基于Hadoop的异常传感数据时间序列检测*
2014-09-06张建平刘学军
张建平,李 斌,刘学军,胡 平
(南京工业大学电子与信息工程学院,南京 211816)
基于Hadoop的异常传感数据时间序列检测*
张建平,李 斌*,刘学军,胡 平
(南京工业大学电子与信息工程学院,南京 211816)
无线传感器网络中,异常时间序列的研究具有十分重要的意义。针对传统研究在海量数据环境中时间效率低下的问题,提出了基于Hadoop的异常时间序列检测算法。首先对时间序列进行预处理,然后在Hadoop的MapReduce操作中调用动态时间弯曲距离计算算法,实现了DTW距离计算的并行化,从而大大提高检测速度。同时针对传统DTW算法计算复杂度瓶颈问题以及传统约束方法准确率较低问题,提出了基于显著特征匹配的局部约束算法,对弯曲路径进行局部限制,在确保准确性的同时进一步降低了时间、空间复杂度。Hadoop平台下实验结果表明,该方法既提高了检测速度,又保证了检测准确率。
无线传感器网络;异常时间序列;Hadoop;局部约束;动态时间弯曲
目前,物联网技术作为一个新的技术热点受到了广泛的关注。在物联网系统中,对传感器海量采样数据的处理显得尤为重要。每个传感器节点采集的数据可形成时间序列,而对时间序列的查询及聚类在各种应用领域中也逐渐成为核心数据操作,如语言识别领域、入侵检测领域、金融领域等。在众多的时间序列中,往往异常的时间序列是最具有研究价值的,而对异常时间序列的检测通常转化为对时间序列相似性的检测。由Eamonn Keogh提出的动态时间弯曲DTW(Dynamic Time Warping)距离方法,与传统的Euclidean距离方法相比具有明显的优越性。DTW距离对那些带有相似的底层模式但由于时间变形(如移位或延伸)彼此不同的序列具有很好的辨识度,因而大大提高了两序列的检测准确性,但其具有较高的时间复杂度,在当今大数据的环境下尤显力不从心。因此,本文提出了一种基于Hadoop的异常时间序列检测方法,采用MapReduce机制对海量时间序列进行并行化处理,在提高检测速度的同时又不显著降低准确性,同时引入基于显著特征比对的局部约束方法(SDTW),进一步降低了离群序列的时间复杂度。
本文后续内容安排如下:第1节介绍了相关研究工作;第2节提出了一种基于Hadoop的离群时间序列检测算法;第3节通过相关实验分析了该算法的性能;第4节总结了全文的工作,并进行了展望。
1 相关工作
异常点,又称离群点,是指明显偏离其他对象的数据点,这种偏离甚至引起人们怀疑它们产生于不同的机制[1-2]。相应地,异常时间序列,是指采集到的与正常序列有很大差异的时间序列。时间序列为一系列随着时间的变化而变化的数据,这些数据可以描述随着时间变化事物的某种状态的变化。大部分的时间序列挖掘算法采用时间序列的相似性进行研究,即将异常时间序列的挖掘转化为求待检测时间序列与标准时间序列的相似度。传统的时间序列相似性度量方式采用欧式距离(Euclidean Distance),欧式距离最为简单直观,但要求两条时间序列长度相同,且缺乏在时间轴上的伸缩性,因此动态时间弯曲(DTW)距离作为一种新的度量方式被提出。Stan Salvador和Philip Chan[3]提出了一种FastDTW算法,它综合了限制和数据抽样两种DTW常用的加速手段,对时间序列进行粗粒度化、投影、细粒度化等操作,实现了DTW的加速,将时间、空间复杂度由传统DTW算法的o(N2)降至o(N)。但由于采用了减少搜索空间的策略,FastDTW算法求得的弯曲时间路径不一定是最佳路径,因此算法在一定程度上影响了准确性。李海林和杨丽彬[4]提出了一种增量动态时间弯曲算法(IDTW),首先利用动态时间弯曲方法对历史时间数据进行相似性度量,得到历史最优弯曲路径及路径中各元素的累积距离。然后通过逆向弯曲度量方法完成当前序列的相似性度量,结合历史数据信息找到与历史弯曲路径相交且度量时间序列距离为当前最小值的新路径,进而实现增量动态时间弯曲的相似性度量。此算法在分类准确率和计算性能上都要优于经典动态时间弯曲,但此算法对历史数据的度量使得其在海量数据面前毫无优势。Thanawin Rakthanmanon和Bilson Campana[5]将4种新颖的方法结合在一起,在基于DTW算法的基础上形成了一套UCR算法,不仅可以完成大规模时间序列的有效挖掘,同时解决了高层次的时间序列挖掘问题。此外,该算法在时间序列数据流的实时监控上也有很好的效果,同时降低了能耗。
基于以上研究,本文提出了一种基于Hadoop的异常传感数据时间序列检测算法。该算法利用了Hadoop集群,运用MapReduce算法对拥有海量数据的时间序列进行分布式运算,大大降低算法的运行时间,提高了时间序列的检测效率。同时,在计算DTW距离前,找出时间序列的显著特征,对各时间序列的显著特征进行匹配以构造局部约束,降低了DTW距离计算的空间搜索,从而与传统DTW算法相比降低了时间、空间复杂度,且保留了应有的准确度。
2 相关定义及算法描述
2.1 MapReduce计算模型
Hadoop起源于Nutch项目,是Google公司的分布式文件系统GFS(Google File System)和MapReduce计算模型的开源实现。Hadoop的核心是MapReduce计算框架,是一种并行编程模型和计算框架,用于并行计算大规模数据集,因此在处理海量数据上卓有成效[6-8]。
MapReduce模型中所有的Map操作彼此独立并且完全并行,而且对于具有相同key值的中间键值对,Reduce函数同样可以执行并行操作,因而有效提高了系统对数据并行化处理的能力[9]。MapReduce集群中的文件通常存储在分布式文件系统(DFS)中,并进行等大小分块,传送至集群上不同节点。执行MapReduce任务,用户需要指定输入文件、所需的Map任务数量和Reduce任务数量,并且提供Map和Reduce函数,通常Map任务数与所给输入文件分块数相同[10]。MapReduce算法的执行分为3个阶段:Map阶段、Shuffle/Sort阶段和Reduce阶段[11]。在Map阶段,框架调用用户自定义的Map函数,处理所输入的键值对list(k1,v1),同时生成一批新的键值对list(k2,v2)。在Shuffle/Sort阶段,对Map阶段输出的结果按k2值进行合并、分类,生成中间数据list(k2,list(vl2))。在Reduce阶段,遍历上阶段生成的中间数据,对每个唯一的k2,执行用户自定义的Reduce函数,输出新的键值对list(k3,v3)。图1为MapReduce基本模型。
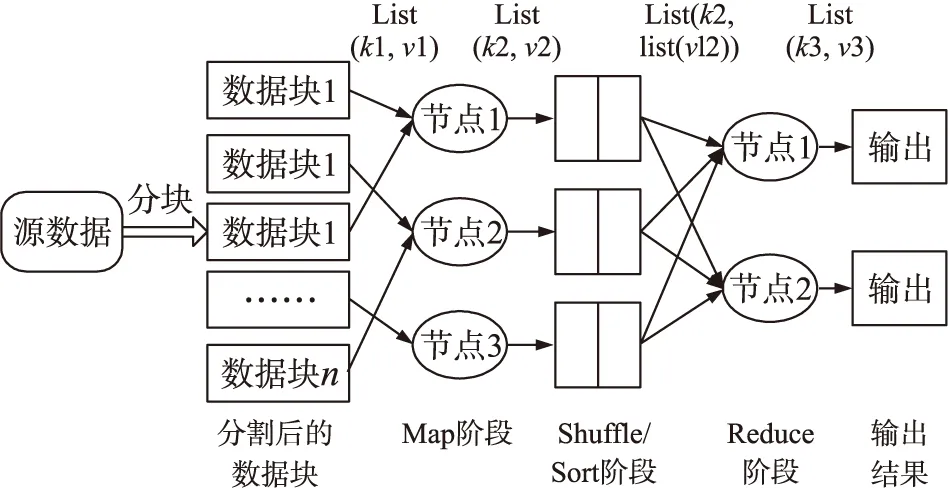
图1 MapReduce基本模型
2.2 基于局部约束算法(SDTW)的动态时间弯曲距离计算
时间序列通常都具有结构特征,SDTW算法通过找出时间序列的显著特征,对两条时间序列的显著特征进行匹配,最终计算得出局部约束结果。根据局部约束结果可以得出局部约束边带大小及局部约束核位置。动态时间弯曲距离的计算采用经典的动态规划方法进行计算。该算法提高了对弯曲路径的搜索效率。
2.2.1 基于显著特征匹配的局部约束算法(SDTW)
SIFT(Scale-Invariant Feature Transform)是一种检测局部特征的算法,通常用于2维图像检索、三维重建[12]。本文提出一种近似SIFT算法,用于1维时间序列显著特征的检测。
近似SIFT算法首先检测时间序列的特征点。在尺度空间中检测出稳定的特征点位置,需要将尺度空间在高斯差分中的极值与时间序列点进行卷积。
定义1给定时间序列X,[xi,σ]为多尺度时间序列点,则
①时间序列点的尺度空间为:L(xi,σ)=G(xi,σ)*X(i)=G(xi,σ)*xi,其中σ为时间尺度因子,σ取值越小,时间序列被平滑程度越小,对应特征越细;G(xi,σ)为一个可变尺度的一维高斯函数,G(xi,σ)=(1/2πσ2)e-(xi)/2σ2。
②时间序列点高斯差分算子为:D(xi,σ)=L(xi,κσ)-L(xi,σ),其中κ[13]为常数。D(xi,σ)体现了时间序列点在不同尺度高斯平滑的差异,差异越大,成为特征点的可能越大。
定义2给定时间序列X,[xi,σ]为多尺度时间序列点(σ为时间尺度因子),若[xi,σ]的邻居中有(1-ε)部分D(xj,σ)的值小于D(xi,σ),则称[xi,σ]为特征点。(其中,ε为阈值,且是一个很小的正数)。

图2 特征点描述符的8维向量表征
时间序列特征点检测完成后,需要对特征点进行描述符的创建,即用一组向量将这个特征点描述出来,这个描述符不仅包含特征点,也包括了特征点周围对其有贡献的时间序列点。描述符的创建通过对特征点周围区域分块,计算块内梯度直方图,生成具有独特性的向量。时间序列中描述符通常采用4×2=8维向量表征,将特征点周围区域分成4块,每块中计算两个方向的梯度信息,如图2所示。
特征点及特征点的描述符确定后,利用特征点的描述符进行两条时间序列特征点匹配对的查找。
定义3令s1,i为时间序列X1的特征点,s2,j为时间序列X2的特征点,若满足以下条件:①两个特征点的振幅差小于阈值τα;②两个特征点的尺度比小于阈值τs;③不存在其他特征点s2,l,满足上述两种情况且描述符相似度满足sim(s1,i,s2,j)×τd≤sim(s1,i,s2,l),其中τd为阈值(τd>1),则称[s1,i,s2,j]为相匹配的特征点。
显著特征匹配对确定后,两条时间序列匹配特征的起始点与终止点构成了特征的范围边界,利用这些信息即可计算局部相关约束[14]。如图3所示,时间序列X,Y的显著特征匹配对确定后,特征范围边界将每个时间序列分成一系列的连续区间,如图区间A到E。局部约束的计算主要分为两部分:自适应核位置的确定和自适应约束边带宽度的确定。
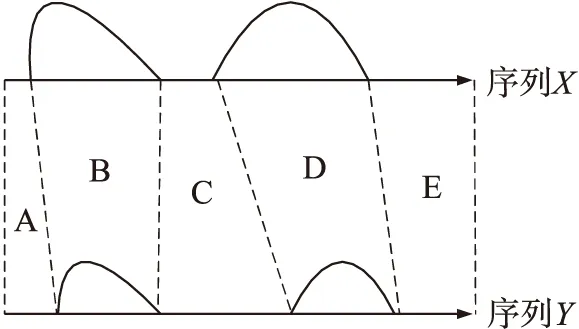
图3 匹配特征范围边界
定义4给定时间序列X、Y,区间B,若B在时间序列X中的起始点和终止点分别为st(X,B)、end(X,B),在时间序列Y中分别为st(Y,B)、end(Y,B),且xi为X序列区间B中的任意一点,则相对应的候选点yj由下式可得:
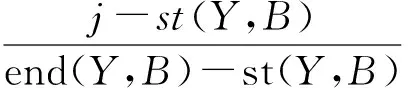
(xi,yj)即确定了自适应核位置。
定义5给定时间序列X、Y,时间序列X上的每个点xi,在时间序列Y上存在候选点yj且xi只与yj±ω/2范围内的点比较,其中ω为包含yj的区间宽度。
SDTW算法步骤如下:①求出输入的时间序列的显著特征点;②创建匹配显著特征点的描述符;③找出所要对比的一对时间序列的所有特征匹配对;④利用所得特征匹配对计算局部约束:自适应核位置和自适应约束边带宽度。
2.2.2 基于SDTW算法的动态时间弯曲距离计算
动态时间弯曲(DTW)距离是一种允许在时间序列时间轴上弯曲的距离,与欧式距离不同的是,它不是完全的点对点距离,而是可以跳过若干点进行匹配的距离,既保留了欧式距离的优点,同时也克服了它的不足。
设时间序列A,B长度分别为m,n:A=(A1,A2,A3,…,Am);B=(B1,B2,B3,…,Bn)。则如图4所示构造一个m×n的网格,其中第i行j列记为
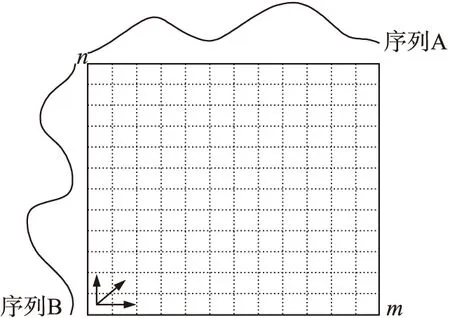
图4 序列A、B的匹配网格
定理1给定时间序列A=(A1,A2,A3,…,Am),B=(B1,B2,B3,…,Bn),dij=(Ai-Bj)2,则最优路径D
证明从<1,1>出发,对于若干满足条件的路径,假设可以计算每条路径到达
基于SDTW算法的动态时间弯曲距离计算是以DTW算法为基础,在时间序列的匹配中加入局部限定条件,减少累计距离的计算,从而降低路径的搜索,具体伪代码如下:
Function SDTW()
{
W=0; //初始化局部约束宽度
S=0; //初始化局部约束核位置
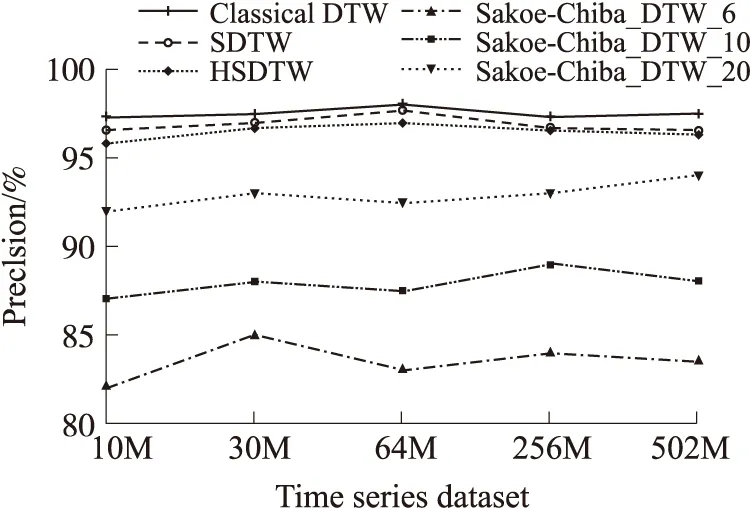
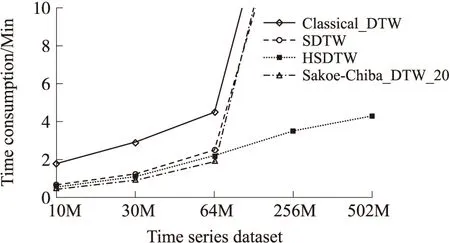
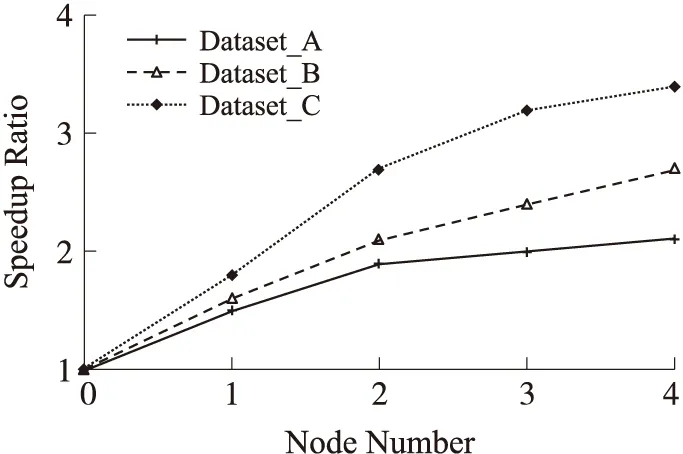
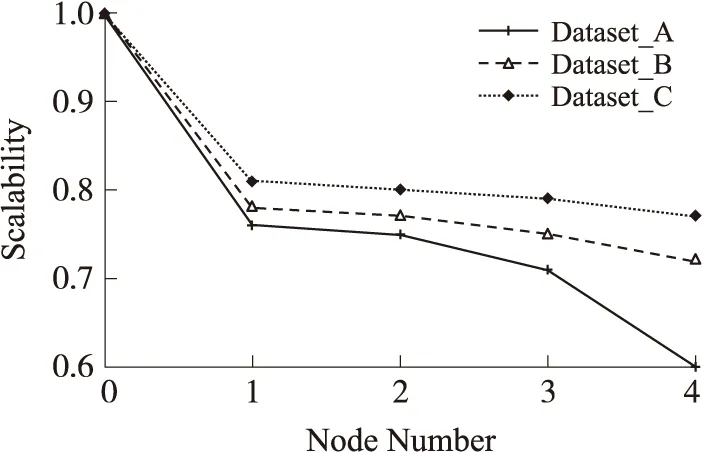
For(i=1;i { W=constraint_width(i); //时间序列A[i]所对应的局部约束宽度 S=score_posi(i); //时间序列A[i]所对应的核位置 For(j=s-w/2;j { Min=min{D } } } 2.3 基于Hadoop的异常时间序列检测算法(HSDTW) 给定标准时间序列A,待检测时间序列B1,B2,…,Bm,则B1,B2,…,Bm是否为异常时间序列的检测分为两个阶段:(1)时间序列预处理阶段;(2)Hadoop集群下计算阶段。 第1阶段时间序列的预处理 ①将标准时间序列A按时间间隔(t,2t),(2t,3t),…,((n-1)t,nt)分成n份,且每份预处理为symbol_series=(symbol_normal,symbol_interval_nomal,value_normal)的形式。其中symbol_normal为时间序列标记,时间序列A记为0;symbol_interval_nomal为时间序列时间段标记,(t,2t),(2t,3t),…,((n-1)t,nt)依次记为t1至tn;value_normal为上述标记下的时间序列内容。 ②同理将m条待检测时间序列(B1,B2,…,Bm)依次按时间间隔t分成n份,且每份预处理为pending_series_Bi=(symbol_pending,symbol_interval_pending,value_pending)的形式.其中symbol_pending为时间序列标记,时间序列B1~Bm依次记为1~m;symbol_interval_pending为时间序列时间段标记;m个时间序列的时间间隔(t,2t),(2t,3t),…,((n-1)t,nt)全部依次记为t1至tn;value_normal为上述标记下的时间序列内容。 ③将同一时间段的标准时间序列与不同的待检测时间序列的预处理所得的内容合并成一条记录,即symbol_series+pending_series_Bi的形式,多条记录形成的数据文件作为MapReduce的输入。 第2阶段将第1阶段处理完成的数据文件存储在HDFS上,数据自动分块至各个节点,每个Map每次输入一条记录,迭代直至所有记录处理完成,函数设计由3个部分组成:Map函数、Combine函数、Reduce函数。 ①Map函数的设计 Map函数的输入为〈k1,v1〉键值对,k1是当前样本相对于输入数据文件起始点的偏移量,v1为当前样本内容。对本次时间段的两条时间序列根据2.2节算法进行DTW距离的计算,最终输出〈k2,v2〉,其中k2为待检测时间序列标记symbol_pending,v2为两时间序列之间的DTW距离。 ②Combine函数的设计 Map任务的输出结果通常保存在本地节点中,为了减少通讯代价,采用combine操作,对Map任务的输出进行本地合并。在Combine函数的输入〈k2,list(v2)〉中,k2为待检测时间序列标记symbol_pending,list(v2)是分配给标记k2的两时间序列DTW距离组成的链表,Combine函数将属于同一标记的DTW距离进行相加运算,最终输出的〈k2,vl2〉中,k2为Combine函数的输入,vl2为本地节点属于k2的时间序列的DTW距离和。 ③Reduce函数的设计 Reduce函数的输入〈k2,list(vl2)〉中,k2为combine函数时间序列标记,list(vl2)为各个combine函数输出的中间结果组成的链表,Reduce函数将来自不同节点的相同k2值对应的vl2值累加,同时定义参数flag,并将累加值与给定阈值ε比较,若累加值小于阈值,则k2值所代表的时间序列与标准时间序列相似,flag值为1;否则为离群时间序列,flag值为0。Reduce函数的输出〈k3,v3〉对中,k3为Reduce函数的输入值,v3为flag值。 对于Reduce函数的输出〈k3,v3〉,若v3值为0,则此时间序列为离群时间序列,否则为非离群序列。 本文实验部分采用10台双核计算机组建的Hadoop集群对时间序列进行分析,操作系统为centos 6。其中一台作为namenode,一台作为secondarynamenode,其余8台均作为datanode。每个节点Map的数量为8个,Reduce的数量为1个。实验从算法的时间复杂度和准确性两方面讨论算法的有效性,同时验证算法的加速比与可扩展性。进行对比的算法为标准DTW算法Classical_DTW、Sakoe-Chiba边带约束算法Sakoe-Chiba_DTW、局部约束算法SDTW,以及本文提出的基于Hadoop下的局部约束算法HSDTW。 3.1 算法的有效性分析 分别从算法的精确度和时间复杂度两方面进行了比较。为了验证HSDTW算法的有效性,本文将运行在Hadoop集群上的HSDTW算法与串行的SDTW算法、Sakoe-Chiba_DTW算法、Classical_DTW算法采用5种不同大小的数据集进行了详细的对比。 3.1.1 精确度对比 精确度对比主要是对比不同算法执行后结果的精确程度,即比较不同算法检测到的正确的异常时间序列与实际异常时间序列的比值。实验对5组不同的数据集进行多次检测,并将结果取平均值,图5显示了多次检测所得结果。Sakoe-Chiba_DTW算法将时间序列的每个点与标准时间序列的ω%个点相比较,本次实验ω的取值有如下3种:20,10,6。而其他算法的ω取值均取决于局部约束计算结果。由图5可知,本文提出的HSDTW算法的精确度较高,类似于SDTW的精确度,SDTW的精确度接近于Classical_DTW算法,而Sakoe-Chiba_DTW算法则展现出较差的准确性,且随着ω取值的降低,精确度越来越低。 图5 不同算法精确度对比 3.1.2 时间复杂度对比 时间复杂度对比主要是比较不同算法执行所需的时间,由于ω值越大,耗时越长,因此Sakoe-Chiba_DTW算法只取ω为20的情况进行检测。如图6所示,在数据量较小的情况下,Sakoe-Chiba_DTW算法时间消耗较低却以牺牲准确性为前提,Classical_DTW算法虽然精确度很高,但以大量的时间消耗为代价,SDTW算法在保持较高精确度的同时也具有较快的运行速度,HSDTW算法与SDTW算法速度相似。但随着数据量的越来越大,串行算法时间消耗明显增大甚至导致溢出,而本文提出的HSDTW算法优势逐渐显著,时间消耗低且在准确性方面没有明显影响。 综合对比这些算法的性能,本文提出的基于Hadoop下的局部约束算法HSDTW较好地兼顾了时间效率和算法精确度,具备较高的有效性。 图6 不同算法时间复杂度对比 3.2 算法加速比分析 并行计算的性能通常通过加速比和可扩展性两方面来衡量。加速比的计算公式为Sp=Ts/Tp,其中Ts表示传统串行算法所消耗的时间,Tp表示Hadoop平台下的并行算法所消耗的时间。加速比越大,Hadoop平台下并行算法的效率和性能提升越高。实验分别采用拥有10 000条记录的数据集A、50 000条记录的数据集B、100 000条记录的数据集C在不同节点数的Hadoop集群下进行检测,多次检测后取平均值得加速比曲线如图7所示。由图可知,算法的加速比接近线性增长。Hadoop集群中节点数越多,加速比越大,但增幅变缓;数据集数据量越大,加速比越大,即数据量越大,Hadoop平台下的并行算法的优势越明显。 图7 算法加速比分析 3.3 算法可扩展性分析 尽管随着节点的增多,加速比在增大,但这并不能反映Hadoop集群的利用率。为此引入了扩展率,扩展率的计算公式为E=sp/n,其中sp为算法的加速比,n为节点个数,扩展率曲线如图8所示。由图可知,节点数越多,扩展率随之下降,这主要是由于节点的增多引起了通讯代价的增大。不过,随着数据量的增多,数据规模越来越大,可扩展率反而在增大,这一结果进一步验证了此算法在大数据集的上的性能优势。 图8 算法可扩展性分析 本文提出了一种基于Hadoop的异常传感数据时间序列检测,与传统异常时间序列检测算法不同的是:首先引入了Hadoop集群,采用MapReduce机制对异常时间序列检测算法进行并行化处理,使海量异常时间序列的检测变得高效。同时采用局部约束算法对传统DTW算法进行改进,减少最优路径的搜索空间,进一步提升检测速度。实验表明此算法既减少了时间上的计算开销,又保证了准确率。本文接下来的工作是对算法的改进,进一步提高算法的精确度,同时,由于Hadoop平台通常支持离线操作,如何实现低延迟也是将来需要进一步深入研究的问题,最后,本文研究还应与具体实际应用相结合,真正显示算法的实用性。 [1] 唐琪,刘学军. 无线传感器网络离群时间序列检测研究[J]. 传感技术学报,2013,26(1):95-99. [2]刘瑞琴,刘学军. WSN中基于加速动态时间弯曲的异常数据流检测[J]. 传感技术学报,2013,26(6):887-893. [3]Salvador S,Chan P. Toward Accurate Dynamic Time Warping in Linear Time and Space[J]. Intelligent Data Analysis,2007,11(5):561-580. [4]李海林,杨丽彬. 基于增量动态时间弯曲的时间序列相似性度量方法[J]. 计算机科学,2013,40(4):227-230. [5]Rakthanmanon T,Campana B,Mueen A,et al. Searching and Mining Trillions of Time Series Subsequences under Dynamic TimeWarping[C]//18th ACM SIGKDD Int Conf Knowledge Discovery and Data Mining. Beijing,China,2012:262-270. [6]Lu W,Shen Y,Chen S,et al. Efficient Processing of k Nearest Neighbor Joins Using Mapreduce[J]. Proceedings of the VLDB Endowment,2012,5(10):1016-1027. [7]Afrati F N,Fotakis D,Ullman J D. Enumerating Subgraph Instances Using Map-Reduce[C]//Data Engineering(ICDE),2013 IEEE 29th International Conference on IEEE. 2013:62-73. [8]Vernica R,Carey M J,Li C. Efficient Parallel Set-Similarity Joins Using MapReduce[C]//Proceedings of the 2010 ACM SIGMOD International Conference on Management of data. ACM,2010:495-506. [9]He Q,Ma Y,Wang Q,et al. Parallel Outlier Detection Using kd-Tree Based on Mapreduce[C]//Cloud Computing Technology and Science(CloudCom),2011 IEEE Third International Conference on IEEE. 2011:75-80. [10]Zhang C,Li F,Jestes J. Efficient Parallel kNN Joins for Large Data in MapReduce[C]//Proceedings of the 15th International Conference on Extending Database Technology. ACM,2012:38-49. [11]赵彦荣,王伟平,孟丹,等. 基于Hadoop的高效连接查询处理算法CHMJ[J]. 软件学报,2012,23(8):2032-2041. [12]姜桂圆,张桂玲,张大坤. SIFT特征分布式算法提取[J]. 计算机研究与发展,2012,49(5):1130-1141. [13]Lowe D G. Distinctive Image Features from Scale-Invariant Keypoints[J]. International Journal of Computer Vision,2004,60(2):91-110. [14]Candan K S,Rossini R,Wang X,et al. sDTW:Computing DTW Distances Using Locally Relevant Constraints Based on Salient Feature Alignments[J]. Proceedings of the VLDB Endowment,2012,5(11):1519-1530. 张建平(1989),女,江苏省南通市,硕士生,主要研究方向为数据挖掘,异常检测,传感器网络,zhangjianpingzl@163.com; 李斌(1979),男,江苏省南京市,硕士,讲师,主要研究方向包括数据库,传感器网络等,libean@139.com; 刘学军(1971),男,江苏省南京市,副教授,博士,主要研究方向包括数据库,数据挖掘,传感器网络等; 胡平(1962),男,江苏南京市,副院长/教授,主要研究领域为远程教育研究、计算机智能等。 AbnormalTimeSeriesDetectioninWirelessSensorNetworkBasedonHadoop* ZHANGJianping,LIBin,LIUXuejun,HUPing (College of Electronic and Information Engineering,Nanjing Tech University,Nanjing 211816,China) In wireless sensor network,the research of abnormal time series detection is of great significance. Due to the poor time efficiency of traditional research under big data,this paper proposes an algorithm about abnormal time series detection based on Hadoop. In this paper,time series are preprocessed firstly and then the DTW algorithm is called during MapReduce operation of Hadoop to realize the parallelization calculation of DTW distance. This measure improves the detection rate greatly. Meanwhile,to solve the bottleneck of computational complexity of classical DTW and the poor precision of the classical constraints,the paper also proposes locally relevant constraints based on salient feature alignments. It constraints the warping path locally to reduce the complexity of time and space further,it also ensures the precision of the algorithm at the same time. The results demonstrate that this algorithm not only decreases the time consumption,but also keeps a high precision. wireless sensor network;abnormal time series;Hadoop;locally constraints;dynamic time warping 项目来源:国家公益性科研专项项目(201310162,201210022);连云港科技支撑计划项目(SH1110) 2014-07-06修改日期:2014-10-30 TP393 :A :1004-1699(2014)12-1659-07 10.3969/j.issn.1004-1699.2014.12.0143 算法实验分析
4 总结与展望




