一种基于遗传算法的语法网络搜索方法
2014-03-16安徽城市管理职业学院汪丹丹
安徽城市管理职业学院 汪丹丹
1.引言
语音识别技术是让机器通过识别和理解人类的语音信号,进而听懂人类的语言。近年来,由于计算机各项功能的日益强大,云计算技术的全面发展,语音信号处理技术也得到了长足的进步。目前语音识别技术已广泛应用于医疗、教育、安全、电信客服等领域,覆盖人类生活的方方面面。
但在实际应用中仍然会存在较多的问题,比如信道干扰、背景噪音干扰等,这些不确定因素都会对识别率造成很大的影响。另外,在各类嵌入式设备终端上,语音识别系统的运行环境相对比较差,在系统的效率和效果之间要做好平衡。基于以上问题,语音识别系统通常从三方面来评价,分别鲁棒性、识别率以及响应时间,本文重点关注语音识别系统的识别率和响应时间。本文选择基于隐马尔科夫模型(Hidden Markov Model,HMM)的语音识别技术[1]构建了基线系统。在该系统中,影响语音识别系统识别率和响应时间的模块比较多,但最主要的还是解码模块。该模块通常采用传统的Viterbi解码方法,但是在海量命令词识别时,如车载领域的兴趣点(Position of Interesting,POI)识别,搜索空间急剧增大,获取最优解的效率大大降低。针对这类复杂的问题,需要把主要精力放在寻求满意解上。
遗传算法(Genetic Algorithm,GA)借鉴了生物学中的染色体和基因的概念,通过模拟自然进化过程,求解满意解较为有效。它对一个参数编码群体进行操作,提供的参数信息量较大,优化效果也相对较好[2-4]。因此,本文将GA算法应用于基线系统的语法网络搜索模块,以此来提升该模块的全局优化搜索能力,进而改善系统的识别效果和响应时间。
2.基线系统的构建
2.1 系统结构
如图1所示,系统各部分按照与识别实例关系的不同分为两大类:实例无关事物和实例相关事物。实例无关事物指的是与识别实例无关的永久性资源:包括拼音到HMM索引表、汉字到HMM的索引表和HMM集合。实例相关的事物则指的是与特定识别实例相联系的行为或数据。它又可分为四个字模块:词典集合、搜索、转化和录音模块。
录音模块,负责和录音设备交互。负责从录音设备中获取声音数据。负责自动将含有静音和语音的数据切分出来,提供给转化使用。
转化模块,负责将波形数据转化为特征向量序列。
搜索模块,负责对特征向量序列在给定的语法网络中搜索。对每一帧搜索数据,能够更新搜索状态。搜索状态是一个记号集合,每个记号对应于搜索网络中的一个节点,同时还包括搜索数据到达此节点的最大概率和路径,以及内部HMM各状态的概率。
词典集合模块,负责管理词典。实际系统支持多个词典,形成一个词典可包含多个词典的词典集合。每个词典包含多个词,可以增加、删除词。可以将一个词典生成语法网络,提供给搜索使用。
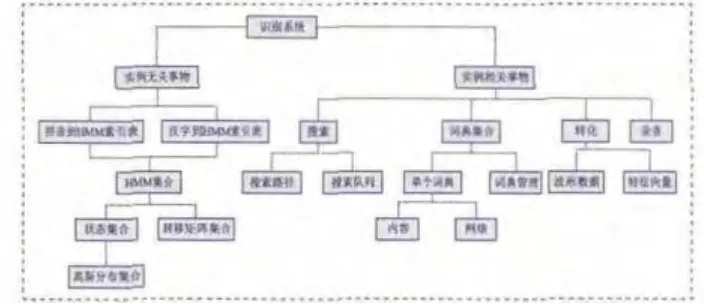
图1 基线系统框架结构
2.2 识别流程概述
系统有两种运行状态:脱机识别和联机识别。脱机识别和联机识别的区别在于语音数据的来源不同。脱机识别数据来自文件,而联机是别的数据来自麦克风。这两种状态的运行流程如图2所示。

图2 语音识别流程
3.语法网络搜索的遗传操作
在实际的搜索中,我们通常是将HMM根据语法的限制连接成一个语法网络,如图3就是一个简单的孤立词识别系统的语法网络,语法网络可以分为三层,如图4所示。
语法网络搜索过程又称为解码,逻辑上通常将解码分为两层,一层是HMM内部状态在时刻t的最大概率,另一层是以网络节点为单元,它们之间的关系为网络节点在时刻t的概率是本HMM内部各状态在时刻t的最大值。
传统的解码方法是Viterbi解码,但是在一些应用场合,比如车载领域的POI识别,其命令词集合非常大,往往有数十万条。此时,解码的搜索空间将急剧增大,而系统的效率、效果将急剧下降。所以,对这类复杂的问题,需要把主要精力放在寻求满意解上,而GA正是寻求这种满意解的最佳工具之一。
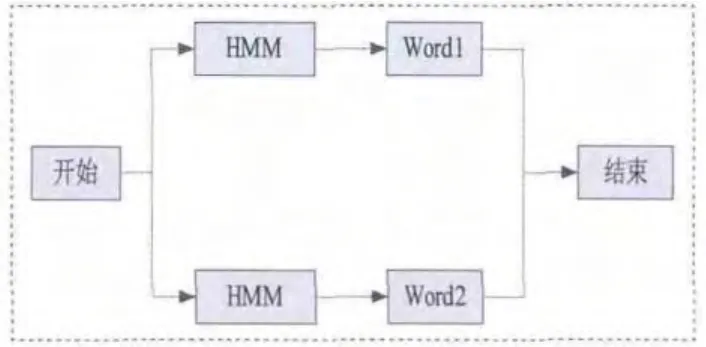
图3 孤立词识别系统的网络结构
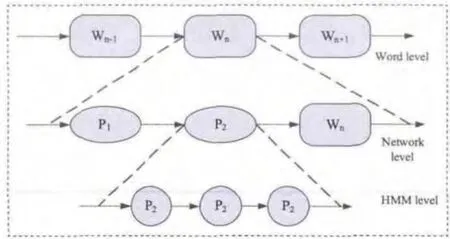
图4 语法网络的三层模型[5]
3.1 编码方案
将语法网络的HMM标号i(i,2,…,N)作为基因,构造有K个命令词的识别网络,每个命令词内存放一类标号,构成遗传操作的染色体。
3.2 创建初始种群
初始种群应具有一定的规模,以保持群体内个体的多样性。由于GA具有很强的鲁棒性,所以如何形成初始种群不影响优化结果,只影响优化时间。可以对一条染色体加以随机扰动产生一定N-1条剩余的染色体。
3.3 适应度函数
计算染色体对应的HMM状态的似然度估计值,以此作为适应度评价函数。似然值越大,适应度值也就越大。不过这显得有些简单,后续还可以将似然值进行分段处理,并增加辅助评价函数。
3.4 交叉运算
交叉运算是遗传算法中产生新个体的主要操作过程,它以某一概率相互交换某两个个体之间的部分染色体[6]。本文采用单点交叉的方法[7],首先对群体进行随机配对;其次随机设置交叉点位置;最后再相互交换配对染色体之间的部分基因。
3.5 突变运算
突变运算是对个体的某一个或某一些基因座上的基因值按某一较小的概率进行改变,它也是产生新个体的一种操作方法[6]。本文采用基本位突变的方法来进行突变运算[8],其具体操作过程是:首先确定出各个个体的基因变异位置,可以随机产生的变异点位置,然后依照某一概率将变异点的原有基因值取反即可。
3.6 系统参数动态控制
在群体演化进程中,系统参数的最佳设置足随演化进程不断变化的,如在演化开始时,群体的多样性较高,较高的交叉率及交叉操作子权重,较低的突变率及突变操作子权重有利于利用已有好基因块组成较好的染色体。随着演化进程的深入,群体的多样性越来越小,此时,较高的突变率和较高的突变操作子权重有利于群体引进新的基因,保持群体的多样性,即探索新的解空间。
为充分发挥各遗传操作子的搜索能力,已有多种系统参数动态设置方案提出。本文采用一种较简单的方法[5],突变率及突变操作了权重随进化进程指数递增,而交叉率及交叉操作子权重进化进程指数递减。
设pc(0),pm(0)为初始交叉率及突变率,Tc、Tm为预设的最小交叉率及最大突变率。在t时刻,交叉率及突变率为:

其中,演化时间t可以是群体更新次数,也可是固定演化时间间隔的记数。
4.总结
传统的解码方法是Viterbi解码,但是在海量命令词识别时,如车载领域的POI识别,搜索空间急剧增大,获取最优解的效率大大降低。所以,对这类复杂的问题,需要把主要精力放在寻求满意解上,本文应用GA方法进行语法网络搜索,求解满意解,提升了该方法的全局优化搜索能力。
在GA方法中,适应度评价函数的设计至关重要,本文以计算染色体对应的HMM状态的似然度估计值作为适应度函数,似然值越大,适应度越好。但这显得有些简单,后续研究还可以将似然值进行分段处理,并增加辅助评价函数。
另外,GA解码得到的搜索结果不唯一,但都是满意解,因此可以称之为“模糊搜索”,与“精确搜索”相对应,是语音识别领域的一种全新的应用理念。
[1]韩纪庆.语音信号处理[M].北京:清华大学出版社,2010.[2]Holland J.H.Adaptation in Natural and Artificial Systems[M].The University of Michigan Press.1975.
[3]宋小鹏,潘宏侠,宋叔飚.遗传神经网络在语音识别中的应用研究[J].机械工程与自动化,2006,6(3):25-26.
[4]刘占军,兆尔波.基于遗传算法提高计算机连续语音识别率的研究[J].沈阳航空航天大学学报,2005(1).
[5]贺前华,韦岗,金连文.基于遗传算法的HMM最小错识率训练方法[J].电路与系统学报,1999,4(4):46-50.
[6]玄光南.遗传算法与工程优化[M].北京:清华大学出版社,2012.
[7]林惠娟.基于遗传算法的测试用例自动生成技术研究[D].四川大学,2006.
[8]刘秋生,杨继昌.遗传优化阈值选取加速算法研究[J].江苏大学学报(自然科学版),2003(3).
