基于深度学习模型的无线传感器网络数据融合算法*
2014-09-06邱立达刘天键黄章超
邱立达,刘天键,林 南,黄章超
(1.闽江学院物理学与电子信息工程系,福州 350108;2.厦门理工学院光电与通信工程学院,福建 厦门 361024)
基于深度学习模型的无线传感器网络数据融合算法*
邱立达1*,刘天键1,林 南1,黄章超2
(1.闽江学院物理学与电子信息工程系,福州 350108;2.厦门理工学院光电与通信工程学院,福建 厦门 361024)
为了在无线传感器网络中提高数据融合性能,基于深度学习模型,提出一种将层叠自动编码器(SAE)和分簇协议相结合的数据融合算法SAEMDA,该算法在各个簇内构建特征提取分类模型SAEM,通过SAEM对节点数据进行特征提取和分类,之后将同类特征融合并发送给汇聚节点。SAEM的训练既可以采用离线有监督学习也可以采用在线无监督学习。仿真实验表明:和BPFDA,SOFMDA算法相比,SAEMDA在网络能耗大致相当的情况下能将数据融合正确率提高最多7.5%。
无线传感器网络;数据融合;深度学习;自动编码器
1 相关工作
无线传感器网络(WSN)数据融合技术能有效去除数据冗余性,减少通信开销从而降低能耗,延长网络寿命,因此成为WSN中的重要研究课题之一。目前已提出了多种WSN数据融合方法,如文献[1]使用遗传算法寻找传感器数据融合节点序列的最优路径,有效减少了网络能耗和传输延时,但未解决数据本身的冗余性问题。文献[2]通过在分簇结构的簇首中对节点数据进行PCA降维达到数据融合的目的,其缺点是簇首需周期性的对所有数据进行PCA运算,开销大,实时性差且PCA的非线性映射能力不佳。文献[3]提出中介真值度度量的动态多节点数据加权融合,算法简单,实时性好,但是未考虑不同类型数据间的差异性。
近年来,鉴于神经网络和WSN的相似性使其成为数据融合算法的研究重点[4-6],该类方法通过神经网络对节点数据进行特征提取分类并融合同类特征,在降低数据通信量的同时能够保留原始数据的关键信息。文献[5]提出的BPNDA是该类算法的典型代表,BPNDA将BP神经网络与分簇协议结合,先在汇聚节点训练BP网络,之后将网络参数发送给各簇的簇首和簇节点用于构造BP神经网络模型来对节点原始数据进行特征提取和分类融合,BPNDA能有效提高数据融合效率,降低网络能耗,但是在训练样本不含标签信息时BP网络将无法训练。文献[7]提出基于SOFM神经网络的SOFMDA算法,SOFMDA对网络分簇后在簇首训练SOFM并通过SOFM对接收到的节点数据进行特征提取和分类融合。作为无监督神经网络,SOFM不要求训练样本包含标签信息。目前在神经网络驱动的数据融合算法中主要使用单隐层BP神经网络,SOFM神经网络等传统浅层模型,它们的非线性映射能力与对复杂数据的特征表示能力较弱,直接影响了数据融合的效果,与之相比,深层模型能更好的逼近复杂函数,泛化能力和数据特征表示能力更强,但是其非凸损失函数局部极值多,训练容易陷入局部极小,以多隐层BP神经网络为例传统训练方法的效果已很不理想[8],因此在深度学习技术出现前,深层模型的应用受到了较大制约。2006年Hinton等提出可以通过无监督贪婪算法对深层模型逐层训练(这种训练方法有效解决了深层结构的优化难题[9])并基于此思想提出了深信度网络[10]。此后层叠降噪自动编码器[11]、DCN[12]、Sum-product[13]等深度学习模型被陆续提出并在各个领域[14-16]取得巨大成功。
迄今深度学习技术在WSN中的应用尚鲜有报道,本文将层叠自动编码器(SAE)和分类器级联,设计了一种基于深度学习的特征提取分类模型SAEM。SAEM采用贪婪算法逐层无监督训练,当训练样本包含标签信息时还可通过有监督“微调”进一步优化参数,有效克服了传统深层模型训练方法的不足,和当前广泛使用的浅层特征提取分类模型相比具有更优异的性能。之后将SAEM和分簇协议结合提出了一种新的数据融合算法SAEMDA,SAEMDA对网络分簇后在各簇内通过训练好的SAEM对节点数据进行特征提取和分类融合,与使用传统神经网络模型的BPNDA,SOFMDA相比,SAEMDA在降低网络能耗的同时对于节点数据具有更高的数据融合正确率。
2 深度学习模型
基于深度学习的层叠自动编码器(SAE)能有效提取数据低维特征,是本文提出的特征提取分类模型SAEM的重要组成部分,下面介绍其原理。
2.1 自动编码器
自动编码器AE(AutoEncoder)是一种单隐层无监督学习神经网络(如图1(a)),AE通过寻求最优参数(W,b)使得输出y尽可能地重构输入x,此时隐藏层输出a(k,2)可看作是x降维后的低维特征。为了使隐藏层输出特征更加稀疏鲁棒,AE的损失函数中包括输入输出均方误差约束,权值衰减约束和稀疏性约束3个部分:
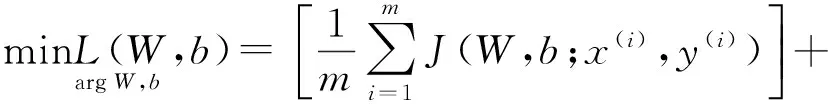
(1)
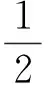
AE通过梯度下降算法来训练网络参数使得损失函数最小化,主要步骤如下:
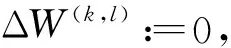
Step2对于i=1到m,计算:
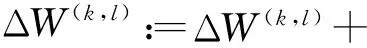
Step3更新参数:
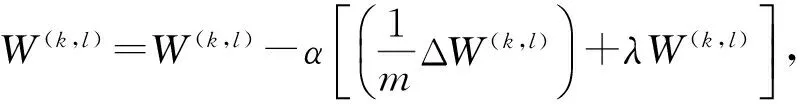
Step4重复Step 2直到收敛或达到最大迭代次数,输出(W(k,1),b(k,1),W(k,2),b(k,2))。
2.2 层叠自动编码器
将若干AE级联可构建多层神经网络:层叠自动编码器(SAE)。SAE的输出可看作是输入数据经过多次降维后的特征表示。SAE的各层参数可以通过逐层贪婪训练来获得(训练时将前一层AE的隐藏层输出作为后一层AE的输入),具体方法如下:
设定SAE隐藏层数Nk,利用样本x训练第1个AE获得其参数和隐藏层输出a(1,2),如图1(a)。用a(1,2)作为输入,训练第2个AE获得其参数和a(2,2),如图1(b)。以此类推,对Nk个AE逐层贪婪训练后获得参数组{(W(k,1),b(k,1))|k=1,…,Nk},将(W(k,1),b(k,1))作为SAE各层间连接权值,如图2“特征提取模块”框中所示。
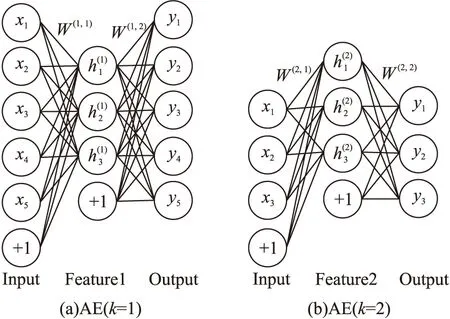
图1 自动编码器AE结构
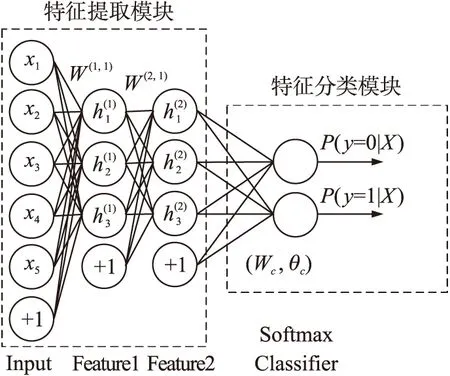
图2 特征提取分类模型SAEM结构
2.3 特征提取分类模型
特征提取分类性能直接影响数据融合的效果,为此本文设计了一种WSN特征提取分类模型SAEM,SAEM由SAE“特征提取”模块和包含分类器的“特征分类”模块级联而成,如图2,其中分类器可采用无监督分类器(SAEM1)或有监督分类器(SAEM2)。由于K-means无监督聚类算法简单,参数少,收敛快且性能优异[17]而Softmax有监督分类器和SAE在单独训练及整体“微调”时都可通过BP算法推导残差并使用梯度下降算法求解,模型复杂度小,故在SAEM1,SAEM2中分别选用二者作为分类器。SAEM构建方法如下:
①SAEM1:当训练样本不含标签信息时,首先训练SAE作为SAEM1的“特征提取”模块,接着将SAE输出的训练样本特征作为输入,训练与SAE级联的K-means无监督聚类器作为“特征分类”模块。
②SAEM2:若训练样本包含标签信息,则首先训练SAE,接着利用SAE输出的训练样本特征和标签信息训练有监督分类器Softmax,如图2所示。然后把训练好的SAE参数{(W(k,1),b(k,1))|k=1,…,Nk}和Softmax参数(Wc,θc)作为SAEM2的参数初值,使用BP算法对其进行整体有监督“微调”以进一步优化模型性能。
3 无线传感器网络数据融合算法
在对传感器节点数据进行分类融合前需要训练相应的特征提取分类模型,针对训练样本不含标签信息或包含标签信息的情况,本文设计了基于SAEM1的无监督数据融合算法SAEMDA1和基于SAEM2的有监督数据融合算法SAEMDA2。为便于比较分析,应用SAEMDA算法的WSN具有和同类网络[4-7]相同的网络模型:①网络节点具有唯一ID号,随机部署后位置固定;节点初始能量相同,不可补给。②汇聚节点部署在感知区域外,位置固定,能量充足,具有较强的存储计算能力。③汇聚节点可直接向节点发送数据而节点功率受限;各节点能获知自己的位置信息。
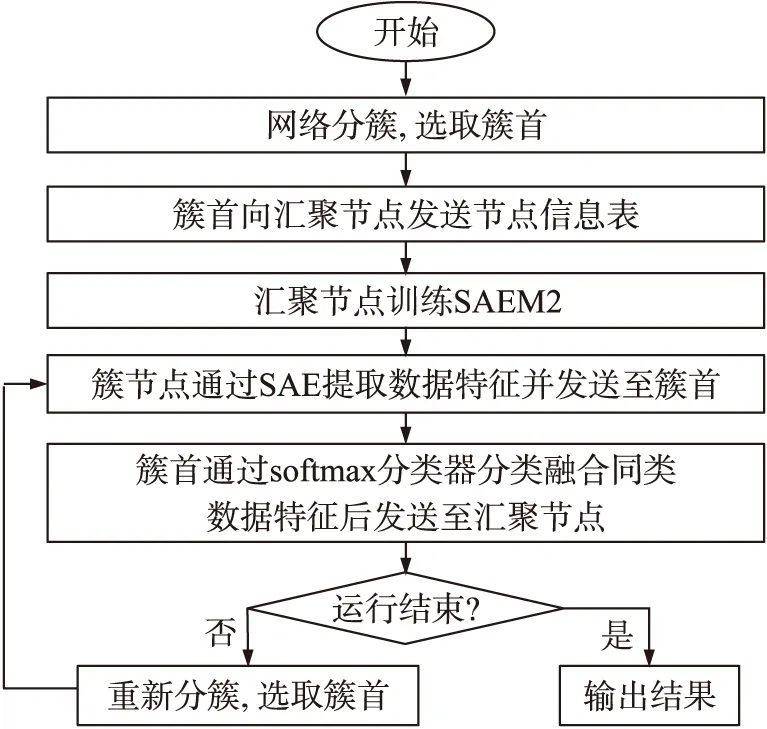
图4 SAEMDA2算法流程
首先通过分簇协议对网络分簇并选出各簇的簇首节点,接着运行SAEMDA1算法(如图3)或SAEMDA2算法(如图4),算法主要步骤如下:
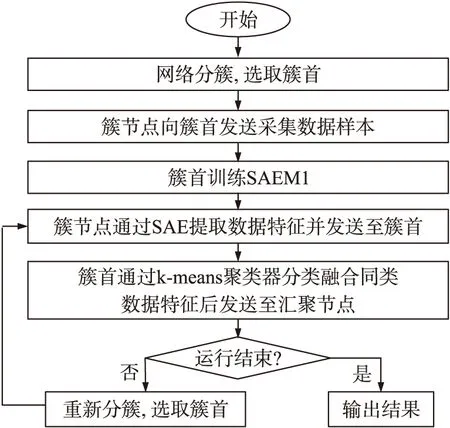
图3 SAEMDA1算法流程
①SAEMDA1
Step1各簇节点采集传感数据并不加处理地发送给相应的簇首节点。
Step2簇首以接收到的簇节点数据作为训练样本,构建并训练SAEM1。之后簇首将其中的SAE参数发送回各个簇节点,K-means聚类器参数则由簇首保存。
Step3簇节点采集传感数据,利用获得的SAE提取数据特征并发送给簇首。
Step4簇首用K-means聚类器对特征分类并按式(2)融合同类特征后向汇聚节点发送
(2)
式中c,Nc为特征类别号和类别数量,nc为c类特征数量,a(Nk,nl)(i,c)为SAE输出的样本特征(被“特征分类”模块判定为c类)。
Step5当网络节点完成一轮数据采集、融合与传输后,汇聚节点运行分簇协议重新分簇、选取簇首并跳转到Step 3。
②SAEMDA2
Step1各簇首节点向汇聚节点发送簇节点信息表。
Step2汇聚节点以包含标签信息的样本数据作为输入,构建并训练SAEM2。之后汇聚节点将SAE参数发送回各个簇节点,将Softmax分类器参数发送回各簇首节点。
Step3簇节点采集传感数据并利用SAE进行特征提取后发送给簇首。
Step4簇首用Softmax分类器对特征分类并按式(2)融合同类特征后向汇聚节点发送。
Step5网络节点完成一轮数据采集、融合与传输后,汇聚节点运行分簇协议重新分簇、选取簇首并跳转到Step 3。
上述SAEM1、SAEM2模型的输入层单元数和节点采集数据的维数相同,与网络分簇数量、簇节点个数等无关,因此SAEMDA算法和分簇协议的实现是相互独立的。
4 实验和分析
利用OMNET++编程对无监督数据融合算法SOFMDA,SAEMDA1以及有监督数据融合算法BPNDA,SAEMDA2进行仿真。为了专注于数据融合的性能分析,算法皆采用未优化的LEACH分簇协议以及第1类无线通信能耗模型,仿真参数设置为:在100 m×100 m平面区域随机分布100个传感器节点,汇聚节点坐标(50,175),节点初始能量0.5 J,网络中数据包长度4 000 bit,分簇消息长度200 bit,包头长度200 bit,仿真时间300 s。
SAEMDA1和SOFMDA的对比如表1,其中nl,s1,Nc分别表示特征提取分类模型的层数、输入数据维数和数据分类数量。由表1可知,SOFMDA的特征提取分类性能略高于SAEMDA1(n1=3),但随着SAEM1层数增加,SAEMDA1(n1=4,5)的正确率逐渐超过SOFMDA;当处理高维多类别数据时,浅层模型SOFM的参数数量急剧增加,训练容易陷入局部极值以至性能不佳,而基于深度学习的多隐层SAEM1此时优势愈发明显。
SAEMDA2和BPNDA的对比如表2,可见当SAEM2和BP神经网络模型层数相同时,SAEMDA2的正确率均高于BPNDA,尤其是处理高维多类别数据时,SAEMDA2通过逐层训练多隐层SAEM2能获得比BP网络更好的参数来提高特征提取分类能力,因此表现更优异。此外由于利用了标签信息,有监督数据融合算法性能要比无监督学习的好。

表1 无监督数据融合正确率

表2 有监督数据融合正确率
以处理数据(s1=1600,Nc=10)为例,算法能耗如图5所示,可见各数据融合算法的能耗均低于LEACH,其中BPNDA和SAEMDA2的能耗水平大致相当且都低于SOFMDA和SAEMDA1,这是因为BPNDA和SAEMDA2中层数相同的BP网络和SAEM2结构相似且都是在汇聚节点中进行训练,而SOFMDA和SAEMDA1则是在簇首中训练SOFM网络和SAEM2,簇首需要接收簇节点发送的原始数据作为训练样本,加大了节点能耗;此外SOFMDA中特征提取分类都在簇首进行,而SAEMDA2中簇节点在本地进行特征提取,簇首只进行分类融合,减少了数据传输量,因此SAEMDA2的能耗又低于SOFMDA。
WSN中随着能量消耗节点陆续死亡,网络逐渐失效,通常将死亡节点达到某一比例时的网络运行时间或轮数定义为WSN的网络寿命。与图5相应的各算法网络寿命如图6,显见网络能耗越低则网络寿命越长,以20%节点死亡为例,各算法下的网络寿命为:LEACH(540轮),SOFMDA(760轮),SAEMDA1(943轮),BPNDA(1265轮),SAEMDA2(1278轮)。可见SAEMDA的网络寿命等同或优于同类算法。
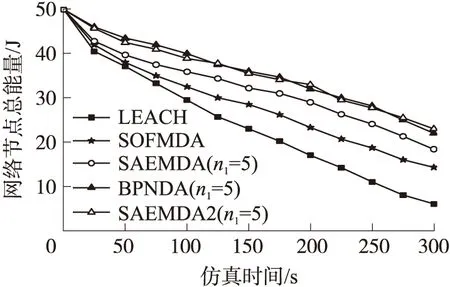
图5 数据融合算法能耗对比
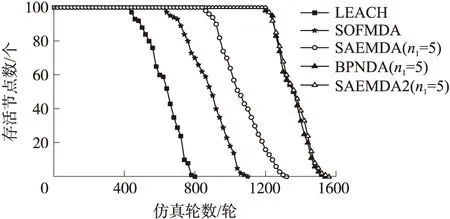
图6 网络寿命对比
5 结论
在WSN数据融合中引入深度学习技术,针对SOFMDA,BPNDA等广泛使用的传统浅层神经网络模型非线性映射能力弱,数据特征表示效果不理想的问题,设计了一种特征提取分类模型SAEM。SAEM基于深度学习,采用逐层训练的方法,相较于BP网络,SOFM网络具有更好的特征提取分类性能。仿真实验表明,本文提出的以SAEM为基础结合分簇协议的SAEMDA算法在降低网络能耗的同时,对各种数据具有更高的数据融合正确率,同时适用于无监督或有监督情况下的数据融合。深度学习模型在WSN领域具有广阔的应用前景,如何进一步简化参数,缩短模型训练时间,提高特征提取分类速度是下一步的研究重点。
[1] 张扬,杨松涛,张香芝. 一种模拟退火遗传算法的传感器网络数据融合技术研究[J]. 计算机应用研究,2012,29(5):1860-1862.
[2]马守明,王汝传,叶宁. 基于主元分析的无线传感器网络数据融合研究[J]. 计算机工程与科学,2010,32(11):44-46.
[3]戎舟. 基于中介理论的无线传感器网络加权数据融合[J]. 电子测量与仪器学报,2010,24(8):705-710.
[4]孔玉静,侯鑫,华尔天,等. 基于BP神经网络的无线传感器网络路由协议的研究[J]. 传感技术学报,2013,26(2):246-251.
[5]孙凌逸,黄先祥,蔡伟,等. 基于神经网络的无线传感器网络数据融合算法[J]. 传感技术学报,2011,24(1):122-127.
[6]俞黎阳,王能,张卫. 无线传感器网络中基于神经网络的数据融合模型[J]. 计算机科学,2008,35(12):43-47.
[7]杨永健,刘帅. 基于SOFM神经网络的无线传感器网络数据融合算法[J]. 传感技术学报,2013,26(12):1757-1763.
[8]Bengio Y. Learning Deep Architectures for AI[J]. Foundations and Trends in Machine Learning,2009,2(1):1-127.
[9]Erhan D,Bengio Y,Couville A,et al. Why Does Unsupervised Pre-Training Help Deep Learning[J]. Journal of Machine Learning Research,2010,11(3):625-660.
[10]Hinton G E,Salakhutdinov R R. Reducing the Dimensionality of Data with Neural Networks[J]. Science,2006,313(5786):504-507.
[11]Vincent P,Larochelle H,Lajoie I,et al. Stacked Denoising Autoencoders:Learning Useful Representations in a Deep Network with a Local Denoising Criterion[J]. Journal of Machine Learning Research,2010,11(12):3371-3408.
[12]Dong Yu,Li Deng. Deep Convex Network:A Scalable Architecture for Speech Pattern Classification[C]//Proc of the 12th Annual Conference of International Speech Comunication Association. 2011:2285-2288.
[13]Poon H,Domingos P. Sum-Product Networks:A New Deep Architecture[C]//Proc of IEEE International Conference on Computer Vision. 2011:689-690.
[14]Mohamed A,Sainath T N,Dahl G E,et al. Deep Belief Networks using Discriminative Features for Phone Recognition[C]//Proc of IEEE International Conference on Acoustics,Speech,and Signal Processing,2011:5060-5063.
[15]Chen Bo,Polatkan G,Sapiro G,et al. Deep Learning with Hierarchical Convolutional Factor Analysis[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence,2013,35(8):1887-901.
[16]Martinez B,Valstar M F,Binefa X,et al. Local Evidence Aggregation for Regression Based Facial Point Detection[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence,2013,35(5):1149-1163.
[17]Coates A,Lee H Y,Ng A. An Analysis of Single-Layer Networks in Unsupervised Feature Learning[J]. Journal of Machine Learning Research,2011,215-223.

邱立达(1984-),男,闽江学院物理学与电子信息工程系,讲师,主要研究方向为目标跟踪与模式识别、机器视觉和无线传感器网络,qld.qq@163.com;

刘天键(1975-),男,闽江学院物理学与电子信息工程系,副教授,主要研究方向为模式分类、目标跟踪和非线性滤波;

林南(1978-),女,闽江学院物理学与电子信息工程系,副教授,主要研究方向为无线传感器网络拓扑控制和光电子器件数值模拟;

黄章超(1985-),男,厦门理工学院光电与通信工程学院,讲师,主要研究方向为光纤传感和光电信息处理。
DataAggregationinWirelessSensorNetworkBasedonDeepLearningModel*
QIULida1*,LIUTianjian1,LINNan1,HUANGZhangchao2
(1.Department of Physics and Electronic Information Engineering,Minjiang University,Fuzhou 350108,China;2.School of Opto-Electronic and Communication Engineering,Xiamen University of Technology,Xiamen Fujian 361024,China)
In order to improve the performance of data fusion in wireless sensor network,a data aggregation algorithm SAEMDA(stacked autoencoder model data fusion algorithm)based on deep learning model was proposed,which combined stacked autoencoder(SAE)and wireless sensor network clustering routing protocol. Feature extraction and classification model(SAEM)is designed by SAEMDA to extract and classify the data features of nodes in each cluster,and then SAEMDA sends the features fused in the same class to Sink node. Either offline supervised learning algorithm or online unsupervised learning algorithm can be used to train the SAEM. Simulation results show that compared with BPFDA and SOFMDA,SAEMDA can improve the data fusion accuracy by 7.5 percentage points at most in similar situations of energy consumption.
wireless sensor network;data aggregation;deep learning;autoencoder
项目来源:福建省教育厅科技项目(JA12263);福州市科技计划项目(2013-G-86)
2014-07-16修改日期:2014-10-20
TP393
:A
:1004-1699(2014)12-1704-06
10.3969/j.issn.1004-1699.2014.12.022
