Keyword Language Identi fication in Uighur,Kazakh,Kyrgyz and Chinese Multi-lingual Dictionary System∗
2014-11-02MardanHoshurWiniraMusajan
Mardan Hoshur,Winira Musajan
(College of Information Science and Engineering,Xinjiang University,Urumqi,Xinjiang 830046,China)
Abstract: This paper takes the designing of Chinese,Uyghur,Kazak,Kirghiz Multi-lingual Multi-directional dictionary system as background,pointed out the language specific technical difficulties including how to determine the writing directions,how to distinguish the letters of Uyghur,Kazak,Kirghiz from each other.Then proposed corresponding solutions:using XML attributes and Unicode region analyzing method to determine the writing directions;calculate the usage rates of letters in specific words select the user de fined fonts.Applying results indicate the feasibility and validity of these solutions.
Key words:Dictionary;Multilanguage,Auto Detection;XML
0 Introduction
Rapid internationalization continues to expand multicultural society where people with different nationalities Zooming in,in the country like China,there are even many minority nations with their own languages such as Uighur,Kazakh and Kyrgyz are being in need of more interaction with majority peoples.In order to ease the multi-lingual interaction,people have developed machine translation and multi-lingual dictionary systems involve many languages.The Uyghur,Kazakh,Kyrgyz and Chinese multi-lingual dictionary system(shortly as UKK dictionary System)is one of the examples that consists of Uighur to Chinese,Kazakh to Chinese,Kyrgyz to Chinese and Chinese to other databases in eight directions with more than one million records(keywords may written in Uighur,Kazakh,Kyrgyz or Chinese)
In such a system,people may enter a keyword in one of the involved languages.Although,it seems not very necessary to automatically identify the language of the given keyword since,customarily,users are just asked to manually select the language direction they want.
But we considered that auto keyword identi fication between Uighur,Kazakh and Kyrgyz due to language identification technologies not only bring even better user experience in multi-lingual applications,but also is an important operation in multi-lingual resource processing.
Although,it is can be done with less effort and high quality when languages are quite similar.But when the brother languages are involved like Uighur,Kazakh and Kyrgyz it will be hard to achieve high identi fication quality since they have many common letters in their alphabets.
Uyghur,Kazakh and Kyrgyz are similar languages that belong to the Turkic language family and all are written in Arabic-derived system in the Xinjiang Uighur Autonomous Region,China.Although,they have their own alphabet respectively,but some letters of them are same in the script that led Unicode Consortium to allocate same IDs for them.These common letters both include vowels and consonants that it is possible to generate words by using them in all three languages.This is the main difficulty that auto detection faces.
In this paper,we have not only proposed an algorithm of keyword language auto identi fication between Uyghur,Kazakh and Kyrgyz languages,but also provided probability data of being detected of these languages to each other by calculating appearance-probability of letters in each language upon more than 600,000 multi-language records in the UKK dictionary system.
In addition,we also collected some letter connection rules which can contribute detection quality.
1 Unicode and UKK Alphabets
Uyghur,Kazakh and Kyrgyz may be written in a number of different orthographies,the Arabic-derived system being the most common in Xinjiang.Considering the being Arabic-derived futures,Unicode IDs for their alphabets are distributed in “Arabic”and “Arabic Presentation”(includes A-range and B-range)ranges of Unicode table.But they are not only in discontinues contribution,but also are sharing same IDs for same shaped letters.
ThebasicArabicrangeencodesthestandardlettersanddiacritics,butdoesnotencodecontextualforms(U+0621–U+0652 being directly based on ISO 8859-6).The Arabic Presentation Forms range encodes contextual forms,ligatures of letter variants spacing forms of Arabic diacritics and more contextual letter forms.
In the basic Arabic range,there are 42 codes allocated for 32 letters in Uighur alphabet,33 letters in Kazakh alphabet and 31 letters in Kyrgyz alphabets(detail will be given in the next section).Apparently,most of letters in each language have no unique code.Here are the language affiliations of three alphabets.

a:Basic form and unicodes of letters shared between Uighur,Kazakh and Kirgiz.
b:Basic form and unicodes of composed unique letters in Uighur.
c:Basic form and unicodes of unique composed letters in Uighur.
d:Basic form and unicodes of unique composed letters in Kazak.
e:Basic form and unicodes of unique composed letters in Kyrgyz.
f:Basic form and unicodes of letters shared between Uighur,Kazakh and Kirgiz.
g:Basic form and unicodes of letters shared between Kazakh and Kirgiz.
As it can be seen,unique letters could be the direct clue for the auto identi fication process.But for better identi fication quality,the connection rules of letters should also be taken into consideration.
2 Statics of Appearance Probability
In UKK dictionary system,in order to calculate the probability of being detected of certain language from others,we calculated appearance-probability of unique letters in its alphabet.But in some cases,like for Uighur,although the composed letters in setbare unique for Uighur,but their appearance-probability cannot represent Uighur itself since their simple forms are shared with Kyrgyz.For example,the letter“u”(0626+06C7)only appears in Uighur,but its simple form “u”(06C7)is common for both Uighur and Kyrgyz
The statistical result of the occurrence of Uighur letters based on 38 000 records in Uyghur to Chinese dictionary database are shown below

Based on the data above,we can calculate the appearance-probability of letters unique for Uighur with the following formula:

The statistical result of the occurrence of Kazakh letters based on 18,000 records in Kazakh to Chinese dictionary database are shown below.
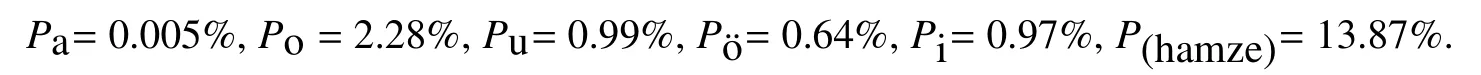
Based on the data above,we can calculate the appearance-probability of letters unique for Kazakh with following formula:

The statistical result of the occurrence of Kyrgyz letters based on 40 000 records in Kyrgyz to Chinese dictionary database are shown below.
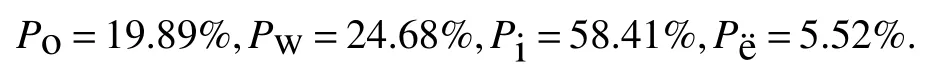
Based on the data above,we can calculate the appearance-probability of letters unique for Kyrgyz with the following formula:

Moreover,the letter“h”is common for Uighur and Kazakh.So we need statics data based on both in Uighur to Chinese and Kazakh to Chinese database shown as below:

In setg,although the letters“a”,“e”,“o”,“u”are common for Kazakh and Kyrgyz,but they can be used in Uighur by composing with an additional letter“i”.Therefore,the only case that a word contains these letter(s)could be Kazakh or Kyrgyz is to having one of them as its first letter.The probability of such a case in Kazakh and Kyrgyz database are shown below:
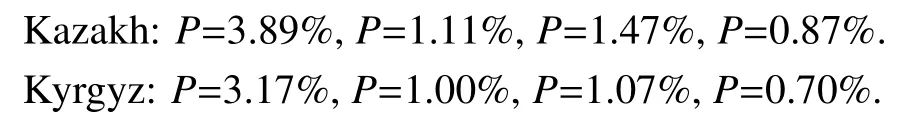
The letters“x”and “gh”are only specified for Kazakh and Kyrgyz so that we can determine “is not Uighur”if a word contains one or both of them.Below are statics data of these two letters.

3 Calculation of Auto Identi fication Probability
Based on the data in section 3,we can calculate appearance-probability of sets of unique letters which can represent language auto Identi fication probability when a certain keyword is given(shortly as global appearance probability)The calculation process is as follows.
Suppose that the variableuyis the amount of keywords(records)written in Uighur,kzis of Kazakh andkrfor Kyrgyz.(uy=380 000;kz=180 000;kr=40 000 with Ukk Dictionary databases).Then we can calculate the probability of being identi fied of each language.

Letters in setfandgare not unique for certain language.Therefore they cannot be participate global(probability in a condition that language is uncertain)calculation.But if a letter(suppose it asl)meets the conditionl∈f∧l∈g,then it can be determined as Kazakh letter and its global appearance-probability isl∈f∧l∈g=211%.
By combining these global probability values,the final auto identi fication probability can be calculated as follows:
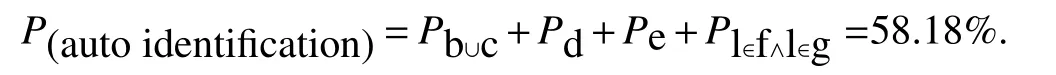
4 Auto Detection Algorithm
It can be seen from the calculation result in section 4 that if there is a proper algorithm,we can achieve more than 60%of auto identi fication rate between Uighur,Kazakh and Kyrgyz in UKK dictionary system in theory.The flow chart of an algorithm proposed in this paper is shown in Fig1.
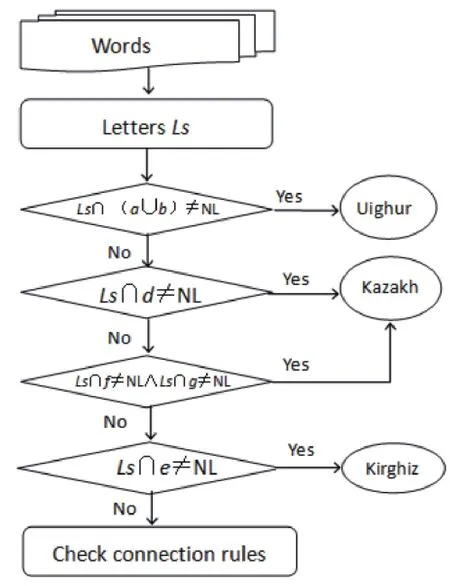
Fig 1 Flow chart of auto identi fication algorithm of Uighur,Kazakh and Kyrgyz
In addition,by analyzing 60 000 records,we found some useful connection rules of letters.
IfLsmeets the conditionLs∈{consonants},the given keyword can be determined as Kazakh.
If one of the four letters in set g is repeated,it can be determined that keyword is not Uyghur,or it is Kyrgyz if the repeated letter located at begging or ending of the keyword.
5 Conclusion
As a contribution of this paper,we processed statistical calculation about the probability of being identi fied of a keyword written in Uighur,Kazakh or Kyrgyz to each other based on more than 600 000 records(keywords may written in Uighur,Kazakh and Kyrgyz both including words and phrases)in the UKK dictionary system,and then proposed a corresponding auto identi fication algorithm in addition to founding some connections roles of letters unique for these languages.
Although the identi fication ratio up to 62%is not high enough,but as a first proposed algorithm about Uighur,Kazakh and Kyrgyz languages,this work may encourage further improvements.
The calculation result shows that identi fication ratio could reach 58.18%,but it could be increased up to 62%when connection roles of letters and some other special affiliations are considered.In other words,to UKK dictionary databases itself,there are 600 000×0.62=37 200 records can be automatically identi fied their languages which include 280 140(46.69%of 600 000)in whole 380 000 Uighur records,26 040(4.34%of 600 000)in whole 180 000 Kazakh records and Warning:30 240(5.04%of 600 000)in whole 40,000 Kyrgyz records Apparently,Uighur and Kyrgyz have much higher,Kazakh has the lower ratio of being identi fied based on statics data.This is mainly because Uighur not only has more unique letters,but also is taking the advantage of using additional letter“i”(it is also used in Kyrgyz as an independent letter,but in Uighur it should be composed with vowels),and for Kazakh,it has more words that mainly formed by shared letters.However,Identi fication ratio may be little different depends on amount of language resource to be processed in statics.
