基于核心词和实体推理的事件关系识别方法
2014-04-14杨雪蓉姚建民朱巧明
杨雪蓉,洪 宇,马 彬,姚建民,朱巧明
(苏州大学计算机信息处理重点实验室,江苏苏州215006)
1 引言
事件是指特定时间和环境下,由若干角色参与,并表现出某种行为或状态特征的客观事实(也称“自然事件”)。文本中的事件则是这一客观事实诉诸文字的独特语用形式,多见于新闻报道、评论或博文等。自然事件往往不是孤立个体,其发生与发展往往与外在的其他自然事件有着本源的逻辑关系,如“因果”(Contingency)和“时序”(Temporal)关系等。然而,自然事件一经诉诸文字并形成文本中的事件体,成为信息传播中可读可解的语言流,则必须遵循自然语言的行文规律,也使得事件关系作为重要的逻辑脉络,参与文本结构和语义表述的形成过程。因此,表述事件以及事件关系的文本信息相应地蕴含着特定的分布规律。形成一种自动识别和检测事件关系的自然语言分析和信息处理机制,对于面向大规模信息流中的离散事件,实现话题推演和话题预测,有着重要的辅助作用。
事件关系识别是一种针对“事件间逻辑关系存在与否”进行自动判定的浅层事件关系检测任务。事件关系检测任务分为两部分:事件关系识别和事件关系判定。事件关系识别通过解析文本结构或语义特征,对文本中描述不同自然事件的文本片段(包括短语、子句、句子和段落)直接给出“有关”或“无关”判定结果。事件关系判定需要对关联事件给出明确的语义关系或逻辑关系标签(如“因果”、“时序”、“扩展”和“对比”等)。因此,预先确定事件之间是否存在关联性,是深入解析事件逻辑关系的重要前提条件。
同一话题下的事件由种子事件或活动以及其相关的外延事件或活动组成。如事件“恐怖分子劫持飞机撞毁世贸大厦”是话题“9/11恐怖袭击”的种子事件,而“袭击嫌疑犯调查”是话题“9/11恐怖袭击”的后续外延事件。为了更细粒度的识别事件之间关联与否,将事件关系识别分为三个层面:1)“种子事件(Seminal Event)”间的关系识别(简称“SS识别”);2)“种子事件”与“外延事件(Extensional Event)”间的关系识别(简称“SE识别”);3)“外延事件”间的关系识别(简称“EE识别”)。
“SS识别”侧重识别一致事件的不同文本描述,现有文本建模和相似度度量方法,如“语言模型(Language Model)”并辅以“KL距离(Kullback-Leibler Divergence)”,已给出较为有效的处理手段。“SE识别”侧重以种子事件为中心,实现关联事件的向心内聚(即话题聚类),其观点是同一话题框架下的不同事件一致地与种子事件具有逻辑关联性。然而,“SE识别”忽视了一种重要现象,即虽然同一话题框架下的外延事件向心地关联于同一种子事件(假设话题未发生漂移或形态变异),但外延事件之间却并非存在必然联系。例如,“中菲黄岩岛对峙”话题下的外延事件“日本三舰访菲”和“菲香蕉被滞留”虽然关联于核心事件“中菲对峙”,但两两之间并无联系。“EE识别”即是针对这一问题提出的事件关系识别任务,其侧重判定外延事件间是否存在逻辑关系。
相对而言,“SS识别”与“SE识别”的难度较低,前者可通过语义一致性或文本近似性予以判定,后者则可用种子事件作为标杆,实现文本聚类,并判定同一聚类中所有文本蕴含的事件皆相关。“EE识别”的难度则较高,其待判定的“外延事件对”本身并非一致事件,文字描述必然差异较强,语义或内容一致性判定方法无法有效利用;同时,相关于同一核心的“外延事件对”之间并非必然关联,现有话题聚类方法并不适用。从而,“EE识别”是针对大规模离散事件流实现关系识别的关键难点。
针对“EE识别”问题,本文提出一种基于事件核心词和事件实体关联线索的事件关系识别方法,该方法利用事件核心词(Event Term)和事件实体(Event Entity)的分布特性,构建事件关系逻辑线索,形成目标事件的虚拟相关事件(virtual related event,简称vre)集合(即,利用事件的新闻背景得到与目标事件相关联的事件),最终建立事件线索(Event Cue,简称Ecue)集合,实现同一话题下事件相关性的自动识别。
本文组织如下:第2节介绍事件关系检测的相关工作;第3节给出事件关系识别任务定义;第4节分析事件中核心词及实体的分布特性;第5节详细阐述本文方法;第6节介绍实验;第7节总结。
2 相关工作
由于在自动问答、自动文摘和事件预测等方面应用需求的增加,事件关系检测逐渐成为新的研究热点[1],其中不乏可以在事件逻辑关系识别研究中借鉴的理论与方法。下面主要分为两个方面予以简介。
·模板匹配法
事件关系检测的主要方法之一是借助事件特征的模式匹配,例如,利用事件触发词的关系模式匹配,根据人工定义的模板,对文本中符合模板的事件关系进行抽取。Chklovski等[2]利用LSP(Lexcial-Syntactic Pattern,即词-句匹配模板)抽取具有事件关系的资源,并将抽取的结果整理成一个称为“VerbOcean”的知识库。Chklovski等利用人工收集的LSP模板,抽取了6种时序关系(similarity,strength,antonymy,enablement,happens和before)的“事件对”。人工定义的事件关系模板往往受数量限制,造成关系检测的低召回率问题。Pantel[3]通过Espresso算法进行自动模板的构建,算法在给定少量关系实例的情况下,通过机器学习方法对现有模板进行迭代扩展,在一定程度上改进了模板匹配方法的召回率。
·元素分析法
以事件元素为线索的研究大都继承了Harris[4]的分布假设。Harris假设指出,处在同一上下文环境中的词语具有相同或相似的含义。Lin[5]提出了一种结合Harris分布假设和建立依存树思想的无监督方法,称为DIRT算法。算法将所有事件构造成依存树形式,树中的每条路径表示一个事件,路径的节点表示事件中的词语。如果两条路径的词语完全相同,则这两条路径所表示的事件相同或者相似。Szpektor[6]提出一种基于TE/ASE算法的无监督学习方法,该方法包含两步:首先利用ASE算法挖掘相似的事件元素集合;然后使用模板抽取算法,收集包含以上元素的句子,将收集的句子作为模板进一步挖掘事件关系。
马彬[7]通过分析事件在演化过程中的语义依存规律,提出一种基于语义依存线索的事件关系识别方法,该方法通过定位文本信息流中的事件,并分析事件之间的依存特征,挖掘事件关系的推理线索(即“依存线索”),实现事件关系的自动识别。
3 任务定义
3.1 事件
事件是一种描述特定人、物、事在特定时间和特定地点相互作用的客观事实。事件由事件核心词和事件实体组成。事件的核心词能够描述一个事件的发生,主要为动词或者动名词。本文将事件描述的依存分析结果中与根节点(“ROOT”节点)相连的词作为该事件的核心词,如图1所示。

图1 事件核心词、依存实体、共现实体定义示例
图1是事件“金正恩当选”的依存分析结果,该句子中与根节点直接相连的词是“当选”,该词能够描述该事件的发生,因此将“当选”作为该事件的核心词。为了验证该方法的可行性,对随机选择的500个事件进行核心词标注,对比发现,人工标注的核心词有87.8%与通过依存分析得到的核心词一致。
事件实体是指事件的参与者,通常为名词。本文将事件实体分为两种类型:依存实体(Dependency Entity,DN)与共现实体(Co-occurence Entity,CN)。依存实体是指事件描述通过依存分析,与事件核心词直接相连的实体,依存实体与核心词语义相关联,如图1中的“金正恩”和“委员长”;共现实体是指事件描述通过依存分析,不与事件核心词相连的实体,如图1中的“朝鲜”、“劳动党”等。
事件关系表示事件之间的逻辑关系,是事件之间固有的一种客观存在。本文侧重研究事件之间的语义关系,即从事件的组成结构以及篇章语义关系的角度解释事件的逻辑关系。
3.2 事件关系识别
话题检测任务中,将包含一个种子事件或活动及与其直接相关的事件或活动的语言形式定义为话题[8]。根据话题的定义,一篇报道论述的事件或活动与特定话题的种子事件有着直接的联系,那么该报道即与话题相关。然而,新闻报道往往包含多个不同事件的论述,报道的主题或主体内容相关于话题主旨,并不能保证报道内所有局部事件都相关于话题。同时,如前一节所述,同一话题框架下的外延事件之间也不能保证逻辑相关,因此,传统的话题检测方法仅能实现对事件关系的粗粒度识别和检测,即同一话题下所有事件或活动都与话题本身有直接联系,但不能针对话题内任意“事件对”之间的关系给出准确判定。
同一话题下的事件分为种子事件和外延事件,本文针对同一话题下的任意两个外延事件的相关性进行识别。同一话题下的外延事件与种子事件相关,但并非两两相关。例如,话题“中国和菲律宾黄岩岛对峙”中包含如下事件。
事件e1“日本三军舰访问菲律宾”
事件e2“菲律宾香蕉在中国港口被滞留”
事件e3“菲律宾香蕉商在中国损失14.4亿比索”
事件e4“日本免费向菲律宾提供十余艘巡逻船”
上述4个事件均与话题“中国和菲律宾黄岩岛对峙”的核心事件存在直接联系。除事件e1和事件e4,事件e2和事件e3存在逻辑关系外,其他任意两事件之间并不存在逻辑关系。同时,事件的相关性(Event Relevancy)与事件的相似性(Event Similarity)不同,事件的相关性是指两个事件之间是否具有关联性,因此,仅仅通过两个事件的文字表述方式无法判断关联与否,需要挖掘更多的外部信息,充分利用外部信息辅助事件关联性的识别;而事件的相似性侧重识别一致事件的不同文本描述(事件相同,描述形式多样),现有文本建模和相似度度量方法,已给出较为有效的处理手段。
本文的核心问题在于如何挖掘话题内事件间的推理信息和语义关联特征,通过文本事件的核心词以及实体的分布规律,挖掘事件的推理线索,实现事件逻辑关系识别。
4 核心词及实体分布分析
事件由核心词以及相关实体组成,同一话题下相关事件的核心词和实体的分布具有较高的相似性和一致性,而不相关事件的这类信息则没有表现明显的相似性和一致性。例如,话题“日本地震”下,以“地震”和“救援”为核心词的事件具有较强的逻辑关系;而以“大跌”和“救援”为核心词的事件往往不具有逻辑关系;话题“中国和菲律宾黄岩岛对峙”下,包含实体“香蕉”和“中国港口”的事件往往相关;而包含实体“渔民”和“香蕉”的事件往往不相关。因此,事件核心词和实体的分布特性将有助于事件关系的识别。下面分别给出同一话题下实体和核心词的分布数据并辅以分析说明。
4.1 面向事件关系的实体分布分析
分析语料发现,“相关事件对”中的实体分布和“不相关事件对”中的实体分布存在较大差异:“相关事件对”中的实体种类少但频度较大,即有关的实体分布较为均衡;而“不相关事件对”中的实体种类多而且离散,即对应的实体分布较为稀疏。
为了验证以上现象,本文进行了相关的统计实验。给定话题“日本地震”,利用互联网分别检索“地震”和“救援”(“相关核心词对”)、“救援”和“大跌”(“不相关核心词对”),得到与每一个“核心词对”相关的前100个反馈结果摘要(Snippy),统计摘要中出现的事件实体及其频度,形成集合“Rset”和“Nset”,其中,“Rset”是“相关核心词对”中出现的实体集合,“Nset”是“不相关核心词对”中出现的实体集合。抽取集合“Rset”和“Nset”中频率最高的5个事件实体,分别统计每个实体在topN(N=1,2,3,…,100)个摘要中出现的频度,如图2所示。
图2表示事件实体出现的频度随着摘要数量的增加而发生变化的趋势样例(针对较大规模数据的统计如表1所示),其中实线表示与事件“地震”和“救援”共现事件实体的频度;虚线表示与事件“救援”和“大跌”共现事件实体的频度。从图2中可以看出,在同一个话题下,与“相关核心词对”(“地震”和“救援”)共现的实体在摘要中分布较为均衡(均衡的分布在100个检索结果中),即随着摘要数的增加,实体的频度呈显著增长趋势;而与“不相关核心词对”(“救援”和“大跌”)共现的实体分布较为稀疏,随着摘要数量的增加,同一实体的数量增长缓慢或者不增长。因此,上述的实体分布情况反映了相关事件和不相关事件中的实体分布差异,这种分布差异将有助于事件关系的识别。

图2 分别与“相关核心词对”和“不相关核心词”共现的实体分布样例

表1 “相关核心词对”与“不相关核心词”共现实体分布情况
为了量化地验证以上现象,本文随机选择50个“相关核心词对”和50个“不相关核心词对”,通过从互联网检索最相关的100个返回结果,分别统计前N(N=20,40,60,80,100)个反馈结果中出现的事件实体及其频度(表1)。分析表1发现,随着反馈结果数量的增加,相关事件中的实体种类数增长缓慢,不相关事件中的实体种类数增加迅速;而相同反馈结果数量时,随着实体种类数的增加,相关事件中高频实体种类数较多,不相关事件中高频实体种类数较少。因此,相关事件实体的分布具有较高的一致性,该特性能够有效辅助事件关系的识别。
4.2 面向事件关系的核心词分布分析
在特定话题下,同一实体往往出现在相同或相似类型的事件中[9],因此提出以下假设:相关事件中的实体往往参与相同或相似类型的事件,即相关事件中的实体参与的事件(核心词)分布较为集中;而不相关事件的实体参与的事件(核心词)分布较为离散。
为了验证以上假设,本文从相关事件集合中选择50对“相关实体对”,同时从不相关事件集合中选择50对“不相关实体对”。以“实体对”作为检索词从互联网中检索实体参与的事件集合,统计由各个“实体对”反馈的事件集合中核心词的重合度。图3中实线部分表示通过检索“相关实体对”得到的核心词相关度;虚线部分表示“不相关实体对”的核心词相关度,其中横轴表示“实体对”编号,纵轴表示核心词重合度。由图3得出,“相关实体对”参与的事件相关性较大,即相关联事件中的实体参与的事件具有较强的一致性和关联性(事件种类集中);而“不相关实体对”参与的事件相关性较小,即不相关事件的实体参与的事件种类较多,事件分布较为离散,相关性较小。
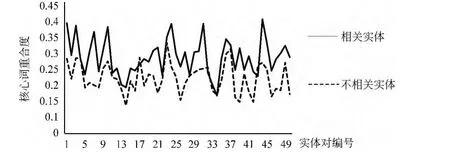
图3 “相关实体对”和“不相关实体对”参与的事件分布
因此,利用以上两种假设,本文提出一种基于实体和核心词推理的事件关系识别方法。
5 基于核心词和实体推理的事件关系识别方法
本研究致力于探究一种基于核心词和实体推理的事件关系识别方法,其核心思想是:事件相关性的识别利用事件的核心词以及实体的分布特性,挖掘与目标事件相关联的事件,形成事件的虚拟相关事件(vre),再进一步通过虚拟相关事件构建事件线索集合(VRE),实现事件关系识别。
基于核心词和实体推理的事件关系识别方法包括如下方面:事件定位、事件线索集构建和事件关系推理。方法总体框架如图4所示。
5.1 事件定位
事件定位的目的是对给定的目标事件探索特定文本中的一致或近似描述,从而得到包含该事件描述的文本片段,以此为媒介,抽取定位点的上下文内容,挖掘与当前事件在核心词以及实体有一致性特征的文本片段,形成虚拟相关事件集。事件定位的处理流程如下:
1)给定事件eA,对其进行分词、词性标注和依存分析等预处理操作;
2)对语料文本进行分句和子句划分,形成(子句,整句)对集合;
3)计算事件eA与所有子句相似度(采用编辑距离算法[7]),从中选择满足相似度阈值θ且相似度值最大的子句作为定位结果,记相似度值为simA。
5.2 虚拟相关事件集构建
虚拟相关事件集的构建包含两项内容,其一是初始虚拟相关事件集构建,其二是迭代扩展初始虚拟相关事件集,丰富虚拟相关事件线索集。下面分别对该两项内容予以介绍。

图4 事件关系识别方法的主体框架
·虚拟相关事件集构建
本文利用相关事件的核心词以及实体的分布一致性特点构造事件eA的事件线索集合VREA。VREA候选集的构建过程具体步骤如下:
1)令eA定位得到的事件描述子句为SubA,SubA与eA的内容一致或相似。SubA所在的整个句子为SA,其组成形式为[Sub1,Sub2,..,SubA,…,Subn],Subi皆为候选虚拟相关事件。
2)虚拟相关事件vreA与事件eA之间的相关程度用关联因子(correlation factor)γ表示,记作:值越大表示事件eA与vreA之间的关联性越大。γ值的计算方法如下。
关联因子γ由核心词关联因子γET、依存实体关联因子γDN和共现实体关联因子γCN组成,将三部分的得分进行加权,公式定义为式(1)。

其中,α、β、χ和δ为加权系数。
a.核心词关联因子γET:事件eA与虚拟相关事件vreA的核心词分别为ETA和ETvreA,同一个话题下,与ETA和ETvreA共现的实体集合分别记为NA和NvreA,计算NA和NvreA的重合度为γET,如式(2)所示。
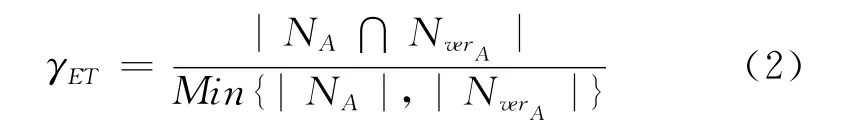
b.依存实体关联因子γDN:分别得到事件vreA与事件eA中的依存实体集合DNvreA和DNA,统计同一个话题下,与每一个依存实体共现的核心词,形成集合ETA和ETvreA,将两个事件中的依存实体两两计算核心词的重合度,得到γDN,如式(3)所示。

c.共现实体关联因子γCN:分别得到事件vreA与事件eA中的共现实体集合CNvreA和CNA,统计同一个话题下,与每一个依存实体共现的核心词(除去依存实体),形成集合ETA和ETvreA,将两个事件中的依存实体两两计算核心词的重合度,得到γDE,如式(4)所示。

根据事件相关因子的计算方法,得到VREA候选集中的每个虚拟事件vreAi和eA的关联因子γ,VREA集合中的每一个元素为每个虚拟事件vreAi和关联因子γ组成的二元组,表示为:VERA={(verA1,γ1),(verA2,γ2),…,(verAn,γn)}。
·迭代扩展虚拟相关事件集
由于句子长度有限,所以蕴含的事件信息较少,在虚拟相关事件集构造中将获得数量有限的候选关联事件。如判定目标事件“9/11袭击致大规模伤亡”和“美国举国哀悼”是否相关,在句子“9/11袭击导致大规模人员伤亡,世贸大楼瞬间倒塌,世界为之震惊。”中构建目标事件“9/11袭击致大规模伤亡”的事件线索集合,仅能获得虚拟相关事件“世贸大楼瞬间倒塌”和“世界为之震惊”。但是,获得的虚拟相关事件对目标事件的关系判定无任何帮助。存在于其它文本中的对目标事件关系判断有辅助作用的信息,如“美国民众为死难者哀悼”,需要通过对虚拟相关事件“世贸大楼倒塌”的进一步扩展中获得。鉴于此,本文在已构建的初始虚拟相关事件集合基础上,通过以下步骤进行迭代扩展。
1)继续将VREA中的每一个虚拟相关事件在文本中定位。在定位过程中,滤掉已定位过的句子,即保证包含当前虚拟事件的句子不会重复出现。
2)构造当前虚拟事件的虚拟相关事件集合,并计算与事件eA之间的关联因子,将扩展得到的虚拟相关事件以相关因子添加到eA的事件线索集合VREA中。
3)迭代上述两步,直到不满足迭代条件。通过迭代方法,最终将得到与目标事件相关的虚拟相关事件集合。
5.3 事件关系推理
事件关系推理部分通过聚类予以实现:同一聚类中的事件两两相关,否则两个事件不存在逻辑关系。事件关系推理以虚拟相关事件集为媒介,通过关联因子计算,度量“目标事件对”之间的关联强度,并以此进行事件集合的聚类划分。
本文采用APCluster聚类算法[10],将该算法原有的相似度转化为事件关联度。事件eA和事件eB的关联度计算公式如式(5)所示。
d(eA,eB)=max(sim(vreAi,eB)·γ(eA,vreAi)),vreAi∈VREA(5)其中,d(eA,eB)表示目标事件eA和eB的相关度;vreAi为事件eA的虚拟相关事件;sim(vreAi,eB)为vreAi和目标事件eB通过编辑距离得到的相似度值。该式的基本原理:在计算eA和eB相关度过程中,首先考虑和eB的相似度,如果vreAi与eB相似度很高,则可通过vreAi与eA的关联因子γ(eA,vreAi)代替eB与eA的相关度值。为了更好地避免相似度计算带来的误差,本文将相似度值作为惩罚因子引入。
6 实验分析
6.1 数据集
实验使用与马彬[7]相同的数据集,从新浪、腾讯等网站的新闻专题中收集6个话题,平均每个话题包含32个新闻事件(外延事件)的30篇新闻报道。通过三位志愿者对每个话题下的事件进行事件关系标注(“相关”或“不相关”),最终获得2 842个事件“关系对”,其中,具有逻辑关系(即“相关”)的“事件对”为811对,占总“事件对”的28.5%。
6.2 评价标准
事件关系识别任务中,系统的性能优劣主要取决于正确识别出关联关系的“事件对”个数(包括正确判定“相关事件对”和“不相关事件对”)。实验采用文本检索领域的通用评价指标:准确率(Precision)、召回率(Recall)和F值。系统的性能由对每个话题的P值、R值和F值通过宏平均计算所得。
6.3 实验结果及分析
为了测试和比较本文提出的事件关系识别模型的效果,选择基于依存线索系统[7]作为基准系统(Baseline)。首先在训练集上对式(1)中加权系数进行调整,使其获得最佳结果,随后将最佳取值应用到测试集中,加权系数的取值分别为:α=0.5、β=0.5、χ=0.7和δ=0.3。实验结果如表2所示。本文提出的方法相对于Baseline在F值上获得了7.68%的提高,在保证事件关系识别精确率P值的情况下,大大提升了事件关系识别召回率,即获得了15.34%的提高。

表2 系统实验结果
本文通过对现有的虚拟相关事件进行迭代,获得更丰富的相关事件集合,迭代次数的选择对系统的性能有一定的影响。图5显示了在测试集中,不同迭代次数下的系统性能,从图5中可以看出,迭代次数为5时,系统的性能最优。因此,在测试集合中,选择5作为最终的迭代次数。

图5 迭代次数的训练结果
为了进一步与Baseline进行对比,分别对识别为有关系的“事件对”集合和无关系的“事件对”集合进行分析,结果如表3所示。其中Baseline-Coincide为Baseline的识别正确,且本文方法也识别正确的比例;Our-Coincide为本文识别正确,而Baseline没有识别正确的比例。从表3看出,Baseline识别为有关系的“事件对”只有25.00%能被本文方法正确判断为有关系,而本文识别为有关系的“事件对”仅有5.80%能被Baseline识别正确。

表3 对比实验结果
分析实验结果发现,Baseline识别为有关系的而本文方法识别错误的“事件对”之间存在较强的依存关系,但是事件中的实体和核心词的出现频率较低(实体省略现象严重),例如句子“朝鲜藐视安理会决议,仍坚持发射卫星。”包含的事件“朝鲜仍坚持发射卫星”中实体“朝鲜”省略。此类事件通过本文方法构造的线索集合较为稀疏,很难有效辅助事件关系识别。本文方法识别为有关系而Baseline识别错误的事件,通过本文方法构建的线索较为充分,弥补了因子句依存分析性能不佳造成的影响,对出现较为频繁的事件的关系识别性能较优。然而,两种方法对于不相关事件的识别性能较为接近。因此,在相关联事件的识别工作中,今后可以将两种方法进行融合,以提升事件关系识别的性能。
图6分别给出本文系统和Baseline对每一个话题中“相关事件对”(左)和“不相关事件对”(右)的识别结果,其中,白色部分为本文系统的识别结果,灰色部分为Baseline的识别结果。从图6可看出,本文对“相关事件对”的识别相对于Baseline有很大的提高,这是由于在构建事件线索集时,Baseline有60.07%的事件不存在事件线索集,而本文方法有27.7%的事件没有获得事件线索集。因此,本文的方法能够构造更丰富的事件线索集,从而提高事件关系的识别效果;然而,本文方法对“不相关事件对”的识别提高不明显。

图6 “相关事件对”(左)和“不相关事件对”(右)识别性能
但是,相关联事件的识别性能依然不理想。其中,实体省略现象较为明显,对事件线索的构建有一定的影响。其次,语料资源有限对事件线索的迭代扩展也具有一定的限制。本文在事件线索构建过程中采用的是本地的新闻语料资源,规模具有一定的局限性,在以后的工作中可以通过搜索引擎,利用互联网信息进行线索集的构建。另外,本文对于事件核心词的选择仍需优化。分析实验结果中的核心词发现,系统识别的一些核心词语并不能真正的表述事件的发生。原因主要有两点:一是在虚拟相关事件构建过程中引入的子句含有较多的噪声,如子句“刘金哲说”、“发言人表示”、“朝鲜官方宣布”等,因此,抽取出的核心词(如“说”、“表示”和“宣布”)对事件间的“区分”贡献较小,这必将对构建事件线索集造成影响;二是事件核心词语的抽取性能还需提高,对比系统的核心词识别结果和人工标注的核心词集合,准确率为87.5%。因此,会在一定程度上影响系统的性能。
7 总结
本文针对同一话题下事件关系识别任务提出一种基于核心词和实体推理的事件关系识别方法。该方法通过利用事件的核心词以及事件实体在相关事件中分布的一致性,形成目标事件的虚拟相关事件集合,实现事件间关联性的识别。实验结果表明,该方法优于基于事件语义依存线索的事件关系识别方法。
然而,本文对事件线索集的构建还需改进,因为仍有部分事件无法通过本文的方法构建虚拟相关事件集合。同时,本文对事件核心词的挖掘方法也需要进一步优化,以避免在实验过程中引入噪声。本文采用的APCluster聚类算法仅仅利用事件分布一致性特征,并没有充分利用事件聚类过程中的层次结构信息,后续工作可尝试采用层次聚类算法,利用聚类过程中的层次强度特性辅助事件关系识别。另外,在事件关系识别基础上,进一步确定事件的关系类别,即事件关系类型的定义和判定。
[1] W J Li,W Xu,M L Wu,et al.Extractive summarization using inter-and intra-event relevance[C]//Proceedings of the 21st International Conference on Computational Linguistics and 44th Annual Meeting of the Association for Computational Linguistics,2006:369-376.
[2] T Chklovski,P Pantel.Global path-based refinement of noisy graphs applied to verb semantics[C]//Proceedings of the Joint Conference on Natural Language Processing,Jeju Island,Korea,2005:792-803.
[3] P Pantel,M Pennacchiotti.Espresso:leveraging generic patterns for automatically harvesting semantic relations[C]//Proceedings of the 21st International Conference on Computational Linguistics and 44th Annual Meeting of the ACL,Sydney,Australia,2006:113-120.
[4] Z S Harris.Mathematical Structure of Language[M].New York,1968.
[5] D Lin,P Pantel.Discovery of Inference Rules from Text[C]//Proceedings of the 7th ACM SIGKDD,San Francisco,California,USA,2001:323-328.
[6] I Szpektor,H Tanev,I Dagan,et al.Scaling Webbased Acquisition of Entailment Relations[C]//Proceedings of the Conference on Empirical Methods in Natural Language Processing,Barcelona,Spain,2004:41-48.
[7] 马彬,洪宇,杨雪蓉,姚建民,朱巧明.基于语义依存线索的事件关系识别方法研究[J].北京大学学报,2012,6:109-116.
[8] 洪宇,张宇,刘挺,李生.话题检测与跟踪的评测及研究综述.中文信息学报[J],2007,6:71-84.
[9] Y Hong,J F Zhang,B Ma,et al.Using Cross-Entity Inference to Improve Event Extraction[C]//Proceedings ACL 2011:1127-1136.
[10] B J Frey,D Duerk.Clustering by Passing Messages Between Data Points[J].Science.2007,315:972-976.
