不确定XML序列匹配等价性研究
2014-09-10张晓琳
张晓琳,王 鹏
(内蒙古科技大学 信息工程学院,内蒙古 包头014010)
0 引 言
由于概率信息需要特殊处理,以往针对普通XML的小枝模式匹配方法[1,2]并不能直接应用到不确定XML上,这就引发了不确定XML中小枝模式匹配等价性的研究。
目前,实现不确定XML小枝模式匹配的方法有二元结构连接和整体匹配两种。二元结构连接[3]会产生大量无用的中间结果,影响查询的效率。整体匹配的方法[4-7]由于查询过程过于集中,概率信息需要进行单独处理,对查询效率也有一定的影响。本文将序列匹配应用到不确定XML小枝模式匹配,可以避免二元结构连接中繁复的结构连接操作,并可以在查询中对概率信息进行统一处理。具体使用的是序列匹配中经典的LCS-TRIM算法[8],所做的主要工作如下:①针对不确定XML中模式树序列化等价性和子序列匹配等价性进行分析和证明,消除了假不予考虑。②针对不确定XML中结构过滤等价性进行分析和证明,消除了假警报。③通过实验验证了不确定XML序列匹配算法的等价性及其效率。
1 相关定义
定义1 小枝模式匹配 (twig pattern matching),给定一个Twig Query查询Q= (VQ,EQ)和一个XML数据库D= (VD,ED),在D上匹配Q的过程就是Q的查询节点到D 的元素节点的映射过程h:{u:u∈Q}→{x:x∈D},满足下列条件:
(1)对每一个查询节点u∈Q,D的元素节点h(u)与u具有相同的TagName,且满足u的谓词要求;
(2)对Q中的每一条边E(u,v),D的元素节点h(u)是h(v)的祖先 (或者父亲)。
定义2 模式树 (pattern tree),一个模式树定义为P=(T,F),其中T= (V,E)是一个节点标记和边标记的树,F是一个布尔式,并有:
(1)V中的每个节点标记了一个唯一的整数;
(2)E中的每条边标记了pc(表示父子关系)或ad(表示祖先后裔关系);
(3)F是作用在节点上的谓词的布尔组合。
定义3 嵌入 (embedding),令P= (T,F)为一个模式,C为一个树的集合。从P到C的嵌入是从T中的节点到C中节点的一个完全映射h:P→C,满足:
(1)h保持了T中的结构关系,即只要h定义在节点u和v上面,如果 (u,v)是一条pc(或ad)边,那么h(v)是h(u)的孩子 (或后裔);
(2)h的映像满足布尔式F。
定义4 实例树,witness tree.令C是树的集合,P=(T,F)是一个模式树,h:P→C是一个嵌入,则实例树如下定义:
(1)如果节点n根据映射h匹配某个模式树节点,则n在实例树中;
(2)对实例树中的任意一对节点n和m,只要在所有实例树节点中,根据C,m是n最近的祖先,则实例树中包含边 (m,n);
(3)实例树保持了C中节点的次序。
从定义1可以看出,小枝模式匹配只是限定了实例树中节点的父子关系和祖先后裔关系,并没有限定节点的兄弟关系。在LCS-TRIM算法中,由于序列匹配自身的特点限定了实例树中节点兄弟之间的关系,查询结果称为嵌入子树。
定义5 嵌入子树 (embedded subtree),限定节点兄弟关系的实例树称为嵌入子树。
通过模式树序列化可以将嵌入子树与实例树统一,详见2.1节。
序列匹配最重要的是匹配结果等价性问题,有两种情况可能导致匹配结果不等价,分别是假警报和假不予考虑。
设D为XML文档,Q为查询,g为序列化方法。
定义6 假警报 (false alarm),g(Q)在g(D)中能找到一个匹配的子序列,但是Q在D中却找不到对应的树片段。
定义7 假不予考虑 (false dismissal),g(Q)在g(D)中不能找到一个匹配的子序列,但是实际上Q在D中有对应的树片段。
2 序列匹配等价性
2.1 模式树序列化等价性
不确定XML小枝模式匹配输入的模式树可以用路径表达式来描述,其中 “/”表示父子关系, “//”表示祖先后裔关系。如图1所示的模式树可以用路径表达式R [A/B]//C来描述。序列化方法中模式树的每个节点描述为 (postorder,tag,ppostorder,R),其中postorder为节点在模式树中的后序遍历编号,tag为节点的内容,ppostorder为该节点父节点的postorder。R表示该节点与上下文节点之间的关系,R= “pc”表示父子关系,R=“ad”表示祖先后关系。
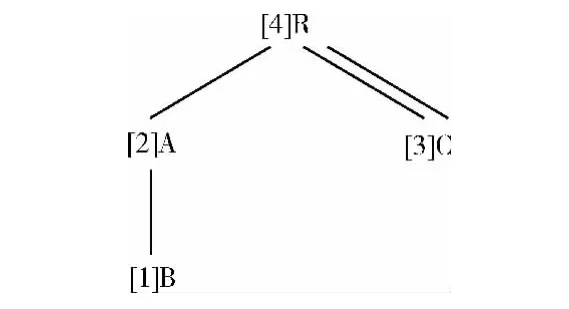
图1 模式树
定义1只限定了父子关系和祖先后裔关系,并没有限定兄弟之间的关系,因此路径表达式R [A/B]//C实际对应5种模式树,如图2所示。

图2 R [A/B]//C对应的模式树
一个带有分支结构和祖先后裔关系的路径表达式对应多个模式树,如果查询时只针对一种模式树进行序列化,只能得到部分结果,那么就存在假不予考虑,所以要进行正确的查询必须将路径表达式对应的所有模式树进行序列化。如图2 (a)序列化为 (1,B,2,pc), (2,A,4,pc),(3,C,4,ad), (4,R,-,-),图2 (b)序列化为(1,C,2,ad), (2,B,3,pc), (3,A,4,pc), (4,R,-,-),图2 (c)序列化为 (1,C,4,ad),(2,B,3,pc),(3,A,4,pc), (4,R,-,-),图2 (d)序列化为(1,B,3,pc), (2,C,3,ad), (3,A,4,pc), (4,R,-,-),图2 (e)序列化为 (1,C,3,ad),(2,B,3,pc),(3,A,4,pc), (4,R,-,-),查询的结果取它们的并集。与其它的查询处理方法相比列举出路径表达式所对应的所有模式树需要额外的工作量,这也是序列匹配方法的缺陷,但在实际应用中这种缺陷并不存在。
定理1 对于有序文档并不需要针对所有的模式树结构进行查询,只需查询一种符合DTD结构的模式树就能得到所有的结果。
证明:通过对来自实际应用中的众多数据集进行分析发现,数据集中元素的出现次序是有序的。以具有普遍代表性的SIGMOD Record数据集[9]为例,如图3所示,先出现元素title,然后出现元素initPage,最后出现元素end-Page,当title、initPage和endPage再次出现时依然按照这个次序,其它的元素同样也是有序的。因此图2(a)与图2(c)不会同时出现,因为在实际XML文档中节点A或者出现在节点C前面,或者出现在节点C后面,只存在一种顺序,同理图2(d)与图2(e)也不会同时出现。

图3 SIGMOD Record数据集片段
在实际应用的XML文档中元素的嵌套也是有序的 (依据DTD),如图3所示,元素articles是元素authors的父节点,元素authors是元素author的父节点,当元素articles、authors和author再次出现时,仍然按照这个关系进行嵌套,其它具有嵌套关系的元素也是有序的。因此在一个文档中图2(a)、图2(b)与图2(d)不会同时出现,因为在实际的XML文档中节点A、B、C只存在一种嵌套关系。证毕。
综上,根据定理1在实际的文档中图2所示的5种模式树结构只能出现一种,如果在路径表达式中限定兄弟关系,那么图2(a)对应的路径表达式为R [A/B]//C,图2(b)对应的路径表达式为R/A/B//C,图2(c)对应的路径表达式为R [//C]A/B,图2 (d)对应的路径表达式为 R/A[B][//C],图2 (e)对应的路径表达式为 R/A [//C][B],这样应用到序列匹配中就能更明确查询的结构。
2.2 子序列匹配等价性
定义8 子序列 (subsequence),某个序列的子序列是从最初序列通过去除某些元素但不破坏余下元素的相对位置而形成的新序列。
定理2 子序列匹配在不确定XML和普通XML中是等价的,即不含假不予考虑。

证明:L文档与普通XML文档相比加入了概率分布节点,但加入概率分布节点之后并不改变后序遍历文档树所生成的LS序列 (label sequence)和 NPS序列 (numbered prüfer sequence)中节点的顺序。因为后序遍历的顺序是“左右根”,加入概率分布节点之后不会改变原XML文档中节点的兄弟关系 (“左右根”中的 “左”和 “右”的关系),即在原文档中为某节点左兄弟的节点在加入概率分布节点之后不会变成该节点的右兄弟。加入概率分布节点之后也不会改变原XML文档中节点的祖先后裔关系 (“左右根”中的 “左右”和 “根”的关系),即原文档中某节点的后裔节点在加入概率分布节点之后不会变成该节点的祖先节点,因此子序列匹配在不确定XML和普通XML中是等价的。证毕。
2.3 结构过滤等价性
子序列匹配的结果只是模式树内容的匹配,一些结果的结构并不符合模式树的结构,所以要进行结构过滤筛选出结构符合模式树的最终结果,消除假警报。
算法:结构过滤
输入:序列化文档树Dtree,序列化模式树Ptree
输出:实例树Wtree

定理3 结构过滤在不确定XML和普通XML中是等价的,即可以消除假警报。
证明:结构过滤的主要思想是模式树中两个相邻节点与子序列匹配结果n元组中对应的两个相邻节点的结构进行对比。普通XML文档与不确定XML文档结构过滤的差异只存在于当模式树中两个相邻节点为父子关系时 (对应结构过滤算法4~15行),这时n元组中对应的两个相邻节点除了可以是父子关系,还可以是只包含概率分布节点的祖先后裔关系,这样就可以利用原来的结构过滤算法把概率分布节点当作普通节点来处理。因此结构过滤在不确定XML和普通XML中是等价的。证毕。
3 实 验
实验中的程序采用Java语言实现,实验环境为PC机,Windows XP平台,主频2.0GHz,奔腾双核处理器,内存2GB。实验所采用的数据集是在University Courses数据集[10]中的reed.xml(里德学院的课程信息)结构基础上随机插入概率分布节点以及概率值生成的不确定数据集。实验中使用的reed.xml大小为138KB,加入概率分布节点之后的reed.xml大小为145KB,通过反复叠加后形成的不确定XML文档大小为58MB。实验所用的查询语句见表1。实验中将LCS-TRIM算法应用到普通XML文档 (记为XML)和不确定XML文档(记为PrXML),对2.2节定理2和2.3节定理3进行验证,并与文献 [6]中Holistic Twig算法的效率进行对比。

表1 实验用到的查询语句
算法的查询效率对比如图4所示,在相同大小的PrXML(58MB)下,对于不同的查询语句 (Q1~Q5),LCS-TRIM算法的效率都高于Holistic Twig算法,这是因为LCS-TRIM算法将概率分布节点当作普通节点来处理,统一的操作提高了查询效率。子序列匹配等价性如图5所示,对于不同的查询语句 (Q1~Q5),在PrXML (145KB)和XML(138KB)中子序列匹配得到的相应结果数量是相等的。结构过滤等价性如图6所示,对于不同的查询语句(Q1~Q5),在 PrXML (145KB)和 XML (138KB)中结构过滤得到的相应结果数量也是相等的。说明序列匹配应用到不确定XML与普通XML是等价的。

图4 查询效率对比

图5 子序列匹配等价性
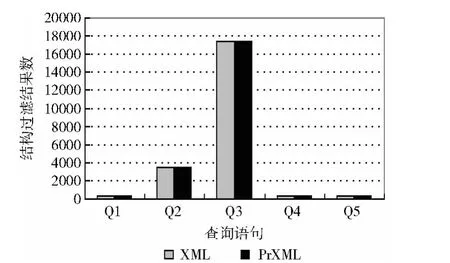
图6 结构过滤等价性
4 结束语
本文将序列匹配的方法应用到不确定XML小枝模式匹配,并对不确定XML中序列匹配的假警报和假不予考虑问题进行分析和证明,为不确定XML序列匹配提供了一定的理论依据。理论分析和实验结果表明不确定XML中序列匹配的假警报和假不予考虑问题同样可以消除,序列匹配应用到不确定XML与普通XML是等价的。在不确定XML中,序列匹配算法与整体匹配算法Holistic Twig相比,效率更高。下一步将根据不确定XML的特点对序列匹配算法LCS-TRIM进行优化,进一步提高不确定XML序列匹配算法的效率。
[1]Chen S,Li H G,Tatemura J,et al.Twig 2stack:Bottomup processing of generalized-tree-pattern queries over XML documents [C]//Proceedings of the 32nd International Conference on Very Large Data Bases.New York:ACM Press,2006:283-294.
[2]Qin L,Yu J X,Ding B.TwigList:Make twig pattern matching fast [C]//Proceedings of the 12th International Conference on Database Systems for Advanced Applications.Berlin:Springer-Verlag,2007:850-862.
[3]Yun J H,Chung C W.Efficient probabilistic XML query processing using an extended labeling scheme and a lightweight index [J].Information Processing & Management,2012,48(6):1181-1202.
[4]ZHANG Xiaolin,LV Qing,LIU Lixin,et al.An efficient algorithm of continuous uncertain XML twig pattern matching[J].Application Research of Computers,2013,30 (2):364-366(in Chinese).[张晓琳,吕庆,刘立新,等.一种高效的连续不确定XML小枝模式匹配算法 [J].计算机应用研究,2013,30 (2):364-366.]
[5]LIU Lixin,ZHANG Xiaolin,LV Qing,et al.Matching twig patterns in uncertain XML without merging [J].Computer Science,2013,40 (5):198-200 (in Chinese). [刘立新,张晓琳,吕庆,等.一种非归并不确定XML小枝模式查询算法[J].计算机科学,2013,40 (5):198-200.]
[6]LI Yawen.Study on Holistically Twig matching algorithm over probabilistic XMLs [D].Shenyang:Northeastern University,2009 (in Chinese).[李亚文.概率 XML文档中 Holistic Twig查询处理算法的研究与实现 [D].沈阳:东北大学,2009.]
[7]LIU Pan.Study on Twig matching algorithm over probabilistic XMLs [D].Shenyang:Northeastern University,2010 (in Chinese).[刘潘.概率XML文档中Twig查询处理算法的研究与实现 [D].沈阳:东北大学,2010.]
[8]Tatikonda S,Parthasarathy S,Goyder M.LCS-TRIM:Dynamic programming meets XML indexing and querying [C]//Proceedings of the 33rd International Conference on Very Large Data Bases.New York:ACM Press,2007:63-74.
[9]Merialdo P.ACM SIGMOD record:XML version [EB/OL].[2013-06-06].http://www.dia.uniroma3.it/Araneus/Sigmod/.
[10]Miklau G.University courses [EB/OL]. [2013-06-25].http://www.cs.washington.edu/research/xmldatasets/www/repository.html#courses.
