超高清实时H.264/AVC编码系统设计
2014-09-18高志勇张小云
邓 刚,高志勇,张小云
(上海交通大学电子工程系图像通信与网络工程研究所,上海200240)
视频是人类娱乐活动的一种主要方式之一。H.264/AVC是目前最通用的一种视频压缩标准,在保证视频高质量的同时降低对存储空间以及传输带宽的需求。随着社会的进步,人类对视频质量的要求越来越高,高分辨率视频正是其中的一项重要需求。超高清视频编码存在数据吞吐量大、计算复杂度高、码流码率大的特点和难点。多核处理器处理性能的提升以及通信网络的发展使得超高清实时H.264视频编码成为可能。
H.264视频编码具有很高的计算复杂度,而超高清(本文特指3 840×2 160的视频)视频编码的复杂度至少是是高清(1 920×1 080)视频编码的3~4倍。具有强大运算处理能力的多核处理器为视频并行编码提供了良好的平台基础,通过合理地设计视频编码的并行任务划分与调度,充分运用多核处理器的并行能力,能够达到实时的要求。处理器性能的提升解决了视频编码计算复杂度高的问题。同时因超高清的巨额数据量,编码过程中像素的存取也是编码器性能的瓶颈之一。根据视频编码的特点以及操作系统内核的内存管理机制,本系统设计的高效内存管理方案将有利于提升编码速度与视频质量。
本文以Tilera[1]公司的TILE-Gx36处理器为核心,设计与实现了超高清实时H.264编码系统。其中摄像机负责采集超高清原始视频序列,FPGA板卡负责视频序列预处理,多核处理器负责视频编码与RTP[2]格式封装,实现视频单播功能。
1 编码系统总体架构
编码系统由超高清摄像机采样得到原始的YUV序列,FPGA采集板对原始的YUV序列进行预处理并存储至内存中,TILE-Gx36处理器对内存中的视频序列编码并封装成RTP格式输出。系统的流程包括3个步骤,如图1所示。
图1 超高清编码系统
1)原始视频序列采集
超高清摄像机负责采样原始视频序列,支持的超高清格式包括24 f/s与60 f/s序列。摄像机输出包括4路HDMI口,其中每路HDMI支持1.3规范,可输出1 920×1 080分辨率的视频序列。4路HDMI输出均连接至FPGA采集板的输入口。
2)视频序列预处理
FPGA采集板接收摄像机传输的4路HDMI视频序列,将4路高清序列拼接成完整的超高清序列。本设计中的超高清编码器目前仅支持帧率小于或等于30 f/s时的视频序列,当摄像机输出格式为60 f/s时,FPGA采集板负责下采样将其转换为30 f/s格式。为减少CPU资源的占用率,FPGA采集板通过基于PCIe接口的DMA方式将视频序列存储至内存设备中。其中视频存储格式符合编码器的格式要求,编码时无须进行格式转换,以降低编码复杂度。
3)视频编码与RTP打包传输
TILE-Gx36处理器对内存中的原始视频序列进行并行编码输出压缩后的比特流,再进一步对比特流进行RTP格式封装并通过网卡控制器输出至网络中。接收端使用支持RTP格式的播放器即可解码回放,实时观看。
2 编码系统设计
2.1 原始像素内存管理
H.264/AVC编码器计算复杂度高,在程序运行过程对内存容量与带宽需求较大,其中像素的存储管理占用了较大空间与带宽。超高清视频为YUV420(3 840×2 160@30 f/s)格式时,原始像素的吞吐量约为356 Mbyte/s,重建像素也会占用一定的内存空间与带宽。本设计中采用高效的原始像素存储管理策略,降低内存需求。
采集线程负责将经过FPGA板卡预处理后的原始像素存储至RAM,编码线程对RAM中的原始像素进行编码。采集线程的采集速度是视频序列的帧率(30 f/s),编码线程的编码平均速度应快于30 f/s才能达到实时编码。根据H.264/AVC标准,采用B帧编码时,编码序列与显示序列(即采集序列)不一致,因此采集线程与编码线程的处理顺序不一致,需要同步机制。另一方面,编码系统是通过库函数malloc()/free()调用实现对内存的分配释放。在编码过程中,原始视频序列随着时间不断更新,如直接进行内存的分配与释放,则会引入内存分配释放函数调用的开销,同时增加了操作系统内存管理的复杂度,降低系统性能。本编码系统使用固定数目的帧存空间来存储原始像素,避免过多的内存分配释放操作。设置原始像素的帧存数目为15,帧存中的每一帧将处于下述3种状态之一:FREE,READY,ENCODING。如图2所示,编码初始化15帧状态均为FREE状态,采集线程成功采集完一帧图像时则设置为READY状态,编码线程开始处理原始图像帧时则设置为ENCODING状态,编码完成则设置为FREE,如此循环往复。其中采集线程与编码线程对15帧的原始像素帧的管理根据各自的特点而采取不同的管理策略。

图2 帧存状态转移图
采集线程端维护两个链表,空闲帧链表(Free_list)与非空闲帧链表(Not_Free_list),如图3所示。空闲帧链表是处于FREE状态的帧集合,非空闲帧链表是处于READY与ENCODIING状态的帧集合。当摄像机端的原始图像数据到来时,如果空闲帧链表非空,则采集原始像素图像至空闲帧链表头部,并将其移至非空闲帧链表尾部;如果链表为空,则说明编码器不能实时编码,可以通过丢帧的方式继续编码。当编码器完成一帧编码时,将该原始帧移至空闲链表尾部。
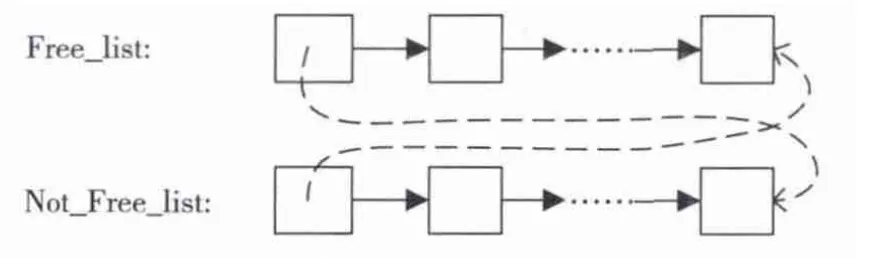
图3 采集线程链表管理示意图
编码线程端维护15帧的状态数组hdcap_frame[15],其中数组中的元素包括以下信息:帧存储的逻辑地址,帧索引号frame_index(按显示顺序递增0,1,2…),以及其他有效的参考信息等。编码线程负责从采集线程的非空闲帧链表获取处于READY状态的原始图像,存储规则为hdcap_frame[frame_index%15]。编码时直接通过帧索引号进行帧的查找。
2.2 并行编码器设计
H.264编码器可以采用不同颗粒度[3]的并行加速方式,主要包括有图像组并行[4]、帧级与条带级并行[5]、宏块级并行[3]、基于编码功能模块的任务并行[6]、指令级并行[7]等。H.264并行编码可采取单颗粒度或多颗粒度并行方式,其中多颗粒度并行方式能获得更好的加速比以及并行扩展性。
图像组并行以GoP为基本处理单元,GoP间不存在数据依赖关系,适合数据并行。延时是实时编码系统的一项重要指标,其中包括编码延时与传输延时。图像组并行将使得较长的原始视频序列同时处于编码状态,易产生延时。帧级与条带级并行、宏块级并行均属于数据并行,基于不同功能模块的流水线执行方式属于任务并行。指令级并行主要是采用单指令多数据指令对编码计算比较规整的数据操作进行优化,包括运动搜索、亚像素插值、变换量化、去块滤波等。指令级并行主要是单核性能优化,可以与其他并行方式嵌套组合。
由于数据并行具有良好的可扩展性[8],本设计的编码器采用帧级与条带级并行、指令级并行的方案进行编码。为了达到实时编码速度、较高的视频质量以及较低的编码延时,设定编码器的GoP结构为IPBB,P条带具有两帧参考图像,B条带具有前后各一帧参考图像。如图4所示,在启动B条带编码时,只须满足如下条件:在B条带的候选垂直运动向量范围内,参考图像已经重建完成。P条带的启动规则与B条带类同。条带的编码启动规则充分利用运动向量在垂直范围的有限性,无须整幅参考图像重建完成,减小了数据依赖性,利于并行。实际应用中,可根据处理器单核的性能和可使用核的数目,通过调整一帧内的条带数以及可并行编码的帧数来产生合适的并行任务。
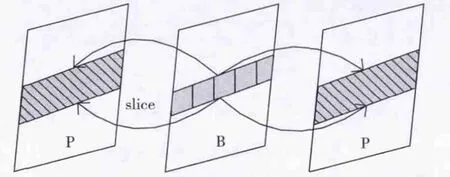
图4 帧级与条带级并行
2.3 视频码流RTP封装传输
RTP协议(Real-time Transport Protocol)是由IETF的音视频工作组提出,主要用于端到端的实时网络传输应用,工作组对H.264的RTP封装格式[9]提出了规范。
由于超高清视频编码的码流比特率大,设计时需要考虑RTP包传输的瞬时吞吐量。编码器采用了帧级并行进行加速,故需要将比特流按照编码顺序进行码流重组输出,从而码流易出现瞬时的大吞吐量输出。网络视频流的传输应尽可能保证单位时间内RTP包的吞吐量波动小,能减少丢包的发生。本设计通过在编码线程与RTP封装线程间设置一个码流FIFO缓冲器,保证RTP包的吞吐量尽可能稳定。如图5所示,编码线程将压缩码流输出至FIFO中,RTP封装线程对FIFO中的码流进行打包封装并传输至网络。
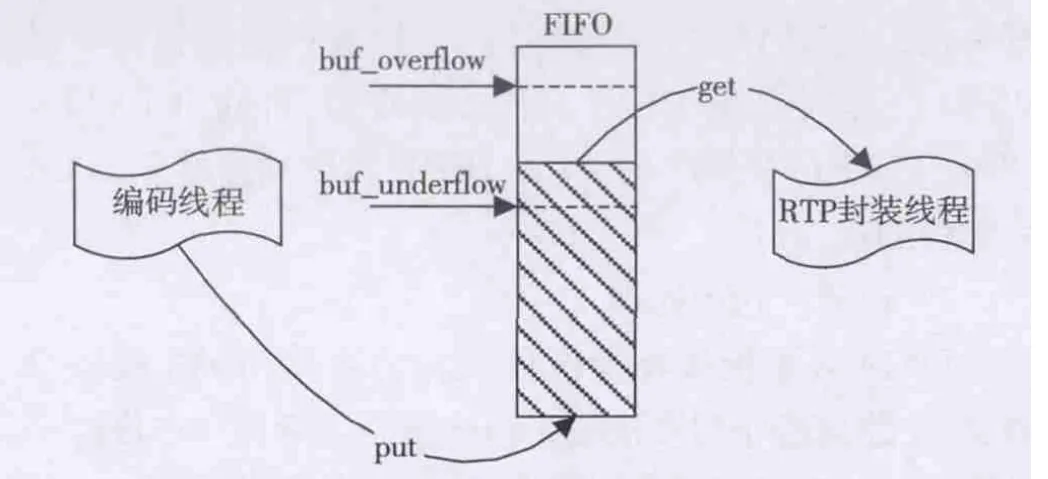
图5 码流FIFO缓冲示意图
编码系统初始化时,FIFO缓冲器为空。随着编码线程不断输出比特流至FIFO中,码流累积至buf_average=(buf_overflow+2×buf_underflow)/3时,RTP封装线程开始进行打包。其中RTP封装线程定期(约20 ms)查询FIFO中的有效码流长度(见图5中的阴影部分),并根据过去一段时间内(约1 s)的RTP包传输速度的统计,设置当前的打包速度。采用上述策略以及编码器自身的码率控制策略,使比特流的长度处于图中的buf_underflow与buf_overflow之间,保持RTP包的传输速度稳定。
3 编码系统实验结果
3.1 编码系统设备组成
整个编码系统所使用的设备包括:超高清摄像机使用JVC GY-HMQ10U设备,输出4路1 080p视频;运算处理器使用Tilera公司的TILE-Gx36多核处理器,该处理器由36个同构核组成,单核支持最高运行频率1.2 GHz;客户端使用基于x86平台的VLC播放器接收RTP码流实时回放。
3.2 超高清编码性能测试
编码系统的核心在于编码器的并行性能,本次测试输入为3个超高清YUV视频序列,设置GoP结构为IPBBPBB,GoP长度为16帧,输出码率为25 Mbit/s。
在核数足够的前提下,仅采用条带级并行加速的实验结果如图6所示。由于同一帧图像中的不同条带编码速度不完全一致,编码已完成的条带需要等待编码尚未完成的条带,由此引入了同步等待时间。因此编码速度相对于条带数的增长呈非线性增长。当条带数为16时,3个序列的编码速度为18~23 f/s。
在核数足够的前提下,设置一帧的条带数为14,在不同并行帧数下的编码实验结果如图7所示。设GoP格式为 I0P3B1B2P6B4B5,当 I0与 P3编码完成时,B1、B2、P6这3帧图像间无数据依赖关系,可同时编码,因此3帧并行时的编码速度呈线性增长趋势。
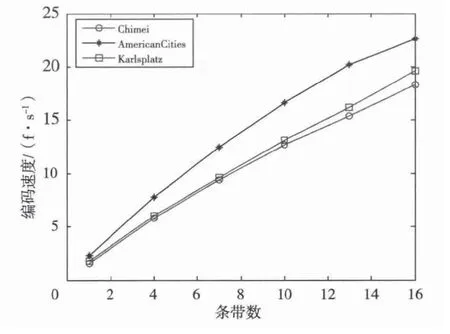
图6 条带级并行测试
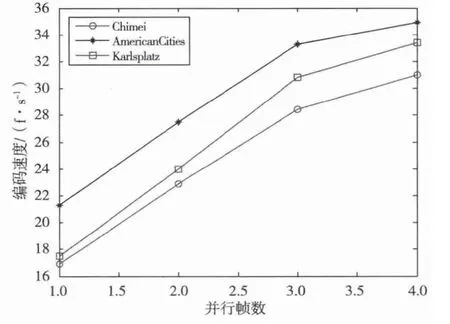
图7 帧级并行测试
设置一帧的条带数为14,可同时并行的帧数为4,在不同核数下的编码实验结果如图8所示。随着核数增加,编码速度随之增加并趋近饱和。可以看出,当核数为21时,3个序列的编码速度大于30 f/s,满足实时编码的需求。
4 小结
本文设计并实现了实时的超高清H.264/AVC视频编码系统,包括原始视频序列采集与预处理,并行视频编码,比特流RTP封装传输。实验结果表明,仅使用1片TILE-Gx36处理器就能够实现实时超高清视频编码。
:
[1] Tilera[EB/OL].[2013-10-21].http://www.tilera.com/.
[2] FREDERICK R,JACOBSON V.Rtp:a transport protocol for real-time applications[S].2003.
[3]于俊清,李江,魏海涛.基于同构多核处理器的H.264多粒度并行编码器[J].计算机学报,2009,32(6):1100-1109.
[4]蒋兴昌,周军,罗传飞.H.264并行编码算法的研究[J].电视技术,2008,32(2):33-35.
[5]叶朝敏,陈颖琪,高志勇.基于多核处理器的高清实时MPEG-2—H.264转码器设计[J].电视技术,2012,36(21):15-19.
[6]吕明洲,陈耀武.基于异构多核处理器的H.264并行编码算法[J].Computer Engineering,2012,38(16):35-39.
[7] LEE J,MOON S,SUNG W.H.264 decoder optimization exploiting SIMD instructions[C]//Proc.IEEE Asia-Pacific Conference on Circuits and Systems(APCCAS).[S.l.]:IEEE Press,2004:1149-1152.
[8] LIN C,SNYDER L.Principles of parallel programming[M].陆鑫达,林新华,译.北京:机械工业出版社,2009.
[9] WENGER S,STOCKHAMMER T.RTP payload format for H.264 video[S].2005.
