基于改进型双门限语音端点检测算法的研究
2015-01-25薛胜尧
薛胜尧
(河海大学 能源与电气学院,江苏 南京 211000)
语音端点检测的目的是从包含语音的一段信号中确定出语音的起点及结束点,它是语音信号处理中的一个基础步骤。有效的端点检测能有效辅助语音识别、语音降噪等语音处理操作,提高语音信号质量。语音端点检测的成败,将直接影响着后续工作的正确率乃至整个语音识别系统的成败。所以语音端点检测的研究一直是学者们研究的热点之一。
端点检测的常用方法有:能量阈值、基音检测、频谱分析、倒谱分析及LPC预测[1]等。其中基于能量和过零率的双门限判决法最为常用。在许多语音信号处理任务中需要判断,一段输入信号中哪些是语音段,哪些是无声段,哪些是噪声。在一些语音识别或低速语音编解码器应用中,对于已经判别为语音段的部分,还需进一步判断清音和浊音。这些问题可以称为有声或无声判决,以及更细致的无声(S)、清音(U)、浊音(V)判决[2]。能够实现这些判决的依据在于,不同性质语音的各种短时参数具有不同的概率密度函数,以及相邻的若干帧语音具有一致的语音特性,不会在无声,清音和浊音之间随意跳变。文章比较了利用短时能量和短时平均过零率进行端点检测的传统方法和改进后大方法,并在Matlab中编程仿真得出了预期结果。
1 语音信号的短时能量分析
语音信号的能量随时间变化而变化的重要参数,一般清音部分的能量比浊音部分的能量小。信号的短时能量分析给出了反应这些幅度变化的一个合适的描述方法。对于信号x(n),第n帧语音信号的短时能量定义如下:
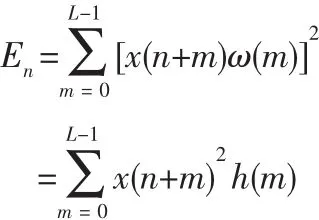
式中,h(n)=ω(n)2,ω(n)表示选取的窗函数,En表示在信号的第n帧语音信号的短时能量,L为帧长。可以看出,短时能量可以看作语音信号的平方经过一个线性滤波器的输出[3],该线性滤波器的单位冲击响应为h(n),如图1所示。
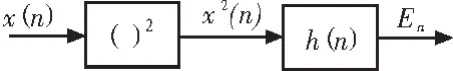
图1 语音信号的短时平均能量实现框图Fig.1 Short-time average energy of the speech signal realization diagram
冲激响应h(n)的选择,或者说窗函数的选择决定了短时能量表示方法的特点。为反应窗函数选择对短时能量的影响,假设式中 的h(n)非常长,且为恒定幅度,那么En随时间的变化将很小,这样的窗就等效为很窄的低通滤波器。h(n)对x(n)2的平滑作用较显著,无法反映语音的时变特性。反之,若 h(n)序列长度N过小,那么等效窗不能提供足够的平滑,以至于语音振幅瞬时变化的许多细节仍被保留,从而看不出振幅包络的变化规律。通常N的选择与语音的基音周期相联系,一般要求窗长为几个基音周期的数量级。
短时能量主要用于区分清音和浊音,因为浊音比清音的能量大得多;其次可以用短时能量对有声段和无声段进行判定,对声母和韵母分界,以及对连字分界等。在语音识别系统中,短时能量一般也作为特征中的一维参数来表示语音信号能量的大小和超音段信息[4]。
图2为语句“一、二、三、四、五”的语言波形图及其短时能量谱。

图2 语句“一、二、三、四、五”的语言波形图及其短时能量谱Fig.2 Statement"one,two,three,four,five"the speech waveform diagram and its short-term energy spectrum
2 短时平均过零率
短时平均过零率是语音信号时域分析中的一种特征参数。它是指每帧内信号通过零值的次数。对于连续语音信号,可以考察其时域波形通过时间轴的情况。对于离散信号,短时平均过零率实际就是信号采样点符号变化的次数。短时平均过零率仍可以在一定程度上反映其频谱性质,可以通过短时平均过零率获得谱特性的一种粗略估计。第n帧语音的短时平均过零率的公式为:
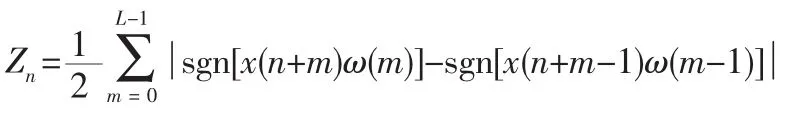
其中sgn为符号函数,帧长为L。
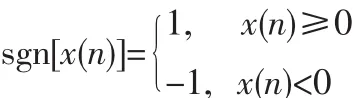
图3给出了短时平均过零率的计算过程。

图3 短时平均过零率的计算过程Fig.3 Calculation time average zero-crossing rate
图4 给出了语音“一、二、三、四、五"的短时过零率图。
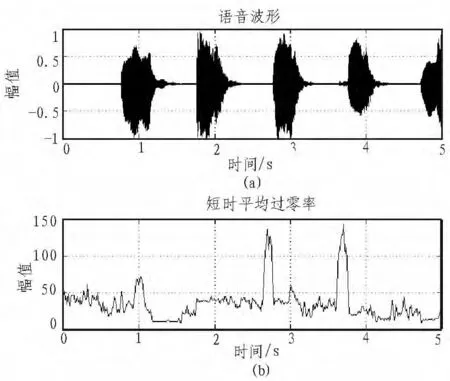
图4 短时过零率Fig.4 Short-term zero rate
通过分析语音信号发现,发浊音时,尽管声道有若干共振峰,但由于声门波引起谱的高频跌落,所以其语言能量约集中在3 kHz以下;而发清音时,多数能量出现在较高频率上。从频率的角度来说,当频率较高时,其过零率应当较高,相反频率较低时,其过零率较低。在语音发音中,短时过零率便可以辨别出浊音信号和清音信号。
由于人说话时是清浊音想结合的,因此利用短时过零率还可以从背景噪声中找出语音信号,可用于判断寂静无话段与有话段的去点和终点位置。在背景噪声较小时,用平均能量识别较为有效;而在背景噪声较大时,用短时平均过零率识别较为有效[5]。当混入不同类型的噪声信号时,往往不能光凭借短时能量判断出语音的端点。将短时过零率和短时能量结合起来应用的双门限法能较好的判断出语音端点的所在。
3 传统的双门限检测方法
双门限法最初是基于短时平均能量和短时平均过零率而提出的,其原理是汉语的韵母中有元音,能量较大,所以可以从短时平均能量找出韵母,而声母是辅音,它们的频率较高,相应的短时平均过零率较大,所以用这两个特点找出声母和韵母,等于找出完整的汉语音节,双门限是使用二级判决来实现的。首先为短时能量和过零率分别确定两个门限,一个是较低的门限数值,对信号的变化比较敏感,很容易超过;另一个是比较高的门限,数值较大。低门限被超过未必是语音的开始,有可能是很短的噪声引起的,高门限被超过并且接下来的自定义时间段内的语音超过低门限,意味着信号开始[6]。
此时整个端点检测可分为四段:静音段、过渡段、语音段、结束。实验时使用一个变量Statue表示当前状态。在处于静音段时,如果能量或过零率超过低门限,就开始标记起始点,进入过渡段。过渡段当两个参数值都回落到低门限以下,就将当前状态恢复到静音状态。而如果过渡段中两个参数中的任一个超过高门限,即被认为进入语音段。处于语音段时,如果两参数降低到门限以下,而且总的计时长度小于最短时间门限,则认为是一段噪音,否则就继续扫描以后的语音数据,当其两个参数都降至门限以下而总计时长大于最短时间门限则标记语音结束端点,注明此处为一段语音,并从新进入静音段[6-7]。
4 改进型双门限法
4.1 噪声的影响
从上面的分析可以知道,在背景噪声较小时,短时过零率在有音段时的幅值较大。但是如果我们适当的叠加噪声后,情况就会变得不一样了。如果我们叠加一个较大的高斯白噪声,得到一个信噪比较低的语音段,并作短时过零率分析,我们将会得到一个完全不同的结果。如图5是一段语音“一、二、三、四、五”加噪后的波形图和短时过零率图,在叠加高斯白噪声后,它的信噪比为0 db。
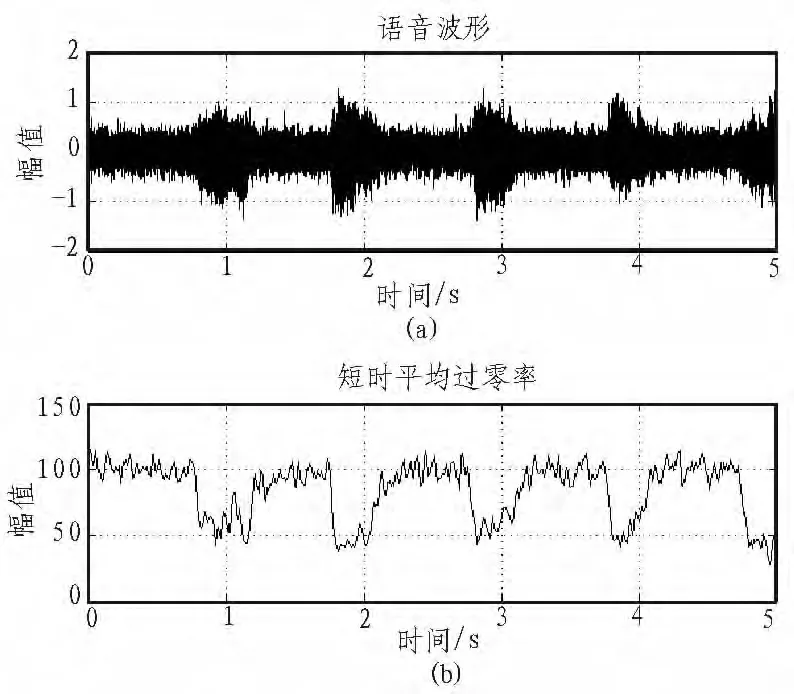
图5 加噪后的语音波形图和短时过零率Fig.5 Voice waveforms and short-term zero rate after adding noise
现在附加上原来纯语音阶段的短时过零率和波形图,如图6所示。
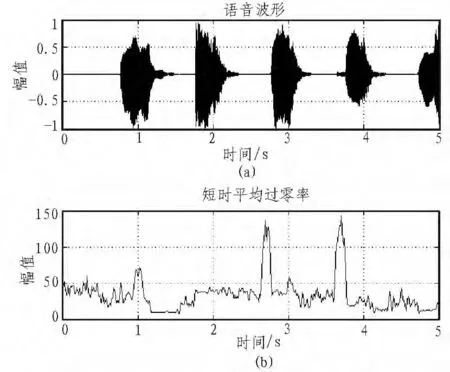
图6 纯语音的短时过零率和波形图Fig.6 Pure voice’s short-term zero rate and waveform
从图中分析可知,短时过零率已不再是在语音的声母和韵母处有较大的过零率,在静音区有较小的过零率;而现在的情况正好相反,在无话段的噪声处有较大的过零率,比声母、韵母都要大。这实际上很好理解,在高斯白噪声声中,同样存在着丰富的高频成分,它的过零率显然是高的,要比韵母高很多,所以会在韵母的部分造成一个凹形的区域。而噪声的过零率与声母相比有时会大于声母的,有时会小于它,这和噪声的短时特性有关。但一般而言,对于处理低信噪比的语音短时,短时过零率都处于以上情况中。所以当我们寻找有音段时,不再寻找过零率大于某一阈值,而是小于某一阈值。并且我们在这里对于短时过零率设置阈值时,我们只设置一个阈值。因为短时过零率不像短时能量,其有音段的值和过度段的值相差不大,设置多个阈值,对于判定并不能起到很好的作用,反而降低计算速度。
4.2 低信噪比时的问题
在低信噪比时的,由于噪声的能量较大,能量曲线和短时过零率曲线的起伏较大,故阈值的设置不能太低。所以当我们说话吐字太清时,能量较低,会出现漏判的情况。为了解决这个问题,引入中值滤波器对于能量曲线和短时过零率曲线进行平滑处理。在这里采用一个滑动窗口,其采样点数一般在5个点,然后选出其中值。中值平滑的优点就在于既可以有效地取出少量的野点,又不会破坏数据在两个平滑段之间的阶跃性变化。如图7,8就像我们展示了,中值滤波前后的短时能量和短时过零率图谱。
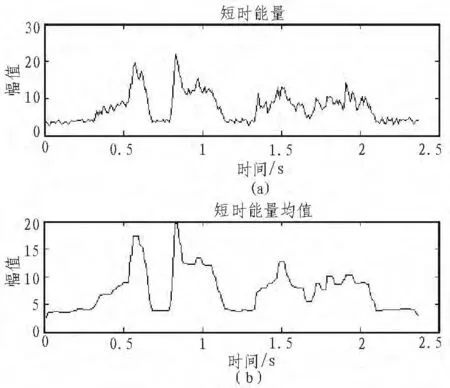
图7 中值滤波前后的短时能量图谱Fig.7 Short-term energy spectra before and after median filtering
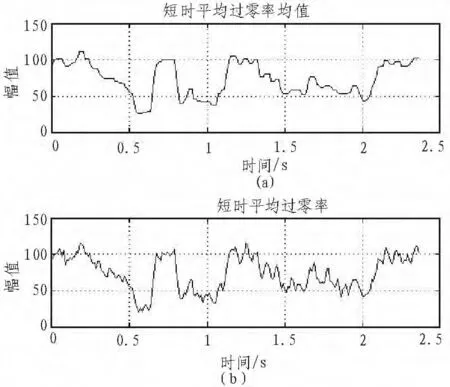
图8 中值滤波前后的短时过零率图谱Fig.8 Short-term zero rate patterns before and after median filtering
4.3 引入语音结束最小长度设定
为了更符合人说话时的语言特性,引入语音段结束最小长度。这是为了考虑人发音是单词之间的静音区会有一个最小长度表示发音间的停顿,就是在小于阈值时满足一个最小长度才判断该语音结束,实际上相当于延长了语音尾音的长度。这样做可以减少对于静音区的误判断,减轻计算量。
总的来说,对于语音的判决我们设定3个门限。T1和T2代表能量阈值,T3代表过零率阈值。首先对于背景噪声算出它的能量统计特性,定出能量高低门限、短时过零率门限,利用能量门限来确定语音信号的初始起止点,然后根据过零率精确得出起止点。在本文的实验中,对于前十帧的信号进行短时平均能量和过零率的计算,然后根据算得的值设定门限。根据能量门限算得一初始起点N1,其能量值超过T1。逐次比较以后每帧的平均幅度是否超过T2和低于T3,直到不满足则判断终止,记为N2。然后判断从N1到N2是否满足最小语音段长度,若满足则在N2的基础上加上n个采样点以表示语音结束最小长度。再从N2+n点处开始重新判断。若N1到N2的长度不满足,则原N1不作为初始起点,改记下一个平均幅度超过了低能量门限的帧为N1,依此类推。在找到第一个平均幅度超过高能量的帧时停止比较。
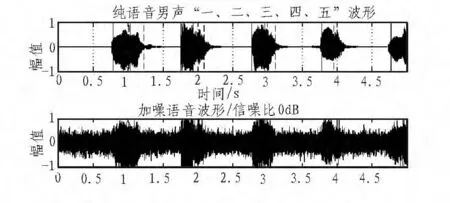
图9 传统型方法Fig.9 Traditional method
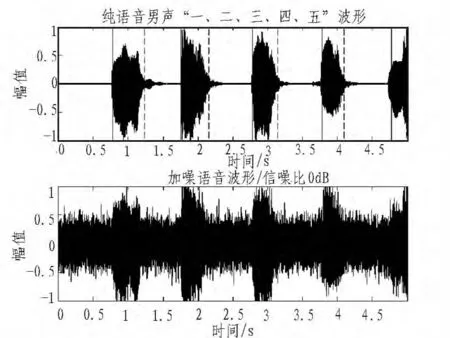
图10 改进型方法Fig.10 Improved method
5 实验
此处对于一段语音“一、二、三、四、五”进行分析,并对其加入高斯白噪声使其信噪比达到0db,其采样频率为8 kHz,其分帧长度为200个采样点,帧间重叠80。这里我们用传统的采样方法和改进行的方法进行对比。分别如图9、图10所示。在图9、10中,统一以实黑纵线表示语音段的开始,以虚黑纵线表示语音段的结束。
6 结论
从图中可以看出,传统形的方法出现了严重的错判和漏判情况。这种方法只能判断出一、三、五这3个读音的端点,其判断的准确率只有60%。在改进型的方法中一二三四五这5个读音的端点均得到了很好的判断,准确率达到了100%。本研究结果解决了在低信噪比情况下传统双门限法无法准确判断语音端点的问题,在此改进型方法下,语音端点判断的准确率大幅提高。
[1]赵力.语音信号处理[M].北京:机械工业出版社,2010.
[2]韩纪庆,张磊,郑铁然.语音信号处理[M].北京:清华大学出版社,2004.
[3]Gerven S,Xie Fei.A comparative study of speech detection methods[C]//EUROSPEECH,Greece,1997:1015-1020.
[4]夏敏磊,语音端点检测技术研究[D].杭州:浙江大学,2005.
[5]陆东钰,周萍.基于双门限算法的语音端点检测和声韵母分离研究[J],桂林电子科技大学学报,2011,32(6):480-484.LU Dong-yu,ZHOU Ping.Dual threshold endpoint detection algorithm vowel harmony separation [J].Guilin University of Electronic Technology,2011,32(6):480-484.
[6]路青起,白燕燕,基于双门限两级判决的语音端点检测方法[J].电子科技,2012,25(1):13-19.LU Qing-qi,BAI Yan-yan.Voice endpoint detection method based on double threshold levels judgment[J].Electronic Technology,2012,25(1):13-19.
[7]邓艳容,景新辛,杨海燕,等.语音端点检测研究[J].计算机系统应用,2012,21(6):240-243.DENG Yan-rong,JIANG Xin-xin,YANG Hai-yan,et al.Voice detection[J].Computer Systems&Applications,2012,21(6):240-243.
