集
实验数据源自我市企事业单位的工资汇总表中的合计情况,每项数据都包含女性数量、单位类别、单位代码、从业人员总数、工资总额、平均人数等属性。工资汇总表如表1所示,为满足保密要求,本文对单位编码进行了处理。在这些属性中,部分数据具有冗余特点,故只能选择最能体现数据对象特点的属性,并根据平均人数和工资总额,计算出人均工资总额。本实验最终选取代表企业人数及工期情况的期末总人数、人均工资总额两项属性。
3.1.2 数据预处理
在进行数据挖掘前,要对所有参与的数据进行预处理,即筛查、剔除各种不符合实际情况、空的、错误的数据对象。比如:期末总人数值不可能为零;工资总额一项不得小于零等。在一个统计表格中,不同的属性项目之间可能存在逻辑关联,若统计结果与逻辑关联不相符,则提示这些数据欠真实。属性间的逻辑关联可分为两类:一是量化关系,即某些数据项之间的大小关系,比如期末总人数不得小于期末女性人数;二是控制关系,即某个数据项的值可影响其他数据项结果,比如机关单位的生产运输设备操作员一项,其数据值应为零,负责生产人员数据项的值也应为零。在统计数据中,若有数据项不满足以上审核关系,表明统计数据有误,该企事业单位应重新上报数据。
在本次实验中,数据属性所应用到的逻辑关系包括:35岁以下人数不大于期末总人数,女性人数不大于期末总人数,有职称技能等级人数不大于期末总人数;初中及以下人数与中专及高中、专科、本科、研究生人数之和等于期末总人数,工资总额不为零。
在一个数据对象中,不同的属性,在度量单位与方法方面会有明显差异,这些差异都与数据距离有着直接关系,所以在剔除不符合实际情况、空的、错误的数据对象后,还需做标准化处理,以排除上述因素的干扰。先将各数字型属性值做归一化处理,再计算绝对偏移平均值(Sf),计算公式:

mf:第f个属性的平均值;xif:各数据的第f个属性取值。
再应用公式,对各属性做标准化处理,公式如下:
Zif:第i个数据的第f个属性。在对数据进行预处理后,可将数据直接应用于聚类算法,经预处理提取出的不合逻辑的数据对象,也是最终异常数据的组成部分之一,其也能为提升统计数据质量提供有效参考。
3.1.3 结果与分析
本次实验的数据集共抽取了998个事业单位,并对数据集进行了预处理。采用自适应异常检测法对数据集进行检测,并将检测结果与应用DBSCAN算法和改进K-means算法获得的结果进行比较,以验证自适应异常检测法的有效性、科学性。
(1)实验结果
在进行逻辑关系检验时,筛查出4各不符合逻辑关系的数据,将其排除,最终有994个数据对象参与聚类。在应用改进K-means算法对数据对象进行聚类后,获得的聚类数目共30个,符合参与聚类条件的簇共6个(见表2)。簇1~6均参与MinPts、Eps参数计算,计算结果为分别为4和0.36,检出的异常数据个数为34。

表2 改良K-means聚类结果
根据计算出的MinPts、Eps值,应用DBSCAN算法,对数据对象进行聚类,聚类结果见表3。应用DBSCAN算法聚类,最终获得的簇数目共5个,数据对象共958个,异常数据共36个,加上预处理阶段筛查出的4个不符合逻辑关系的数据对象,共检测出40个异常数据。

表3 DBSCAN聚类结果
(2)结果比较
应用K-means算法对本次实验中的数据对象(994个)进行处理,将初始值k设为6,随机选择初始质心,进行聚类后的结果,详见表4。

表4 K-means聚类结果
对自适应检测法中改进K-means算法和传统K-means算法的聚类质量进行比较,评估标准为目标函数的误差平方和(SSE),即计算各数据与最近质心的欧氏距离,再计算误差平方和,数值越小,则聚类效果越好。K-means算法获得的SSE值为175.64,改进K-means算法的SSE值为157.98,这表明改进K-means算法的聚类效果比以前的K-means算法更好。
DBSCAN算法中,MinPts、Eps参数的计算,是通过观察K-距离图,找出急剧变化点位置,来估计Eps值。MinPts值取4在大多数的二维数据集中都是合理的。本次实验数据集的K-距离图,见图4。从图4可看出,曲线的急剧变化范围在0.3~0.4范围内,但要确定具体值,还需应用人员结合自身经验进行估计和判断。在自适应异常检测法中,应用改良K-means算法计算出的Eps值为0.35,这一数值与K-距离图值域完全吻合,该方法无需绘制K-距离图,也无需人工判定Eps值,且计算所得的Eps值正确、合理,其能较好地避免因操作者经验不足造成的认为误差。

图4 数据对象的K-距离图
3.2 异常检测系统设计
本文在人力资源实际统计数据基础上,结合自适应异常检测法,提出了统计数据异常检测系统的设计思路,以期发现人力资源统计数据中的异常情况。
3.2.1 系统结构设计
人力资源数据异常检测系统的开发平台为Windows操作系统,数据库为Access 2000,开发语言为SQL和C#,该系统主要实现数据导入、图表显示及检测结果显示几项功能。

图5 数据异常检测系统的算法流程图
异常统计数据主要来源于瞒报、虚报,操作错误,经营方式特别的企事业,规模或效益较高的特大型企业等。在发现统计数据中的异常情况,应将检测重点放在与员工工资、工作人数相关的数据上。针对运行正常的企业,其统计数据的波动幅度应该较小或相对稳定,而类似企业,其数据也应具有一定的相似性,这是异常数据检测应掌握的最基本原理。
在结构方面,异常检测系统共有四层:应用层及数据挖掘、数据处理、数据源层。数据源层用于获取工资统计及人力资源信息系统中的相关数据,将这些数据汇总到同一数据源中,建立一个数据仓库;数据处理层用于预处理源数据,使统计数据符合数据挖掘需求;数据挖掘层负责检验数据异常;应用层负责创建交互式操作界面,展示检测结果。
3.2.2 算法流程
异常检测系统的检测对象包括企事业单位工资汇总表、人力资源年度报表、劳动工资季度及年度报表。在异常数据检测中,这四张报表间的差别主要体现在逻辑检查方面,其他实现方法相同,该系统的算法实现流程,如图5所示。
4 总结
本文在深入分析DBSCAN和K-means聚类算法局限性及应用优势的基础上,提出了结合两种算法优点,弥补二者局限性的混合聚类算法——自适应异常检测法。该算法较好地弥补了K-means和DBSCAN算法的不足,在检测过程中最大限度地排除了人为干预,实现了初始参数的自适应计算。在人力资源统计数据中应用自适应异常检测法,能够较好地检出其中存在的异常数据,实验证明,自适应检测法获得的异常数据检测结果能够达到专家检测水平,其能为统计部门的人力资源数据抽查提供科学的参考、借鉴。
[1]Liu Y B,Zhang L,Wang J M.Mining Workflow Event Log to Facilitate Parallel work Item Sharing Among Human Resources[J].International Journal of Computer Integrated Manufacturing,2011,24(7/9).
[2]Hanadi Al-Zegaier H,Al-Zu'bi H A,S Barakat S Investigating the Link between Web Data Mining and Strategic Human Resources Planning[J].Computer and information science,2011,4(3).
[3]王玉红,王康碧,薛红月等.基于Gini Index决策树的人力资源挖掘研究[J].云南民族大学学报(自然科学版),2013,22(2).
[4]马正友.基于知识管理的人力资源管理信息系统分析和模型设计[J].人力资源管理(学术版),2009,(8).
[5]洪强.基于数据挖掘的人力资源故障诊断技术[J].科技资讯,2009,(6).
[6]瞿丹.数据挖掘技术在高校人力资源管理中的应用研究[J].电脑知识与技术,2014,(10).
[7]孙进.浅析人力资源数据挖掘中的数据清理[J].福建电脑,2010,26(12).
[8]高福良.浅谈数据挖掘在人力资源管理中的应用[J].科技信息,2011,(33).
[9]陈晓璠,邓砚谷,郑玉莉等.数据挖掘在企业人力资源绩效管理中的应用[J].上海管理科学,2009,31(6).
[10]李琦,苏立玢,王剑霞等.基于Oracle数据挖掘技术的高职院校人力资源管理系统的研究与实现[J].科技信息,2010,(20).
