一种结合贪婪因子求解0-1背包问题的分布估计算法
2014-03-13谭阳周虹
谭 阳 周 虹
(湖南网络工程职业学院,湖南 长沙 410004)
一种结合贪婪因子求解0-1背包问题的分布估计算法
谭 阳 周 虹
(湖南网络工程职业学院,湖南 长沙 410004)
针对0-1背包问题,在分布估计算法的基础上提出了一种结合传统贪婪方法的新算法。通过计算物品的重量价值比后获得物品的贪婪因子值,并将贪婪因子融入基本的分布估计算法之中,在保证收敛速度的基础上进一步平衡了个体间的竞争,相较对比算法而言取得了更好的优化结果。
分布估计算法;贪婪因子;0-1背包问题;概率模型
1.引言
背包问题又称子集合问题,运筹学中一个典型的组合优化难题,有着广泛的应用背景,如仓库货物装载问题、选址问题等。不失一般性背包问题的描述通常如下:给定n个物品和1个背包,物品i的重量为wi,其价值为vi,i=1,2,…,n。且该背包的最大容量为 C,要从给定的n个物品中挑选若干个物品放入背包中,要满足挑选的物品总重量不超过 C,且总价值达到最大。背包问题的解采用向量X=(x1,x2,…,xn)T,xi∈{0,1}表示。其数学模型为:
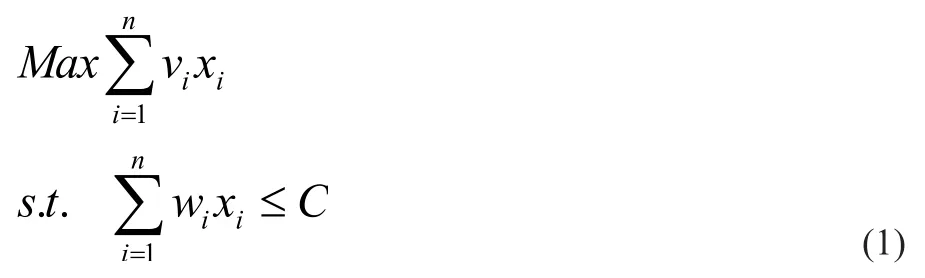
xi∈{0,1} i=1,2,…,n
背包问题属于NP难题,目前求解的方法有精确方法(如动态规划、递归法、回溯法、分支限界法等[1]),近似算法(如贪婪法[1],Lagrange法等)以及智能优化算法(如模拟退火算法[2]、遗传算法[2]、遗传退火进化算法[3]、蚁群算法[4-5])、粒子群优化算法[6]。精确方法虽然可以得到准确解,但时间复杂性与物品数目成指数关系。近似算法和智能优化算法虽然不一定得到准确解,但可得到比较有效解,并且时间复杂性比较低。
2.结合贪婪因子的分布估计算法
2.1 贪婪因子
贪婪算法通过一系列的选择得到问题的解,在每一次总是做出在当前状态下看来是最好的选择,也就是希望通过局部的最优来达到一个全局的最优。这种启发式的策略并不总能获得最优解,然而在许多情况下确能达到预期的目的。通常对于0-1背包问题采用价值密度贪婪准则:每次都选取vi/wi值最大的物品放入背包之中,这种选择准则通常需要对所有物品进行一次扫描,并按照物品的vi/wi值的大小进行一次降序排列。因此本文在对0-1背包问题的处理上采用将物品的vi/wi值作为该物品的加权因子,以作为在分布估计算法中该物品被选择的参考因素。
2.2 分布估计算法
分布估计算法(EDA)是一种新兴的基于统计学原理的随机优化算法最初由Baluja[7]在1994年提出,分布估计算法是一种全新的进化方法。分布估计算法首先构造描述解空间的概率模型,通过对种群的评估,从中选择优秀的个体集合,然后采用统计学习等方法根据优秀的个体构造概率模型;然后由这个概率模型随机采样产生新的种群,如此反复迭代,实现种群的进化,直到满足终止条件。标准的EDA的算法流程如下:
Step 1:初始化群体,并对每一个个体计算适应值;
Step 2:依据适应值,从群体中选择优秀的个体;
Step 3:根据所选择的个体的分布,构建概率模型;
Step 4:根据概率模型进行随机采样,生成下一代群体,并对新个体计算适应值;
Step 5:判断是否符合终止条件,符合则算法结束并输出结果;否则转Step2。
本文采用二进制表达,分布估计算法中的种群个体,每个个体采用长度为n的0-1字符串表达对物品的选取情况,X=x1,x2,…,xn,xi=0,1,i=1,2,…,n当xi=0时则表示第i个物品没有被选择。
2.3 算法的概率模型及更新机制
通过建立一个包含n个分量的概率向量p(x)=[p(x1),p(x2),…,p(xn)]来表示在解空间中分布的概率模型,其中p(xi)为物品i被选取的概率。通常在算法开始时会将初始概率p(x)设置为[0.5,0.5,…,0.5]的均匀分布状态,随着算法迭代进化,新个体的产生则基于概率向量p(x)的分布情况来产生。即个体中对于物品i的选取是通过一个0~1间的随机数r来决定的,若有r<p(xi)则选取该物品,记为xi=1;否则不选取该物品,记为xi=0。如此反复,直至产生全部M个个体。通过计算所有个体的目标值,通过排序并选择其中价值最高的前N个个体N<M,以机器学习中的PBIL法则[7]来更新概率向量p (x)。
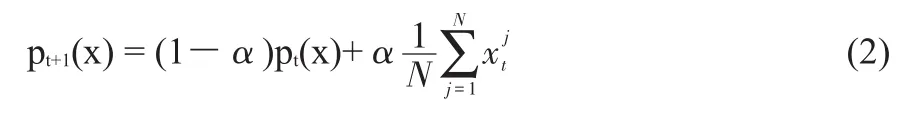
其中t为算法当前进化的代数,pt(x)为第t代时的概率向量,α,(0<α<1)为机器学习的速率为第t代时被选择的第j个个体。
计算机出物品i的贪婪价值vi/wi,并对所有物品的贪婪
2.4 修复非可行解
在解决背包问题中EDA是根据当前的概率模型来产生新个体,但是新个体未必是可行解,为了能保证所有产生的新个体都是可行解,就必需对所有新个体扫描并对非可行解进行修复。本文采用贪婪价值修复法,修复流程如下:
Step 1:判断个体是否为可行解,若可行则转Step 3,否则继续下一步;
Step 2:找到该个体向量中贪婪价值vi/wi最小的,且数值为“1”的位;并将其置为“0”后转Step 1;
Step 3:判断是否满足退出条件,满足则退出,否则继续判断下一个个体。
2.5 结合贪婪因子的分布估计算法(GEDA)
结合以上设计,在引入贪婪因子后,在算法将初始概率p(x)以物品的贪婪因子值来进行设置[β1,β2,…,βn],同时还需对PBIL概率向量更新法则进行一些调整,其主要目的是降低机器学习的速率,平衡个体间的竞争压力,调整后的PBIL法则如下:

由式(3)可知,在引入(1-β)后权重因子后,可以有效减小由超级个体带来的极值效应,其βi贪婪因子值越高反而在向量概率更新的权重越小,从而有效降低了早熟收敛的发生。
通过改进后,结合贪婪因子的分布估计算法的流程如下:
Step 2:以p(x)进行随机采样生成M个个体,并转Step 4;
Step 3:以p(x)进行随机采样,并生成M-N个个体;
Step 4:检测所有新生成个体,并以“贪婪价值修复法”对非可行个体进行修复;
Step 5:计算新个体的适应值,并依据适应值的大小进行降序排序,同时划分出的前N个最优个体;
Step 6:依据最优的N个个体的分布情况,以式(3)来更新向量概率p(x);
Step 7:判断是否符合终止条件,符合则算法结束并输出结果;否则转Step 3。
由此可见,在分布估计算法中引入贪婪因子可以更好地在算法初期体现“性价比”较高个体,在此基础上通过设立保留机制使得在算法迭代过程中产生的优秀个体得以传承,从而保证算法可以进行有效的搜索。同时为了防止贪婪因子引发极值效应,在机器学习的环节中通过加入贪婪因子来平衡个体间的竞争关系,进而获得更好的搜索性能。
3.仿真测试
3.1 搜索能力的仿真对比测试
本文选取文献[8]中物品数目为50的实例背包问题(最优解为:3103)来验证GEDA算法的有效性。其中GEDA和EDA的参数均为:学习速率α=0.1,种群规模M=100,N=20。文献[9]中提出以微粒群算法(PSO)来求解0-1背包问题,其中PSO列的数据直接取自于文献[9]。每种算法均独立运行50次。
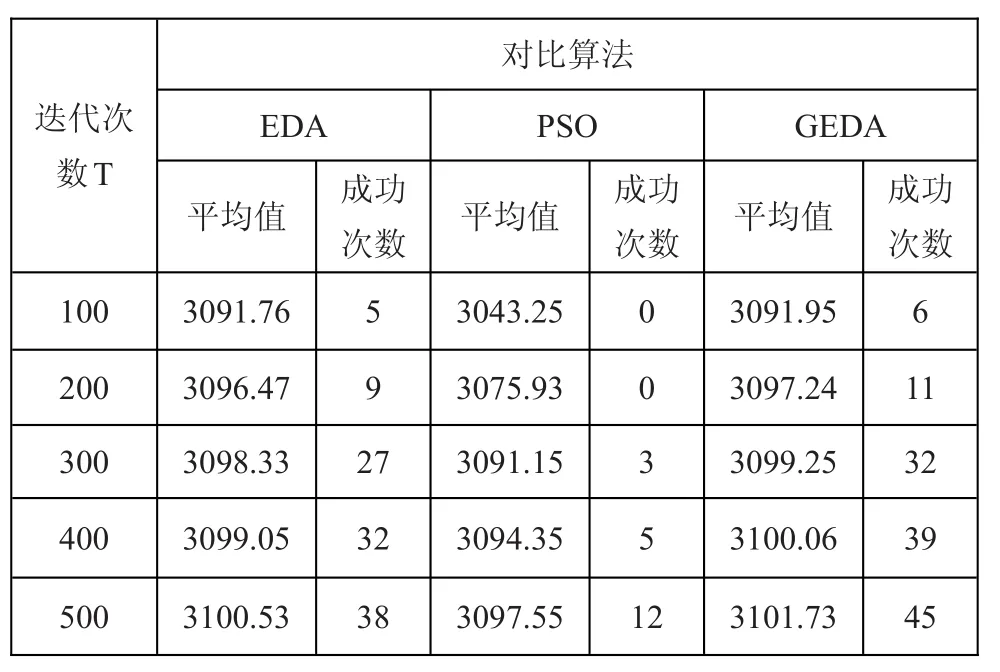
表1 几种对比算法的优化统计结果
由表1可知GEDA在平均值和成功次数上均优于对比算法,具备较好的寻优能力。同时通过对GEDA算法的分析可知,只是在EDA的基础上增加了对所有物品的贪婪因子计算量O(n),以及在PBIL法则中的因子系数相乘的计算机量O(n),相较EDA而言其算法的时间复杂度只是线性的增加开销不大,基本可以等同于EDA。
3.2 搜索效率的仿真对比测试
本文选取文献[10]中物品数目为100的实例(最优解为:4142)来做对比测试。三种对比算法分别独立运行10次取平均值,最大迭代次数为500代,其它参数保持不变。
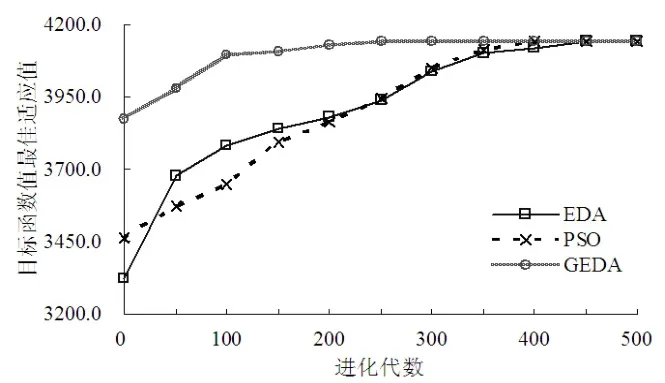
图1 三种对比算法对实例优化的情况
通过图1可以看出,相对于使用随机初始化种群的EDA和PSO而言,使用贪婪因子值初始化种群的GEDA在一开始就具备较好的种群优势。在后续的搜索过程中GEDA的收敛效率也明显优于其它对比算法,可以看出GEDA在第250代左右时就已经非常接近最优解,与此相对EDA和PSO分别是在第450代和第400代时才接近最优解。
因此,GEDA是一种有效解决0-1背包问题的方法,相较对比算法而言GEDA在搜索能力和搜索效率方面具备更好的性能。
4.结语
在解决0-1背包的问题上,本文通过结合传统贪婪算法提取物品的贪婪价值,并以此生成物品的贪婪因子值。通过在EDA算法中使用贪婪因子,使得算法在寻优性能上得到了提升,同时还较好地限制了计算开销的增长。后续的仿真实验也证明GEDA是一种有效解决0-1背包的方法。
[1]王晓东.计算机算法设计与分析[M].北京:电子工业出版社,2001:92-168.
[2]王凌.智能优化算法及其应用[M].北京:清华大学出版社,2001:17-59.
[3]金慧敏,马良.遗传退火进化算法在背包问题中的应用[J].上海理工大学学报,2004,26(6):561-564.
[4]马良,王龙德.背包问题的蚂蚁优化算法[J].计算机应用,2001,21(8):4-5.
[5]于永新,张新荣.基于蚁群系统的多选择背包问题优化算法[J].计算机工程,2003,29(20):75-76,84.
[6]高尚,杨静宇.背包问题的混合粒子群优化算法[J].中国工程科学,2006,8(11):94-98.
[7]Baluja S.Population—Based Incremental Learning:A method for Integrating Genetic Search Based Function Optimization and Competitive Learning[R]. C MU- CS-94-163.Available via Anonymous ftp at reports,Adm. CS.cmu.Edu,,1994Technical Report, Carnegie Mellon University.
[8]李娟,方平,周明.一种求解背包问题的混合遗传算法[J].南昌航空工业学院学报,1998,12(3):31-35.
[9]沈显君,王伟武,郑波尽等.基于改进的微粒群优化算法的0-1背包问题求解[J].计算机工程,2006,32(18):23-38.
[10]ZHUANG Zhong-wen,QIAN Shu-qu.Immune algorithm with antibody-repaired and its application for high-dimensional 0/1 knapsack problem[J].Application Research of Computers,2009,26(8):2921-2923.
An Estimation of DistributionAlgorithm Solving the 0-1 Knapsack Problem with Greed Factors
Tan Yang Zhou Hong
(Hunan Network Engineering Vocational College, Changsha 410004,Hunan)
Aiming at the 0-1 knapsack problem,this paper proposes a new algorithm combined with traditional greedy approach based on estimation of distribution algorithm.It obtains the greedy factor values of the goods by calculating the weight-to-value ratio.It also integrates the greedy factor into the basic estimation of distribution algorithm.While ensuring the rate of convergence,it keeps the competition between individuals in balance,making better optimization results compared with the comparison algorithm.
estimation of distribution algorithm(EDA);greed factor;0-1 knapsack problem;probabilistic model
谭阳,男,湖南望城人,硕士,副教授,研究方向:智能计算,信息安全,数据挖掘。
本文受湖南省教育厅重点项目资助,项目编号:10A074。
