基于话题检测的自适应增量K-means算法
2014-02-28李胜东吕学强施水才
李胜东,吕学强,施水才,孙 军
(1. 廊坊燕京职业技术学院 计算机工程系,河北 廊坊 065200;2. 北京信息科技大学 网络文化与数字传播北京市重点实验室,北京 100101;3. 北华航天工业学院,河北 廊坊 065000)
1 引言
互联网的出现,使信息急剧膨胀。这些信息包含有用的信息、无用的信息、感兴趣的信息、不感兴趣的信息等。在这种情况下,人们最关注的是如何快速而又准确地得到感兴趣的信息。目前,各种信息检索、信息抽取和信息过滤技术也都围绕这个目的展开[1]。但是,这些技术返回的信息冗余度过高,例如,仅仅因为信息中含有指定的关键词,许多不相关的信息就被作为结果返回了,其中,即使是相关的信息,也没有进行有效地组织。在这种背景下,研究者开始关注一种新的技术,它就是话题检测技术[2]。该技术就是研究如何检测新发生的事件,并帮助人们把分散的信息有效地组织起来。
在话题检测与跟踪研究中,话题检测[3~4]被定义为将输入的新闻报道归入不同的话题簇,并且在需要的时候建立新的话题簇。从定义可以看出,话题检测研究在本质上等价于一种无监督的聚类研究,即它的关键技术就是文本聚类算法。文本聚类算法[5]一般可以分为基于层次的聚类算法、基于平面划分的聚类算法、基于密度的聚类算法等,其中,最常用的是基于层次的聚类算法和基于平面划分的聚类算法。基于层次的聚类算法[6]可以达到很高的精确度,但是时间复杂度较高;以K-means算法为代表的基于划分的聚类算法,具有很高的效率,适合处理海量文本数据。
2 话题检测任务的特点
话题检测任务[4]的关键技术是文本聚类算法,这决定了它除了具有文本聚类的相似性,还有一些自己的特点。传统的文本聚类算法从全局的角度处理静态的对象,而话题检测任务从局部的角度以增量的方式处理动态的对象。这是话题检测任务的特点,也是话题检测与文本聚类算法的本质区别。
3 聚类算法
3.1 传统的增量聚类算法
传统的增量聚类算法处理话题检测问题时,其基本思想[7]是一次处理一篇报道。对于每一篇报道,先与每个已知话题进行比较,如果相似度大于阈值,则把该报道归入相似度最高的话题,如果对所有话题的相似度都低于阈值,则创建一个新话题,并更新话题数。
这种算法非常简单且易于实现,但缺点也很明显: 一篇报道只能做一次决策,早期根据很少信息作出的错误判断,累计到最后的错误量可能很大。针对这个缺点,本文对比了国内外常用的聚类算法,分析了传统的K-means算法,发现传统的K-means算法和增量聚类算法具有优缺点互补的可能性,能够弥补传统的增量聚类算法的缺陷。
3.2 传统的K-means算法
K-means聚类[8]的算法思想简单,易于实现,能够快速有效地处理大规模数据,已经成为数据挖掘等领域应用最广泛的聚类算法之一。它的核心思想[9]是通过迭代过程把数据划分到不同的聚类中,以使目标函数(1)最小化。
(1)
在公式(1)中,Ci是语料中的第i类话题;x是话题Ci中的数据对象;xi是话题中Ci的均值;K为初始化的聚类数,也是算法认定的话题数。
定义1根据两层阈值的话题/报道表示模型[10],报道i和报道j之间的余弦相似度函数Sim(di,dj)的定义为[11]式(2)。
(2)
在公式(2)中,di表示报道i的特征向量;dj表示报道j中的特征向量;参数M是基于两层阈值的话题/报道表示模型的特征空间维数。
定义2报道向量间的余弦距离Dis(di,dj)被定义为式(3)。
Dis(di,dj)=1-Sim(di,dj)
(3)
从定义1和定义2可知,报道i与报道j之间的余弦相似度越大,它们越相似,因此,这两个报道之间的余弦距离越小,传统的K-means算法越有可能把它们作为同一个话题。
传统的K-means算法通过迭代过程能够得到全局最优解,但初始化K值影响它的性能。
4 自适应的增量K-means算法
传统的K-means聚类算法可以通过迭代过程得到全局最优解,但初始化聚类数K制约着该算法的性能;而传统的增量聚类算法对一篇报道只做一次决策,能够得到局部最优解,很难得到全局最优解,但该算法不需要初始化聚类数K。
通过分析传统增量聚类算法和K-means聚类算法的优缺点,发现它们的优缺点有互补的可能性;在此基础上,用传统的增量聚类得到初始聚类中心,产生自适应的K值,解决K-means算法对K值初始化敏感的问题;然后用传统K-means算法的迭代过程得到全局最优解,解决传统增量聚类中的局部最优问题,提出了自适应的增量K-means算法作为话题检测算法。
自适应的增量K-means算法把所有中文新闻报道语料划分为r个增量,每个增量报道的规模为Ni(i=1,2,…,r)。对于每一个增量,先按传统增量聚类处理所有报道,得到K个聚类,接着对当前增量按照传统K-means算法进行迭代操作,每一次迭代都按要求进行适当的改变,直到聚类中心不变为止,然后处理下一个增量的报道。详细算法过程如下:
• Step1 对于每一个增量,设它的报道规模为Ni(i=1,2,…,r),判定报道S是否是第一篇报道,如果是,使用报道S建立第一个话题,如果不是,计算报道S与其他话题中心的相似度;
• Step2 根据S与各个话题的相似度,找到与S相似度最高的话题T1;
• Step3 判定报道S与话题T1的相似度是否大于阈值θ。如果相似度大于阈值θ,就把报道S归入话题T1,否则,使用S建立一个新话题,并更新话题数K;
• Step4 判定报道规模Ni是否为0。如果Ni为0,则输出话题数K和聚类结果,并转到Step5;否则,转到Step1,处理下一篇报道;
• Step5 根据传统增量聚类的结果,计算K个话题的均值,作为传统K-means算法的初始聚类中心;
• Step6 根据式(2)和式(3),计算每个聚类中心与其余所有新闻报道之间的余弦距离。根据余弦距离的大小,把每个报道分配到余弦距离最小的聚类中心,也就是把每个报道分配到最近的聚类中心;
• Step7 重新计算每个聚类的均值,作为该话题类的新聚类中心;
• Step8 如果所有的聚类中心不发生变化,这说明目标函数收敛到最小值,转向Step9;否则,修改聚类中心,按照Step6和Step7迭代;
• Step9 判断增量数i是否为0。如果i为0,算法终止,并输出话题数K和聚类结果;否则,转到Step1,处理下一个增量的报道。
5 实验结果与分析
根据传统增量聚类算法、传统K-means算法和基于话题检测的自适应的增量K-means算法的算法思想,分别把它们作为话题检测算法设计话题检测实验,得到相应的话题检测与跟踪评测结果,对比评测结果评估基于话题检测的自适应的增量K-means算法作为话题检测关键技术的性能。
5.1 实验结果
在实验中,分词程序是中科院计算所软件室提供的ICTCLAS[12];语料是中科院计算所谭松波博士提供14 150篇中文新闻报道[13-14],第一层是12个主题,第二层是60个话题。对每个话题检测算法,在实验参数和实验环境相同的条件下,分别用60个话题进行测试,得到60个测试结果,对这60个结果进行归一化后,得到能够反映话题检测性能的话题检测与跟踪评测结果,即: 归一化检测开销(CDet)Norm[15-16]。最后,根据实验的话题检测与跟踪评测结果分别评估传统的增量聚类、传统的K-means算法和自适应的增量K-means算法的性能。实验的评测结果如表1所示。
为了便于分析这个新算法对话题检测性能的影响,用Excel 2003中的图表向导工具把表1中的数据映射成图1。
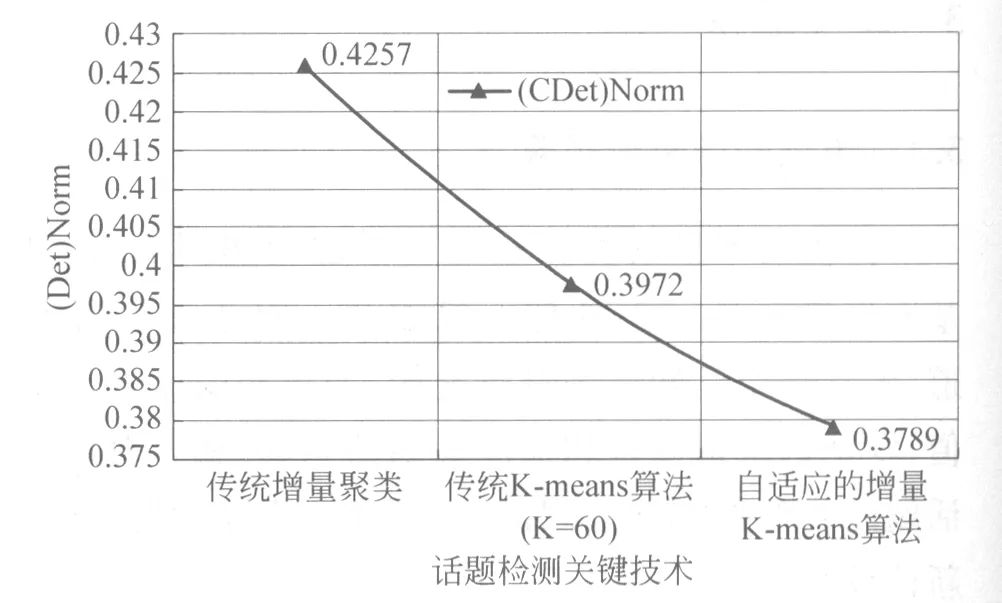
图1 话题检测关键技术与话题检测性能之间的变化趋势图
5.2 实验分析
在实验中,根据评测结果评测话题检测性能,然后根据话题检测性能评估聚类算法作为话题检测关键技术的性能。在同等条件下,评测结果越小,说明话题检测性能越好,也表明该聚类算法作为话题检测关键技术的性能越好。
根据表1和图1,传统的增量聚类作为话题检测关键技术时,TDT评测结果为0.425 7;传统的K-means算法作为话题检测关键技术时,TDT评测结果为0.397 2;自适应的增量K-means算法作为话题检测关键技术时,TDT评测结果为0.378 9。因此,在同等条件下,基于自适应的增量K-means算法的评测结果比基于传统的增量聚类的评测结果减少了10.994%,即自适应的增量K-means算法的性能比传统的增量聚类提高了10.994%;基于自适应的增量K-means算法的评测结果比基于传统的K-means算法的评测结果减少了4.607%,即自适应的增量K-means算法的性能比传统的K-means算法提高了4.607%。除此之外,传统的K-means算法需要对K值初始化,而且K的初始化值对该算法性能的影响很大,而自适应的增量K-means算法用传统增量聚类的思想自适应地调节K值,在很大程度上减少了K初始化值对该算法性能的影响;传统的增量聚类能够得到局部最优解,但很难得到全局最优解,而自适应的K-means算法通过迭代过程能够得到全局最优解,很好地解决了传统的增量聚类所面临的问题。
6 结论
本文分析了话题检测任务的定义和特点,对比了传统的增量聚类和K-means算法的优缺点,然后通过传统的K-means算法改进了传统的增量聚类,提出了基于话题跟踪的自适应增量K-means算法。在同等条件下,经过广泛而深入地研究和分析可知,新算法作为话题检测关键技术具有良好的性能。
[1] 郑斐然,苗夺谦,张志飞,等.一种中文微博新闻话题检测的方法[J].计算机科学,2012,39(1): 138-141
[2] 张阔,李涓子,吴刚,等. 基于关键词元的话题内事件检测 [J]. 计算机研究与发展,2009,46(02): 245-251.
[3] 李忠俊.基于话题检测与聚类的内部舆情监测系统[J].计算机科学,2012,39(12): 241-244.
[4] Nist. The 2004 Topic Detection and Tracking (TDT2004) Task Definition and Evaluation Plan. http://www.itl.nist.gov/iad/mig/tests/tdt/2004/TDT04.Eval.Plan.v1.2.pdf.
[5] 马慧芳,王博. 基于增量主题模型的微博在线事件分析[J]. 计算机工程, 2013, 39(3): 191-196.
[6] 骆卫华,于满泉,许洪波,等. 基于多策略优化的分治多层聚类算法的话题发现研究[J]. 中文信息学报,2006,20(1): 29-36.
[7] 洪宇,张宇,刘挺,等. 话题检测与跟踪的评测及研究综述[J]. 中文信息学报,2007,21(6): 71-87.
[8] 吕明磊,刘冬梅,曾智勇.一种改进的K-means聚类算法的图像检索方法[J]. 计算机科学,2013,40(8): 285-288.
[9] 毛嘉莉. 基于K-means的文本聚类算法[J]. 计算机系统应用,2009,(10): 85-87.
[10] 李胜东,吕学强,魏震等.基于两层阈值的话题报道表示模型[J]. 华中科技大学学报(自然科学版),2013,41(S2): 117-120.
[11] Li Xinwu. Research on Text Clustering Algorithm Based on K_means and SOM[C]//Proceedings of ShangHai: International Symposium on Intelligent Information Technology Application Workshops, 2008: 341-344.
[12] 中科院计算所. 基于多层隐马模型的汉语词法分析系统ICTCLAS. http://www.nlp.org.cn/project/project.php?proj_id=6.
[13] 谭松波,王月粉. 中文文本分类语料库-TanCorpV1.0. http://www.searchforum.org.cn/tansongbo/corpus.htm.
[14] Tan S B, et al. A Novel Refinement Approach for Text Categorization[C]//Proceedings of ACM CIKM, 2005.
[15] Tim Leek, Richard Schwartz, Srinivasa Sista. Probabilistic Approaches to Topic Detection and Tracking [J]. Data Mining and Knowledge Discovery. 2003, 7(3): 67-83.
[16] Yiming Yang, Jaime Carbonell, Ralf Brown, et al. Multi-Strategy Learning for Topic Detection and Tracking: a joint report of CMU approaches to multilingual TDT[C]//Proceedings of TDT 2002 Workshop. 2002: 85-114.
