基于聚类分析的短期负荷智能预测方法研究*
2014-03-05陈宏义李存斌施立刚
陈宏义,李存斌,施立刚†
(1.华北电力大学 经济与管理学院,北京 102206;2.中国能源建设集团有限公司,北京 100029)
基于聚类分析的短期负荷智能预测方法研究*
陈宏义1,2,李存斌1,施立刚1†
(1.华北电力大学 经济与管理学院,北京 102206;2.中国能源建设集团有限公司,北京 100029)
短期电力负荷预测作为电网企业的基本工作,其精度的提高对于电网企业运营管理和调度管理具有较大的意义,然而由于电力负荷受到诸多非线性因素的影响,因此得到高精度的电力负荷预测结果是比较困难的.本文首先利用数据挖掘中的k-means聚类技术对训练集的气象数据进行聚类分析,分析提取相似日,在提取相似日的相关历史数据后,建立支持向量机模型进行短期电力负荷预测.经算例结果证明,由该方法得出的预测结果平均相对误差为0.88%,和同结构支持向量机预测的平均相对误差(1.66%)以及ARMA预测的平均相对误差(3.81%)相比,预测精度得到明显的提高,证明了该方法的有效性.
数据挖掘;负荷预测;聚类;支持向量机;k-means
随着电力工业市场化的进展,短期电力负荷预测精度的提高对电网企业的电力调度安排,电网调度自动控制,电网企业的营销行为具有十分重要的意义[1].20世纪80年代,国外学者Bunn和Farmer在研究负荷预测精度对电网企业的经济效益影响时就已经指出,负荷误差每增加1%将会增加10 000 000英镑的电力经营成本[2],因此,负荷预测精度的提高对电网企业而言将会产生较大的社会经济效益.
很多研究负荷预测的学者已经对电力负荷预测的建模问题开展深入研究,其方法包括回归拟合预测模型、灰色预测方法、时间序列分析以及几种方法组合在一起的组合预测方法等.近二十年来,随着人工智能领域的发展,越来越多的研究人员将神经网络为代表的人工智能预测方法应用到负荷预测中,取得了一定的成果.其中人工神经网络由于具有无需先验经验便可以按照任意精度进行非线性拟合的优点,受到了众多学者的青睐,成为近些年来主要的研究方法之一.国内外学者对应用神经网络进行电力负荷预测的文献进行了综述,并指出,和非智能的预测方法相比,神经网络得到的负荷预测结果精度更高[3-6].但是也有学者指出利用神经网络进行预测的缺点是可能收敛于局部最优解,并且在训练时需要大量的样本[7].
支持向量机预测方法的出现极大地改善了神经网络的上述缺陷,具有要求确定的参数少、在理论上有全局最优唯一解的特点,在小样本的条件下被认为是可以替代神经网络的智能预测方法[8].很多学者针对支持向量机在不同领域内的运用展开研究,均取得了不俗的效果,证明了支持向量机的实用性[9-11].但是由于短期的负荷预测受到大量复杂影响因素的多重非线性干扰,如气象、电力的实时需求、经济影响、电力系统的影响、电力市场各参与方、政治活动等.因此,无论模型如何先进,如果不尽可能地考虑这些因素的影响,很难进一步提高负荷预测的精度.
近几年,很多学者意识到利用数据挖掘技术首先对数据进行处理,再利用模式识别技术提取出相应的负荷预测影响相关的知识,能够进一步提高预测的精度.在提取出的相关知识里,尤其是气象相关的知识,如分类[12]、寻找相似日特征[13]等对提高负荷预测的精度作用最大.这表明将数据挖掘技术引入到电力负荷预测中不但是可行的,而且可以提高预测的精度.受此思路启发,本文首先利用待预测日的气象因素,采用数据挖掘中的k-means聚类算法进行聚类,得到相似日的结果,然后提取相似日的相关历史负荷数据,并利用支持向量机模型对负荷进行预测.由于该预测方法在建模前,首先通过聚类方法找出和待预测日相似的负荷数据样本进行短期负荷预测,因此和传统预测方法利用近期样本进行预测相比,能够有效地进一步提高负荷预测的精度.
1 利用k-means聚类方法选取相似日数据
聚类分析是对样本或指标按照各自的特性进行

其中E是所有样本的平方误差的总和;p是聚类空间中的样本点;mi是簇Ci的平均值.
由于短期电力负荷预测受到较多因素的影响,因此能否针对待预测日,利用和待预测日相近日的数据进行预测是进一步提高短期电力负荷预测精度的一个关键步骤.这是因为利用数据挖掘在预测前先选取相似日可以将具有高度相似特征的类似负荷点寻找出来,尤其在利用智能算法对负荷进行预测时,可以避免由于具有不同特征的预测点对智能预测方法训练时产生的收敛慢的问题.利用k-means聚类方法提取相似日电力负荷数据,结合智能预测模型进行预测的流程如下:
1)针对待预测日/时点,收集相关预测影响因素的数据,如天气,日期类型等,组成一条数据记录;
2)对上述数据记录,针对历史负荷数据中的数据,设定聚类个数k,利用k-means算法进行聚类寻找;
3)根据聚类结果,记录日期标识,按照预测的“近大远小”原则,选择距离待预测日最近日期的相分类的一种多元统计分析方法,一般基于距离的标准对样本数据分成不同的类或者簇.和分类相比,聚类不需要先验知识,即,可以在无监督、无指导的条件下进行机器学习.聚类目前应用于很多领域中,包括数学、计算机科学、统计学、生物学和经济学等.聚类算法主要以统计方法、机器学习、智能计算等方法为基础,其中较著名的聚类方法是k-means划分算法,也是最具有代表性的聚类方法之一.该算法只需要一个参数,即聚类个数k,然后将样本n分为k个簇,分类原则是具有较高相似度的尽量划分为一个簇,而不同簇之间的相似度则尽可能的小.k-means算法过程如下[14]:
1)从n个样本中任选k个对象作为簇中心;
2)计算中心外样本和中心之间的相似度(一般采用距离函数);
3)按照相似度进行分配,具有较高相似度的样本聚类为一簇;
4)计算聚类后所得簇的新的簇中心,并不断重复,直到标准测度函数开始收敛为止.
k-means聚类的标准测度函数一般采用如式(1)所示的均方差予以计算:关历史负荷数据,确定出待预测日的输入因素,建立智能预测模型进行预测.
2 支持向量机预测模型
本文的智能预测模型选取的是支持向量机(support vector machine,SVM),该模型是 Vapnik于20世纪90年代中期提出的一种新的智能学习方法,起先用于非线性的模式识别问题,随着应用领域的不断扩展和对支持向量机研究的深入,支持向量机逐渐应用于非线性的拟合中,表现出了良好的性能,并且由于支持向量机利用结构风险最小化代替了神经网络的经验风险最小化对网络结构进行训练,因此具有较好的泛化能力,在理论上能够搜索到全局最优解,能够克服神经网络易陷入局部最小值的缺点.由于支持向量机在小样本的条件下学习速度快,因此可以认为支持向量机方法是可以在小样本条件下取代神经网络方法的较好的选择.
支持向量机进行非线性拟合预测方法的原理如下[1].
假设有训练样本集 G = {(xi,di)},i=1,…,N,xi∈Rn,di∈R1.支持向量机回归的基本原理是通过映射将数据映射到一个高维特征空间中,并在该空间中寻找一个输入空间到输出空间的非线性映射 ψ(x),其回归函数如下:

其函数逼近问题等价于如下函数最小:

通过引入两个松弛变量ζ,ζ*,上述函数可以变成如下形式:

利用拉格朗日型和Karush-Kuhn-Tucker条件,解其对偶问题,可以得到支持向量机回归函数:

3 实证分析
本文以我国南方电网某地市级电力局的日整点负荷数据为例进行实证分析.利用聚类分析的因素数据有日期类型数据、气象数据(包括气压相关数据、气温相关数据、湿度相关数据、降水量、人体舒适程度等)共12项属性相关数据,共组织形成54条记录形式,将最后1条数据作为测试记录使用.其具体数值如表1所示.
接下来对这些记录进行预处理,对于标识型的数据,利用数值予以替代.以星期为例,分别用0,1,…,6代替星期日,星期一,…,星期六,对于原本是数据类型的属性值,利用等距离方法将其离散化,从而得到初始分析记录集.
对于支持向量机模型的训练,按照相关文献,将输入层节点选取L(t-24i),L(t-j),其中i=1,2,3;j=1,2,即,使用待预测时点的前三个时点和同一聚类中的日期待预测时间最近两天的同一时点的数据作为输入变量.此外,为方便对比分析,选取同结构的支持向量机,即,使用待预测时点的前三个时点和前两天的同一时点数据作为输入变量,同时,利用自回归滑动平均模型ARMA(1,1)对上述数据分别进行预测.实验计算环境选择matlab2011a,libsvm2.8.8软件包,误差对比分析采用平均相对误差eMAPE,计算结果如表2所示.
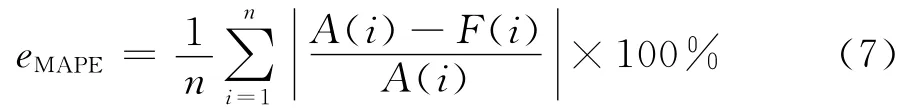
从图1和表2中可以明显发现,本文提出的方法具有较高的精度值,并且在大多数预测点上均表现良好,平均误差值达到了0.88%,而同结构未进行聚类寻找相似数据的支持向量机预测的平均误差为1.66%,根据 ARMA(1,1)得到的预测平均误差为3.81%.从误差对比中可以直观地看出,本文的方法具有更高的拟合精度.

表1 处理后的待聚类数据集Tab.1 Cluster’s data set to be processed

图1 3种方法预测结果曲线图Fig.1 The forecasting result with three models

表2 不同方法得出的预测结果Tab.2 Forecasting result from different methods
4 结 论
1)通过实例分析证明,支持向量机的预测结果高于传统的时间序列分析方法,说明智能预测方法较传统的预测方法结果更优.
2)本文将数据挖掘的k-means和支持向量机预测方法相结合,利用聚类技术提取历史数据集中的相似数据后,再利用支持向量机进行预测,能够更进一步提高预测精度.
[1] 王建军.智能挖掘电力负荷预测研究及应用[M].北京:中国水利水电出版社,2013.
WANG Jian-jun.Collaborative intelligence and knowledge mining technology for load forecasting method and application[M].Beijing:China Water & Power Press,2013.(In Chinese)
[2] BUNN D W,FARMER E D.Comparative models for electrical load forecast[M].New York:John Wiley,1985.
[3] 胡晖,杨华,胡斌.人工神经网络在电力系统短期负荷预测中的应用[J].湖南大学学报:自然科学版,2004,31(5):51-53.
HU Hui,YANG Hua,HU Bin.Application of artificial ANN to short-term load forecasting in power system[J].Journal of Hunan University:Natural Sciences,2004,31(5):51-53.(In Chinese)
[4] 曾鸣,刘宝华,徐志勇,等.基于混沌模糊神经网络方法的短期负荷预测[J].湖南大学学报:自然科学版,2008,35(1):58-61.
ZENG Ming,LIU Bao-hua,XU Zhi-yong,et al.Short-term load forecasting based on artificial neural network and fuzzy theory[J].Journal of Hunan University:Natural Sciences,2008,35(1):58-61.(In Chinese)
[5] 彭显刚,胡松峰,吕大勇.基于RBF神经网络的短期负荷预测方法综述[J].电力系统保护与控制,2011,39(17):144-148.`
PENG Xian-gang,HU Song-feng,LV Da-yong.Methods of short-term load forecasting based on RBF neural network[J].Power System Protection and Control,2011,39(17):144-148.(In Chinese)
[6] HENRIQUE Steinherz Hippert,CARLOS Eduardo Pedreira,REINALDO Castro Souza.Neural networks for short-term load forecasting:a review and evaluation[J].IEEE Transactions on Power Systems,2001,16(1):44-55.
[7] ENGIN Avci.Selecting of the optimal feature subset and kernel parameters in digital modulation classification by using hybrid genetic algorithm-support vector machines:HGASVM[J].Expert Systems with Applications,2009,36(2):1391-1402.
[8] 李元诚,方廷健,于尔铿.短期负荷预测的支持向量机方法研究[J].中国电机工程学报,2003,23(6):55-59.
LI Yuan-cheng,FANG Ting-jian,YU Er-keng.Study of support vector machine for short-time load forecasting[J].Proceedings of the CSEE,2003,23(6):55-59.(In Chinese)
[9] 袁小芳,王耀南,孙炜,等.一种用于RBF神经网络的支持向量机与BP的混合学习算法[J].湖南大学学报:自然科学版,2005,32(3):88-92.
YUAN Xiao-fang,WANG Yao-nan,SUN Wei,et al.A hybrid learning algorithm for RBF neural networks based on support vector machines and BP algorithms[J].Journal of Hunan University:Natural Sciences,2005,32(3):88-92.(In Chinese)
[10]耿艳,韩学山,韩力.基于最小二乘支持向量机的短期负荷预测[J].电网技术,2008,32(18):72-76.
GENG Yan,HAN Xue-shan,HAN Li.Short-term load forecasting based on least squares support vector machines[J].Power System Technology,2008,32(18):72-76.(In Chinese)
[11]张莹,王耀南,文益民.啤酒瓶检测中多分类支持向量机算法的选择[J].湖南大学学报:自然科学版,2009,36(5):37-41.
ZHANG Ying,WANG Yao-nan ,WEN Yi-min.Choice of multi-class support vectormachines on beer bottle detection[J].Journal of Hunan University:Natural Sciences,2009,36(5):37-41.(In Chinese)
[12]牛东晓,谷志红,邢棉,等.基于数据挖掘的SVM短期负荷预测方法研究[J].中国电机工程学报,2006,26(18):6-12.
NIU Dong-xiao,GU Zhi-hong,XING Mian,et al.Study on forecasting approach to short-term load of SVM based on data mining[J].Proceedings of the CSEE,2006,26(18):6-12.(In Chinese).
[13]栗然,刘宇,黎静华,等.基于改进决策树算法的日特征负荷预测研究[J].中国电机工程学报,2005,25(23):36-41.
LI Ran,LIU Yu,LI Jing-hua,et al.Study on the daily characteristic load forecasting based on the optimizied algorithm of decision tree[J].Proceedings of the CSEE,2005,25(23):36-41.(In Chinese)
[14]KRISTA Rizman Zalik.An efficient k-means clustering algorithm[J].Pattern Recognition Letters,2008,29(9):1385-1390.
A New Forecasting Approach for Short-term Load Intelligence Based on Cluster Method
CHEN Hong-yi1,2,LI Cun-bin1,SHI Li-gang1†
(1.School of Economics and Management,North China Electric Power Univ,Beijing 102206,China;2.China Energy Engineering Group Co Ltd,Beijing 100029,China)
Load forecasting is one of the basic issues of the electric power industry.However,because load has a certain social attributes,the improvement of the accuracy of load forecasting result is a difficult issue.This paper first used k-means cluster method to find similar data from historical date and weather data,and then used support vector machine(SVM)for forecasting.Seen from the result,the proposed method's MAPE is 0.88%,but BP-ANN and ARMA are 1.66%and 3.81%respectively.It is proved that this method has a high accuracy.
data mining;load forecasting;clustering;support vector machine(SVM);k-means
TM715
A
1674-2974(2014)05-0094-05
2013-12-22
国家自然科学基金资助项目(71271084);国家电网公司2014年总部科技项目6-5
陈宏义(1966-),男,湖南汉寿人,中国能源建设集团有限公司高级政工师,华北电力大学博士研究生
†通讯联系人,E-mail:shlg87@163.com
