基于Logistic函数的贝叶斯概率矩阵分解算法
2014-11-18方耀宁郭云飞兰巨龙
方耀宁郭云飞 兰巨龙
(国家数字交换系统工程技术研究中心 郑州 450002)
1 引言
当前,推荐系统(Recommender Systems, RS)是电子商务领域的研究热点之一。与基于内容的(Content-based)推荐算法相比,协同过滤(Collaborative Filtering, CF)推荐算法无须对内容进行解析,只利用历史行为信息便可以进行个性化推荐,在过去十年中取得了丰富的研究成果。其中,基于矩阵分解(Matrix Factorization, MF)的潜在因子模型(latent factor model)在预测准确性和稳定性上得到了最为广泛的认可[1]。
核矩阵分解算法(kernelized matrix factorization)虽然能够表征潜在因子间的非线性联系,但是计算量较大并不实用[8,9]。此外,项目间的隐含关系,用户的社交信息,上下文也可以用来提高矩阵分解算法的性能[10,11]。最近,Mackey等人[12]提出“分而治之”的思想,把原始矩阵拆分成多个小矩阵分别进行分解。与之类似,文献[13]假设原始矩阵是局部低秩的,把原始矩阵分解为多个低秩矩阵,然后再进行分解。文献[14]和文献[15]在 Netflix和MovieLens数据集合上对主流的推荐算法进行了较为详细的对比分析。
本文利用 Logistic函数来表征潜在因子间的非线性关系,在不增加计算复杂度的前提下,建立了L-BPMF(Logistic Bayesian Probabilistic Matrix Factorization)模型,并使用马尔科夫链蒙特卡罗方法训练L-BPMF模型。在两种真实数据集合上的实验结果表明,L-BPMF比主流推荐算法的预测准确性都要好,能够明显缓解数据稀疏性问题[15]。
2 贝叶斯概率矩阵分解
概率矩阵分解(Probabilistic Matrix Factorization, PMF)假设用户和项目的特征向量矩阵都服从高斯分布,不同用户、项目的概率分布相互独立[6]。

进而,把用户对项目的评分变成一个概率问题:

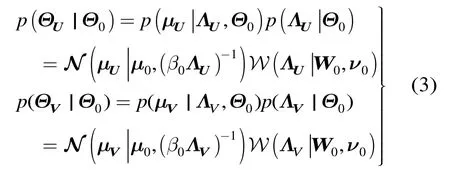

图1 Bayesian PMF模型[7]
BPMF模型一般用马尔科夫链蒙特卡罗方法进行训练,虽然预测误差较小,但仍然是一种线性模型。线性模型不能反映用户特征U和项目特征V之间的非线性关系,这一定程度上限制 BPMF的性能,特别是在数据稀疏条件下提取潜在信息的能力。
3 基于Logistic函数的BPMF算法
3.1 Logistic BPMF模型
Logistic函数是机器学习领域中常用的一种 S型函数,定义域为,值域为。Logistic函数在定义域内单调连续,呈现出先缓慢增长,然后加速增长,最后逐渐稳定的趋势,能够较好反映生物种群发展、神经元非线性感知、人类认知学习过程等[16]。受数理情感学中情感强度第一定律启发,本文用Logistic函数的横轴表示用户感知到的“刺激”,纵轴表示用户评分:用户受到的“刺激”为正,则评分大于评分均值;“刺激”越强烈,评分越高;原点附近评分随“刺激”变化较快,属于敏感区域;偏离原点处评分随“刺激”变化缓慢,属于麻木区域[16,17]。
Logistic BPMF模型如图2所示,其核心改进是假设用户 i对项目 j的评分 Rij服从均值为方差为的高斯分布,即
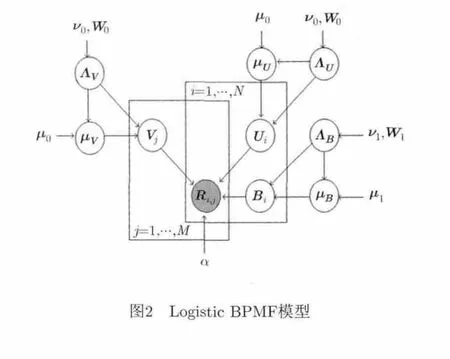
图2 Logistic BPMF模型



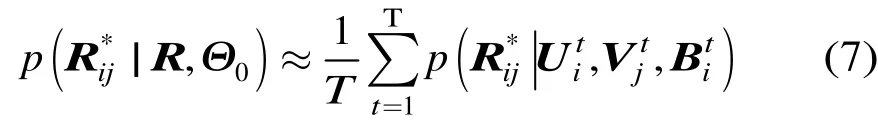
3.2贝叶斯推断与吉布斯抽样
. 贝叶斯推断(Bayesian inference)是将先验的思想和样本数据相结合,得到后验分布,然后根据后验分布进行统计推断。贝叶斯推断的精度受到样本数量和先验分布准确性的影响。在先验分布一定的情况下,样本数量越大则推断精度越高。本文在训练Logistic BPMF的过程中,使用吉布斯抽样进行贝叶斯推断。吉布斯抽样(Gibbs sampling)是一种典型的 MCMC方法,适用于联合概率未知,但条件概率容易获取的情况。首先利用条件概率构造平稳分布为所求联合概率的马尔科夫链,然后进行T次抽样,此时的样本可以近似认为是来自联合概率的抽样,最后利用式(7)进行评分预测。
使用吉布斯抽样方法进行贝叶斯推断,条件后验概率必须要有显示解,即明确的新样本产生规则。L-BPMF模型中,在已知其它参数的条件下,Ui的条件后验概率为

为了简化式(9)的形式,本文对Logistic函数进行麦克劳林展开, 于是

根据共轭先验分布理论:若方差已知,高斯分布均值的共轭先验分布是高斯分布[7],利用配凑平方和的方法可以得到


已知样本B,超参数BΘ的条件后验概率可以利用高斯-威沙特分布的性质得到。

3.3 算法复杂度分析
4 实验设计及结果分析
4.1 数据集合及评价标准
为了测试L-BPMF算法的有效性,本文采用推荐系统常用的两种数据集合:Netflix和MovieLens。Netflix数据集合是Netflix Prize比赛中使用的标准测试数据集,本文从中随机抽取了包含8662名用户对 3000部视频的约5310×条评分信息(评分密度为1.1%)作为测试集合。MovieLens数据集合由GroupLens提供,MovieLens 1M数据集包含了6039名用户对 3883部电影的610条评分信息(评分密度为4.3%);MovieLens 100K数据集包含了943名用户对 1682部电影的条评分信息(评分密度为6.3%)。
文献[18]全面总结了推荐系统领域各种不同的评价标准,文中采用检验推荐算法最常用的预测误差MAE和RMSE 作为评价依据,预测误差越小则表示算法性能越好。其中是测试集合,是testS 中的元素个数。

4.2 实验设计及结果
本文在上述两种数据集合上,以 MAE和RMSE为评价标准,设计了3组实验从不同方面对L-BPMF的性能进行测试,每组结果都是10次实验结果的平均值。
A组实验在Netflix和MovieLens 1M数据集合上,随机选取不同比例的训练集合,对L-BPMF和经典 BPMF进行了对比(特征维度 10d= ),使用RSVD(学习率lr 0.005= ,正则化因子的预测误差作为参考。实验结果如图3,图4所示。在Netflix数据集合上,L-BPMF比BPMF的预测误差小约1%,而且在训练比例较低时优势更明显,在训练比例为 20%时能够降低约 1.5%;在MovieLens 1M数据集合,L-BPMF比RSVD的预测误差小1%~2%,L-BPMF和BPMF预测准确性基本一致,在训练比例较低时L-BPMF略好一点。分析发现,Netflix数据集合的评分密度只有1.1%,而MovieLens 1 M的评分密度为4.3%。一种可能的解释是,评分密度较大时L-BPMF与BPMF的性能基本一致,评分较稀疏时L-BPMF比BPMF的预测误差更小。
为了验证上述结论,利用MovieLens 100K数据集合产生评分密度<1.5%的训练环境,进行B组测试。实际应用中的评分密度都在1%以下,稀疏条件下的实验更能反映算法提取潜在信息的能力。从图5中可以看出,L-BPMF的RMSE预测误差比BPMF低约2%,在最坏的情况下也能够降低约1%的预测误差。这说明L-BPMF提取潜在信息的能力要大于BPMF,能够有效缓解数据稀疏性问题。
C组以MAE为指标对比了L-BPMF和其它主流推荐算法(RSVD, SVD++, KNN, Slope One[19]),实验结果如图6所示[20]。其中,RSVD的参数与A组实验相同;SVD++算法中学习率lr 0.005= ,正则化因子; RSVD, SVD++的特征空间维度d为20, L-BPMF算法的特征维度为10。都只记录了训练过程中的最优值,并未记录过拟合现象。KNN算法中以皮尔森相似度公式计算相似性,选择与目标用户最相似的20个用户作为邻居进行预测。一般来说,KNN算法中邻居数目小于20时预测准确性会明显下降[14]。

图3 Netflix上L-BPMF与BPMF的对比

图4 MovieLens 1M上L-BPMF 与BPMF的对比

图5 稀疏条件下L-BPMF 与BPMF的对比
从图6中可以看出,L-BPMF和SVD++是预测误差最小的两种算法,L-BPMF的MAE误差比RSVD低约0.5%~1.5%。因为L-BPMF特征维度为10, SVD++的特征维度为20,而且L-BPMF的性能略高于SVD++,这说明L-BPMF能够用较小的特征维度d获得更高的预测准确性。

图6 主流推荐算法的MAE预测误差比较
5 结束语
本文针对经典贝叶斯概率矩阵分解模型不能表征潜在因子间非线性关系的问题,提出一种利用Logistic函数的L-BPMF模型,并使用MCMC方法对模型进行训练。在两种真实数据集合上的实验表明,L-BPMF能够明显提高预测准确性,用较小的特征维度获得比RSVD和SVD++更好的性能。在稀疏条件下的测试结果表明,L-BPMF比BPMF提取信息的能力更强,能够有效缓解数据稀疏性问题。
[1] Koren Y, Bell R, and Volinsky C. Matrix factorization techniques for recommender systems[J]. IEEE Computer,2009, 42(1): 30-37.
[2] Billsus D and Pazzani M J. Learning collaborativeGranada, 2012: 1134-1142.
[13] Lee J, Kim S, Lebanon G, et al.. Local low-rank matrix approximation[C]. Proceedings of the 30th International Conference on Machine Learning (ICML-13), Atlanta, 2013:82-90.
[14] Cacheda F, Carneiro V, Fernandez D, et al.. Comparison of collaborative filtering algorithms: limitations of current techniques and proposals for scalable, high-performance recommender systems[J]. ACM Transactions on Web, 2011,5(2): 1-33.
[15] LÜ Lin-yuan, Medo M, Yeung C H ,et al.. Recommender systems[J]. Physics Reports, 2012, 1(3): 159-172.
[16] Jordan M I. Why the logistic function? a tutorial discussion on probabilities and neural networks[J]. MIT Computational Cognitive Science Report , 1995, 9503: 1-13.
[17] 仇德辉. 数理情感学[M]. 长沙: 湖南人民出版社,2001:55-60.Qiu De-hui. Mathematical Emotions[M]. Changsha, Hunan People’s Publishing House, 2001: 55-60.
[18] 朱郁筱, 吕琳媛. 推荐系统评价指标综述[J]. 电子科技大学学报, 2012, 41(2): 163-175.Zhu Yu-xiao and LÜ Lin-yuan. Evaluation metrics for recommender systems[J]. Journal of University of Electronic Science and Technology of China, 2012, 41(2): 163-175.
[19] Lemire D and Maclachlan A. Slope one predictors for online rating-based collaborative filtering[J]. Society for Industrial Mathematics, 2005, 5(1): 471-480.
[20] 方耀宁, 郭云飞, 丁雪涛, 等. 一种基于局部结构的改进奇异值分解推荐算法[J]. 电子与信息学报, 2013, 35(6): 1284-1289.Fang Yao-ning, Guo Yun-fei, Ding Xue-tao, et al.. An improved Singular Value Decomposition recommender algorithm based on local structures[J]. Journal of Electronic& Information Technology, 2013, 35(6): 1284-1289.
