处理器中非阻塞cache技术的研究
2015-01-28孟锐
孟锐
(西安工业大学 北方信息工程学院,陕西 西安 710025)
自从第一个微处理器问世以来,微处理器技术已经成为现代信息化社会中信息技术的核心,其研究已经成为各国在竞争中的一个热点,现在的微处理器在功能、规模、工艺以及工作频率等性能上越来越优良。由于我国致力于处理器的研究比较晚,尽管其发展速度很快,在市场上仍然没有办法与外国芯片竞争,因此研制具有自主知识产权的处理器具有极其重要的意义。
1 非阻塞cache技术的引用
提高处理器性能可以从两方面进行:一方面提高指令并行性,同时执行多条不相关的指令。二通过提高主频,加快指令执行速度[1]。超标量处理器的研究就是从第一方面来提高处理器性能,采用流水线结构,通过增加取值、发射带宽以及复制执行部件实现多条指令的并行执行,而在引入的这些技术中对数据的使用要求比较高,因此需要高性能的cache来满足。
当访问数据cache的请求在未命中时,数据cache就会由于等待从低一级存储器中取回失效的数据而阻塞发射下一条访问存储器的请求,因此导致整个处理器的工作被阻塞。以上两种情况的存在,严重降低处理器的性能,最终导致blocking data cache成为高性能处理器的性能瓶颈。
非阻塞cache技术是一种通过减少缺失代价,挖掘处理器其他执行部件的操作和访问存储器的操作之间并行性的一种技术,对数据cache以及整个处理器系统的性能都有很大影响。因此研究高性能流水结构非阻塞数据cache对于提高处理器性能具有重要的意义。
2 非阻塞cache技术的研究
该技术的核心思想是指在访问cache缺失的情况下允许后续访问存储器的操作继续进行。当访问cache未命中时,一方面可以像其他级的cache发出请求,另外不阻止后续对cache的访问,对于命中和未命中都按照命中的方式进行处理,从而可以节省平均访问存储器的时间,提高处理器的性能[2]。非阻塞cache技术在哈佛结构的数据cache和指令cache都能够使用,本文主要针对数据cache进行介绍。
在该技术中常用的方法有:
1)采用缺失状态保持存储器(MSHR),该寄存器的作用可以用来跟踪和记录缺失的cache块的信息,一般包括:①缺失的cache块在内存的物理地址;②缺失块按特定的替换算法应该被存放到cache的什么地方;③所有访问这个cache块缺失的指令码。同时使用该寄存器可以查看是否发生了二次缺失的情况,即当前正在处理的缺失块是否有指令需要再次访问该cache块,如果发生则认为该cache块发生了二次缺失。因此在指令访问cache发生缺失,首先采用全相联的方式查找所有的MSHR入口,如果发现有匹配的MSHR入口,则说明发生了二次缺失,就不会给这个缺失的请求分配新的MSHR入口,而是仅仅给它在load miss queue和storemiss queue中分配一个入口。这样就达到了将多个缺失合并为一个缺失的目的,而且这种做法对于提高cache的命中率和减少总线接口单元的带宽压力也有好处。
当所有的MSHR寄存器被使用完,cache就会阻塞处理器。随着MSHR寄存器的入口数目的增加,cache的设计复杂度急速增加。研究结果表明,使cache取得最大性能的MSHR的最佳数目是4个[3]。
2)数据cache流水线划分。对cache的组织采用流水线结构可以提高数据cache的吞吐率,也是实现非阻塞cache技术的关键。图1的数据cache支持非阻塞机制,这是一个4路两端口的数据cache。数据cache具备4个TAG RAM,以及4个DATA RAM,整个数据cache的大小32KB,具有两端口的4级流水线,每个周期可以执行2个load/store操作,这个非阻塞cache支持4个cache挂起的缺失操作,保持流水线不阻塞[4]。其中,当store操作的数据是cache hit的情形,数据就会被写到cache的RAM中,即使两个store操作具备相同的地址,也不会也导致数据cache的流水线阻塞。当store操作的数据是cache-miss的情形,数据将会被写合并store data buffer,目的是为了减少总线的事务。合理的cache流水线划分对于cache指令的执行以及cache的控制复杂度有比较大的影响。

图1 一个4级流水结构的非阻塞cache结构Fig.1 Non-blocking cache structure of the four level pipeline structure
3)多体交叉编址存储器。图2-6是“龙芯”处理器中的非阻塞Cache结构示意图[5]。这是2路组相联的cache,每个cache的块是8个字。为了支持数据cache流水方式的读写访问流水操作,消除流水线中的结构冲突,将cache的每一路的TAG RAM和DATA RAM分成4个bank。但是对多体RAM会增加cache的功耗,嵌入式处理器中对功耗的要求比较高,所以这项技术的使用受到一些限制。
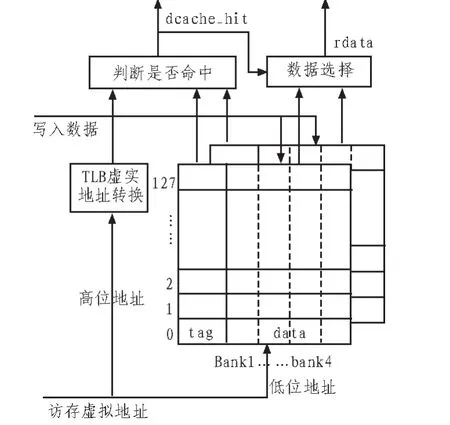
图2 非阻塞cache结构图Fig.2 Non-blocking cache structure
4)缺失情况下,读优先于写操作。对于支持写回的cache,若要进行换入,换出,就遵循先换入,再换出的原则,即等到取回的数据从内存回来后,再把写回缓冲器中的被cache淘汰的cache数据写回到内存。
3 非阻塞数据cache的流水线冲突解决策略
对cache采用合理的流水线划分是实现非阻塞cache技术的关键,因此对流水线技术中出现的数据相关的冲突解决策略是关键。为了充分发挥流水线性能,就需要有效地解决微处理器中流水线的冲突问题。相关是指引起指令流中的一条指令在指定的时钟周期内停滞(stall)执行的事件。相关的发生将会引起流水线的断流或延迟,降低微处理器的性能。在流水线中相关主要包括了数据相关、资源相关、控制相关3种冲突问题。其中数据相关是指后续指令的执行需要前面指令的数据,从而导致了后续指令在执行过程当中需要等待前面指令提供数据的停滞。资源相关是指多条指令在执行过程当中对相同资源的同时访问而造成的竞争造成指令周期的停滞。控制相关是由于转移指令的执行而产生的断流情况。针对这3种相关问题可以采用不同的方法解决,在流水线的设计中,一方面减少相关的发生,增长微处理器处理的连续指令长度,来充分发挥流水线的性能;另一方面合理安排流水线中各级的操作,降低指令断流引起的延迟,减少由于指令相关所带来的性能损失。
4 基于“龙腾”R2的非阻塞数据cache的设计
“龙腾”R2是由西北工业大学航空微电子中心在“十五”期间研制成功两款面向航空领域的嵌入式处理器。该处理器中的指令cache采用了三级流水线技术,增强了取指令的能力。IEU部件通过LSU部件把访问cache的存取指令发射给数据cache。LSU部件对数据cache共有16种类型的访问请求,如表1所示,把cache中将这些操作都归为读操作、写操作和cache控制指令3类。读操作每次读取1个字,存操作可以以单字节、双字节、三字节和字4种数据大小进行。当数据cache需要替换时,把整个cache行(32个字)写回内存。
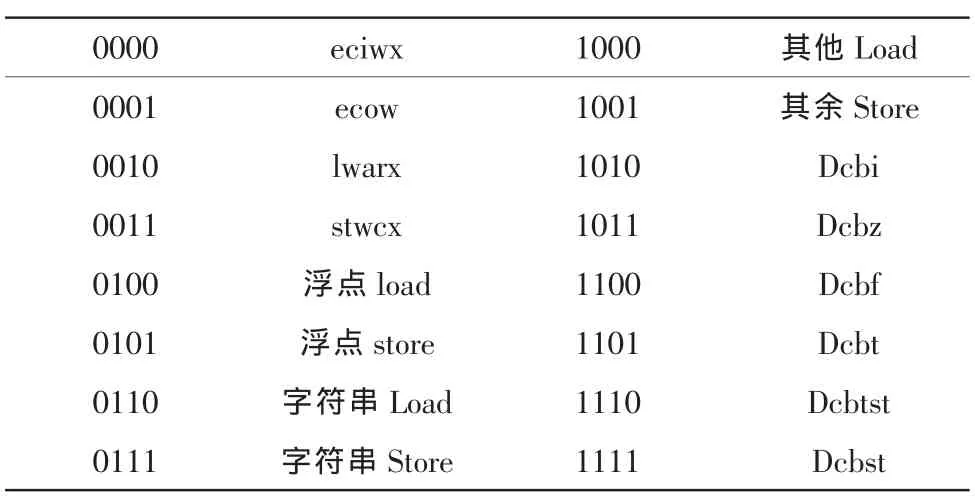
表1 数据cache相关指令Tab.1 data cache instruction
5 保持cache一致性策略
保持cache数据的一致性是cache设计中的一个关键问题。常见的解决cache一致性问题的方法有:监听协议、目录表法。高性能处理器目前最常用的方法是MESI监听协议,其性能在众多一致性协议中是最高的。MESI协议是一种采用写——无效方式的监听协议。它为每个cache块提供两个状态,用于当前该处所处的状态:修改态、专有态、共享态或者无效态当中的一个状态。在龙腾R2中采用了MESI[6]协议的一个子集,忽略了共享态S(shared)状态,即MEI一致性协议。表2描述了MEI的状态。

表2 MEI状态定义Tab.2 MEI state defintion
在“龙腾”R2中实现了对内存一致性协议的检测。MEI的状态转移与当前的MEI状态以及内存存储标志WIM都有关系。在非阻塞数据cache中不支持写操作缺失下的写分配(write-allocated)[4], 数据 cache为写回 cache, 所以在新的cache一致性协议中就没有无效态到修改态之间的状态变迁,这样新的数据cache的就是写回且不支持写分配的数据cache。
图3是在非阻塞cache中采用的新的一致性协议,是在原来的MEI的基础上增加了一个已分配的状态,这个状态用来表明在缺失的情况下需要使用替换算法为这个cache行分配一个空位,用来防止后面的指令继续访问该缺失的cache行。使用“已分配”这个状态来表明这一路的cache块是处于从内存加载的路上,以防发生错误。
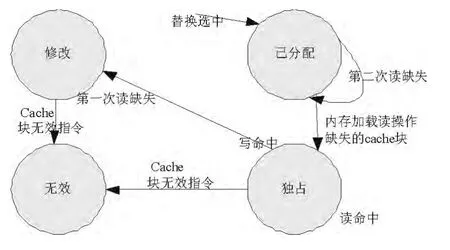
图3 cache一致性状态转换图Fig.3 Cache coherency policy state transition diagrams
6 cache的替换策略
在cache设计中,采用效率较高的替换算法对于提高cache的性能非常重要,多种替换算法一直被深入的研究,但是常用的也仅有LRU和PLRU等少数几种。LRU(leastrecently used)算法依据程序访问的时间局部性原理,每次替换最近最少被使用的cache块。随着cache相联度的增大,PLRU是LRU算法的一种近似实现,它使用一个二叉树结构保存cache块的历史访问顺序。Hassan Ghasemzadeh等人发现PLRU算法在一些情况下会做出错误决定,并认为PLRU算法的最大缺点是二叉树结构的顶层节点不能包含底部叶子节点的足够信息[7],并提出了MPLRU算法。在“龙腾”R2中采用了提出一种新的替换算法,即PLRU-0替换算法。Pseudo-LRU(PLRU)的原理:使用一个二叉树结构保存cache块的历史访问顺序信息。它相对于LRU的优点是存储信息只需要3位,节省了存储空间,而堆栈实现的LRU则需要8位。
7 数据cache验证结果
对cache功能的验证采用了Synopsys公司的VCS仿真平台和Vera验证平台表3列出了数据cache的验证结果。

表3 数据cache功能验证覆盖率Tab.3 data cache functional verification coverage
8 结论
文中研究了非阻塞cache技术缺失下如何命中的原理,讨论了在流水线结构中采用非阻塞cache技术提高cache的命中率,减少缺失代价从而提高处理器的性能,通过在“龙腾”R2中采用该技术的功能验证说明了该技术的可行性。
[1]黄海林,徐彤,范东睿.嵌入式处理器中降低Cache缺失代价设计方法研究[J].小型微型计算机系统,2006(11):2077-2081.HUANG Hai-lin,XU Tong,FAN Dong-rui.Research on reducing cachemiss penalty of embedded processor[J].Small Microcomputer System,2006(11):2077-2081.
[2]胡孔阳,陈鹏,桑红石.多线程非阻塞cache设计[J].微电子学与计算机,2012(5):144-147.HU Kong-yang,CHEN Peng,SANG Hong-shi.Design of Amultithreading non-blocking cache[J].Microelectronics and Computer,2012(5):144-147.
[3]Kroft D.Lockup-free instruction fetch/prefetch Cache organization[J].In Proc of the 8th Annual Int.Symp.On Computer Architecture,1981:81-87.
[4]Hayakawa F,okano H,Suga A.A8-WAY VLIW Embedded Multimedia Processor with Advanced Cache Mechanism[C]//IEEE,2002:213-216.
[5]PowerPC Microprocessor Family:The Programming Environ ments For 32-BitMicroprocessors[S].Rev.2,Motorola Inc,Dec.2001.
[6]Jouppi N P.CacheWrite Policies and Performance[C]//08-S4-7495/93 1993 IEEE.
[7]Ghasemzadeh H,Mazrouee S,Kakoee M R.Modified Pseudo LRU Replacement Algorithm:Proceedings of the 13th Annual IEEE International Symposium and Workshop on Engineering of Computer Based Systems[C].IEEE [S.l.]:[s.n.].2006:371-376.
[8]刘铎,黄晓燕.基于Direct3D技术的VTS雷达PPI显示优化设计[J].电子科技,2014(5):5-7,11.LIU Duo,HUANG Xiao-yan.Optimization design of VTS radar PPI display based on Direct3D Technology[J].Electronic Science and Technology,2014(5):5-7,11.
