微博负向情感热点话题发现模型
2014-07-09刘一丹邸书灵范通让
刘一丹,邸书灵,范通让
(石家庄铁道大学 信息科学与技术学院,河北 石家庄 050043)
当今,网络已成为舆情爆发的活跃之地。微博作为一种新兴的社交媒体,以其强大的互动性、时性和随意性,更是为舆情的传播提供了绝佳的场所。微博低门槛的传播特性,使大量信息能够快速且大范围的传播,造成短时间内事件的突发,进而引起热点话题的涌现。热点话题即在短时间内引起人们热议的一些话题,其中带有消极情感热点话题的爆发会煽动民众的情绪,甚至引起民众恐慌。因此对微博中含有负面情感的热点话题进行发现具有重要意义。
本文提出了一个微博负面情感热点话题发现模型。该模型从情感角度出发,引入文本情感分析的原理,对微博进行情感划分,提取具有消极情感的负面微博进行分析及聚类得到负向情感热点话题。为了更好地为舆情分析提供前提,本文继续对负向情感词进行了细粒度的划分,将负向情感热点话题划分为轻度负向、负向、极度负向三个类别。
1 相关工作
1.1 话题追踪与检测
话题检测与追踪一直是舆情发现的核心内容。随着Web 2.0发展,微博成为民众发表意见的首要社交媒体,庞大的信息来源使话题检测与追踪(TDT)领域将目光转向微博热点话题的发现。目前,在微博热点话题检测领域主要从微博文本内容和用户信息两方面考虑。从文本内容主要是基于词频统计发现关键词[1],但是这并没有将微博的实时性考虑在内。从用户信息则针对用户关系进行分析或排名发现热点话题[2],但用户分析方面干扰大、噪声多,度量复杂。
微博热点话题的实时性是最重要的一个特征。Sankaranarayanan[3]等提出了Twitter-Stand扑捉实时热门的Twitter新闻话题。Mario[4]等在热点话题发现中引入时序概念,提出热点话题即在一段时间内频繁出现但之前很少出现的话题。郑斐然[5]等提出词语增长系数来发现微博中新闻话题。薛素芝[6]等提出词语增长速度评价主题词很好的将时序性融入微博热点话题发现中。但是以上微博热点话题发现并没有对话题情感加以区分。对于舆情的发现与检测,消极情感的话题发现更为关键。Garcia[7]等指出研究表明微博中消极词语的使用更为频繁且信息量更大。李炤[8]等结合网民心里特征提出了基于一段时间内极度负向情感微博挖掘热点话题。但是微博是实时互动的,只将极度负向情感考虑在内并不全面。
1.2 机器学习情感分类器
分类器是机器学习领域一种重要的一种数学模型,通过分析或从训练集“学习”来构造它。目前,用于分类的主流算法有朴素贝叶斯算法、最大熵算法、决策树算法等。Pang[9]等使用支持向量机、朴素贝叶斯,最大熵算法对电影评论文本进行情感分类,发现支持向量机方法最好。李炤[8]等使用朴素贝叶斯、最大熵和决策树算法对情感微博进行分类,通过比较发现朴素贝叶斯算法效果最好。
基于上述原因,笔者从情感角度出发,为舆情发现做铺垫,针对负向情感的热点话题进行发现。通过构造情感分类器,选择性地选取负面情感的微博博文用于话题发现,在话题发现过程中综合考虑词频和词语增长速度评价主题词,在词语增长速度的计算中引入了用户信息,进一步提高热点话题发现的准确度。
2 微博负向情感热点话题发现模型
本研究的话题发现模型以中文微博为主,不同于以Twitter为主的英文微博,140个字的中文微博包含的信息量更为复杂。提出的模型主要分为预处理,分词,情感分类,主题词检测,话题聚类,话题情感分类几大部分,详见图1。
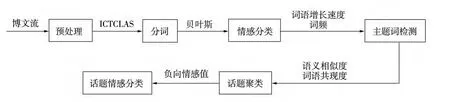
图1 整体流程图
2.1 数据预处理
微博文本简短且格式多样,在话题检测之前,需对爬取的文本进行预处理,滤除噪声以避免对词频统计及话题聚类造成干扰。本文在进行预处理时,大致分为两类:一类是针对微博本文本内容的预处理;另一类是针对微博用户一些其他数据的预处理。
(1)对文本内容的预处理
①滤除“@用户名”格式信息:微博中用“@某用户”的格式来表示提到某个用户,因此该类信息带有特定指向,通常为好友之间的对话,具有用词随意,描述事件的可能性小等特点,对话题词检测贡献小。
②滤除“#话题词#”格式信息:微博中用“#话题词#”来表示参与某个特定主题,但这类话题词常常有微博平台发出,人为、商业因素明显,并伴有大规模的转发量,对词频统计影响大。
(2)对用户数据的预处理
滤除不活跃用户、僵尸用户信息:不活跃用户即一些注册用户并不经常登录,这些用户关注度及粉丝数很少。即使登录也只浏览自己关注的信息,不参与评论与转发。而僵尸用户,通常是由系统自动产生的恶意注册用户,收听人数少(粉丝数),会发布大量重复的内容用于一些商业目的。这两种对话题检测具有干扰作用的用户均具有粉丝数少的特点,因此在判断方法上,本文选取滤除粉丝数小于阈值F的账号。
2.2 分词
分词是中文文本处理的关键,分词的好坏直接影响到话题的聚类。热点话题的流行往往伴随着一系列网络新词的诞生,因此新词的发现在分词过程中显得尤为重要。笔者直接采用中科院分词系统ICTCLAS对预处理之后的文本语料进行自适应分词处理。该系统通过采用基于信息交叉熵自动发现新词特征,并自适应测试语料的概率分布模型的方法进行自适应分词,该方法能够良好的发现语料中的新词[8]。除此之外,该系统还具有词性标注的功能,根据词性,我们保留对话题表达贡献最大的动词和名词。
2.3 情感分类器
2.3.1 朴素贝叶斯算法
目前,在情感分类方面,朴素贝叶斯算法被认是一种简单而有效的算法,采用朴素贝叶斯分类器作为微博情感分类。朴素贝叶斯分类器的依据是贝叶斯定理[11]。
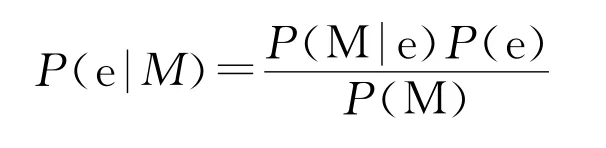
其中,e表示文本情感(正向、负向),m表示某条微博,P(M)对于每条微博来说是相同的。在训练集中,我们等量选择两种情感微博,即P(e)也是相等的,因此P(e|M)最终取决于P(M|e)。
将每条微博使用n个特征项表示M={m1,m2,…,mn},最终公式如下。
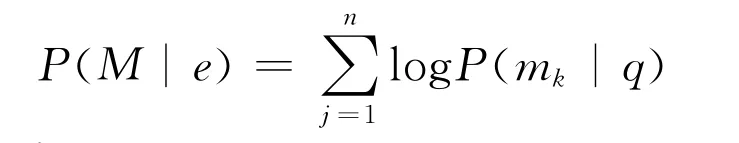
2.3.2 特征项选取
分类器的准确性主要取决于特征项的选取,主要考虑情感词对微博情感的贡献,情感词的情感极性主要由Hownet情感词典来判断,正向情感词极值为1,负向情感词极值为-1。选用的特征项分类表如表1。

表1 特征项分类表
2.4 主题词检测
微博强大的实时性使得传统的话题检测方法不再适用。将微博的文本按照固定的时间窗口划分成若干块,每块都固定一个时间长度T,T取决于具体实验采样频率。然后综合考虑词频、词语增长速度两个因子的复合权值来评价一个关键词。
(1)词频:词频即一个词在一段时间内出现的次数。当一段时间内某个词在频繁出现,并且出现频率高于其它词汇,则认为该词高概率的与热点话题相关联。

其中Tij是词wi在时间窗口j的相对词频,fij是词wi在时间窗口j的频率,fmax是时间窗口j的最高词频。
(2)词语增长速度:词频增长率是指某词在该时间窗口内的词频相对之前k个窗口的增长情况。此值越大说明该词在当前时间窗口出现了激增情况,则该词高概率的与话题词相关。除此之外,还引入了用户增长速度,一个词能否成为热点话题词还要看它传播的广度。此值越大,说明使用该词的不同用户大量增加,则该词高概率与话题词相关。

其中,Gwi是词i的相对词频增长率,Guseri是词i的用户增长率,uij是窗口j内与词语i有关的用户数量。这是词语i的词语增长速度兼顾这两者,公式如下:Gij=a×Gwi+b×Guseri
上述方法对每个词计算其Wij,选取大于阈值F的关键词作为主题词进行话题聚类。
2.5 话题聚类
一个热点话题应该是包含若干个主题词的一个集合,聚类的目的就是将上节中提取的属于同一个话题的候选主题词归类到一个话题簇中。以往的思路就是根据词意的相似度来进行词语的聚类匹配,但是一个具体的话题的多个主题词并无语义很大的联系。例如“马航失联,民众忧心忡忡,愿遇难同胞平安”这个条博文中,主题词{马航、失联、忧心忡忡}在语义上毫无联系。然而,我们发现这些词都同时出现在同一条微博中,这种情况我们称之为词语共现。因此在语义相似的基础上,再采用词语共现度来对词语相似度进行度量。
对于两个指标,具体算法如下:
(1)对于两个主题词c1,c2,基于知网语义相似度计算S(c1,c2);
(2)计算两个主题词c1,c2的共现度C(c1,c2)。
(3)计算两个主题词复合相似度F(c1,c2)=αS(c1,c2)+βC(c1,c2),复合相似度大于一定阈值F,归到一个话题簇当中。

上式中,P(c1|c2)为c2出现时c1出现的概率,P(c2|c1)为c1出现时c2出现的概率,f(c1c2)为c1、c2同时出现的概率。
2.6 负向情感热点话题分类
微博信息传播门槛低,群众参与广泛,这使热点话题能够在短时间内波及全国各个角落。负向情感的热点话题更是推动网络舆情发展的强大助力。本节从情感角度,将负向情感的热点话题进一步划分为轻度负向话题、负向话题、极度负向话题三类,细粒度的情感倾向划分更有利于舆情的监控。
2.6.1 细粒度负向情感词划分
情感词是情感分析的重要指标,文献[10]中得到的基于心理感受的情感词共有390个,文献[8]对其进行褒贬分类得到72个负向情感词,笔者对这些负向情感词进行更细致的划分,并为其赋予情感极值。
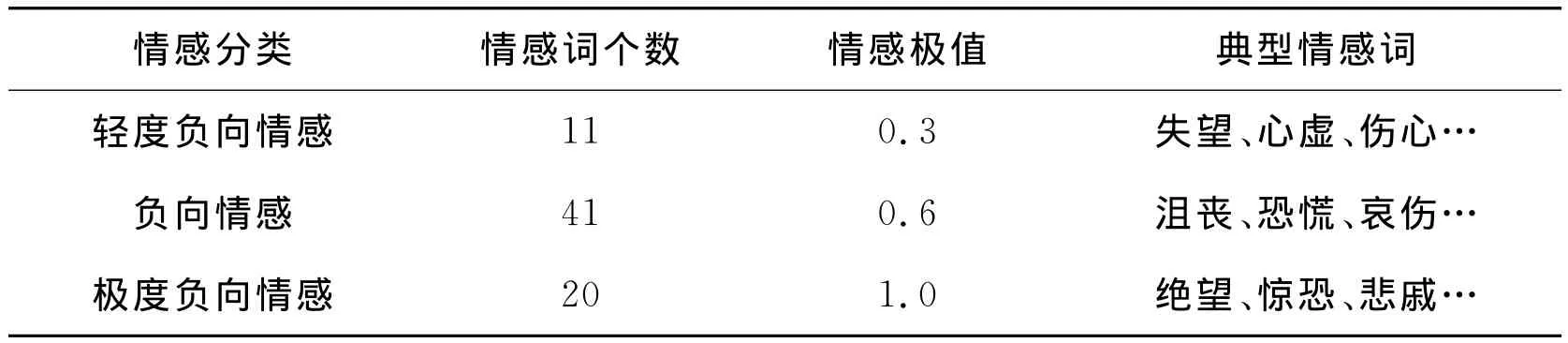
表2 细粒度负向情感词分类表
2.6.2 负向情感热点话题分类
本节将负向情感热点话题分为三类,具体分类方法:首先,根据负向情感词表计算博文i的负向情感值esi;然后统计每个时间窗口中计算包含主题词i博文的个数,计算每个主题词的负向情感值eci;最后计算话题i负向情感值eci,若该值在(0.3,0.5)之间为轻度负向热点话题,在(0.5,0.7)之间为负向热点话题,在(0.7,1)之间为极度负向热点话题。
(1)博文负向情感值:若每条博文中包含n个负向情感词,则该条博文的负向情感值公式如下。

(2)主题词负向情感值:若各个时间窗口中包含主题词的博文有m个,则该主题词的负向情感值公式如下。

(3)热点话题负向情感值:如一个热点话题包含k个主题词,则该热点话题的负向情感值计算公式如下。

3 结束语
提出了一种从微博负向情感的博文中发现消极态度的热点话题模型,利用机器学习的方法构造情感分类器,筛选出负向情感的微博文本。考虑到微博强大的实时性,将微博文本划分时间窗口,并在词频的基础上引入词语增长速度提高主题词评价的准确性。在本文的最后,又通过三个级别的情感值计算最终得到话题的负向情感值,对负向情感热点话题在情感强度上进一步划分。在下一步的工作中,将进一步对微博文本情感分析进行深入研究以提高情感分类器的精度。此外,如何利用Hashtag这一信息更为准确地对热点话题进行发现,也是未来的工作目标。
[1]Rosa K D,Shah R,Lin B.Topical clustering of tweets[C]//Proceedings of 17th ACM SIGIR:SWSM.2011.
[2]杨武,李阳,等.基于用户角色定位的微博热点话题检测方法[J].计算机应用,2013,33(11):3076-3079.
[3]Sankaranarayanan J,Samet H,Benjamin E T.TwitterStand:news in Tweets[C]//Proceeding of the 17th ACM SIGSPATIAL Internationnal Conference on Advances in Geographic Information Systems.York News:ACM,2009:51-52.
[4]Mario,Luiqi D C,Claudio S.Emerging topic detection on twitter based on temporal and social terms evaluation[C]//MDMKDD 10Proc of the 10th International Workshop on Multimedia Data Mining.2010:1-10.
[5]郑斐然,苗夺谦,等.一种中文微博新闻话题检测的方法[J].计算机科学,2012,39(1):138-140.
[6]薛素芝,鲁燃,等.基于增长速度的微博热点话题发现模型[J].计算应用与研究,2013,30(9):2599-2601.
[7]Garcia D,Garas A,Schweitzer F.Positive words carry less information than negative words[J].EPJ Data Science,2012,1(1):1-16.
[8]李炤.基于微博情感分析的网络舆情热点话题检测方法[D].兰州:兰州大学,2013.
[9]Pang B,Lee L,Vaithyanathan S.Thumbs up:sentiment classification using machine learning techniques[C]//Proceedings of the ACL-02conference on Empirical methods in natural language processing-Volume 10.Association for Computational Linguistics,2002:79-86.
[10]许小颖,陶建华.汉语请安系统中情感划分的研究[C].//第一届中文情感计算及智能交互学术会议论文集.2003.
[11]张珊,于留宝,等.基于表情图片与情感词的中文微博情感分析 [J].计算机科学,2012,39(11):146-176.
