HybridFA:一种基于统计的AC自动机空间优化技术
2015-01-06熊刚何慧敏于静刘燕兵郭莉
熊刚,何慧敏,于静,刘燕兵,郭莉
(1. 中国科学院 信息工程研究所,北京 100093;2. 中国移动(深圳)有限公司,深圳 518031)
1 引言
多模式串匹配是计算机科学领域最经典的问题之一,目的是在任意字符串文本中找出已知的一组特定字符串集合出现的所有位置。网络内容安全处理主要采用串匹配算法对网络分组的内容负载进行检测、分析和过滤。典型的网络内容安全应用软件的入侵检测/防御系统和反病毒反垃圾邮件检测系统都采用串匹配算法来检测恶意数据[1~3]。基于自动机的串匹配算法是多模式串匹配采用的主要研究方法之一,它以自动机作为数据结构,在搜索过程中通过搜索文本中自动机所能识别的语言来实现匹配,该类方法性能相对稳定,因而在实际系统中被广泛使用。但该类方法空间开销较大,匹配速度较慢。
Aho-Corasick (AC) 自动机[4]是最经典、实际应用最广的自动机之一,开源病毒检测系统 ClamAV和开源入侵检测系统Snort均使用AC自动机作为其基本的数据结构。基于AC自动机的串匹配算法称为AC算法,其思想是使用Trie树存储所有的模式串,然后从Trie树的根节点开始层次遍历,构造节点间的后缀链(supply link)[5]。在匹配过程中,若当前状态无法识别输入字符时,就沿着后缀链回溯(也称为失效转移),直到能够识别该字符的状态为止。该算法可以在O(n)时间复杂度内找到文本中的所有目标模式(n为给定文本长度),而与模式集合的规模无关。但其突出的问题是数据流在匹配时往往需要进行多次回溯才能跳转到有效状态继续匹配,严重影响了匹配速度。
高级AC自动机是在AC自动机的基础上,将后缀链进行改进,直接指向当前状态的后继状态。也就是说,所有状态对于字母表的每一个字符都有相应的转移,称为一个完全的自动机。在匹配过程中无需沿着后缀链回溯,而是直接跳转到它的后继状态,因而匹配速度更快。但高级AC自动机的空间复杂度为O(|P| |Σ|)(其中P是模式串集合,Σ是字符集),存在巨大的空间浪费。
为解决自动机因为存储空间引发的性能瓶颈,国内外学者提出了许多经典的压缩方案。1984年Dencker等[6]最早提出了一种行压缩方法,使状态转移表中每一行只存储非空的转移边对应的读入字符和下一跳状态,但该方法仅对稀疏的状态转移表具有良好的压缩效果,当状态转移表相对稠密时,该方法的效果变差,甚至会超过压缩前的存储空间。文献[7~9]使用一个一维数组重叠排列状态转移表中所有的行,但必须保证各行的非空元素不得相互冲突,另外用2个数组分别存储每一行的偏移位置和一维数组中每个元素所属的行。该方法具有较好的压缩效果,并且可以达到O(1)的状态转移速度,但处理过程中峰值内存太大,导致其不能处理大规模的串匹配问题。此外,刘燕兵等[10]利用suffix-trie和双数组相结合的数据结构来存储模式串,该方法在压缩存储空间的同时也保持了快速的访问速度。实验表明该方法比较适合关键词规模为10 000~20 000的应用环境。
上述自动机压缩方法的基本思想大都是针对自动机的状态转移表,删除以空转移为主的冗余状态转移边,只保存有用的信息,在搜索过程中通过计算来查找下一跳状态。此类方法都不能适用于无空转移状态的高级AC自动机的压缩。而高级AC自动机空间开销大的主要原因是它将每个节点都完全化,而在实际应用系统中并不是所有节点都具有较高的访问频率,将访问频率相对较低的节点完全化会占用大量存储空间,而不会带来匹配速度的显著提升。本文将充分分析待处理数据流量的特征,提出基于数据访问特征的混合自动机构建算法HybridAC。根据不同的数据流特征,分别研究了按访问频率完全化和按层次完全化的2种混合自动机的构建算法HybridAC_1和HybridAC_2,并进一步综合考虑数据流量的特征,结合上述2种方法的优点,提出改进算法 HybridAC_3。在 Snort、 ClamAV、URL等真实数据集上的实验表明,本算法在保证匹配速度的同时,大大降低了高级AC自动机的存储空间。
2 算法设计
2.1 算法提出的依据
AC自动机作为最经典、实际应用最广的自动机之一,广泛应用于入侵检测/防御系统和反病毒反垃圾邮件检测系统。根据自动机构造的程度,AC自动机可以分为基本的AC自动机和高级AC自动机(完全化的AC自动机)。基本的AC自动机只保存模式串的Trie结构和每个节点的回溯状态,在搜索过程中,如果状态转移不成功,则需要回溯;高级AC自动机对于字符集中的每个字符,所有的状态都有相应的转移,在搜索过程中不需要回溯,因而匹配速度更快。但在高级AC算法中,自动机的所有状态节点都被完全化,每个节点具有相同的地位。然而在实际应用中,自动机的每个节点的访问频率各不相同,把一个数据访问频率为零或者接近于零的节点完全化,存在很大的空间浪费。
数据流量对自动机不同节点的访问频率各不相同,下面以开源入侵检测系统Snort中的模式串规则为例,分析数据流量对自动机各状态节点的访问特征,本实验中待扫描的文本数据来自MIT公开的一组真实的网络数据,所采用的实验方法如下。
1) 按频率统计方法
统计高级AC自动机各个节点的访问频率,按照访问频率从大到小对自动机的各个节点排序,依次对访问频率累计求和,分别统计每个频率界限内的节点数目。统计结果如表1所示,可见,前408个节点的累计访问频率已经达到91%,节点数目所占比例不超过 1%;前3% 的节点累计访问频率达到98%。

表1 高级AC自动机各节点的访问频率统计
2) 按层次统计方法
把高级AC自动机的Trie树结构图的根节点标记为第一层节点,按照广度优先搜索的方式,根节点的后续未标记节点为第2层节点,以此类推。分别统计各层节点的访问频率,实验结果如表2所示。可以看出,随着层次的增大,每层节点的访问频率逐渐降低。根据统计,前3层节点的累计访问频率已经超过95%,第8层及以后的节点访问频率几乎为零。

表2 高级AC自动机各层访问频率统计
统计结果表明,大部分数据流只访问小部分节点,大多数节点几乎未被访问过;其次,数据流量倾向于访问靠近根节点的低层节点,离根节点较远的高层节点的访问频率接近于0。根据数据流量的这些显著特征,本文将把访问频率高的节点和层次完全化,其余节点只保存基本的Trie树结构和回溯状态。根据表1和表2的统计分析,需要完全化的节点比例很小,所以该算法可以大幅度降低存储空间。
2.2 HybridFA算法的基本思想
HybridFA算法是根据数据流量的访问特征,分别按访问频率完全化(HybridFA_1算法)和按层次完全化(HybridFA_2算法)2种方式来改善高级AC自动机的空间浪费问题。按访问频率完全化是根据大部分数据流量只访问小部分节点的特征,把访问频率高的节点完全化;按层次完全化则根据数据流量倾向于访问靠近根节点的低层节点的特征,把低层节点完全化。2种算法的流程如图1所示。

图1 基于访问层次完全化和访问频率完全化构建HybridFA的流程
2.3 HybridFA算法的设计与实现
HybridFA算法在数据训练阶段统计各状态节点的访问频率,确定完全化的访问频率界限和层次界限,然后根据按访问频率完全化和按层次完全化2种算法分别构建由完全化节点和不完全节点混合构成的自动机HybridFA,并实现数据扫描。
2.3.1 数据训练
数据训练阶段的主要任务是分析数据流量的访问特征,统计自动机各状态节点的访问频率,分别确定按访问频率完全化和按访问层次完全化2种方法所需要完全化的节点。具体步骤如下。
Step1对模式串规则构造高级AC自动机。首先对模式串规则构建Trie树,然后为每个节点计算其回溯状态,并把所有节点都完全化,也就是使所有节点包含对任意字符的下一跳状态,至此完成对高级AC自动机的构建。
Step2扫描训练数据,在高级AC自动机对数据进行匹配的过程中,统计自动机每个节点的访问频率。
Step3按照访问频率的递减顺序,对自动机的每个节点排序,并对排序后节点的访问频率累计求和。选择合适的访问频率作为访问频率界限fre,把在访问频率界限范围内的所有节点标记为Hybrid_1算法需要完全化的节点,其他节点仍按照AC自动机的构造方式保留失效转移。

图2 按照访问频率完全化构建HybridFA自动机示意
Step4广度优先遍历高级AC自动机,从根节点开始,按层次递增顺序统计每层节点的累计访问频率,并计算累计层次的访问频率之和占所有节点访问频率之和的比值,选择合适的比值作为访问层次界限level,把层次界限范围内的所有节点标记为Hybrid_2算法需要完全化的节点,其他节点仍保存可识别字符的跳转和失效转移。
2.3.2 按访问频率完全化算法
按访问频率完全化的方法在预处理过程中,首先对模式串规则构建Trie树,然后为每个节点计算其回溯状态,并把在访问频率界限fre范围内的节点完全化,即对任意字符,计算该节点的下一跳状态,称此算法为HybridAC_1。图2是按照访问频率完全化构建的混合自动机示意。编号为{0,1,2,3}的灰色节点表示被完全化的节点,节点上的表格表示该节点存储的对任意字符的跳转状态;标号为{4,5,6,7}的白色节点表示未被完全化的节点,节点上的表格表示该节点存储的可识别字符的跳转和失效转移。图3是该自动机的构建过程的伪代码(其中Trie(P)采用文献[11]中的Trie(P)算法)。
图4为HybridFA算法扫描过程的伪代码,在扫描过程中,逐个读入文本字符,此时可能出现 2种情况。
1) 如果当前状态Current为完全化的状态,则根据当前读入字符c,直接从状态转移表中查找其对应的下一跳状态GoTo(Current,c),并令Current←GoTo(Current,c)。
2) 如果当前状态Current为未完全化的状态,首先查找当前状态的状态转移表,查看GoTo(Current,c)是否为NULL,如果GoTo(Current, c) ≠ NULL,则 令Current ← GoTo(Current, c) , 如 果GoTo(Current, c) = NULL,则根据其回溯状态回溯,直到 找 到Current使GoTo(Current,c)≠ NULL , 令Current← GoTo(Current,c)。

图3 HybridFA自动机构建过程伪代码

图4 HybridFA算法扫描过程伪代码
处理完当前读入字符,判断当前状态Current是否为终止状态,如果为终止状态则输出所有的匹配结果,否则,读入下一个文本字符,继续对文本进行扫描。
2.3.3 按访问层次完全化算法
按访问层次完全化的算法在预处理过程中,首先对模式串规则构建Trie树,然后为每个节点计算其回溯状态,然后把在层次界限 level范围内所有层的节点完全化,即对任意字符,计算该节点的下一跳状态。其中,根节点的level为0,level值随着树的深度变化逐层增加 1,称此算法为HybridAC_2。图 5是按照访问层次完全化生成的HybridFA自动机的示意。其中自动机的第1、2、3层包含的全部节点被完全化,其他层的节点仅保留可识别字符的跳转和失效转移。HybridAC_2算法在构建自动机过程中,除了选择完全化的节点不同,其他过程与 HybridFA_1算法相同,而数据扫描过程与HybridFA_1算法一致。
2.3.4 综合考虑数据流量特征的完全化算法
根据2.1节对数据流量的统计分析,得到数据流量的2种访问特征:大部分的数据只访问小部分的节点;数据倾向于访问靠近根节点的低层节点。据此,上文分别按访问频率完全化和按层次完全化2种方法构建符合数据流量访问特征的自动机。按频率完全化的方法,完全化的最小单位为节点,对数据流量的统计更精确,所以需要完全化的节点相对较少,自动机所需要存储空间越少;但是当数据流量有较大变化时,当前访问频率高的节点可能变成未完全化的节点,从而会导致匹配速度下降。按层次完全化的方法,完全化靠近根节点的所有低层节点,当数据流量发生变化时,尽管访问频率高的节点可能发生变化,但大部分高访问频率节点仍偏向集中在低层节点,所以对匹配速度的影响相对较小;但是当部分访问频率高的节点出现在较高层次时,由于完全化的最小单位为一层,若想进一步提高匹配速度,需增多完全化的层数。因此,在提高相同匹配速度时,基于访问层次完全化算法增加的存储开销将超过基于访问频率完全化算法。
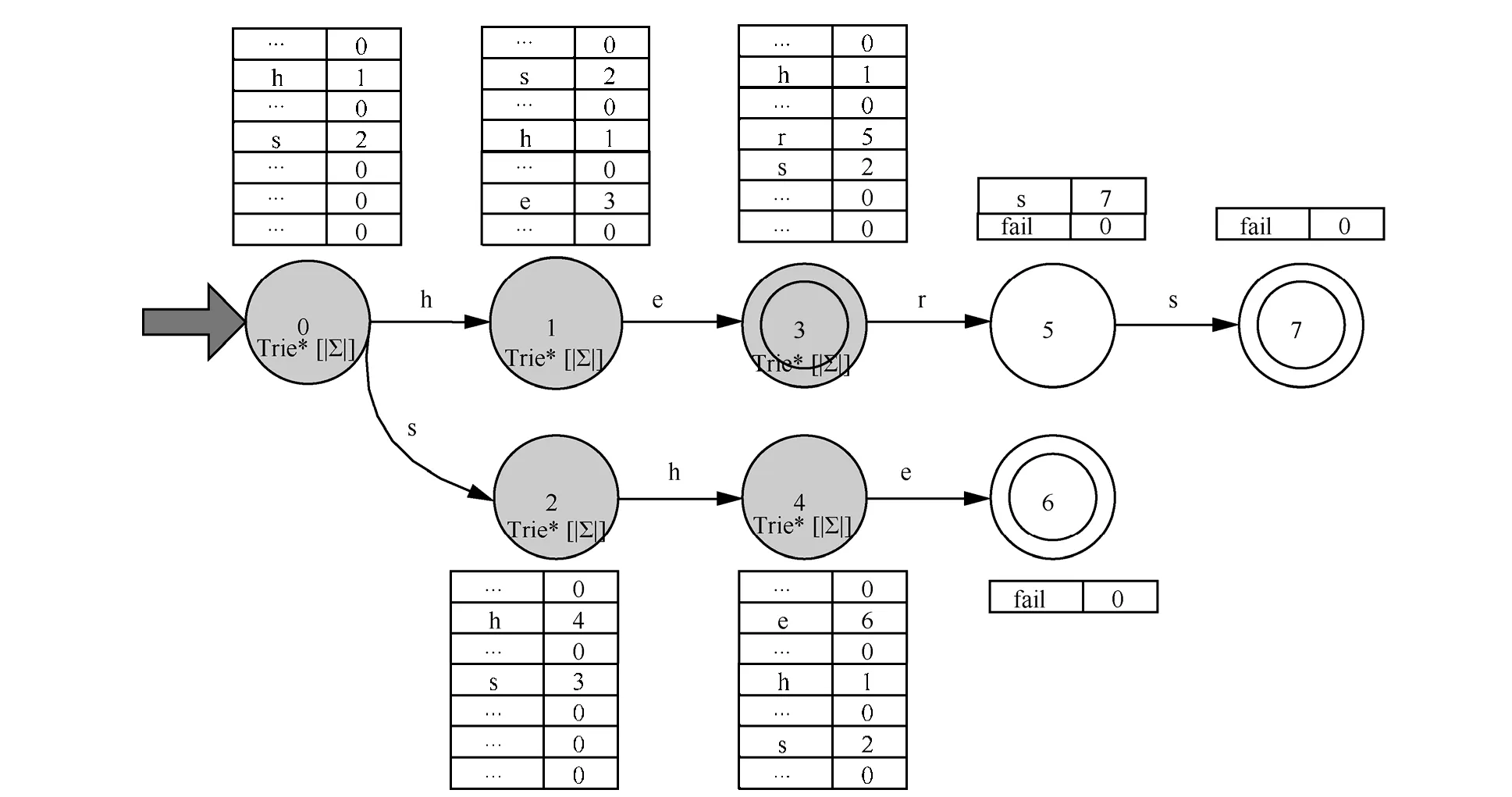
图5 按照层次完全化构建HybridFA自动机示意
综合考虑数据流量的特征,结合按访问频率完全化和按层次完全化2种方法的特点,本节提出进一步的改进方案。首先将靠近根节点的低层节点完全化,再把层次相对较高且访问频率较高的节点也完全化,如此便不会陷入因某条模式串的命中率较高而使完全化的层次增多或者因数据流量发生变化而使匹配速度大幅度下降的问题,称这种构建自动机的算法为HybridAC_3。构建HybridAC_3的具体步骤如下。
Step1通过扫描训练数据并统计自动机中每个节点的访问频率,确定需要完全化的访问层次界限level和访问频率界限fre,并把在level范围内所有层次的节点标记为需要完全化的节点,另外标记在fre范围内而不在level范围内的节点为需要完全化的节点。
Step2确定完全化节点后,自动机构建过程和数据扫描过程与HybridFA_1算法相同。
2.4 空间复杂度分析
自动机存储空间的大小与状态转移边的数目成正比。由于按频率完全化和按照层次完全化的方法根据数据流量的特点,仅需要完全化一部分状态节点,所以与高级AC算法相比,二者的状态转移边更少,存储空间更小。具体存储空间的大小与完全化的节点数目相关。下面分析完全化的节点比率与所需存储空间的关系。
已知有限字符集合记作Σ(本文数据集中字符集大小|Σ|均为256),构建的自动机中所有状态集合记作M,被完全化的节点(状态)占所有节点(状态)的比率记作k(0<k<1)。当完全化比率为k时,所构建自动机存储空间的上限占高级 AC自动机存储空间的比率为

3 实验结果与分析
本节将通过一系列实验对本文提出的HybridFA算法的性能进行系统验证,3种HybridFA算法的存储空间(MB)和匹配速度(Mbit/s)将与高级AC算法在3个真实数据集上进行比较。
1) ClamAV规则+MIT数据
Clam Antivirus[12]是一个开源的防病毒检测软件,病毒库特征不断更新,抽取了 ClamWin Free AntiVirus 0.90.1版本中的部分精确模式串作为本实验的规则。待扫描的文本数据来自MIT公开的一组真实的网络数据[13],它的原始目的是用来对网络入侵检测系统进行评估,使用 mit_1999_training_week1_friday_inside.dat(约62.7 MB)作为待扫描文本,选取部分(约32.4 MB)作为训练数据,剩余部分作为测试数据。
2) Snort规则+MIT数据
Snort[14]是一套开源代码的网络入侵预防软件与网络入侵检测软件,规则库定期发布。抽取了2009.06版本中的部分精确模式串作为本实验的规则。待扫描的文本数据与ClamAV相同。
3) URL规则+URL数据
从骨干路由器上采集了约100 GB的URL数据,对采集数据去重后,得到 2.60 GB、约 2 000万条URL。从中随机抽取了50 000条URL(URL长度大于4)作为规则,抽取了约2.3 GB作为待扫描文本,其中1.09 GB作为训练数据,剩余部分作为测试数据。
3.1 实验结果与分析
3.1.1 数据流量访问特征
按照 2.1节中数据流量的统计方法,分别统计Snort规则、ClamAV规则和URL规则上高级AC自动机不同访问频率下包含的节点数目所占的百分率(如图6所示)和各层节点下的累计访问频率(如图7所示)。由图6可见,在98%的访问频率界限下,数据流仅访问了基于Snort规则的高级AC自动机不足2.5%的节点,ClamAV规则对应节点的累计访问比率不足 1%,而 URL规则上的相应比例仅为0.51%。其次,数据流量倾向于访问靠近根节点的低层节点,Snort规则前 3层的节点累计访问频率为88.9%,ClamAV规则为89.3%,URL规则为86.5%。由此,在真实数据集上,按照访问频率完全化和按照层次完全化的方法符合数据流量的访问特征。

图6 高级AC自动机以频率为界限的数据流量统计结果

图7 高级AC自动机以层次为界限的数据流量统计结果
3.1.2 存储空间和匹配速度测试
1) 按访问频率完全化和层次完全化2种算法
2种完全化算法在3个数据集上的性能将分别与高级AC算法进行对比,高级AC算法在相应数据集上的存储空间与匹配速度如表3所示。
本节首先测试访问频率界限在 90%~98%变化时(变化间隔为1%),算法HybridFA_1的存储空间和匹配速度的变化情况,实验结果如图8中相应曲线所示。可见随着访问频率界限的增高,在3种真实数据集上HybridFA_1算法的存储空间均逐渐增大,这是由于访问频率界限越高,需要完全化的节点越多,从而使存储空间增大;在匹配速度方面,随着访问频率界限的提高,在3种真实数据集上HybridFA_1算法的匹配速度也逐渐提高,这是由于完全化的节点数目越多,在匹配过程中状态需要回溯的次数越少,因而匹配速度越快。当访问频率界限为 98%时,HybridFA_1算法在Snort、ClamAV和URL上的存储空间分别为2.22 MB、10.25 MB和8.60 MB,仅占高级AC自动机存储空间的3.96%、1.86%和4.58%,而匹配速度分别是高级AC自动机的82.78%、106.06%和 79.98%。可见,该算法在保证匹配速度的同时,大大降低了存储空间。
访问层次界限在2~10层变化时(变化间隔为1层),算法HybridFA_2的存储空间和匹配速度随层次界限的变化结果如图8中相应曲线所示。

图8 HybridFA_1算法,HybridFA_2算法在Snort、ClamAV、URL 3个真实数据集上匹配速度与存储空间的关系
在 3种数据集上,当访问层次界限提高时,HybridFA_2算法的存储空间均逐渐增大,相应的匹配速度也逐渐增快,与 HybridFA_1具有相似的实验结果。但随着完全化的层次界限的提高,HybridFA_2算法的匹配速度增长速度逐渐减慢,而存储空间却增长迅速,尤其当访问层次界限设为 3层以上时,这种变化趋势更加明显。当访问层次界限设为3层时,HybridFA_2算法在Snort、ClamAV和URL上的存储空间分别为2.22 MB、13.29 MB和8.22 MB,仅分别占高级AC自动机存储空间的3.95%、2.42%和 4.38%,而匹配速度分别是高级AC自动机匹配速度的62.13%、90%和56.22%。另外,与HybridFA_1算法相比,在存储空间相近时,HybridFA_1算法均具有更快的匹配速度。
综合上述分析,从存储空间和匹配速度的测试结果表明,当访问频率界限为98%时,HybridFA_1算法在3种数据集上存储空间的平均值仅为AC自动机存储空间的3.47%,且最高比率为4.58%,而匹配速度的平均值为 AC自动机匹配速度的89.61%,且最低比率为79.98%;当访问层次界限为3时,HybridFA_2算法的在3种数据集上的存储空间的平均值仅为AC自动机存储空间的3.58%,且最高比率为4.38%,而匹配速度的平均值为AC自动机匹配速度的69.45%,且最低比率为56.22%。可见,2种算法在匹配速度不低于高级AC的50%时,存储空间已降低到高级AC的5%以下。
2) 综合考虑数据流量特征的完全化算法
由图 8可知,当完全化的访问频率界限设为95%或更大时,HybridFA_1算法存储空间的增长速度逐渐增快,本文将 HybridFA_3算法的频率界限设为 98%;另外,随着完全化层次界限的增大,HybridFA_2算法在匹配速度增长的同时,存储空间也增长迅速,而当层次界限设为3层时,存储空间小于高级AC的5%,且匹配速度均超过高级AC算法的50%,所以将HybridFA_3算法的层次界限设为 3。表3显示了HybridFA_1算法、HybridFA_2算法、HybridFA_3算法、高级AC算法在3个真实数据集上存储空间与匹配速度的对比结果。
由表3分析可见,HybridFA_3算法的存储空间略大于HybridFA_1算法和HybridFA_2算法,但匹配速度都快于二者。同时,HybridFA_3算法在Snort、ClamAV和URL这3个数据集上的存储空间分别为2.75 MB、14.55 MB和8.70 MB,仅占高级AC自动机存储空间的4.90%、2.65%和4.63%,而匹配速度分别是高级AC自动机的85.80%、120.05%和83.81%。可见,存储空间均小于高级AC算法的5%;匹配速度在 Snort规则和 URL规则上与高级AC算法相当,在ClamAV规则上快于高级AC算法。
实验结果表明,按访问频率完全化和按访问层次完全化2种方法在构建HybridFA时都具有较好的压缩效果。对比而言,按频率完全化的方法,完全化的最小单位为节点,对数据流量的统计更精确,所以需要完全化的节点相对较少,自动机所需要存储空间也更少,但是对数据流量变化适应性不强。按层次完全化的方法,完全化靠近根节点的所有低层节点,当数据流量发生变化时,访问频率高的节点可能发生变化,但大部分高访问频率的节点仍集中在低层节点中,对数据流量的变化适应性相对较强。在实际应用中,随着完全化层次的增加,存储空间也相应迅速增长,因此需要根据具体需求权衡存储空间与匹配速度的关系。最后提出的结合数据流访问频率和访问层次特征的混合自动机构建算法在存储空间、匹配速度和数据适应性等综合性能上获得了最好效果。
4 结束语
本文根据数据流对自动机节点的访问特征,提出基于访问频率完全化和基于访问层次完全化的 2种构建混合自动机的算法,并综合分析以上2种算法的优势,进一步提出改进的自动机完全化算法。真实数据集上的实验结果表明,与高级AC算法相比,3种算法在保证匹配速度的同时,存储空间降低到高级 AC算法的5%左右。同时,结合数据流访问频率和访问层次特征的自动机完全化算法在匹配速度和数据适应性方面都获得了最好效果。未来工作将考虑对访问频率和访问层次这2个重要参数的选择进行优化。

表3 HybridFA_1、HybridFA_2、HybridFA_3和高级AC算法在3组真实数据集上存储空间和匹配速度对比
[1] ME L, HEYE L, KURI J,et al. A pattern matching based filter for audit reduction and fast detection of potential intrusions[A]. The 3rd International Workshop on the Recent Advances in Intrusion Detection[C]. Toulouse, France, 2000.17-27.
[2] NAVARRO G, KURI J. Fast Multipattern Search Algorithms for Intrusion Detection[R]. Technical Report TR/DCC-99-11, Dept. of Computer Science, Univ of Chile.1999.
[3] VARGHESE G, FIST M. Applying Fast String Matching to Intrusion Detection[R]. Technical Report In preparation, successor to UCSD TR CS2001-0670. University of California, San Diego. 2002.
[4] AHO A V, CORASICK M J. Efficient string matching: an aid to bibliographic search[J]. Communications of the ACM, 1975, 18(6): 333-340.
[5] NAVARRO G, RAFFINOT M. Flexible Pattern Matching in Strings:Practical On-line Search Algorithms for Texts and Biological Sequences[M]. SIAM Publishing, 2002.
[6] DENCKER P, DORRE K, HEUFT J. Optimization of parser tables for portable compilers[J]. ACM Transactions on Programming Languages and Systems, 1984, 6(4):546-572.
[7] AHO A V, SETHI R, ULLMAN J D. Compilers: Principles, Techniques, and Tools[M]. Addison-Wesley Publishing, 2006.
[8] ZIEGLER S. Smaller faster table driven parser[EB/OL]. http://www.researchgate.net/publication/242522203_Smaller_faster_table_driven_parser. Unpublished manuscript. Madison Academic Computing Center, 1977.
[9] AOE J, MORIMOTO0 K, SATO T. An efficient implementation of trie structures[J]. Software—Practice and Experience, 1992,22(9):695-721.
[10] 刘燕兵, 刘萍, 谭建龙等. 基于存储优化的多模式串匹配算法[J].计算机研究与发展, 2009, 46(10): 1768-1776.LIU Y B, LIU P, TAN J L,et al. A multiple string matching algorithm based on memory optimization[J].Journal of Computer Research and Development,2009,46(10):1768-1776.
[11] NAVARRO G, RAFFINOT M. Fast and flexible string matching by combining bit-parallelism and suffix automata[J]. Experimental Algorithmics, 2000, 5(4): DOI:10.1145/351827.384246.
[12] Clam Antivirus, an anti virus detection software[EB/OL]. http://www.clamav.net/binary.html#pagestar.
[13] Free real network data for string matching test released by MIT[EB/OL].http://www.ll.mit.edu/IST/ideval/
[14] Snort, a free and open source network intrusion detection and prevention system[EB/OL]. http://www.snort.org/snort-rules/?#rules
