融合形态特征的最大熵维吾尔语词性标注
2015-01-01帕力旦吐尔逊房鼎益
帕力旦·吐尔逊,房鼎益
(1.西北大学信息学院,陕西 西安 710127;2.新疆大学软件学院,新疆 乌鲁木齐 830046)
词性标注(Part-of-Speech Tagging)是词法分析的一个重要部分,主要目的是给句中每一个词赋以正确的分类标记。词性标注的难点是如何正确判断兼类词的词性以及对生词词类的判别。
目前词性标注的方法有基于统计及基于规则的方法。最早提出的是基于规则的一种方法,主要是词类消歧规则[3]的建立要依据兼类词之间的搭配情况,在考虑语境以及上下文的含义。由于应用的范围广,要求高,被标注的语料的规模也会增大,原来的人工的方法提取规则虽然有其一定的优点,但是也有很大的缺点,同时浪费了时间和精力,再加上在不同的领域词性标注系统的要求都不一样,针对各种语言标注系统也不可通用,基于以上种种原因,在对大规模语料进行处理时我们选择了另一种标注方法,也就是基于统计方法来进行词性标注,这个方法克服了前一种方法的缺点,也可以进行移植,现在也成为了包括经英语和汉语在内的一些语言进行词性标注方面研究的一种常用的方法,而且这个方法的效果也是令人满意的。
维吾尔文的词性标注的研究方面开展得比较晚一些,而且最开始大家都使用了基于词典的方法以及基于规则的一种方法[4-6],同时也使用了基于N-gram的HMM模型[7],尽管它们的效果也都比较好,但在处理维吾尔文等黏着型的语言时也有一定的问题,由于维吾尔语在融入语言知识上有一定的不足,因此在使用它时就受到了一定的局限。在维吾尔语的词性标注研究时遇到的一个很大的难点就是该语言的词形变化十分丰富,举例来说,如果在一个词干的后面加上不同词缀的附加成分,那么这个单词就可以构成不同的单词。采用上述方法尽管取得了较好的成绩,但仍然有大量的未登录词无法避免,而且也使得维吾尔文的词性标注出现了更加严重歧义的现象,如果不能使用足够的特征信息来进行处理,就会对兼类词消歧产生很大的影响,并且也会在对未知词进行标注时影响它的词性标注的准确度,一般采用猜测的方法对上述模型中未登录词的词性进行标注。
本文充分利用维吾尔文形态特征建立了一个基于最大熵理论的维吾尔文词性标注模型,由于最大熵模型使用的特征丰富,而且充分利用了上下文的信息,因此它的概率分布在给定的约束条件之下可以达到与训练数据大致一致,同时也因为选择并使用了一些丰富的上下文信息,就使得在对未登录词的词性标注进行预测时结果也非常理想[8-10]。通过对实验的结果进行分析,最后证明在对维吾尔文兼类词进行消歧以及对未知词的词性进行标注时,使用最大熵模型对其进行预测就能够得到较满意的效果,而且该方法取得的标注的效果也会优于其他方法。
1 维吾尔文词性标注
1.1 维吾尔语词类分析
维吾尔文按照词的大的类型来划分,则可以将其分为实词、虚词、感叹词等类型,如果对其中的实词再细分还能分成动词、静词两种,其中静词还可分成副词、数词、名词、形容词、量词、代词、拟声词等几种类型;虚词还可分成语气词、连词、后置词等几种类型。实词中包含的分类有形态的变化并可以表达意义,虚词词类则没有形态变化[11]。维吾尔语静词的不同词缀有65个,其中形容词的不同词缀有55个,名词的不同词缀49个,数词的不同词缀57个,动词有150多个不同词缀。维吾尔文实词词缀的各种组合中静词总计可达1 502种,动词可达1 500种。而实际上语料库却只有368种组合方式。
1.2 维吾尔语词性标记集
维吾尔语没有一个统一词性标记集的规范,新疆多语种信息技术重点实验室[7]和新疆师范大学[5]的标注规范有自己的标准。本文采用的维吾尔文词性标注标记集是新疆多语种信息技术重点实验室采用的。该标记集在对英文、中文词性标注标记集参考的基础上,在维吾尔文原有12个基本词类的基础上(表1),制定的词性标注规范[7]中具有一级标记集15个,二级标记集71个,三级标记集51个。本文进行建模与实验时采用一级标记集是由于语料库规模不大。

表1 新疆多语种信息技术重点实验室维吾尔语词性一级标记集Tab.1 First level POS tagging set proposed by the key laboratory of multilingual information technology in Xinjiang
1.3 词性标注难点
维吾尔语形态会有变化,所以需要考虑词性标注前是否需要对维吾尔语单词进行形态分析的问题。若对单词不进行词干提取的话,则词性标注时同一个单词的不同变体被系统认为不同的单词,大量的未登录词可能会出现;若对单词进行词干提取的话,虽然在一定程度上减小了数据稀疏的问题,但是同时却又增大歧义现象的可能。例如:
(拉丁文转写):mëning ëtimbek oruq,hazirche beygige yarimaydu,sëningëtingniat beygisge qatnashturup baqsaq qandaq?
(翻译成):我的马太瘦了,现在还不能参加赛马,你的马参加一下如何?
“马”这个单词在以上的句子中出现了3次,每一次都是不一样的形态。若训练库中只有ëtim和at的形式,而ëtingni(你的马)形式却没有,则模型将ëtingni判断为未登录词,实际上该单词的词干形式已在训练库有了,由于单词形态的变化使得已有词被识别为未登录词的现象产生。即便如此,对单词进行词干提取后也可能有更多的歧义产生。比如,单词at在以上句子中的还有“射击”的意思,是动词,对ëtim词干提取之后,at就有了歧义。若利用当前连接的词缀模型或规则就能确定当前词干at不是动词而是个名词。另外,词性转移概率一定程度上受在训练语料库中的形态影响。文献[7]中基于HMM的词性标注方法的研究中就遇到了该问题。HMM模型不能利用有利于歧义消除或未登录词预测的特征信息而只能用发射概率、单词的前后搭配出现概率等。故本文建立维吾尔语统计词性标注模型时采用最大熵模型。
近几十年来研究者研究了基于支持向量机、隐马尔科夫、条件随机场、最大熵等模型的词性标注工作[1]。由于最大熵模型可以和自然语言模型很好地匹配,还能对多类约束信息进行融合,因此在用其进行词性标注研究时效果较好。在英语的词性标注中使用最大熵方法其准确率达到了97%以上,已和人工标注的准确度[2]相似。
2 基于最大熵的维吾尔文词性标注模型
2.1 最大熵的模型及原理
自然语言处理的方法中最大熵模型经常被使用[8]。可以将它应用到自然语言处理里的词性标注、分词、词义排歧、文本分类、机器翻译等方面。
首先建立一个随机过程的模型p,把自然语言看作随机过程,p∈P;输出值的集合为Y,y∈Y;上下文集合X,x∈X;N个样本的集合S={(x1,y1),(x2,y2),…,(xN,yN)},(xi,yi)是对一个事件的观察,事件空间为X×Y;用特征表示语言知识,特征为一个2值函数f:X×Y→{0,1}。
模型p的熵

其中C是满足约束条件的模型集合,接下来就要在C中寻找具有下面形式的p*
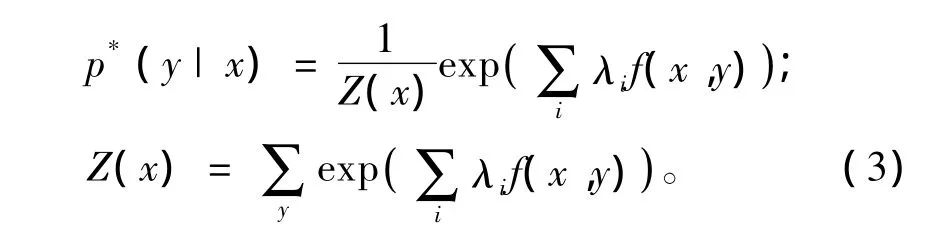
式中Z(x)是模型的参数,表示一个归一化常量。
也可以将它看作是特征的权值,而权值的大小则由λi每个特征的贡献来决定。
2.2 特征选择方法
模型中针对问题选取特征集合[8]是最大熵模型的关键。将复杂的语言现象转化为简单的特征表示。使用最大熵模型构建序列对模型进行标注,即标注结果y是根据x的上下文特征来确定的,由此可见合适的特征集合的建立十分重要。本文中建立维吾尔文词性标注模型的特征集合的方法:
1)常规特征:词的词性和它的上下文环境有很大关系,故判断当前词的词性时应当考虑这个词w的前n个词及后m个词的含义及其他信息。
2)维吾尔文中构词的特点:维吾尔语是黏着型的语言,属于阿尔泰语系突厥语族,其他如蒙古语、满语、土耳其语、日语、韩语、匈牙利语、芬兰语、泰米尔语均属于黏着型语言。它的特点是时态的变化可以通过在单词的词尾加上各类词缀来实现。
维吾尔文词语在结构上分为词根和词干两部分,词根不可再分,为最小的语义单位。几个词根连接在一起,或者词根和词缀连接在一起就组成了词干。例如:词根为 ish(事宜,事情,职业,事),通过这个词根后面连接构词词缀chi,可以得到词干ish+chi=ishchi(工人)。在维吾尔文文本中的单词一般由词干和连接词尾的几个构形词缀来表达句中的语法功能。例如:ishchi(工人)+ning(构形词缀)=ishchining(工人的)。
经新疆多语种信息技术重点实验室的《维吾尔语百万词词法标注语料库》进行统计得知,平均每条句子中出现形态变化的单词约有66.54%,句子中单词连接两个以上词缀的词汇有37.39%。因此,对维吾尔文词性标注模型而言,词干是能够有效减小数据稀疏问题的重要信息,构形词缀是有利于消除歧义及识别未登录词词类的重要线索之一。
2.3 特征模板定义
本文中,文献[8-9]是在词性标注模型特征模板的基础上,根据维吾尔文的构词特点,设计了维吾尔文词的内部特征、前后依存特征及混合特征。
2.3.1 维吾尔文词内部特征 词干和词缀信息统称词内部特征。在维吾尔文文本中的单词一般由词干和连接词尾的几个构形词缀来表达句中的语法功能。本文设计的词内部特征模板如下:
1)词干信息
维吾尔语中词干附加构形词缀原词干的词性不变,只是表达语法功能,所以对句子中的单词进行词干提取不影响词干词性的识别。例如:kitab(书)+ta(构形词缀)=kitabta(书上),所以句子中只考虑kitab的词性就可以,特征函数定义为

2)词缀信息
作为黏着语言,维吾尔语有丰富的形态变化,名词有49个词缀,数词有57个词缀,形容词词缀有55个,动词词缀有150多个。不同组合数可以达到3 002种,动词词缀超过1 500种,但在实际语料库中出现的有368种组合方式。词缀的主要作用是表达语法功能,在句中什么位置连接什么样的词缀,要看具体的上下文。因此,词缀在识别未登录词词性和排除兼类词词性时能够提供线索。例如,at是兼类词,词类是名词和动词,at+ing=ëting(你的马),根据词缀ing就可以判断当前词类是名词,at+ma=atma(不要射击)就可以判断当前词类是动词。特征函数定义为

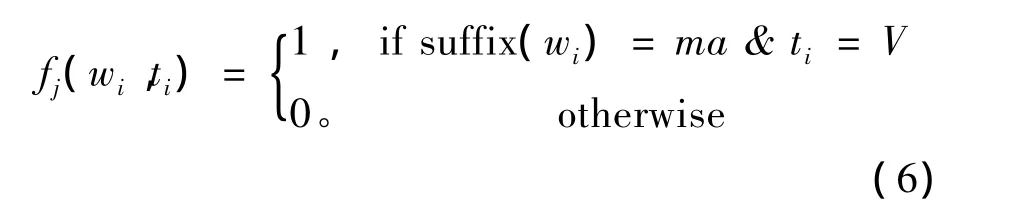

表2 词内部信息特征模板Tab.2 Inner word information feature template
2.3.2 前后依存特征 前后依存词特征指的是与句子中的当前词联系紧密的词之间的关系,对于兼类词可以根据前后依存词的相关信息予以解决。例如,句子1:“men dora yeyishni untup qaptimen.(我忘了吃药。)”;句子2:“sen meni dorima.(你不要模仿 我。)”。单词dora有药品、模仿等意思,可以看作名词或动词。消歧处理时可以利用其前后词的词类特征来进行。

表3 前后依存词信息特征模板Tab.3 Word context information feature template
2.3.3 混合特征 就是混合当前词的词干、词缀、前驱词的词干、词缀、后续词的词干、词缀等特征信息,混合信息特征定义如表5所示。

表4 混合信息特征模板Tab.4 Mixed information feature template
3 分析实验结果
3.1 维吾尔语语料库
本文的实验使用的语料库是较为权威的,新疆多语种信息技术重点实验室的《维吾尔语百万词词法标注语料库》,该语料库包含词性标注,词干、词缀等信息,选用的规模为60 041条句子、词次1 119 565,不重复的词汇为98 941条,词干为42 258,平均每条句子中出现形态变化的单词约有66.54%,句子中单词连接两个以上词缀的词汇有37.39%,其中兼类单词词干1 848条、出现频率为16 347次。

表5 实验数据Tab.5 The experimental data
因为语料库主要包括文学、医学、农业、法律、新闻等内容,领域覆盖度并不高,所以本文中对句子进行了随机抽取,其构成如表6所示。可看出,各种词性在训练语料库和测试语料库中分布均匀。形容词、动词、名词、标点符号稍多一些。

表6 训练和测试语料库详细统计Tab.6 Detailed statistics on training and testing corpus
一般词性标注准确度是评价标注结果的有效数据,其定义如下

3.2 实验设置及结果分析
在本文中,采用SharpNLP的MaxEnt工具包进行实现最大熵模型,采用新疆大学多语种信息技术开发的XJUNLP基于N元语法的HMM模型进行对比分析。由前所述,对各种不同组合的特征进行实验,选出最适合于维吾尔文词性标注的特征组合。表3作为基本特征组合使用,用T1表示。
采用常用的词依存特征进行实验,准确度达到了94.21%,以此为基准。实验2、实验3、实验4、实验5、实验6等加入了词干特征,随着增加上下文词干特征,提高了模型准确度。分析结果可得当前单词之前单词词干、当前单词词干及后一个单词词干特征对准确度贡献较高。为了测试词缀对模型的影响,实验7加入了当前词的词缀特征,准确度比基准系统提高了0.47%。实验8中加入了连续两个词缀的混合特征,模型性能得到了明显的提高。该特征证明了维吾尔文词缀表达语法功能的说法,大部分词缀根据前一个单词词缀进行连接。例如,menging kitabim(我的书),ing(的格词缀),im(人称词缀),前一个词缀ing要求一定要连接一个人称词缀,而人称词缀只能附加到名词。根据实验5和实验8的结果,设置了实验9和实验10。分析结果可得,当前单词的前缀和后缀、前一个单词词缀和当前单词词缀及后一个单词词缀等特征对模型准确贡献较大。
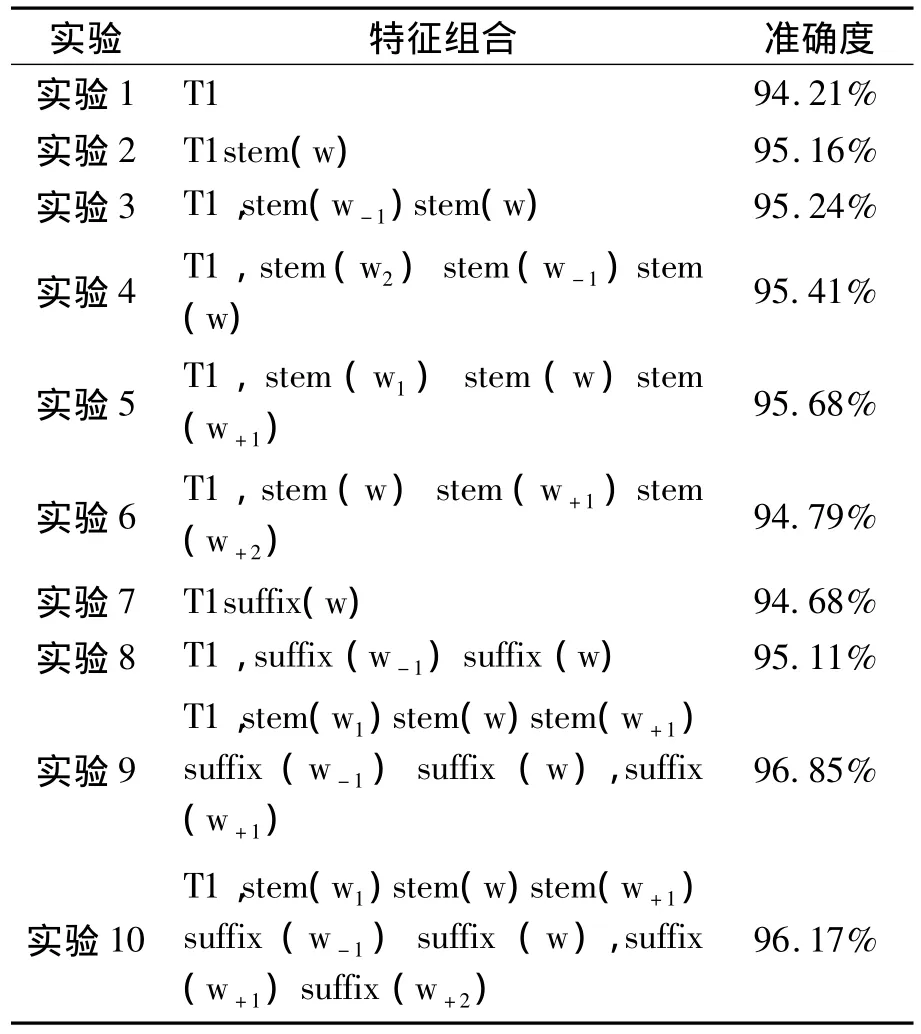
表7 实验结果Tab.7 The experimental data
为了对比HMM模型与最大熵模型的性能,采用相同的语料库进行了实验,实验结果如表8所示。

表8 HMM与最大熵对比实验结果Tab.8 Comparative experimental results of HMM and maximum entropy method
从实验结果可看出,最大熵模型能够较好地处理名词、动词、形容词等类,同时能够较高地识别未登录词。
3.3 错误分析
经过对错误数据分析得出,主要错误是名词、形容词被标注为动词的情况比较多,占32.8%;还有名动词、形动词、副动词等被标注为名词、形容词、副词的情况较多,占27.6%。
另外,实验中出现的普通外国人名和汉族人名对系统的性能产生的正确率下降为12%左右。根据对错误进行分析发现,除了句子头部出现的外国人名、汉族人名以及一个词的外国人名(只用名的情况,例如奥巴马,而不是巴拉克·奥巴马)以外的其他人名基本上给予错误的标注。因为外国人或汉族人的姓名中间有空格或”?”,一般出现连续两个或3个人名,这严重地削弱上下文信息量。例如:
Junggo xelq tashqi dostluq jem'iyitining bashliqi①chën xawsu,afghanistan diplomatiye ministirlikining muawën ministiri ②muhemmed kabir falahi ziyapetke qatnashti hemde tebrik sözi qildi.
以上句子中,用①标注的是汉族人名,按照维吾尔语的正字法,汉族人的姓和名之间留一个空格,所以在这个位置出现连续两个未登录词。用②标注的是阿富汗外交部副部长的姓名,由3个单词组成,除了第一个名词“muhemmed”以外,连续出现的其他两个人名均是未登录词。
4 总结与展望
本文介绍了维吾尔文融合语言特征的最大熵词性标注的研究工作,其亮点在于最大熵模型特征的选择上,根据维吾尔文的形态特征特点,选取当前词词干、词缀等混合形态特征信息,构建了基于最大熵的维吾尔文词性标注系统。分析实验结果发现最大熵适合于构建维吾尔文词性标注序列标注模型,通过融合多种特征,能够显著提高标注准确率。在本文实验中准确度达到了96.85%,准确度比原基准系统提高了2.64%。由于所使用语料规模和覆盖面还需进一步提高,因此所做词性标注的整体效果也受到一定影响。在以后的工作中,继续扩建标注语料库,进一步考虑融合词典和规则,把无歧义的感叹词、量词、数字表达式等通过规则或词典进行标注,然后把这个结果融入到模型,从而提高模型的鲁棒性。
[1] 宗成庆.统计自然语言处理[M].北京:清华大学出版社,2008.
[2] 张贯虹,斯·劳格劳,乌达巴拉.融合形态特征的最大熵蒙古文词性标注模型[J].计算机研究与发展,2011,48(12):2385-2390.
[3] 刘开瑛.中文文本自动分词和标注[M].北京:商务印书馆,2000.
[4] 吐尔根·依布拉音,阿里甫·库尔班,阿不都热依木.基于词典的现代维吾尔语词性自动标注系统的研究[C].北京:中文信息处理会议,2006年10月.
[5] 玉素甫·艾白都拉,张海军,艾孜尔古丽.信息处理用现代维吾尔语词干词类标记集研究[J].信息技术与标准化,2011(6):45-481.
[6] 吐尔根·依布拉音,阿里甫·库尔班.基于规则的维吾尔语词性自动标注系统的研究[C].合肥:第二届全国少数民族青年自然语言处理学术研讨会,2008:210-214.
[7] 买合木提·买买提,吐尔根·依布拉音.基于N-gram的维吾尔语词性自动标注系统的研究[C].合肥:第二届全国少数民族青年自然语言处理学术研讨会,2008:206-209.
[8] ADWAIT R.A maximum entropy model of part-ofspeech tagging[C].Proceedings of the Conference on Empirical Method in Natural Language Proeessing,1996,1:133-142.
[9] 张磊.基于最大熵模型的汉语词性标注研究[D].大连:大连理工大学,2008.
[10]赵岩,王晓龙,刘秉权,等.融合聚类触发对特征的最大熵词性标注模型[J].计算机研究与发展,2006,43(2):268-274.
[11]哈密提·铁木尔.现代维吾尔语语法[M].北京:民族出版社,1987.
