结合语义的改进FTC文本聚类算法
2014-12-23王秀慧王丽珍麻淑芳
王秀慧,王丽珍,麻淑芳
(山西大同大学 教育科学与技术学院,山西 大同037009)
0 引 言
文本聚类是数据挖掘领域研究的一个热点。传统聚类算法像基于划分的K-MEANS、K-MEDOIDS,基于层次的CURE等可以实现文本聚类,但是这些算法大多采用向量空间模型表示文本,容易产生“高维效应”,直接导致聚类算法效率低下且聚类结果不准确。针对这样的问题,Bei和Xu在论文frequent term-based text clustering中提出了一种基于频繁项集的文本聚类方法FTC (frequent term-based clustering)。
FTC算法保证了高维度数据聚类的效率,有效地降低了时间开销,可伸缩性良好。但是,由于直接在文本的关键词集上挖掘频繁项集而未考虑词语间的语义联系,因此聚类质量并没有得到明显提高。另外,具有多个主题是文本的一个自然属性,而FTC把一个文本硬性地划分到唯一结果簇中,不能获取最优聚类结果。针对FTC 算法存在的不足,本文进行了有效改进。首先,借助某种中文语料库把文本的关键词集映射到概念集合,在更高更抽象的级别挖掘满足最小支持度的频繁项集并获取聚类候选簇。由于充分考虑了关键词间的语义联系,相似文本将会更好的聚集。其次,定义了簇间相似度度量公式,以决定簇间是否应该存在重叠,合理实现了对候选簇的软分离,保证了聚类结果全局最优。实验结果表明,改进后的FTC 算法聚类准确度更高。
1 FTC算法介绍
FTC算法是一种基于频繁项集的文本聚类算法,它由Bei和Xu提出。该算法的基本思想是:从文本集合中挖掘所有满足最小支持度的频繁项集,并把包含频繁项集的文本集合看成一个候选簇,然后通过一种贪心策略,重复选择与其它候选簇重叠度最小的作为结果簇,直到结果簇集合覆盖到所有文本为止[1]。
在FTC中,假定文本数据库D 包含D1,D2…Dm文本,每一个文本Di由包含在该文本的关键词集合Ti表示。在T={T1,T2,…,Tm}上挖掘满足最小支持度minsup的频繁项集,得到频繁项集集合F= {F1,F2,…,Fn}。对于任一Fi,如果包含k个频繁词,则称之为频繁k项集,相应的候选簇称之为k阶簇。k个频繁词包含在该簇的所有文本内,反应了文本集的共性,可作为该簇的类别标签。
由于一个文本通常包含多个频繁项集,因此候选簇之间会存在重叠现象。定义熵重叠度 (entropy overlap)E O(Ci)来衡量Ci与其它候选簇的重叠情况

其中,fj为Dj所支持的频繁项集个数。
E O(Ci)反映了Ci所支持的频繁项集在其它候选簇中的分布情况。显然,值越大,Ci与其它簇的重叠度越高。当值为0时,Ci所包含的文档都不支持其它频繁项集,此时Ci与其它簇无重叠。
在对文本进行分词、停用词过滤等预处理后,去除大部分噪声词,得到关键词集合T= {T1,T2,…,Tm},FTC在此基础上再进行聚类,该算法详细步骤描述如下:
输入:文本数据库D 的关键词集T
输出:结果簇集C
(1)从T 中挖掘满足最小支持度minsup 的频繁项集F= {F1,F2,…,Fn},每个频繁项集Fi对应的文本集合构成候选簇Ci。
(2)聚类结果簇集C= {}。
(3)计算每个候选簇Ci的熵重叠度。
(4)把熵重叠度最小的Ci加入结果簇集C中。
(5)对于包含在Ci中的任一文本Dj,如果Dj属于其它候选簇Cj则从Cj中删除Dj。
(6)从候选簇中删除Ci。
(7)判断聚类结果簇是否覆盖所有文本,如果没有返回 (3)继续执行,否则算法终止。
Bei和Xu通过实验验证,FTC 算法的聚类质量比bisecting k-means更高,同时时间花销较少,具有处理大型数据集的能力。但是,考虑到两个文本对象的相似度并不是单纯的由文本内出现相同的词语决定,比如 “土豆”和“马铃薯”,这两个词词形不同,但语义是完全相同的。如果聚类简单的只考虑词形,而忽略了词语之间语义联系的话,包含 “土豆”和 “马铃薯”的两个文本将被划分到不同的簇中,显然会影响聚类准确性。另外,文本具有多个主题是其一个自然属性,例如一段关于医药的价格报道文本,就应该归入医药和财经两个类别中。而FTC 聚类是一种硬划分,即每个文本被唯一的划分到一个簇中,未能体现出文本的多主题性。针对FTC 算法存在的两点不足,本文进行了有效改进,如2所述。
2 FTC算法改进
对FTC算法的改进体现在两个方面:一方面,把文本的关键词集映射成概念集合,以概念集合作为挖掘频繁项集的基础;另一方面,定义簇间相似度度量公式,以便于把多主题文本划分到不同结果簇中,实现聚类软划分。改进后的FTC 算法称为基于语义的FTC 算法 (semanticsbased FTC,SFTC)。
2.1 关键词概念获取
为了准确有效的挖掘文本关键词之间的潜在语义关系,需借助某种中文语料库来获取关键词所代表的概念。目前,知网作为一个知识系统,在中文信息处理领域发挥的作用越来越大,因此,本文选定知网[2]作为概念获取的语料库。
知网有两个非常重要的概念:义项和义原。其中义项是对词的一个描述,主要用DEF来描述。义原是不可分割的最小语义单位,没有歧义。DEF 由多个义原组合而成,知网用有限的义原去定义无限的义项[3]。根据义原的这些特点,本文采用义原作为文本中关键词在语义上的概念。为了把文本集的关键词映射成知网中的某个义原,需先处理未登录词、多义词。
2.1.1 处理未登录词
考虑到知网收录词条的有限性,文本中的有些词在知网中查不到,把这些词称为未登录词。对于未登录词,如果出现频率很低,直接过滤掉,如果出现频率较高,则直接把它归入文本的概念集合中。
2.1.2 处理多义词
由于中文词语的多义性,文本中的一个关键词可能存在多个义项,如 “出口”一词,可以是名词,也可以是动词。对应到知网中有两个义项,其中名词 “出口”的DEF为 {location|位置:PartPosition= {mouth|口},belong={building|建筑物}, {GoInto|进入:location= {~}},{GoOut|出去:location= {~}}},动词 “出口”的DEF为 {transport|运 送:LocationFin = {place |地 方:PlaceSect= {country|国家},domain= {politics|政},modifier= {foreign|外国}},domain= {commerce|商业}}。对于有多个义项的关键词,需要首先为其选择合适的义项,即词义排岐。由于义原的组合说明了知网中各个义项的含义,因此描述义项的义原在某文本中出现次数越多,表明该义项更符合原文本的语义环境。定义了义项对原文的重要程度公式
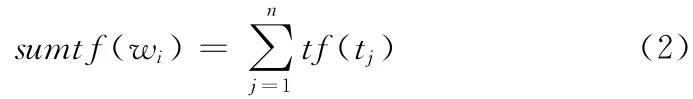
式中:tf(tj)——多义词w 的第i个DEF中的第j个义原tj在文本中出现的频率,sumtf(wi)——w 的第i个DEF中所有义原在文本中出现的频次之和。显然,sumtf(wi)值越大,表明该DEF更符合原文本的上下文环境。因此从w 的若干义项中选择sumtf 值最大的作为该关键词的最终义项。
2.1.3 概念获取
知网中的单义登录词只有一个义项,可以直接获得其DEF。多义登录词有多个义项,通过2.1.2 描述的方法可以唯一确定该词的DEF。为了获取关键词所对应的概念,需从DEF所包含的多个义原中选择主题描述能力最强的作为该词的最终概念。
DEF中各个义原的语义描述能力不同。比如 “长跑”一词,其DEF= {fact|事情:CoEvent= {exercise|锻炼},domain= {sport|体育}}。显然 “事情”这个义原所含的语义信息很少,查询义原概念树可知其位于第二层,层次越低,则语义描述能力越弱。对于这类义原,本文称之为弱义原,应该过滤掉。像 “人”、“地方”、“万物”、“属性”等,都属于弱义原。为了实现义原过滤,本文首先从知网中把所有的弱义原提取出来并存放在一个数据库表中,在进行义原抽取时,碰到此类义原,直接过滤即可。
过滤掉弱义原后,DEF 里还可能包含多个义原,为了选择DEF中的某个义原作为最终概念,本文借鉴了文献[4]的方法。即:计算出各个义原的权值,然后选择权值最大的作为最终义原。
由知网的结构特点可知,义原之间存在8 种关系,但最重要的是上下位关系。本文只考虑上下位关系,则知网系统对应9个义原概念树,每个义原是概念树中的一个节点。显然,影响义原权重的因素有二,一是义原所在的概念树,一是义原在概念树中的层次。
由于一篇文本中能表达文本主题的大多是名词和动词,因此9棵概念树中最重要的是实体树和事件树。文献 [4]简单的将义原所处的实体树或事件树的权重设为1.0 和0.25而未考虑义项的词性,实际上义原的重要程度跟义项的词性也有关。如 “出口”作动词使用时其DEF= {transport|运送:LocationFin= {place|地方:PlaceSect={country|国 家},domain= {politics|政},modifier={foreign|外国}},domain= {commerce|商业}}。在它的若干义原中,“运送”的语义描述能力更强,更具代表性。而如果采用文献 [4]的方法, “地方”的权值要更大,显然计算结果不准确。为使权重计算更准确,本文根据义项的词性来给义原概念树赋予不同权值,当义项为名词时,实体树权重要偏大,而当义项为动词时,事件树权重偏大。其它概念树如专有名词树、属性树等对一个义项的描述能力较弱,本文简单将权重都设置为一个比较小的值。
义原作为概念树中的一个节点,所处位置不同,义原的语义描述能力也不同。由知网结构特点可知,义原在概念树中层次越深,且下位义原越少,则描述能力越强。综合义原所处的概念树以及在概念树中的层次情况,可得义原的权值计算式
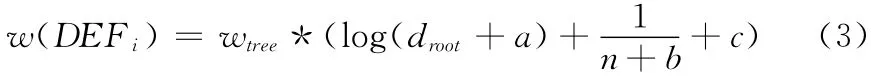
式中:w(DEFi)——DEF中第i个义原的权值,wtree是根据义项的词性所确定的义原所在的概念树的权重,droot——该义原在概念树中的层次,n——下位义原数。参数a、b、c为可调节参数,用来控制义原权值的取值范围。采用式(3)计算出DEF中每个义原的权值,选择权值最大的义原作为关键词的最终概念,完成了关键词的概念获取。
2.2 候选簇的生成与簇相似度
2.2.1 生成候选簇
FTC在文本集合的关键词集中直接挖掘频繁项集,然后以每个频繁项集所支持的文本集合作为候选簇或初始簇,由于未考虑关键词间的语义联系,会导致最终聚类结果质量不高。本文依据2.1中的方法,把文本的关键词集映射到知网中的概念集合,在更高更抽象的概念集合中挖掘频繁项集。由于事先考虑了关键词间的语义联系,聚类结果将会更准确。
挖掘频繁项集的算法很多,具有代表性的有自底向上遍历的Aprior 算法、自顶向下遍历的Max-Miner 算法等[5]。而最近提出的FP-Growth算法不产生候选项集,直接产生频繁模式项集,且对数据库的扫描限制在两遍,有效地提高了挖掘效率[6,7]。因此,本 文采用FP-Growth 算法从文本的概念集合中挖掘频繁项集。把每个频繁项集看做一个候选簇,所有支持该频繁项集的文本被划分到该簇中。频繁项集中的词语反映了该候选簇的共性,可作为簇标签使用。
2.2.2 定义簇相似度
对于候选簇Ci和Cj,如果两者所支持的频繁项集存在交集,包含在两簇内的文本存在重叠,则两簇存在一定的相似性。定义簇间相似度度量公式见式 (4)

式中:Fi——描述簇Ci的频繁项集,doc(Ci)——簇Ci包含的文本集。即簇间相似度定义为两个簇所对应的频繁项集相交个数占所有频繁项集的百分比与簇间相交文本占数所有文本的百分比的叠乘。Sim(Ci,Cj)的取值范围为 [0,1],值越大,相似度越高,当两簇完全相同时,Sim(Ci,Cj)=1。
在FTC算法的步骤 (5)中,如果选定候选簇Ci为结果簇,则包含在Ci中的任一文本Di,如果存在于剩余候选簇Cj,则直接从Cj中删除Di,根本没有考虑文本具有多主题性的特点。鉴于此,本文首先计算出Sim(Ci,Cj),如果Sim(Ci,Cj)小于阈值α,表明两簇所表达的主题不一致,此时应保留Cj中的文本Di;反之,Sim(Ci,Cj)大于阈值α,表名两簇主题相似,此时应删除Cj中的文本Di,这样合理的实现了聚类结果的软划分。
2.3 SFTC算法描述
在把文本的关键词集映射成概念集合后,结合式 (4)得到SFTC算法,详细步骤描述如下:
输入:文本数据库D 的概念集合S
输出:聚类结果簇集C
(1)利用FP-Growth从概念集合S中挖掘满足最小支持度minsup 的频繁项集F= {F1,F2,…,Fn},根据频繁项集构造候选簇集 {C1,C2,…,Cn}。
(2)置聚类结果簇集C= {}。
(3)计算每个候选簇Ci的熵重叠度。
(4)把熵重叠度最小的Ci加入结果簇集C 中。
(5)对于包含在Ci中的任一文本Dj,如果Dj属于其它候选簇Cj,根据式 (4)计算簇间相似度Sim(Ci,Cj)。
(6)如果Sim(Ci,Cj)>α,删除Cj中的Dj,否则保留。
(7)删除候选簇中的Ci。
(8)判断聚类结果簇是否覆盖所有文本,如果没有返回 (4)继续执行,否则算法终止。
3 实验结果与分析
为了测试SFTC 算法的性能,本文采用了两组数据,文本集一选自大同地区科学数据共享平台中的8000条科学数据,文本集二选自搜狗实验室的全网新闻数据-sougou-CA[8],从中随机选择了5000 篇文本,并使用目前比较常用的F-measure方法进行结果评价。
3.1 F-measure
F-measure是一种基于人工标注的外部评价标准,它综合了召回率和准确率两种评价指标[9,10]。对于类Ki和簇Cj,召回率和准确率的公式定义见式 (5)和式 (6)
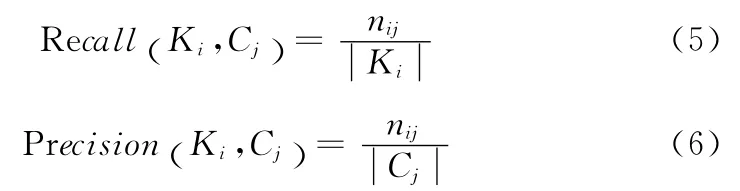
其中,nij表示簇Cj中属于类Ki中的文本数。由召回率和准确率可得到表示簇Cj描述类Ki能力的计算公式

对于每一个Ki,都对应一个最能描述它的结果簇Cj,即maxCj∈C{F (Ki,Cj)}。据此定义F(C),它表示所有类的maxCj∈C{F (Ki,Cj)}加权之和。其定义见式 (8)
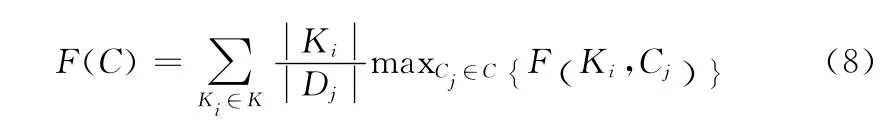
F(C)的取值范围 [0,1],值越大表示聚类质量越好。
3.2 聚类质量评价
为了测试SFTC 算法的聚类质量,选取bisecting kmeans和FTC 与本文算法进行比较。其中,bisecting kmeans随机选择初始聚类中心,FTC 和SFTC 的最小支持度相同,取5%。Bisecting k-means和FTC 在文本的关键词集上实现聚类,SFTC 在关键词集所对应的概念集合中完成聚类。3种算法在两个文本集合上的聚类结果见表1。
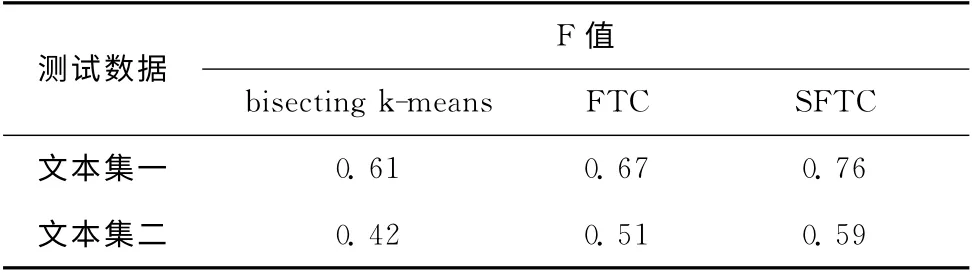
表1 3种算法F值比较
从表1可以看出,SFTC 在两个文本集上的F 值比bisecting k-means和FTC都要高,表明SFTC 算法确实提高了聚类质量。究其原因,主要有两个方面:一是因为用知网中的概念代替文本的关键词,使得聚类在更抽象的概念集合上完成,确保了同类文本更好的聚集;二是把多主题文本划分到不同的相关簇中,使得聚类结果更符合人的思维。
3.3 性能分析
一个聚类算法只有当执行效率得到保证时才是可行的。为了测试SFTC算法的运行效率,本文采用大同大区科学数据共享平台中的8000条科学数据作为测试对象。3种算法在科学数据集上的运行时间如图1所示。
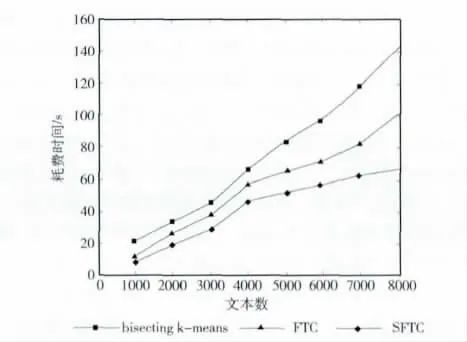
图1 3种算法在同一数据集上的时间开销比较
从图1可以看出,随着文本数的逐渐增大,3种算法的运行时间也在不断增加。但是SFTC 比其它两种算法的运行时间都要低,而且当文本数增加到一定程度时,SFTC运行时间增加比较平缓。这主要是因为SFTC 在文本的概念集合上进行聚类。由于概念集合建立在知网的有限义原基础之上,因此维度得到明显的降低。在一个维数较低的空间实现聚类,SFTC运行时间相对于其它算法肯定会减少。
从上述实验结果可以看出,SFTC 算法无论是在聚类质量上还是在算法性能上都有了一定的提高。
4 结束语
本文主要针对FTC算法在实现文本聚类时未考虑词语之间语义联系以及文本集硬划分聚类的问题,提出了一种结合语义的改进FTC文本聚类算法。通过引入知网把文本的关键词集映射到更抽象的概念集合,以概念集合作为发现频繁项集的基础,有效实现了相关文本在语义层面的更好聚集。通过定义簇间相似度度量公式合理实现了对聚类结果簇的软分离,使得最终聚类结果更符合人的思维。实验结果表明,改进后的算法在保证性能的前提下有效提高了聚类的质量。
[1]ZHOU Chong.Document clustering in search engine [D].Wuhan:Huazhong University of Science and Technology,2009 (in Chinese). [周翀.搜索引擎中文档聚类方法研究[D].武汉:华中科技大学,2009.]
[2]DONG Zhendong,DONG Qiang.HowNet[OL]. [2013-05-01].http://www.keenage.com/zhiwang/c_zhiwang.html(in Chinese).[董振东,董强.知网 [OL]. [2013-05-01].http://www.keenage.com/zhiwang/c_zhiwang.html.]
[3]GUO Chong,ZHANG Yangsen.Study of semantic automatic error-detecting for Chinese text based on sememe matching of HowNet[J].Computer Engineering and Design,2010,31(17):3924-3928 (in Chinese). [郭充,张仰森.基于 《知网》义原搭配的中文文本语义级自动查错研究 [J].计算机工程与设计,2010,31 (17):3924-3928.]
[4]BAI Qiuchan,JIN Chunxia,ZHOU Haiyan.Text clustering algorithm based on concept vector[J].Computer Engineering and Applications,2011,47 (35):155-157 (in Chinese).[白秋产,金春霞,周海岩.概念向量文本聚类算法 [J].计算机工程与应用,2011,47 (35):155-157.]
[5]YAO Xiaoling.Research on fast mining frequent itemsets algorithm [D].Changsha:Hunan University,2010 (in Chinese). [姚晓玲.快速频繁项集挖掘算法研究 [D].长沙:湖南大学,2010.]
[6]HE Zhongsheng,ZHUANG Yanbin.Algorithm of mining frequent itemset based on Apriori &Fp-growth[J].Computer Technology and Development,2008,18 (7):45-47(in Chinese).[何中胜,庄燕滨.基于Apriori &Fp-growth的频繁项集发现算法 [J].计算机技术与发展,2008,18 (7):45-47.]
[7]XIAO Jie.Research on text clustering based on frequent item set[D].Changsha:Central South University,2009 (in Chinese).[肖杰.基于频繁项集的文本聚类方法研究 [D].长沙:中南大学,2009.]
[8]Sogou Labs.The news network [DB/OL].[2013-04-10].http://www.sogou.com/labs/dl/ca.html(in Chinese).[搜 狗语实验室.全网新闻数据 [DB/OL].[2013-04-10].http://www.sogou.com/labs/dl/ca.html.]
[9]SUN Aixiang,YANG Xinhua.Evaluation of text clustering effect[J].Journal of Shandong University of Technology,2007,21 (5):65-68 (in Chinese).[孙爱香,杨鑫华.关于文本聚类有效性评价的研究 [J].山东理工大学学报,2007,21 (5):65-68.]
[10]WANG Xinbo.Research and application of metadata clustering algorithm based on OAI-PMH [D].Taiyuan:Taiyuan University of Science &Technology,2009 (in Chinese).[王新波.基于OAI-PMH 协议的元数据聚类算法及应用研究[D].太原:太原科技大学,2009.]
