自然语言的计算机处理模型
2015-02-07容联七陌科技有限公司张志新
容联七陌科技有限公司 张志新
自然语言的计算机处理模型
容联七陌科技有限公司 张志新
目前在自然语言理解方面的研究程度并不深,始终停留在让计算机正确理解语言信息上,在自然语言理解的研究上主要有基于规则的语义处理方法和基于语料库的统计方法两种,虽然这两种方法获得了一些成绩,但是二者均需要依赖可靠的语言知识对计算机进行驱动,从而对自然语言进行处理,因此,后台语言知识的重要性可见一斑。本文主要基于以上内容,提出了粗浅的自然语言处理模型,并针对后台语言知识库的建立以及文章知识提取等方面展开了一系列的分析,希望本文的分析可以为同行的研究带来一些参考。
自然语言;计算机处理;模型
自然语言的计算机处理涉及到多种学科和多个研究领域,其主要研究力量由语言学、数学以及计算机科学等不同学科的研究人员组成,近年来随着科学技术的快速发展,计算机功能从数值计算逐渐发展为数值计算和信息处理并重的一种状态。实际上自然语言处理就是对怎样使计算机理解并生成人们日常需要的进行研究,同时利用对话的方式对人提出的问题进行回答。自然语言处理的目的在于建立起在人和机器之间形成的友好关系,对信息进行高度的传递与认知,鉴于此,本文结合笔者的实际工作经验,针对自然语言的计算机处理模型展开分析,相信一定可以为大家带来一些启示。
1 自然语言概述
通常情况下我们所说的计算机理解了一些事情,主要是指计算机将一些表现形式转换成了另外一种表现形式,也可以说将事件的自然语言表现形式转换成了计算机能理解的表现形式,这就是目标语言。之所以自然语言在理解上存在一定困难,主要原因可以从以下几方面进行分析:首先,目标表示的复杂性。例如要想从语句中将关键字提取出来非常复杂,同时还要了解很多相关与客观世界相关的知识。其次,映射的类型。从源语言到目标语言的映射,理想中是一对一类型的映射,但是现实中很难达到一对一的要求。第三,成分的交互程度。语言中每个语句都需要由多个成分组成,如果每个成分的映射都与其成分没有直接关系,那么映射的过程就会变得非常简单,但是非常遗憾,自然语言中的成分存在非常高的交互程度,往往将句子中一个成分改变了,其整体结构就会大大改变,从而大大增加映射的复杂程度。目前计算机还远远没有的阿道人一样的理解水平,相信将来也不会达到这样的水平,所以应该从实用的角度去判断计算机对自然语言的理解,只要计算机能够实现人机会话,或者能够自动摘录一些语言信息,那么我们就可以说计算机已经具有了自然语言的能力。
2 自然语言的计算机处理模型
2.1 汉语理解系统模型
汉语理解系统模型主要包括分词与词性标注子系统、句子成分划分子系统、代词指代子系统、汉语理解子系统几部分,本系统模型需要建立知识网作为自然语言语义描述上的理论,同时依赖可靠的语言知识驱动计算机对自然语言进行正确处理,这就需要建立起体现知识网理论的词库,还要对文章中的信息进行提取,了解每句话所反映的知识,将这些知识提取出来以后,系统会为文章建立语境,从文章中提取有助于理解的信息,完成这些步骤以后,初步的语义提取已经完成。
2.2 知识库设计
因为汉语独特的性质及使用习惯,计算机汉语理解非常依赖于语境分析,这就不可避免的要建立知识库,知识库中知识的表达方式以及知识的覆盖范围都会对系统运作及分析效果产生影响,这种情况下建立知识库的关键在于知识颗粒的大小以及表示方法。知识的表达方式将会直接影响到知识库的内容及使用方式,由此可见知识库设计是整个系统成败的关键所在。
2.2.1 知识网理论介绍
知识网是一个以汉语和英语词语所代表的概念作为描述对象,用来揭示概念之间存在的属性关系,以这种关系为基本内容的常识知识库。要想利用好知网系统,首先需要对知网系统的哲学思想进行了解,从知网哲学的观点来看,世界上所有事物都在特定的空间和时间中发生着变化,一般来说会从一种状态转变成为另外一种状态,主要利用属性值的改变来实现。知网运算及描述的基本单位是万物,主要包括物质及精神两类,值得一提的是,部件与属性这两个单位在知网哲学中占据着非常重要的地位,汉语中用拟人的方式来描述部件,其他语言也是如此,直接反映出了人类对事物认识方法的共性,此外,知网还规定在标注属性值时一定要标注出它指向的属性。
2.2.2 知网类库的设计
知网理论主要通过对客观世界的概念对知识进行描述与分类,概念和概念之间存在着一定的联系,这些关系在全局中是一个树型的结构,在不同概念中,都会有相应的概念对其进行描述,对于一种具体的知识来说,知网对其描述主要采用类+属性的方式进行表示。在知网理论中,每一类概念都有相应的属性,概念之间又存在直接的关系,因为出于对易扩展性的考虑,通常情况下会采用面向对象的程序设计爱思想来实现知网理论。在现实中知网理论和程序的实现之间是一一对应的关系,往往一个知网概念对应程序中的一个类,而概念属性主要对应类中的成员变量。因为受到多种因素的影响,现在对知网类库的设计始终不是很完善,加上自然语言内容比较大,知网理论提出了一种相对来说比较实用的描述方法,从目前的情况来看,知网理论中还有很多地方需要完善。因此,为了满足未来的扩充及更好的对上层应用进行支持,知网类库设计中易维护性得到了高度的重视。
2.2.3 知网词库设计
要想实现知网类库对文章的处理,应该以知网类库为基础对知网词库进行构造,这样才能使文章理解的需求得到满足。例如“医生”这个词,作为“人”来理解时,那么其“word class”字段应该是“hownnet Class.thing.Humanbeing”,由于医生的活动中包含“医治”,这时“init property”字段应填“canSubject=cure”。在生成对象时,医生与其他人类的对象是不一样的。在实现过程中需要我们对目前的需求进行考虑,因此采用jdatastore数据库。
2.2.4 知识库目前提供的功能支持
实际上知识库只是语言计算机表达的一种形式,其本身并不能提供分析文章的具体算法,但是可以针对上层分析提供很好的语言知识上的支持,这样分析起来会更加容易,现阶段知识库对上层分析提供的功能支持主要有提供知识提取功能的支持、提供语义层面辨错功能的支持、提供准确分词功能的支持等。
2.3 知识的提取
知识库建立起来以后,我们开始尝试对文章知识进行提取,基本的思想是从文章中将知识提取出来,然后将其用对象的形式放在内存中,目前我们只能做到对文章表层知识的提取,也就是分析,了解文章中存在哪些实体,这些实体都做了怎样的事情以及这些实体之间存在的关系。其具体设计是建立在知识库建立的基础上,不仅要对知识进行提取,同时还可以将其作为知识库使用的例子(见图1)。
利用句子构造器来接收数据,生成“句子实体”,在未来的运行中该实体可以作为一个整体来使用,利用句型判断器来接收句子实体,对句子的句型进行判断,按照句子实体的句型利用句型判断器将其发给不同的解析器,利用其来提取句子实体中的知识,并将其结果存放在缓冲区中,分析句子之后缓冲区会生成实体对象,这就是提取的知识。在知识提取模块中句子构造器非常简单,只需要输入并生成一个“句子对象”就可以,这里不做过多的说明。
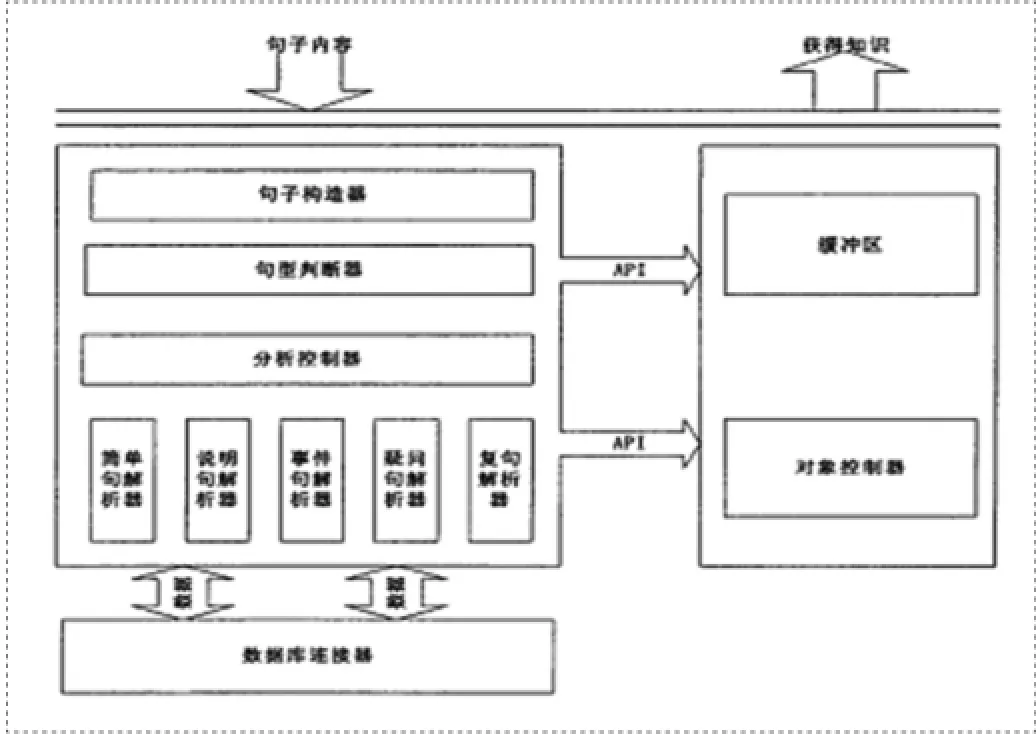
图1 知识提取模块框架图
3 结语
综上所述,本系统是针对计算机汉语理解的一种尝试,在系统设计及实现过程中主要完成了知识库设计与建立、文章知识提取等工作,但是目前该系统中还存在一些不足,例如知识库设计并不完善,在上层知识提取的工作中,对知识的提取和分析工作做得不够充分,对于一些问题的处理通常用较为常见的句子作为例子展开分析,其实用性上难免会受到一些限制,现在本系统是一个演示系统,在很多方面都存在着不足,因此程序健壮性还不够。在这种情况下,希望在以后的工作中能够积极克服上述不足,并有效提高知识库的知识表示能力,从而更好的对文章展开知识提取与分析。
[1]葛玮,吴佳.基于计算机智能识别技术的自然语言处理模型设计[J].无线互联科技,2014(9):40.
[2]袁毓林,陈振宇,张秀松,李湘,周强,高嵩.从认知假设到计算分析和程序实现——一种认知语言学研究的计算范式与技术路线[J].当代语言学,2010(2):97-114+189.
[3]赵晓琴,孙毅中,薛晓蕾.基于知识单元的自然语言结构化解析模型—以城市规划领域规则为例[J].测绘科学,2010(6): 110-113.
[4]李翠霞.现代计算机智能识别技术处理自然语言研究的应用与进展[J].科学技术与工程,2012(36):9912-9918.
