无人值守传感器网络的高性能分布式存储算法
2014-07-11肖宜龙蒋海波
肖宜龙, 蒋海波
(1. 中煤平朔集团有限公司,山西 朔州 036006; 2. 中国科学院 成都生物研究所,四川 成都 610041; 3. 中国科学院 成都计算机应用研究所,四川 成都 610041)
无人值守传感器网络[1-2]通常部署在恶劣环境中,数据收集节点Sink不固定在网络中,而是每隔一段时间后在网络中出现,收集各数据节点产生的数据包.在Sink节点出现之前,为避免数据包因节点损坏或是能量耗尽而丢失,各数据包通常分布式地存储在整个网络中.
笔者针对无人值守传感器网络的分布式存储算法[3-5]进行研究.基本假设[6]为网络由均匀分布的n个传感器节点构成,其中k个为数据节点 (n>k),每个数据节点用来感知物理量并产生一个大小固定的数据包,称为源数据包,其余的所有非数据节点只用来存储数据.每个节点有相同的通信半径,距离小于通信半径的两个节点互称为邻居节点,可以直接通信;处于通信半径之外的节点通过多跳机制间接通信.网络是连通的,但网络中每一个节点都没有路由表记录如何与其通信半径之外的节点间接通信,因此,两个节点之间的间接通信是通过随机选择中间节点来完成的.
针对无人值守传感器网络设计的最新且最具代表性的分布式存储算法是文献[6]中提出的基于LT码的算法.存储过程中该算法采用简单随机游走规则将k个源数据包传递到网络中的n个节点;每个节点按照LT码的度分度函数接收一定数量的源数据包,并计算得到一个存储数据包存储起来.Sink节点出现后,通过访问这些存储数据包恢复出原来的源数据包.该方法主要有两方面的缺点:一是简单随机游走的低效率以及算法本身的需求,导致每个源数据包为了遍历网络中所有的节点,在实际过程中至少需要传递 3nlnn次.因此,这增加了网络的通信成本.二是Sink节点为了恢复出所有的k个源数据包,需要访问k+kλ个存储数据包 (λ> 0,与k的取值有关).文献[6]的实验表明k的数量级大于等于102时,kλ的值大于100.因此,这导致了Sink节点的访问成本较高.针对LT码算法的上述不足,尤其是考虑到如何降低网络的通信成本(有利于传感器网络节能),笔者提出了一种基于源数据包传递过程中并行定向随机游走规则和网络中每个节点对源数据包独立处理机制的分布式数据存储算法.
1 并行定向随机游走
为了用数值实验模拟和验证文中算法的有效性,将无人值守传感器网络抽象为一个连通的二维随机图[7].各传感器节点用图中的各顶点表示.若两个传感器节点互为邻居节点,则用一条边连接图中对应的顶点;一个传感器节点的数据包传递到另一个节点的过程用随机几何图上一次随机游走表示.
二维随机图上的随机游走定义为按某一随机序列访问图中顶点的过程.一次随机游走开始于图中某一顶点,并且下一步要访问顶点是从当前访问顶点的邻居顶点中选取的;如果下一步要访问的顶点是从当前访问顶点的所有邻居顶点中等概率随机选取的,那么这样的随机游走称为简单随机游走.
与文献[6]中采用的简单随机游走规则不同,文中算法采用效率更高的并行定向随机游走规则[8]在网络中传递每个源数据包.下面先介绍(串行的)定向随机游走规则,再介绍其并行化方式.
1.1 定向随机游走规则
按照定向随机游走规则,每当源数据包到达了当前访问的传感器节点v后,要从v的所有邻居节点中选出一个作为下一步要访问的节点u.
如果用N(o)表示任意一个节点o的邻居节点集合,δ(o)表示节点o的邻居节点个数,c(o)表示定向随机游走目前已访问节点o的次数,那么,下一步将要访问的节点u的选取过程分为如下两步:
步骤1 从当前访问节点v的邻居集合N(v)中随机均匀地选择2个节点作为备选节点.
步骤2 从2个备选节点(用集合N′表示)中选择满足下式的节点u作为下一步将要访问的节点.
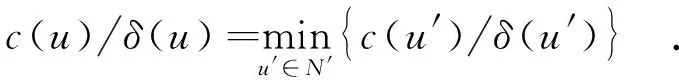
1.2 并行定向随机游走规则
每个数据节点将其源数据包并行地向外发出m个副本(0 对于一个连通的二维随机图,用t表示随机游走的步数,那么该随机游走对图的覆盖率(也就是访问到的不同顶点数占图中总的顶点数的比例),其理论值可以近似地表示[9]为 1-exp(-t/n).因此,对于无人值守传感器网络,当采用随机游走机制(串行或并行[10])传递每个源数据包时,理论上传递次数达到O(nlnn) 时,才能使得每个源数据包访问到网络中的每个节点. 文献[6]提出的基于LT码的方法,为使每个源数据包遍历网络中所有n个节点,每个源数据包的传递次数(文中将其看做网络通信成本开销)必须达到O(nlnn).为降低这一开销,笔者提出了一种基于并行随机游走机制的高性能分布式存储算法,该算法只要求每个源数据包的传递次数达到O(n)即可. 文中算法的具体实现流程用代伪码表示如下(命名为算法1): 算法1 无人值守传感器网络的高性能分布式存储算法 输入:k个源数据包Xv,v=1,…,k. 输出:n个存储数据包Yu,u=1,…,n. /*初始化阶段*/ 1: For 每个数据节点v=1 tok 2: 为源数据包Xv添加头信息: IDv号及定向随机游走步数计数器N=0; 3: For 每个节点u=1 ton 4: 初始化每个存储数据包的值:Yu=0; 5: 初始化每个源数据包Xv已访问节点u的当前次数:cv(u)=1,v=1,…,k;/*分布式存储阶段*/ 6: For 每个数据节点v=1 tok 7: 按照概率alnk/k接收Xv,并且更新自己的存储数据包:Yv=Yv⨁Xv; 8: 按照定向随机游走规则将源数据包Xv的m个副本分别传递出去; 9:cv(v)=cv(v)+1; 10: For 每个节点u=1 ton 11: For 每个到达节点u的源数据包Xj 12: IfXj是第一次访问节点u 13: 节点u按照概率alnk/k接收Xj,并且更新自己的存储数据包:Yu=Yu⨁Xj; 14:cj(u)=cj(u)+1; 15: 源数据包Xj更新头信息:N=N+1; 16: IfN 17: 节点u按照定向随机游走规则将源数据包Xj传递到它的一个邻居节点; 18: Else 19: 节点u丢弃Xj; 算法结束. 算法1完成之后,每个节点存储了一个存储数据包,源数据包不再存储.算法有两个重要参数: 一个是定向随机游走步数,即每个源数据包副本的传递次数,设置为cn/m,用变量N来计数;副本每传递一次N的值加1,当N>cn/m时,副本被丢弃,不再传递.另一个参数是每个节点接收一个新到达的源数据包副本的概率,算法中设置为alnk/k.算法性能主要由这两个参数决定.下面做具体分析. 当算法1执行完成之后,k个源数据包被分布式地存储到网络的n个节点中,每个节点存储的存储数据包都是若干个源数据包的异或和(每个源数据包和存储数据包都看做是二元域上的比特向量).下文将分析Sink节点收集到多少个存储数据包之后可以恢复原来的k个源数据包. 假定Sink节点出现后,随机地从k+ε个未损坏节点中收集了k+ε个存储数据包.为便于描述,这k+ε个存储数据包表示为Yi,i=1, 2, …,k+ε.每个存储数据包都是源数据包的线性组合,因此,任意一个Yi,i=1, 2, …,k+ε,都可以表示为下式(式中的乘法为二元域上的元素与二元域上的向量之间的数乘): Yi=gi·[X1,X2,…,Xk]T, (1) 其中,X1, …,Xk表示k个未知的源数据包,gi是一个独立的且取值在二元域上的随机行向量,称为存储数据包Yi的生成行向量.当gi的某个元素gij取值为1时表示对应的源数据包Xi被接收.假定步数为t=cn的并行定向随机游走覆盖的各节点均匀地分布在网络中,那么,由算法1可知:gi中每个元素gij,j=1,…,k,都是独立取值的,且都服从式(2)定义的分布. (2) 这k+ε个存储数据包的生成行向量构成了一个(k+ε)×k阶矩阵G(k+ε)×k,称为这k+ε个存储数据包的生成矩阵,即G(k+ε)×k= [g1,g2, …,gk+ε]T.借助生成矩阵,这k+ε个存储数据包可以表示为 [Y1,Y2,…,Yk+ε]T=G(k+ε)×k·[X1,…,Xk]T. (3) 若生成矩阵G(k+ε)×k存在一个可逆k×k阶子矩阵,也就是G列满秩,则式(3)定义的方程组存在惟一一组解,解方程组后可求得k个未知的源数据包X1, …,Xk.因此,Sink节点可由任意k+ε个存储数据包计算得到k个未知源数据包的概率等于这k+ε个存储数据包的生成矩阵G(k+ε)×k列满秩的概率.如果用Pfailure表示二元域上的生成矩阵G(k+ε)×k列不满秩的概率,当式(2)成立时,得到如下结论: 引理1 当G(k+ε)×k的每个元素的取值服从式(2)定义的分布时,Pfailure的上界为 (4) 证明 若G(k+ε)×k的各列线性相关,则G(k+ε)×k列不满秩,因此 (5) 令R表示G(k+ε)×k的任意一个行向量,用w表示向量x中1的个数,因为行向量R的每一个元素取值独立,且取值为1的概率由式(2)定义,因此 (6) 因为矩阵G(k+ε)×k的每一个行向量独立,因此,G(k+ε)×kxT=0的概率为 (7) 当向量x取所有不同的值时,根据式(5)可得到引理1中的结论. 综合上述分析,可用如下定理1描述算法1的性能. 定理1 采用算法1,Sink节点可由随机选取的k+ε个存储数据包计算得到原来的k个源数据包的概率Psuccess满足: (8) 另外,通过数值实验发现(鉴于篇幅关系,这里不再列出相关实验结果),当式(8)中的参数(1-exp(-c))a≥2 时,Psuccess的下界主要由ε的值决定,可以用简化表达式 1-(1/2)ε近似表示Psuccess的下界. 算法的数值实验在MATLAB环境下进行.用随机生成的二维随机图模拟网络,在L×L= 100×100的正方形区域随机均匀地分布n个点模拟传感器网络各个节点,其中数据节点的比例设置为40%,即k=0.4n,每个节点的通信半径R满足R2= (2 lnn/(πn))L2(按照随机几何图的理论,这一条件保证了网络极大的连通概率).实验分为两组,第1组测试网络的通信成本,即存储过程中每个源数据包在达到一定的网络覆盖率前提下需要在网络中的传递次数.通信成本越低,越有利于节约网络中各节点的通信能耗.第2组测试读取源数据包时的访问成本,即存储完成之后,Sink节点需要访问多少个存储数据包才能恢复出原来的k个源数据包.访问成本越低,允许损坏的传感器节点就越多,网络的可靠性就越高. 每个源数据包都按照并行随机游走机制在网络中传递,每个源数据包并行传递的副本数设为m=2,当m个副本总的传递次数,即随机游走的总步数为t时,网络覆盖率的理论值[9]近似为 1-exp(-t/n).实验中将并行定向随机游走的总步数设为t=cn时,单个副本的传递次数设置为cn/m.实验测试了k个源数据包对网络各节点的平均覆盖率与系数c之间的关系.作为对比,也测试了采用简单随机游走机制时的相关性能.图1、图2所示为n,k,c取不同值时的实验结果. 图1 源数据包通信成本测试1(随机游走步数t=cn, n=500, k=200)图2 源数据包通信成本测试2(随机游走步数t=cn, n=1000, k=400) 从图1和图2中可以看出,采用并行定向随机游走机制,k个源数据包对网络覆盖率平均值的实验值与理论值 1-exp(-t/n) 是近似相等的.当t=n时,实验值接近60%,当t=3n时,基本上每个源数据包都能覆盖网络中超过95%的节点.而采用简单随机游走规则,实验值明显小于理论值,比并行随机游走机制的网络覆盖率平均低约20%.因此,采用定向随机游走机制能有效降低网络的通信成本.同时,采用并行定向随机游走机制时,网络中每一时刻平均有mk个源数据包被同时处理,提高了网络的吞吐率,节省了整个存储过程的耗时;而采用简单随机游走机制时,网络中每一时刻只有k个源数据包处理. 需要说明的是,当每个源数据包并行传递的副本数m小于lnn值时,实验结果与图1和图2所示类似;而当m大于 lnn值时,网络覆盖率随m的增大而减小. 测试存储过程完成之后,Sink节点为得到k个源数据包而访问的存储数据包的个数.实验结果用如下两个变量之间的关系描述:源数据包恢复开销η,即Sink节点访问到的存储数据包个数h与源数据包个数k之差;源数据包恢复成功率S,即Sink节点能从h个存储数据包计算出k个源数据包的概率. 实验中主要调节参数为每个源数据包的并行定向随机游走的总步数cn的系数c以及每个传感器节点接收一个新到达的源数据包的概率alnk/k的系数a.图3至图6所示为不同网络规模下,c和a的取值不同时,S与η之间的关系(图中S的每个值都是 1 000 次实验的平均值). 从图3至图6可以看出, 当参数a≥2时, 只要c的取值增大, 就能以较少的源数据包恢复开销成功计算出原来的源数据包.进一步地,从图4、图6可以看出,当参数a=3 时,只要c≥3,Sink节点就能从任意收集到的k+11 个以上的存储数据包以100%的概率恢复出k个源数据包.此时,式(8)中的 (1-exp(-c))a≥ (1-exp(-3)) 3≈ 2.85.按定理1的结论,当η≥11 时,理论上Sink节点可由任意k+η个存储数据包计算得到原来的k个源数据包的概率S近似大于 1-2-11≈ 99.95%,实验值基本上验证了理论值. 图3 源数据包访问成本测试1(n=500, k=200, 参数a=2)图4 源数据包访问成本测试2(n=500, k=200, 参数a=3) 图5 源数据包访问成本测试3(n=1000, k=400, 参数a=2)图6 源数据包访问成本测试4(n=1000, k=400, 参数a=3) 鉴于篇幅有限,参数a和c取其他值时的实验结果不在文中列出.不过笔者发现,当 (1-exp(-c))a小于2时,实验结果不稳定;当 (1-exp(-c))a取值不是很大时,实验结果与 (1-exp(-c)) 3 时的类似;而当 (1-exp(-c))a取值较大时,反而会使得成功恢复源数据包的概率降低.因此,建议在实际应用中,取a=3,c=3 即可,这样既能获得好的稳定性,也能使网络各节点的计算成本较低(因为a的值越大,每个节点接收源数据包的概率就越大,因而计算成本就会提高). 文献[6]提出的基于LT码的算法中,单个源数据包在网络中总的传递次数为O(nlnn),并指出这一值达到 3nlnn时实验效果较好.而文中方法所需传递次数为O(n),实验中将这一值设置为3n时就能得到很好的源数据包恢复性能.另外,采用基于LT码的算法,Sink节点为了恢复出k个源数据包而需要访问的存储数据包的个数与LT码的译码性能有关.文献[6]的实验表明,当k大于100时,只有当源数据包恢复开销η的值较大(大于100)时,Sink节点才能成功恢复出源数据包.而采用文中方法,不论k的取值如何,成功恢复k个源数据包,Sink节点只需访问k+11 个存储数包.对于某些实验参数,文中算法(源数据包传递次数设置为3n,参数a的值设置为3)与基于LT码算法(源数据包传递次数设置为 3nlnn,译码时采用极大似然译码算法)的具体对比结果列于表1中. 综上可得出结论: 采用文中算法可以有效节约存储过程中的通信成本和Sink节点的访问成本. 表1 性能比较 笔者研究了无人值守传感器网络的高可靠性数据存储问题,依靠源数据包传递过程中的并行定向随机游走机制和网络中每个节点对源数据包的独立处理机制,提出了一种执行简单,性能高效的分布式数据存储算法.与同类方法相比,文中方法能有效降低存储过程中各节点的通信成本和Sink节点的访问成本. [1] Reddy S K V L, Ruj S, Nayak A. Distributed Data Survivability Schemes in Mobile Unattended Wireless Sensor Networks [C]//Proceedings of IEEE GLOBECOM. Piscataway: IEEE, 2012: 979-984. [2] 郭江鸿, 马建峰, 张留美, 等. 高效的无线传感器网络加密数据汇聚方案 [J]. 西安电子科技大学学报, 2013, 40(3): 95-101. Guo Jianghong, Ma Jianfeng, Zhang Liumei, et al. Efficient Encrypted Data Aggregation Scheme for Wireless Sensor Networks [J]. Journal of Xidian University, 2013, 40(3): 95-101. [3] Mitra S, De Sarkar A, Ray S. A Review of Fault Management System in Wireless Sensor Network [C]//Proceedings of the CUBE International Conference on Information Technology. New York: ACM, 2012: 144-148. [4] Vitali D, Spognardi A, Mancini L V. Replication Schemes in Unattended Wireless Sensor Networks [C]//Proceedings of 4th IFIP International Conference on New Technologies, Mobility and Security. Piscataway: IEEE, 2011: 1-5. [5] 任伟, 任毅, 张慧, 等. 无人值守无线传感器网络中一种安全高效的数据存活策略 [J]. 计算机研究与发展, 2009, 46(12): 2093-2100. Ren Wei, Ren Yi, Zhang Hui, et al. A Secure and Efficient Data Survival Strategy in Unattended Wireless Sensor Network [J]. Journal of Computer Research and Development, 2009, 46(12): 2093-2100. [6] Kong Z, Aly S A, Soljanin E. Decentralized Coding Algorithms for Distributed Storage in Wireless Sensor Networks [J]. IEEE Journal on Selected Areas in Communications, 2010, 28(2): 261-267. [7] Cooper C, Frieze A. The Cover Time of Random Geometric Graphs [J]. Random Structures and Algorithms, 2011, 38(3): 324-349. [8] Avin C, Krishnamachari B. The Power of Choice in Random Walks: An Empirical Study [J]. Computer Networks, 2008, 52(1): 44-60. [9] Tzevelekas L, Oikonomou K, Stavrakakis I. Random Walk with Jumps in Large-scale Random Geometric Graphs [J]. Computer Communications, 2010, 33(13): 1505-1514. [10] Cooper C, Frieze A, Radzik T. Multiple Random Walks in Random Regular Graphs [J]. SIAM Journal on Discrete Mathematics, 2009, 23(4): 1738-1761.2 高性能分布式数据存储算法
2.1 算法流程
2.2 算法性能分析
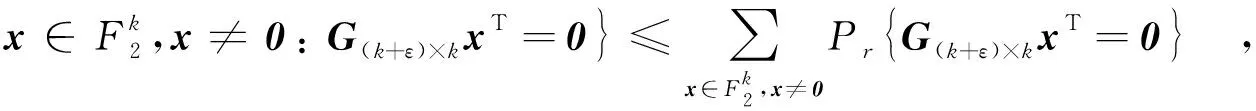
3 数值实验
3.1 存储源数据包的通信成本实验
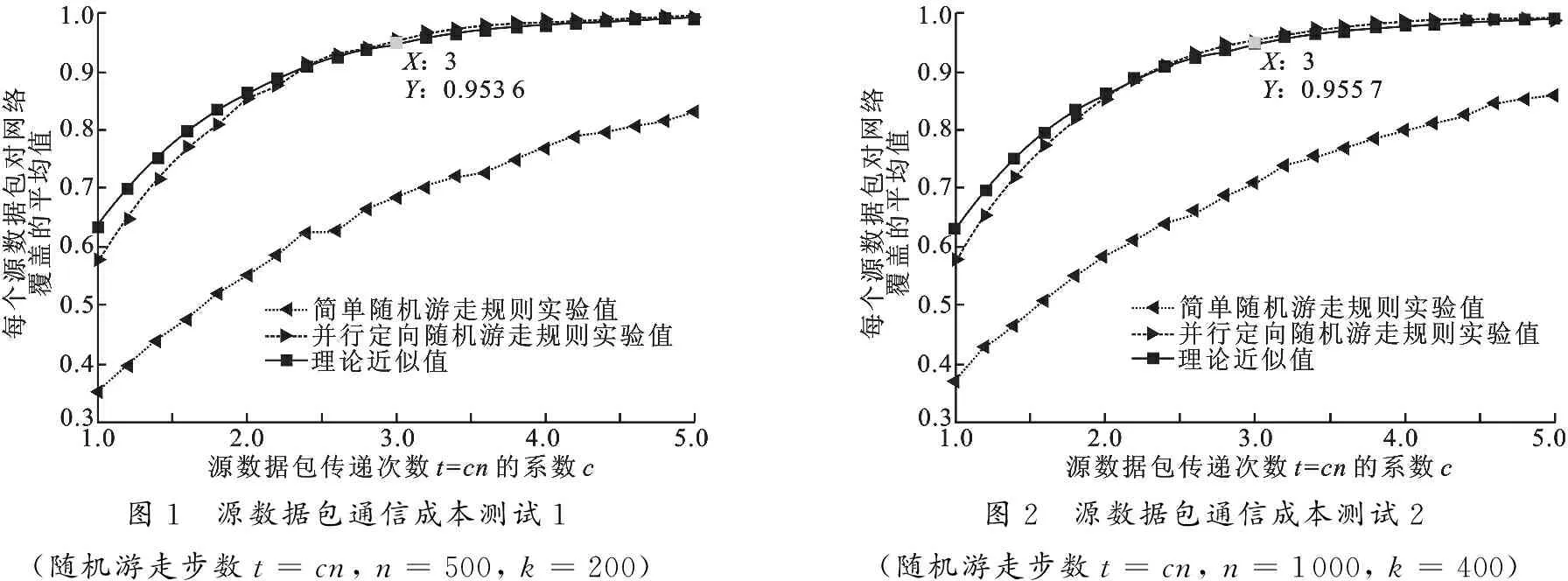
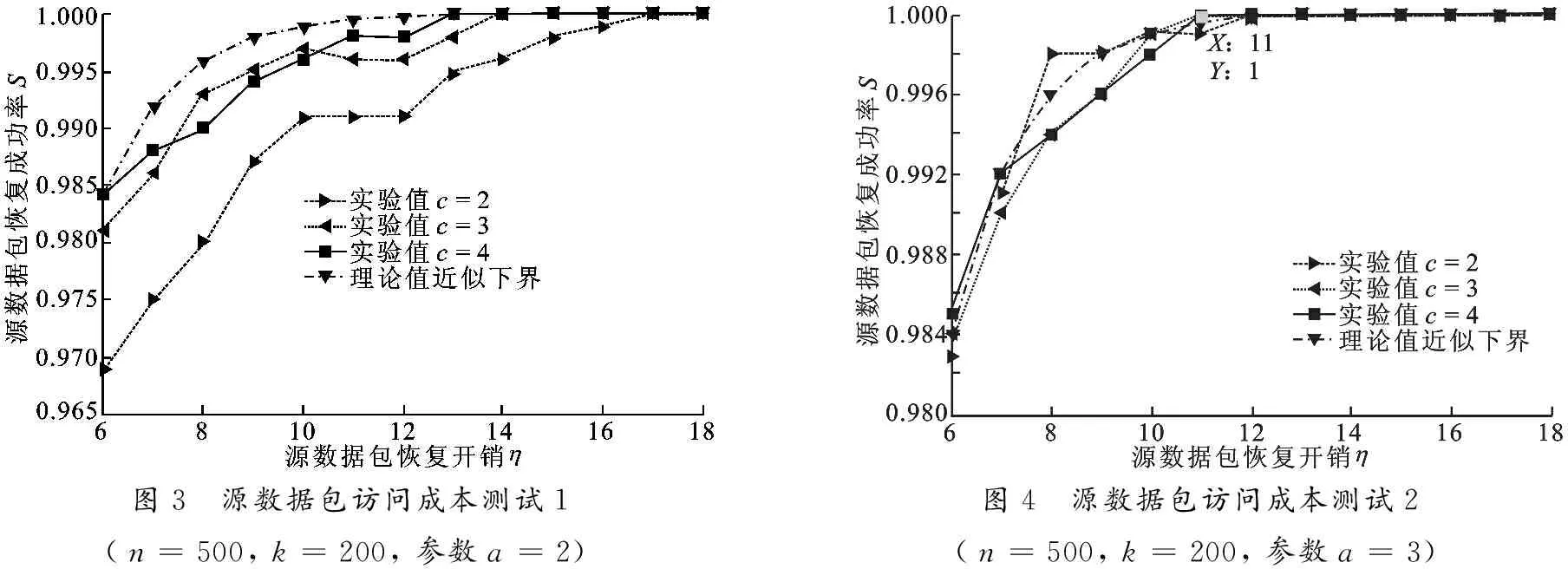
3.2 读取源数据包的访问成本实验

3.3 性能比较

4 结 束 语
