基于提升回归树的东、黄海鲐鱼渔场预报
2015-01-05高峰陈新军官文江李纲
高峰,陈新军*,官文江,李纲
(1. 上海海洋大学 海洋科学学院,上海 201306;2. 上海海洋大学 大洋渔业资源可持续开发省部共建教育部重点实验室,上海 201306;3. 上海海洋大学 国家远洋渔业工程技术研究中心,上海 201306;4. 远洋渔业协同创新中心,上海 201306)
基于提升回归树的东、黄海鲐鱼渔场预报
高峰1,2,3,4,陈新军1,2,3,4*,官文江1,2,3,4,李纲1,2,3,4
(1. 上海海洋大学 海洋科学学院,上海 201306;2. 上海海洋大学 大洋渔业资源可持续开发省部共建教育部重点实验室,上海 201306;3. 上海海洋大学 国家远洋渔业工程技术研究中心,上海 201306;4. 远洋渔业协同创新中心,上海 201306)
为提高东、黄海鲐鱼渔场预报准确率、降低渔业生产成本,研究提出了一种基于提升回归树的渔场预报模型。研究采用2003—2010年我国大型灯光围网渔捞日志数据,以有网次记录的小渔区为渔场,以渔捞日志未记录的区域作为背景场随机选择假定非渔场数据,以海表水温等环境因子作为预测变量构建东、黄海鲐鱼渔场预报模型并以2011年的实际作业记录对预报模型进行精度验证。验证计算得到预报模型的AUC(area under receiver operating curve)值为0.897,表明模型的预报精度较高。模型的空间预测结果表明,预报渔场与实际作业位置基本吻合,其位置移动也与实际情况相符。这表明基于提升回归树的渔场预报模型可以用来进行东、黄海鲐鱼渔场的预报。
提升回归树;鲐鱼;渔场预报;东、黄海
1 引言
鲐鱼(Scomberjaponicus)属大洋暖水性中上层鱼类,广泛分布于西北太平洋沿岸海域,主要为中国、日本、韩国等国的灯光围网渔业所利用[1]。鲐鱼是一种季节洄游性鱼类,其作业渔场位置与洄游路线密切相关,同时也受到海洋环境条件变动的影响,呈现出较大的年际变化[2]。目前,在鲐鱼渔场方面的研究主要是对鲐鱼渔场形成机制[3—4]、时空分布[2,5]以及渔场与环境因子之间关系[6]的分析和解释,对于鲐鱼渔场的预报则以栖息地指数模型(Habitat suitability index,HSI)等专家系统方法为主[2,7—9]。栖息地指数模型实现过程简单,易与地理信息系统(Geographical information system,GIS)结合应用[10],但其预报结果中适宜的栖息地范围一般较广,对于实际渔业生产的指导作用有限。
提升回归树(boosted regression trees,BRT)是一种基于决策树的集成学习方法[11],已在渔业上有一定的应用,如单位捕捞努力渔获量(catch per unit effort,CPUE)标准化[12]、鱼类空间分布、丰度和多样性预测[13—14]、鱼类栖息地研究[15—16]、兼捕预测[17]等。与传统多元回归方法相比,提升回归树能自动拟合自变量的交互作用,且不易出现过度拟合,因此泛化误差较低,对于新数据的预测精度较高[13]。本研究基于2003—2010年我国大型灯光围网渔船捕捞日志数据,利用提升回归树方法建立东、黄海鲐鱼作业渔场预报模型,并用2011年的实际作业渔场位置对模型进行了验证。
2 材料与方法
2.1 渔业数据及处理
本文研究区域为25°~40°N、120°~130°E围内的东、黄海海域,时间为2003—2011年7—12月。
东、黄海鲐鱼大型灯光围网渔捞日志数据由中国远洋渔业协会上海海洋大学鱿钓技术组提供。数据包括作业日期、作业船组、作业位置(大渔区、小渔区)、产量(箱)、放网次数和平均网次产量(箱/网)。将数据按小渔区(空间分辨率10′×10′)和周为单位进行重新统计并添加小渔区中心经纬度坐标。处理后的数据覆盖928个小渔区,共2 880条记录。
渔捞日志数据只记录了作业渔场的信息,而没有记录非作业渔场的信息。根据生物分布预测中处理“仅包含发现”(presence-only)的数据的方法[18],以渔捞日志中未作记录的时间和小渔区作为背景场,采用完全随机的方式选择2 880条假定非作业渔场数据记录[19]。将其与处理后的渔捞日志数据合并组成渔业数据集。
2.2 环境数据
已有的研究表明,东、黄海鲐鱼渔场的形成和时空分布变动受海表水温、海水水质、饵料生物等众多海洋环境要素的影响[2—7,20—22],但考虑到实际渔业生产中对于渔场预报的要求,本研究仅选取了4个可通过海洋卫星遥感获取且实时性和可用性较好的环境因子,即海表水温(sea surface temperature,SST),海表水温梯度(gradient of sea surface temperature,GSST),海面高度(Sea Surface Height,SSH)和地转流流速(geostrophic velocity,GV)。
周平均SST来自NOAA OceanWatch网站(http://oceanwatch.pifsc.noaa.gov/)提供的AVHRR全球覆盖海表水温数据集,空间分辨率为0.1°,单位为℃。
海表水温梯度采用计算公式[23]:
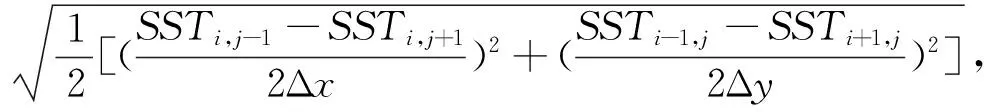
(1)
式中,SSTi±1,j和SSTi,j±1为上下左右4个网格点的海表水温,Δx和Δy为SST网格数据在经度和纬度方向的分辨率,其单位为(°)。
周平均SSH和地转流数据来自NOAA OceanWatch网站提供的卫星高度计融合数据产品,其中SSH以大地水准面为起算面,空间分辨率为0.25°,单位为cm。地转流数据包括东西方向(u)和南北方向(v)两个分量,其空间分辨率为0.5°,单位为cm/s。
地转流流速GV采用计算公式:
(2)
另外,时空数据方面选取了周数(Week)、经度(Longi)和纬度(Lati)3个因子作为预测变量。
将环境因子数据插值到与渔业数据相同的空间分辨率(10′×10′小渔区)并与渔业数据进行匹配,匹配后的数据分为训练数据集(2003—2010年数据)和验证数据集(2011年数据)两部分。
2.3 预报模型及参数选择
2.3.1 预报模型
研究采用提升回归树模型,以小渔区是否为渔场为响应变量、相关环境和时空因子为预测变量对训练数据集进行建模。模型拟合使用R语言(3.0.3版,R核心开发组,2014)gbm包[24]以及Elith编写的实用函数包[13]。
提升回归树是一种自适应的集成学习方法,它结合了提升(boosting)和分类回归树(classification and regression trees,CART)两种技术[13,25—26]。与传统统计学方法和CART不同的是,提升回归树并不寻求单一的“最佳”模型,而是通过组合大量相对简单的决策树的方式以优化模型的预测性能[13]。提升回归树模型可以写成M棵分类回归树相加的形式:
(3)
式中,X为SST、SSH等预测变量,Tm(X,γm)为第m棵分类回归树,γm为其参数,代表了该决策树的分裂点和每个叶子结点的赋值,求解γm的过程即单棵决策树的学习过程。
2.3.2 模型参数选择
提升回归树采用逐步迭代的方式[11]按顺序学习每一棵决策树。有3个参数可以用来调整提升回归树的学习过程。首先,每棵决策树在学习时仅按比例随机抽取部分观测数据作为学习样本,这个比例称为装袋分数(bagging fraction),其目的是通过引入随机因素以提高模型预测精度[27]。其次,为了降低模型对观测数据的拟合速度,防止出现过度拟合,需要在每棵决策树前乘以一个较小(小于0.1)的收缩系数ν之后再加入模型,这个收缩系数也称为学习率(learning rate,lr)。最后,提升回归树中所有决策树的叶节点数都相同,训练时叶节点达到相应数量即停止生长,因此不需要剪枝。单棵决策树的叶节点数量也称为树的复杂度(tree complexity,tc),它代表了提升回归树模型能够拟合的环境因子之间交互作用的阶数[11]。这3个参数中,装袋分数一般推荐取值0.5~0.75,为减小模型的变异性[13],选择装袋分数为0.75。lr和tc的取值对模型的预测性能影响相对较大,因此分别设置lr为0.001、0.005、0.01、0.1,tc为1、2、4、8,按年分组随机选取训练数据集的70%构建模型,以剩余30%数据计算模型的预测偏差,根据模型的拟合过程以及预测偏差的大小选择最优的lr和tc。为减小运算时间,限制模型最多包含5 000棵分类回归树。
2.3.3 最优决策树数量
随着决策树数量的逐渐增加,提升回归树模型对训练数据的拟合将越来越好,但决策树超过一定数量,则可能出现过度拟合,导致模型的预测精度降低。本研究先以10倍交叉验证(10-fold cross-validation)方法建立提升回归树模型,取平均估计偏差最小的决策树数量为最佳决策树数量,然后使用全部训练数据建立包含最佳数量决策树的渔场预报模型。
2.4 预测因子重要性计算
对于单棵分类回归树,以Jn(T)作为第n个预测因子Xn与响应变量的相关性度量[26],其中:
(4)

).
(5)
实际计算中可以对结果进行正规化处理,使所有预测因子的相对重要性之和为1.0,以百分数的形式来表示单个预测因子的重要性。
2.5 预报模型分析及验证
2.5.1 模型精度评价
将验证数据集中各记录的环境和时空数据部分代入预报模型,计算相应的渔场概率。使用预测偏差(predictive deviance)和ROC(receiver operating curve)曲线[28]下的面积(area under ROC,AUC)对模型的预报精度进行评价。
预测偏差使用计算公式[24]:
(6)
式中,(xi,yi)为测试数据,wi为第i个测试样本的权重,测试样本权重全部为1.0,f(X)为提升回归树模型的原始输出,即作业渔场概率的对数优势。
AUC是评价二值预测模型的预测性能的常用标准,AUC值为0.5表示模型的预报与随机取值效果相同,AUC值为1则表示模型能正确预报所有作业渔场和非作业渔场[13],一般AUC大于0.75的预报模型就可以认为是“有用”的[28]。AUC相关的计算使用R语言PresenceAbsence包[29]。
2.5.2 最佳阈值的选择
提升回归树模型的输出值是作业渔场的概率,因此一般需要选择一个阈值对模型输出结果进行二值化处理,即预测渔场概率大于该阈值的渔区为中心渔场,反之则非中心渔场。虽然确定最佳阈值的方法较多,但本研究所采用的非渔场数据为随机选取,而非真实的非渔场数据,理论上这些方法并不适用[29]。在根据渔捞日志数据来确定中心渔场或高产渔区时,常以单位渔区上的作业次数或捕捞努力量、以及渔获量作为评价指标,因此本研究将模型预测渔场概率平均分为5个区间,即0~0.2、0.2~0.4、0.4~0.6、0.6~0.8、0.8~1.0,然后根据2011年实际作业网次和渔获量在这些区间上的分布来选择一个合适的阈值。
2.5.3 空间预测验证
将2011年7—12月各周的环境数据带入预报模型,计算研究区域内所有渔区每周的渔场概率。由于实际作业周次较多,将每个月4或5周的预报渔场概率进行平均,得到每月的渔场概率分布图,并与当月实际作业渔场位置进行叠加,以考察预报渔场与实际作业渔场的吻合程度以及预报渔场位置分布的合理性。
3 结果
3.1 预报模型拟合
由图1可知,当lr为0.005和0.001时,各模型拟合过程均比较慢,当决策树达到5 000棵时模型的预测偏差曲线仍处于下降阶段,未能达到最佳的预测性能。当学习率为0.1时,各模型均能在2 000棵决策树之前达到最小预测偏差。当学习率为0.01时,tc为1、2和4的模型在5 000棵决策树之前预测偏差曲线均处于下降阶段,而tc为8的模型在5 000棵决策树之前达到最小预测偏差,且最小预测偏差的值也比学习率为0.1时各模型的最小预测偏差值小。因此选择0.01和8作为预报模型的学习率和复杂度参数。

图1 不同学习率和复杂度下的模型预测偏差与决策树数量的关系Fig.1 The relationship between predictive deviance and number of trees for models fitted with four learning rates and four levels of tree complexity模型以训练数据的70%进行拟合,以剩余30%数据计算预测偏差;图中虚线表示模型的最小预测偏差The models were fitted with 70% records of the training dataset,and the remaining 30% were used to calculating the predictive deviances. The dashed line marks the minimum predictive deviance
设置模型的lr为0.01,tc为8、10倍交叉验证方法得到的平均估计偏差与决策树数量的关系如图2所示。随着模型中决策树数量的增加,平均估计偏差逐渐降低。当决策树为50棵时,平均估计偏差约为1.146。当模型中决策树达到1 000棵时,平均估计偏差下降至0.674。最佳决策树数量为4 950棵,此时平均估计偏差达到最小值0.578。以上参数拟合全部训练数据并建立最终的渔场预报模型。

图2 10倍交叉验证平均估计误差与决策树数量的关系Fig.2 The relationship between mean estimated deviance of 10-fold cross-validation and number of trees虚线表示模型最小平均估计偏差0.578及最优的决策树数量4 950The dashed line identifies the minimum mean estimated deviance as 0.578 and the optimal number of trees as 4 950
3.2 因子重要性
分析认为,SST与渔场的关系最为密切,其相对重要性达到22.4%;其次是空间因子,其中纬度的相对重要性(21.6%)大于经度(18.8%)。SSH和Week的重要性稍低,分别是14.5%和12.9%。GV和GSST的重要性较低,分别是5.4%和4.4%(图3)。
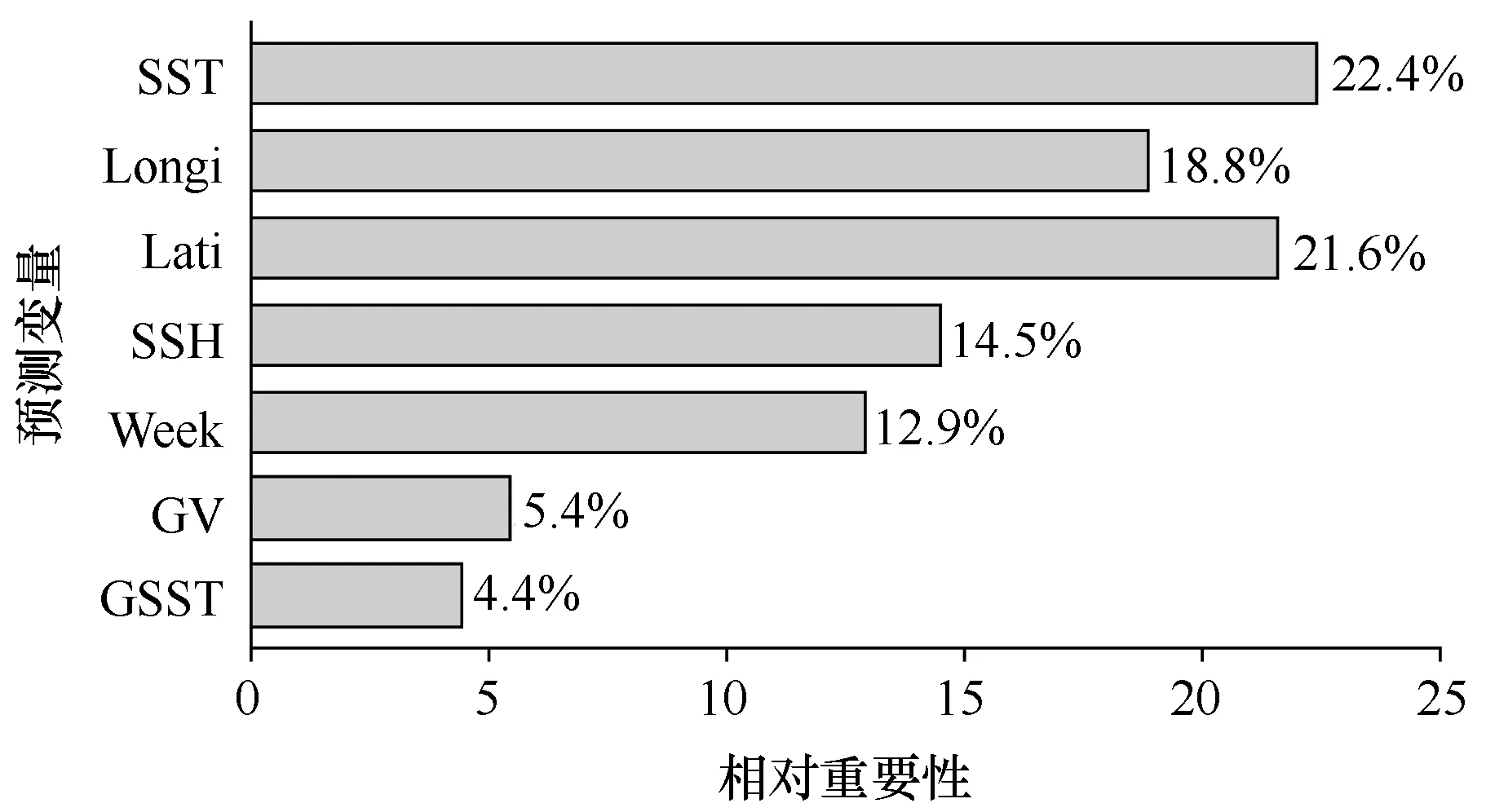
图3 预测因子的相对重要性Fig.3 Relative importance of the predictor variables
3.3 模型精度评价以及中心渔场阈值的选择
由表1可知,交叉验证得到的模型AUC值为0.942,以2011年实际作业渔场数据验证得到的模型AUC值为0.935。从数据验证的角度来看,模型预报的预报精度较高。
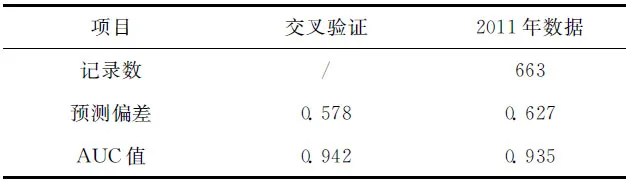
表1 预报模型的预测偏差及AUC值Tab.1 Predictive deviance and AUC of the forecasting model
表2可知,在预测渔场概率小于0.4的海区,作业网次和渔获量比例分别为6.48%和5.28%,总数均不超过全年的10%,且渔获量比例低于作业网次比例,即CPUE低于年平均CPUE。在预测渔场概率大于0.7的海区,作业网次和渔获量比例分别为77.11%和80.24%,总数均超过全年的75%,且渔获量比例高于作业网次比例,即CPUE高于年平均CPUE。这表明预测模型能有效的区分出低产和高产的区域。在对预测渔场概率进行二值化处理时,若以作业网次和渔获量作为中心渔场的准确性指标,则0.7应是一个合适的阈值。为了避免出现中心渔场范围过大的问题,也可以取0.8为阈值,即将预测渔场概率大于0.8作为中心渔场的判断标准。

表2 2011年作业网次和渔获量在模型预测渔场概率区间上的百分比分布Tab.2 Percentages of nets and catch in different predicted probability ranges of fishing grounds in 2011
3.4 作业渔场预测
由图4可知,2011年7-9月的预报渔场主要位于东海中南部26.5°~31°N、122.5°~127°E区域以及29°~31°N、124°E以西的舟山渔场,其中9月份东海中南部渔场向东北方向稍有移动,并且在36°N附近的黄海海域也有渔场分布,但预报的渔场概率不高。10-12月的预报渔场主要位于黄海海域,随时间推移预报渔场有向黄海南部移动的趋势,12月份的主要预报渔场已南移至33.5°N,最南达到东海北部海域,同时东海中南部也有小范围的渔场分布。总体上看,除了9月份黄海海域和10月份东海北部海域实际作业渔场概率预测值偏低之外,预报渔场的位置与实际作业位置基本吻合,其随时间的位置移动也基本与实际情况相符,这说明模型的预报渔场在空间分布上是合理的。

图4 2011年预测渔场与鲐鱼大型灯光围网渔业实际作业位置Fig.4 Distribution of predicted fishing grounds and the fishing locations of Chinese large-type lighting purse seine fishery for chub mackerel in 2011
4 讨论
4.1 假定非渔场数据的选择及其影响
在渔场预报研究中,常以单位区域内CPUE或捕捞努力量作为该区域渔场好坏的指标,并以此为响应变量建立渔场预报模型[30—31]。但这种基于CPUE或捕捞努力量定义渔场的方法对一些渔业并不合适。Andrade[32]在研究西南大西洋金枪鱼杆钓渔业与海表温度的关系时指出,CPUE仅能作为鱼群可用性的指标,而不能代表资源的丰度或渔场的好坏。其原因在于该区域金枪鱼杆钓渔业特定的作业过程:作业人员根据经验选择合适的作业地点,若发现鱼群,即抛洒饵料以吸引鱼群聚集,之后开始竿钓作业。考察东、黄海鲐鱼大型灯光围网渔业的作业过程会发现,虽然聚集鱼群的方法和作业网具与金枪鱼竿钓渔业不同,但这两种渔业的作业方式具有3个相同的特点,一是作业位置的选择主要依据作业人员的经验(可能主要是基于水温的经验);二是发现鱼群之后才开始作业;三是渔获量主要受作业行为本身的效率以及鱼群状态(聚集程度、聚集位置等)的影响,导致CPUE或捕捞努力量只能代表捕捞行为的成功率(或鱼群的可用性),而并不能代表资源的丰度或渔场的情况。
基于上述原因,本研究使用了一种新的处理方式,即将有作业记录的小渔区均作为渔场,以随机选择的背景数据作为假定的非渔场,从而建立渔场预报模型。从模型预报结果的准确率来看,这种处理方法是有效的。但同时,在训练样本中引入假定非渔场数据也会对预报模型产生一定的影响。首先,由于大型灯光围网渔业的产量在东、黄海鲐鱼总产量中的比例逐年下降[2],从概率上讲,很大一部分假定非渔场数据其实是真实的作业渔场;其次,由于假定非渔场数据取值在环境空间上的随机性,相同的环境因子在渔场和假定非渔场条件下的分布可能存在某些相似性,这必然导致环境因子作用的相互抵消[33]。如图5所示,由于南北渔场的作业时间和环境条件的不同,实际作业渔场的SST分布呈现明显的双峰,但假定非作业渔场下的SST分布在26~30℃范围同样也出现了峰值。由于这种分布上的相似性,SST对渔场的作用很可能被弱化。此外,由于鲐鱼渔场分布的总体概率未知,只能根据经验确定假定非渔场数据记录的数量,相应的,模型所预测的渔场概率只是一个相对值,并不是实际的渔场概率[10]。

图5 假定非渔场和实际作业渔场记录中海表水温的分布Fig.5 Distribution of sea surface temperature of fishing grounds and pseudo non-fishing grounds
4.2 预测因子的相对重要性
提升回归树模型认为,SST与鲐鱼渔场的关系最为密切,这与其他研究者的研究结果是一致的[20],当然这也可能是因为在实际作业过程中水温是作业人员选择作业位置的主要依据。相应的,GSST和GV的影响并不显著,这可能有3个原因:一是作业人员在根据经验选择作业位置时可能未考虑GSST和GV因素,因为作业人员一般很难获知当前作业位置的GSST和GV;二是由于假定非渔场数据的选择使得渔场和非渔场条件下的GSST和GV分布相同,影响相互抵消因而弱化了效果;三是GSST和GV可能主要是对鲐鱼的聚集和作业的成功率有影响,但对作业渔场位置却影响不大。
此外,模型也发现,时间和空间因子对作业渔场位置具有非常强的影响,二者的相对重要性合计超过了50%。这一方面是因为“某时间在某地点可能会出现渔场”是作业人员经验的重要组成部分,因此对作业渔场位置的选择确实存在重要影响。另一方面这也与预报模型本身有关,提升回归树是一种机器学习方法,它倾向于仅使用训练数据所包含的模式来解释渔场的分布[34]。由于一些重要的环境因子(如饵料条件)可能未包含在模型中,已有的环境因子又由于假定非渔场数据的影响而作用被减弱,结果导致时空因子的作用被大大强化了。这也从侧面说明,虽然机器学习方法对数据的拟合能力强于传统的线性和加性回归,能充分利用训练数据中所包含的各种模式,但如果训练数据本身不具有代表性,模型所发现的模式很可能与实际情况有偏差。因此在使用机器学习方法进行渔场预报时,对预测因子的选择工作将更加重要。
4.3 模型预报效果及完善
由表1、表2和图4可知,从基于验证数据集的评价结果来看,模型预报准确率较高(AUC值0.935),且能有效地区分低产和高产区域。从空间位置上来看,预报渔场的范围也基本与实际作业位置吻合。因此,采用基于提升回归树的渔场预报模型来预报东、黄海鲐鱼渔场是可行的。同时,从鲐鱼渔业资源管理和保护的角度来说,中心渔场或高产渔区同时也是鲐鱼资源保护的关键区域。因此,准确的预测这些区域的位置,对于鲐鱼资源的管理和保护也有重要的意义。
由表2和图4可知,模型对2011年9月黄海海域和10月东海北部海域作业渔场的预测概率值偏低,其主要原因可能在于2011年9-10月为当年大型灯光围网渔业在南北渔场之间转场时间,故在东海和黄海海域均有作业,而预报模型未能发现这种作业模式,仅能正确预测主要渔场区域而对次要作业区域预测值偏低。这很可能表明模型对时空因子作用的强化已经对预报的准确性产生了一定的影响。另外,一些对渔场位置分布具有显著影响的环境因子也可能未被包含在模型中,因此SST等环境条件的差异未能对预报渔场产生足够的影响。针对这些问题,在后续的研究中可以从两方面对模型进行完善:首先,可以考虑将水团、锋面和涡流、底层水温以及饵料条件等环境因子加入模型以增加训练数据集的代表性。其次,在选择假定非渔场数据时,可使用基于环境因子的分组随机采样,或者采用HSI、生态位因子分析[10](Ecological niche factor analysis,ENFA)和最大熵值法[35](maximum entropy,MAXENT)等模型确定背景场以降低假定非渔场数据引起的模型偏差。
[1] 程家骅,林龙山. 东海区鲐鱼生物学特征及其渔业现状的分析研究[J]. 海洋渔业,2004,26(2): 73-78.
Cheng Jiahua,Lin Longshan. Study on the biological characteristics and status of common mackerel (ScomberjaponicusHouttuyn) fishery in the East China Sea region[J]. Marine Fisheries,2004,26(2): 73-78.
[2] Li Gang,Chen Xinjun,Lei Lin,et al. Distribution of hotspots of chub mackerel based on remote-sensing data in coastal waters of China[J]. International Journal of Remote Sensing,2014,35(11/12): 4399-4421.
[3] 苗振清. 东海北部鲐鲹中心渔场形成机制的统计学[J]. 水产学报,2003,27(2): 143-150.
Miao Zhenqing. The statistical research on the formation mechanism of central fishing ground ofPneumatophorusjaponicusandDecapterusmaruadsiin the north of East China Sea[J]. Journal of Fisheries of China,2003,27(2): 143-150.
[4] 李曰嵩,潘灵芝,严利平,等. 基于个体模型的东海鲐鱼渔场形成机制研究[J]. 海洋学报,2014,36(6): 67-74.
Li Yuesong,Pan Lingzhi,Yan Liping,et al. Individual-based model study on the fishing ground of chub mackerel (Scomberjaponicus) in the East China Sea[J]. Haiyang Xuebao,2014,36(6): 67-74.
[5] 李纲,陈新军. 东海鲐鱼资源和渔场时空分布特征的研究[J]. 中国海洋大学学报,2007,37(6): 921-926.
Li Gang,Chen Xinjun. Tempo-spatial characteristic analysis of the mackerel resource and its fishing ground in the East China Sea[J]. Periodical of Ocean University of China,2007,37(6): 921-926.
[6] 郑波,陈新军,李纲. GLM和GAM模型研究东黄海鲐资源渔场与环境因子的关系[J]. 水产学报,2008,32(3): 379-386.
Zheng Bo,Chen Xinjun,Li Gang. Relationship between the resource and fishing ground of mackerel and environmental factors based on GAM and GLM models in the East China Sea and Yellow Sea[J]. Journal of Fisheries of China,2008,32(3): 379-386.
[7] Chen Xinjun,Li Gang,Feng Bo,et al. Habitat suitability index of chub mackerel (Scomberjaponicus) from July to September in the East China Sea[J]. Journal of Oceanography,2009,65(1): 93-102.
[8] 张月霞,丘仲锋,伍玉梅,等. 基于案例推理的东海区鲐鱼中心渔场预报[J]. 海洋科学,2009,33(6): 8-11.
Zhang Yuexia,Qiu Zhongfeng,Wu Yumei,et al. Predicting central fishing ground ofScomberjaponicain East China Sea based on case-based reasoning[J]. Marine Sciences,2009,33(6): 8-11.
[9] 陈峰,雷林,毛志华,等. 基于遥感水质的夏季东海鲐鱼渔情预报研究[J]. 广东海洋大学学报,2011,31(3): 56-62.
Chen Feng,Lei Lin,Mao Zhihua,et al. Fishery forecasting for chub mackerel (Scomberjaponicus) in summer in the East China Sea based on water quality from remote sensing[J]. Journal of Guangdong Ocean University,2011,31(3): 56-62.
[10] Franklin J. Mapping species distributions: spatial inference and prediction[M]. New York: Cambridge University Press,2009: 200-205.
[11] Hastie T,Tibshirani R,Friedman J. The elements of statistical learning: data mining,inference,and prediction[M]. New York: Springer-Verlag,2001: 299-345.
[12] Abeare S. Comparisons of boosted regression tree,GLM and GAM performance in the standardization of yellowfin tuna catch-rate data from the Gulf of Mexico longline fishery[D]. Baton Rouge: Louisiana State University,2009: 1-94.
[13] Elith J,Leathwick J R,Hastie T. A working guide to boosted regression trees[J]. Journal of Animal Ecology,2008,77(4): 802-813.
[14] Froeschke B F,Tissot P,Stunz G W,et al. Spatiotemporal predictive models for juvenile southern flounder in Texas estuaries[J]. North American Journal of Fisheries Management,2013,33(4): 817-828.
[15] Lewin W C,Mehner T,Ritterbusch D,et al. The influence of anthropogenic shoreline changes on the littoral abundance of fish species in German lowland lakes varying in depth as determined by boosted regression trees[J]. Hydrobiologia,2014,724(1): 293-306.
[16] Compton T J,Morrison M A,Leathwick J R,et al. Ontogenetic habitat associations of a demersal fish species,Pagrusauratus,identified using boosted regression trees[J]. Marine Ecology Progress Series,2012,462: 219-230.
[17] Soykan C U,Eguchi T,Kohin S,et al. Prediction of fishing effort distributions using boosted regression trees[J]. Ecological Applications,2014,24(1): 71-83.
[18] Pearce J L,Boyce M S. Modelling distribution and abundance with presence-only data[J]. Journal of Applied Ecology,2006,43(3): 405-412.
[19] Barbet-Massin M,Jiguet F,Albert C H,et al. Selecting pseudo-absences for species distribution models: how,where and how many?[J]. Methods in Ecology and Evolution,2012,3(2): 327-338.
[20] 李纲,陈新军. 夏季东海渔场鲐鱼产量与海洋环境因子的关系[J]. 海洋学研究,2009,27(1): 1-8.
Li Gang,Chen Xinjun. Study on the relationship between catch of mackerel and environmental factors in the East China Sea in summer[J]. Journal of Marine Sciences,2009,27(1): 1-8.
[21] 官文江,陈新军,高峰,等. 海洋环境对东、黄海鲐鱼灯光围网捕捞效率的影响[J]. 中国水产科学,2009,16(6): 949-958.
Guan Wenjiang,Chen Xinjun,Gao Feng,et al. Environmental effects on fishing efficiency ofScomberjaponicusfor Chinese large lighting purse seine fishery in the Yellow and East China Seas[J]. Journal of Fishery Sciences of China,2009,16(6): 949-958.
[22] 官文江,陈新军,李纲. 海表水温和拉尼娜事件对东海鲐鱼资源时空变动的影响[J]. 上海海洋大学学报,2011,20(1): 102-107.
Guan Wenjiang,Chen Xinjun,Li Gang. Influence of sea surface temperature and La Nia event on temporal and spatial fluctuation of chub mackerel (Scomberjaponicus) stock in the East China Sea[J]. Journal of Shanghai Ocean University,2011,20(1): 102-107.
[23] 陈新军,刘必林,田思泉,等. 利用基于表温因子的栖息地模型预测西北太平洋柔鱼(Ommastrephesbartramii)渔场[J]. 海洋与湖沼,2009,40(6): 707-713.
Chen Xinjun,Liu Bilin,Tian Siquan,et al. Forecasting the fishing ground ofOmmastrephesbartramiiwith SSJ-based habitat suitability modelling in Northwestern Pacific[J]. Oceanologia et Limnologia Sinica,2009,40(6): 707-713.
[24] Ridgeway G. Generalized boosted regression models: A guide to the gbm package[EB/OL]. (2007-08-03)[2014-09-30]. http://ftp.ctex.org/mirrors/cran/web/packages/gbm/.
[25] Friedman J H. Greedy function approximation: a gradient boosting machine[J]. The Annals of Statistics,2001,29(5): 1189-1232.
[26] Brieman L,Friedman J,Olshen R A,et al. Classification and regression trees[M]. Belmont: Chapman & Hall/CRC,1984: 1-368.
[27] Friedman J H. Stochastic gradient boosting[J]. Computational Statistics & Data Analysis,2002,38(4): 367-378.
[28] Swets J A. Measuring the accuracy of diagnostic systems[J]. Science,1988,240(4857): 1285-1293.
[29] Freeman E A,Moisen G. PresenceAbsence: An R package for presence absence analysis[J]. Journal of Statistical Software,2008,23(11): 1-31.
[30] 崔雪森,伍玉梅,张晶,等. 基于分类回归树算法的东南太平洋智利竹筴鱼渔场预报[J]. 中国海洋大学学报,2012,42(7/8): 53-59.
Cui Xuesen,Wu Yumei,Zhang Jing,et al. Fishing ground forecasting of Chilean jack mackerel (Trachurusmurphyi) in the Southeast Pacific Ocean based on CART decision tree[J]. Periodical of Ocean University of China,2012,42(7/8): 53-59.
[31] 陈雪忠,樊伟,崔雪森,等. 基于随机森林的印度洋长鳍金枪鱼渔场预报[J]. 海洋学报,2013,35(1): 158-164.
Chen Xuezhong,Fan Wei,Cui Xuesen,et al. Fishing ground forecasting ofThunnusalalungin Indian Ocean based on random forest[J]. Haiyang Xuebao,2013,35(1): 158-164.
[32] Andrade H A. The relationship between the skipjack tuna (Katsuwonuspelamis) fishery and seasonal temperature variability in the south-western Atlantic[J]. Fisheries Oceanography,2003,12(1): 10-18.
[33] VanDerWal J,Shoo L P,Graham C,et al. Selecting pseudo-absence data for presence-only distribution modeling: how far should you stray from what you know?[J]. Ecological Modelling,2009,220(4): 589-594.
[34] 陈新军,高峰,官文江,等. 渔情预报技术及模型研究进展[J]. 水产学报,2013,37(8): 1270-1280.
Chen Xinjun,Gao Feng,Guan Wenjiang. et al. Review of fishery forecasting technology and its models[J]. Journal of Fisheries of China,2013,37(8): 1270-1280.
[35] Phillips S J,Anderson R P,Schapire R E. Maximum entropy modeling of species geographic distributions[J]. Ecological Modelling,2006,190(3/4): 231-259.
Fishing ground forecasting of chub mackerel in the Yellow Sea and East China Sea using boosted regression trees
Gao Feng1,2,3,4,Chen Xinjun1,2,3,4,Guan Wenjiang1,2,3,4,Li Gang1,2,3,4
(1.CollegeofMarineSciences,ShanghaiOceanUniversity,Shanghai201306,China; 2.KeyLaboratoryofSustainableExploitationofOceanicFisheriesResources,MinistryofEducation,ShanghaiOceanUniversity,Shanghai201306,China; 3.NationalDistance-waterFisheriesEngineeringResearchCenter,ShanghaiOceanUniversity,Shanghai201306,China; 4.CollaborativeInnovationCenterforDistant-waterFisheries,Shanghai201306,China)
To improve the accuracy of fishing ground forecasting of chub mackerel (Scomberjaponicus) in the Yellow and East China Sea,and reduce the fishery production cost,a new fishing ground forecasting model based on boosted regression trees was proposed in this study. Model was fitted with data extracted from electronic logbooks of Chinese mainland large-type lighting purse seine fishery for chub mackerel,with a range from 2003 to 2010. The fishing area with fishing effort was identified as fishing ground and the pseudo non fishing ground data was randomly collected from background field,which is the fishing areas with no records in the logbooks. The predictive variables were sea surface temperature and other environmental factors. The performance of prediction of the model was evaluated with the testing dataset consist of actual fishing locations of year 2011. The results of the evaluation showed that the prediction model had a high prediction performance with an AUC value of 0.897. The results of spatial prediction showed that the predicted fishing ground and its shifting were coincided with the actual fishing locations,which indicated that the forecasting model based on boosted regression trees can be used to forecasting the fishing ground of chub mackerel in the Yellow and East China Sea.
boosted regression trees; chub mackerel; fishing ground forecasting; Yellow Sea; East China Sea
2014-12-16;
2015-07-14。
国家863项目(2012AA092301);国家发改委产业化专项(2159999);国家科技支撑计划(2013BAD13B01);上海市教委科研创新项目(14ZZ147)。
高峰(1979—),男,湖北省宜都市人,博士生,研究方向为渔业GIS和渔情预报。E-mail:gaofeng@shou.edu.cn
*通信作者:陈新军,男,教授,研究方向为渔业资源与渔场学。E-mail:xjchen@shou.edu.cn
10.3969/j.issn.0253-4193.2015.10.004
S931.4
A
0253-4193(2015)10-0039-10
高峰,陈新军,官文江,等. 基于提升回归树的东、黄海鲐鱼渔场预报[J].海洋学报,2015,37(10):39—48,
Gao Feng,Chen Xinjun,Guan Wenjiang,et al. Fishing ground forecasting of chub mackerel in the Yellow Sea and East China Sea using boosted regression trees[J]. Haiyang Xuebao,2015,37(10):39—48,doi:10.3969/j.issn.0253-4193.2015.10.004
