基于键值存储的事务控制策略
2014-10-15张延园张向彬
白 皓,张延园,张向彬
(西北工业大学计算机学院,陕西 西安 710129)
0 引言
云数据库是SaaS(Software as a Service,软件即服务)成为应用趋势的大背景下发展起来的云计算技术,而键值存储模型是云数据库最常采用的数据模型。目前 Facebook 的 Cassandra[1]、Amazon 的 Dynamo[2](开源实现 Voldemort[3])、Google 的 Bigtable[4]等实际上都采取了类键值存储的方法。
键值存储系统[5]的目的是存储海量半结构化和非结构化数据,以系统横向扩展[6]的方法应对数据量和用户规模的不断扩展。由于现实应用的需求,传统关系型数据库的SQL访问方法及事务特性[7],键值存储系统也需要具备,所以需要在键值系统上建立关系型数据库的访问层,以兼具键值存储系统和关系型数据库的优点。传统的关系型数据库在多节点情况下的事务控制方法,即两阶段提交协议[8],由于复杂的控制逻辑与频繁的网络访问,不适应在大规模集群应用,具有十分严重的效率低下问题[9]。
Google的MegaStore[10]提出了支持实体组内事务的概念,实际上是传统事务的一个子集,目的是避免过于复杂和昂贵的分布式事务。通过预先定义事务的处理范围,将特定事务的控制实际上分配在特定单个节点。但是,MegaStore是Google内部使用的系统,与其业务密切相关,其实现细节并不对外公开,本文描述基于开源软件并且借鉴关系型数据库的技术来实现类似的事务机制,具有更好的可定制以及可扩展的能力。
1 键值存储的事务控制策略
1.1 系统总体设计思想
传统的DBMS都存在一个事务存储管理器[11],它包含相互紧密结合的4个组件:(1)负责并发控制的锁管理器;(2)负责恢复的日志管理器;(3)进行分批I/O处理的数据缓冲池;(4)负责如何在磁盘上存放数据的访问控制方法。
在云数据库的时代,产生了对事务服务和数据管理进行分离的需求,这种分离方法支持在云数据库中实现比较灵活的事务处理[12]。存储引擎分成两个部分,即事务组件(事务日志管理器)和数据组件(存储器)。事务组件只在逻辑层面工作,即它知道事务以及事务的逻辑并发控制和恢复,但是并不知道底层存储的结构;数据组件知道物理存储结构,它可以支持面向记录的原子访问操作,但是不知道事务。
根据事务服务和数据管理进行分离的设计思想,事务管理中涉及的组件列举如下:
(1)查询执行引擎;(2)事务日志管理器;(3)存储器(持久存储数据,实为Voldemort实现);(4)更新器(将事务日志异步更新至存储器,又称SYNC)。
事务系统结构图如图1所示。

图1 事务系统结构图
查询执行引擎执行应用程序的关系型语句,需要访问存储器和事务日志管理器。当实体组内事务提交成功,它将该事务中所有的写操作交给事务日志管理器来进行存储,事务日志负责保存那些还没有应用到存储器中的数据,数据更新器根据数据布局负责将事务日志应用到存储器。
1.2 数据布局与实体组
数据布局与实体组的概念,决定数据组件(存储器)和事务组件(事务日志管理器)的数据存储内容以及对应关系,是决定事务操作对象的核心。由于本文的主要内容是讨论事务的实现,因此只举一个最简单的例子,详细的描述请参照文献[13]。
在具有关系型数据的表1中,PK代表主键,TK代表事务键,具有相同的事务键的数据属于一个实体组。

表1 数据布局与实体组划分
在存储器上存储时,以PK为key,整条记录为value进行存储。在事务日志管理器上存储时,以TK为key,将事务日志存储在value中。需要注意的是,事务日志中并不是将同一个实体组中的所有元组录入,而只是跟该事务相关的元组。所以,事务日志管理器的负荷来自于事务的多少及每个事务的大小,而存储器的负荷是所有元组的总量的大小,方便系统针对不同应用情况进行横向扩展。
1.3 事务分散方法
事务分散方法是指通过预先定义的事务处理范围,明确任何一个数据元组(key-value对)的归属(实体组),并且任何一个事务都应该局限于一个实体组中。同一个事务组内的各事务日志存储在事务日志管理器的某一节点。

图2 数据分散与事务范围
如图2所示,不管其来自任何客户端,任何事务的操作对象都应该被分配在一个确定的实体组中。可以看到,图2中虚线连接的2个事务破坏了这条规则,它们是非法的,应该在提交时失败。结合1.2节中的数据,举例如下。
(1)合法事务(事务的操作对象局限在TK=1的实体组内)。

(2)非法事务(事务的操作对象分别在TK=1和Tk=2的实体组)。

2 查询执行引擎
查询执行引擎由一个或多个查询执行节点组成,各节点之间无关,是应用程序与系统的连接部分,将用户输入的每个SQL语句进行编译为一个执行计划,执行该计划,并返回结果。执行计划为key-value对的操作的集合,key-value对的操作为get、put和delete共3种。图3为一个事务的执行过程示意图。

图3 一个事务的执行过程
应用程序输入语句和事务语句后,通过与查询执行引擎连接,将SQL语句和事务语句传输给查询执行引擎。当查询执行引擎执行事务(开始执行事务和提交事务)时,访问事务日志管理器。开始执行事务时,读该事务所属事务组的日志集合(WAL)。在查询执行引擎中,基于有限访问模式的SQL优化器、SQL解析器/编译器访问元数据,然后产生查询计划。执行引擎和事务管理器使用乐观并发控制的方式来执行该查询计划,这中间可能需要访问存储器(data)来得到尚未在事务日志中缓存的数据,并缓存所有的写操作。最后,使用键值存储中的put-if-current原子操作来提交事务至该事务所属事务组的日志集合。在执行过程中,事务管理器识别事务键的值并使用它来提交一个事务。由于各个查询执行节点并不相关联,所以查询执行引擎的横向扩展只需单纯地增加节点即可。
3 事务日志管理器
3.1 事务日志管理器构成
事务日志管理器是由多个服务器组成的Voldemort集群,用来处理分布式的事务日志。事务日志管理器为每个事务组分发一个固定的key,通过一个特定的哈希函数将该key映射到一维空间上,落在一维空间的某一分区,由负责该分区的节点进行处理,从而将分布式事务转化为在单个节点上处理的事务。该节点对同一个事务组内的事务日志进行存储和管理,每个提交的事务形成一个事务日志,并按提交时间的顺序具有唯一的时间戳,这些日志构成事务组事务日志的集合。每个事务日志用于更新存储器中的不相关联的数据集合。由于Voldemort本身具有非常好的扩展性,事务日志管理器和存储器的横向扩展是非常容易的。
3.2 事务提交和冲突检查
当同一事务组内多个事务并发时,它们在提交时都需要经过冲突检查,才能成功提交,转化为一个事务日志。冲突检查机制采用并发版本系统的方法,并且充分利用键值对象的特征,针对key进行检查,而不是对数据元组进行对比,提高了检查的效率。
在进行检查时,没有发生冲突的日志条目,就称检查成功。如果当前正在进行提交的事务在事务提交前读取了一个键值对象,然后其他事务对这个键值对象进行了写操作产生了日志条目,则这个正在提交的事务就与产生的日志条目发生了冲突。
一个检查通过一个时间戳和一系列的读集合来进行呈现。检查的时间戳是由事务启动时得到的值。

一个读集合包含了在同一个实体组中的一系列的key值。

如图4所示,进行检查时,事务管理器检查是否有任何位于Tc和Current之间的写操作与读集合发生冲突,Tc为检查的时间戳。如果 Tc的值小于OLDEST,则事务管理器无法保证冲突没有发生。在这种情况下,检查返回的结果为false。

图4 冲突检查
在事务执行期间,查询执行引擎会缓存所有的写操作和记录下所有可能与其他事务发生冲突的读集合。
当事务请求提交时,查询执行引擎使用已经记录下的读集合和时间戳Tc来进行一个检查操作。当检查请求返回true时,事务则成功提交;否则,事务被拒绝,查询执行引擎应该重新开始或者丢弃该事务。
4 实验结果与分析
4.1 验证结果与分析
为了验证事务控制的正确性,采取了tpc-c[14]中的表结构和事务来进行实验。
实验环境为查询执行引擎若干台,事务日志管理器3节点,存储器3节点。采用的参照更新比例为95:5,实验得到的数据如表2所示。
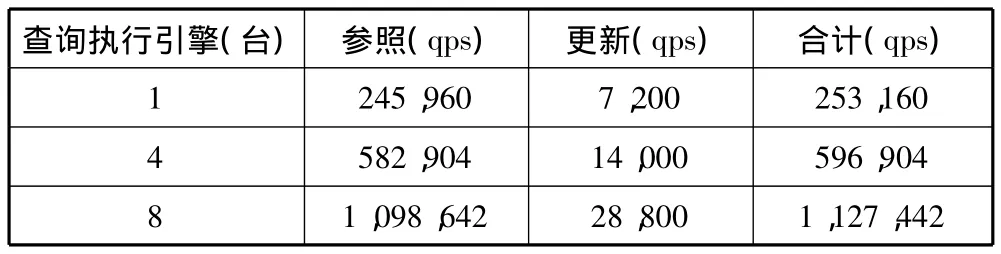
表2 实验结果
表2中,qps表示每秒钟执行的SQL语句数。
经过实验,本系统能在分布式的条件下具有较好的事务特性。
4.2 开销分析
由于关系型查询语句和事务的处理不可能只涉及某存储节点上的某一条键值对的数据,在语句执行时因需要访问多个存储节点上的数据会造成系统响应过慢而浪费网络资源。因此,设定事务访问的模式,然后根据事务处理的特点和访问的方式,将事务处理过程中需要用到的数据从各个存储节点上读取出来,集中到事务日志管理器的对应节点中,从而使用该节点的数据来进行查询和更新操作,保证了事务的ACID特性,减小了网络资源的使用,极大地提升了事务处理的速度。
5 结束语
本文探讨了如何在分布式键值存储系统中实现有限制的高速事务,使其满足ACID特性。在分布式系统键值存储系统中,事务的分布式控制是非常复杂的,网络访问非常耗时并且带来了更多的复杂性,本系统通过限制事务数据的范围,减少网络访问的次数。在提交验证时,也充分利用键值系统的特点,并结合传统关系型数据库事务控制的方法,从而实现了在键值系统上的事务ACID特性。
[1]Avinash Lakshman,Prashant Malik.Cassandra:A decentralized structured storage system[J].ACM SIGOPS Operating Systems Review,2010,44(2):35-40.
[2]De Candia G,Hastorun D,Jampani M,et al.Dynamo:Amazon’s highly available key-value store[J].ACM SIGOPS Operating Systems Review,2007,41(6):205-220.
[3]LinkedIn.Project Voldemort[EB/OL].http://www.project-voldemort.com/voldemort/,2013-03-19.
[4]Chang F,Dean J,Ghemawat S,et al.Bigtable:A distributed storage system for structured data[J].ACM Transactions on Computer Systems,2008,26(2):Article No.4.
[5]Wikipedia.NoSQL[EB/OL].http://en.wikipedia.org/wiki/NoSQL,2012-07-07.
[6]中国存储网.什么是Scale Up和Scale Out?[EB/OL].http://www.chinastor.com/a/jishu/scale.html,2011-06-13.
[7]Jim Gray,Andreas Reuter.Transaction Processing:Concepts and Techniques[M].Morgan Kaufmann,1992.
[8]刘威.分布式数据库及其技术[J].长春大学学报,2000,10(1):27-30.
[9]Browne J.Brewer’s CAP Theorem[DB/OL].http://www.julianbrowne.com/article/viewer/brewers-cap-theorem,2009-01-11.
[10]Baker J,Bond C,Corbett J,et al.Megastore:Providing scalable,highly available storage for interactive services[C]//Proceedings of the 5th Biennial Conference on Innovative Data Systems Research.2011:223-234.
[11]林子雨,赖永炫,林琛,等.云数据库研究[J].软件学报,2012,23(5):1148-1166.
[12]Lomet D,Fekete A,Weikum G,et al.Unbundling transaction services in the cloud[C]//Proceedings of the 4th Biennial Conference on Innovative Data Systems Research.2009.
[13]宋慧,张延园,何娟娟.基于键值存储上中间件技术的研究[J].计算机与现代化,2013(1):77-80.
[14]Meikel Poess,Chris Floyd.New TPC benchmarks for decision support and Web commerce[J].ACM SIGMOD Record,2000,29(4):64-71.
