基于均值密度中心估计的k-means 聚类文本挖掘方法
2014-02-23符保龙张爱科
符保龙,张爱科
(柳州职业技术学院,广西柳州, 545006)
0 引言
随着计算机技术、网络技术、信息技术的迅猛发展,人类获取信息的渠道更加丰富而方式更加简单。这也使得每个人一天被大量的各色信息所包围,而每天所做的重要工作,就是如何从海量信息中遴选出真正需要的信息,这就需要用到数据挖掘技术[1]。文本挖掘是数据挖掘的一个重要分支,专门以分析搜索文本类型的数据为核心目标,综合了数据库、统计分析、机器学习、模式识别等众多学科领域的知识和技术[2]。从文本挖掘的实现方法来看,形成了分析预测法、描述统计法两大类。其中,分析预测法又包含决策树法、神经网络法、支持向量机法等;描述统计法又分为关联分析法、聚类分析法等[3]。
决策树法根据文本信息的属性特征对原始集合进行逐级划分,直到分离每一个属性特征为止,并生成相应的决策树,最终的挖掘过程体现为沿着决策树的逆向回溯。此方法的主要优点是原理简单,但复杂度受控于决策树的维度[4]。神经网络法将搜索特征和搜索策略,映射为神经元和神经网络,其挖掘能力的准确度高,但计算时间长[5]。支持向量机法是非常常用的分类方法,用于数据挖掘和文本挖掘具有理论上的优势,但其挖掘过程受控于核函数的选择[6]。关联分析是数据统计的常见方法,通过置信度、支持率2个重要参数实现对关联规则的解读。其中,支持率可以支撑不同属性特征的划分比例,置信度则表明了这种划分比例的可信程度。这种方法会受到关联规则制定者的主观影响,不同的领域知识、个人价值取向都会造成关联规则制定的差异性[7]。聚类分析致力于基于知识的自动挖掘,是非常高效的无监督学习方法。它通过对初始集合的特征聚类,最大程度地使用文本信息的内在相似性,使得具有相近属性的文本信息聚集于一个空间上高度致密的区域[8]。从实现上来看,K-means聚类就是非常典型的一种。但是K-means聚类受到聚类中心可变性[9]、奇异点[10]等问题的影响,有时无法达到预期的挖掘性能。本文对于文本挖掘技术的研究,就是针对K-means聚类方法展开的,尤其是针对一般K-means聚类方法的聚类中心可变性、奇异点等问题进行处理,使其能达到更高的挖掘性能。
1 K-means聚类方法
设K-means聚类方法是聚类分析中的代表性方法,也是数据挖掘和文本挖掘中的常用技术。其基本的数学处理过程如下:假设用于执行聚类分析的初始数据集合中有m个样本数据,其特征属性总共有K个,这里K是一个大于0的整数。整个K-means聚类的过程,实质上就是使得这m个样本数据形成的特征聚类中心距离平方和最小,即满足(1)式。
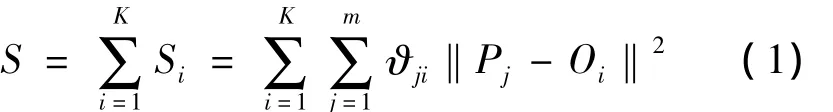
(1)式中:S表示距离平方和的目标函数;Pj为第j个样本数据;Oi为第i个特征聚类中心;ϑji为第j个样本数据与第i个特征聚类中心距离的权重系数。K-means聚类的实现过程,实际上就是求取距离平方和的目标函数的极值过程。当K-means聚类应用于文本挖掘时,实现流程如图1所示。
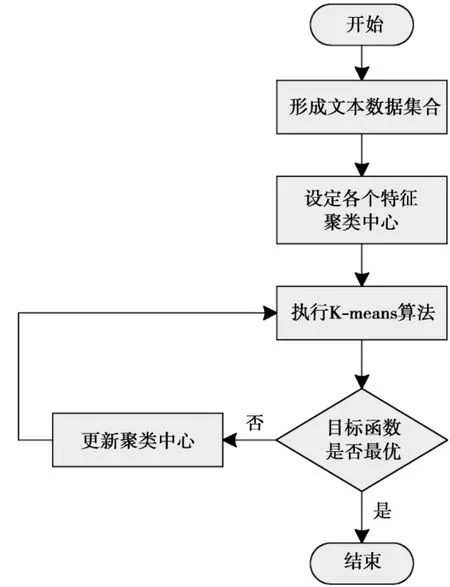
图1 K-means聚类的实现流程Fig.1 K-means clustering implementation process
根据图1所示的K-means聚类实现流程,首先确定执行文本挖掘的原始文本数据集合。然后,为原始集合的K个特征随机选定聚类中心。接下来开始执行K-means迭代算法,求取最佳的距离平方和目标函数。迭代过程中,只要距离平方和目标函数的数值还在变化,就说明其尚未达到最优。这时,就需要更新各个特征聚类中心,重新执行迭代过程。当距离平方和目标函数的数值不再发生变化时,结束迭代过程,此时的聚类中心就是我们所需要的聚类中心。样本数据与各个特征聚类中心的计算公式为(2)式中;sji表示第j个样本数据pj与第i个特征聚类中心Oi间的距离;t表示迭代次数。
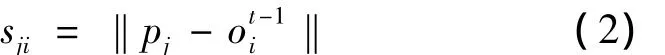
距离平方和目标函数是否发生变化的判断依据如(3)式所示。

K-means聚类的优点是,原理简单、便于数学实现、收敛速度快、聚类能力强,对于大数据量的文本操作非常适用。K-means聚类的缺点是,聚类中心对于迭代结果影响较大,而对于一般使用者而言,聚类中心的数目和初值往往很难设置得非常理想。另外,因为距离平方和的目标函数形式,只能形成规则球形聚类区域,使得K-means聚类对于一些非规则聚类特征效果不理想。再有,奇异点对于K-means聚类的迭代过程也有较大影响。
2 改进的K-means聚类方法
从K-means聚类方法的缺点可以看出,对其影响较大的主要有3个因素:①聚类中心如何妥善选择;②如何根据聚类情况选择有针对性的聚类区域;③如何对奇异点进行处理。为此对K-means聚类方法提出3点改进措施,以全面提高其聚类效果。
首先,对于要执行聚类分析的文本数据而言,不再随机选取聚类中心,而是采取基于均值密度的中心估计方法来估算聚类中心,避免随机选取聚类中心导致的偶然性和错误。仍然用pi表示初始集合的一个文本数据点,现在以pi为中心、以E为边长,构建一个立方体,在这个立方体内的文本数据点的总数称之为pi的密度,记为d(pi)。遍历初始集合中的所有数据点,我们就可以得到以所有数据点为中心的密度集合D为
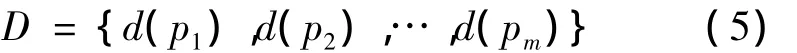
对(5)式中的集合数据求取均值,即可以得到原始数据集合的平均密度为

从(8)式可以看出,OK实际上是剩余数据中前(K-1)个聚类中心距离最小数据的最大者。至此,所有的聚类中心就选取完毕了。这样选择的聚类中心显然比随机选取的聚类中心具有更高的合理性和可信度。
确定了聚类中心,再来解决聚类情况与原始数据分布不符的问题。这里,我们采用一个相对更加灵活的方式。如前所述,我们对原始数据集合和候选密度数据集合中的数据邻域一直使用一个边长为E的立方体,实际上这个可以根据经验事先确定邻域为其他形式。比如球型、棱锥、长方体等,如图2所示。
图2 数据邻域的其他形式Fig.2 Other forms of data neighborhood
当然,实际上事先往往很难决定最适合聚类数据的邻域形式,可以分别选用不同的邻域形式,对比后续的处理结果哪个更加可靠。
最后,对奇异点的处理问题。所谓奇异点,就是原始数据集合中,存在一些远离聚类中心,其周围数据稀疏甚至没有数据的点。在随机选取聚类中心的情况下,一旦选取到奇异点,往往会导致聚类不准确甚至迭代过程无法进行的情况。因此,对于奇异点的去除会大大提高聚类的准确性和可靠程度。对于本文的改进方法而言,奇异点的去除仍然可以依据(5)式进行。(5)式中那些密度最小的点,就可以被作为奇异点删除掉。也可以根据事先设定的域值进行筛选,如(9)式所示。
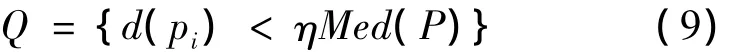
(9)式中:Q为事先设定的阈值;η为调整阈值的权重系数。
我们可以通过控制η的大小,来调整奇异点的判据。至此,对K-means聚类方法的3点改进就全部实现,其他聚类分析的执行过程仍然采用一般的聚类分析的执行方法。
3 实验结果与分析
为了验证本文方法的有效性,我们对基于均值密度中心估计的K-means聚类文本挖掘方法进行了性能测试性实验。实验选用的计算机硬件配置为CPU双核、主频 2.6 GHz,内存 4 GByte、硬盘300 GByte。软件开发工具选择了XP操作系统、C++程序设计语言。文本挖掘实验流程如图3所示。
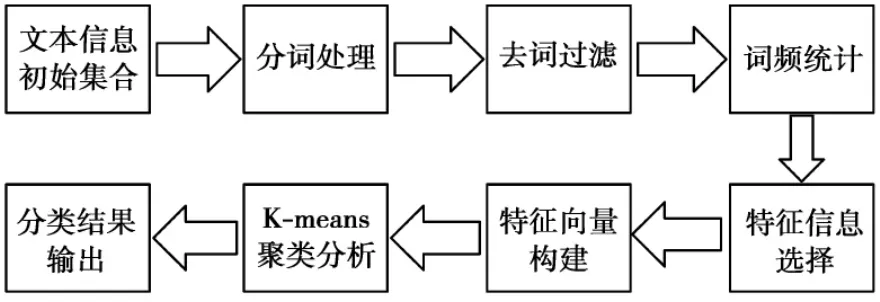
图3 文本挖掘实验流程Fig.3 Process of textmining experiment
图3中,实际中分词处理、去词过滤、词频统计、特征信息选择、特征向量等环节属于文档的预处理阶段,因为不是本文的核心研究工作,因此加以简要介绍。分词处理、去词过滤处理我们直接使用了中科院发布的文档词法分析系统。特征信息选择和特征向量构建,我们采用了基于文档词频的方法。经过这些预处理工作,才可以执行后续的K-means聚类分析。实验所用的文本数据为120篇科技类文献,其内容主体涉及了生物、医学、机械、通信、建筑、农业六大方面,每个领域的文献共有20篇,合计120篇。这120篇文献的分布情况如表1所示。
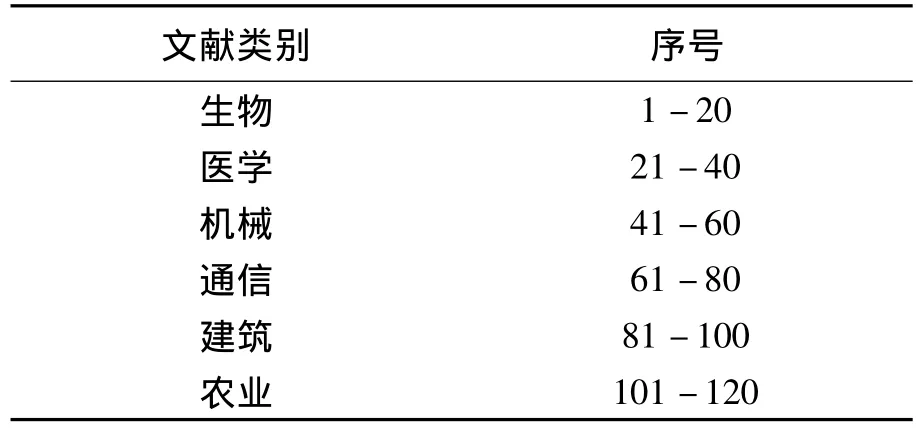
表1 120篇科技文本的序号排布Tab.1 Serial number arrangement of 120 text of science and technology
我们选择聚类项数K=6,分别执行一般的K-means聚类挖掘方法和本文改进后的方法,聚类结果如表2所示。
从表2的数据可以看出,使用一般的K-means聚类挖掘方法得到的结果是生物科技文献查找正确的有第1-8篇、第11-14篇;医学科技文献查找正确的有第22-29篇、第33-40篇;机械类科技文献查找正确的有第42-48篇、第50-58篇;通信类科技文献查找正确的有第61-65篇、第72-79篇;建筑类科技文献查找正确的有第82-88篇、第92-98篇;农业类科技文献查找正确的有第101-106篇、第114-120篇。而采用改进K-means聚类挖掘方法得到的结果是生物科技文献查找正确的有第1-10篇、第14篇、第16-18篇、第20篇;医学科技文献查找正确的有第21-28篇、第30篇、第32-37篇、第39-40篇;机械类科技文献查找正确的有第42-52篇、第55-60篇;通信类科技文献查找正确的有第61-70篇、72-76篇;建筑类科技文献查找正确的有第81-88篇、第92-98篇;农业类科技文献查找正确的有第101-106篇、第111-120篇。
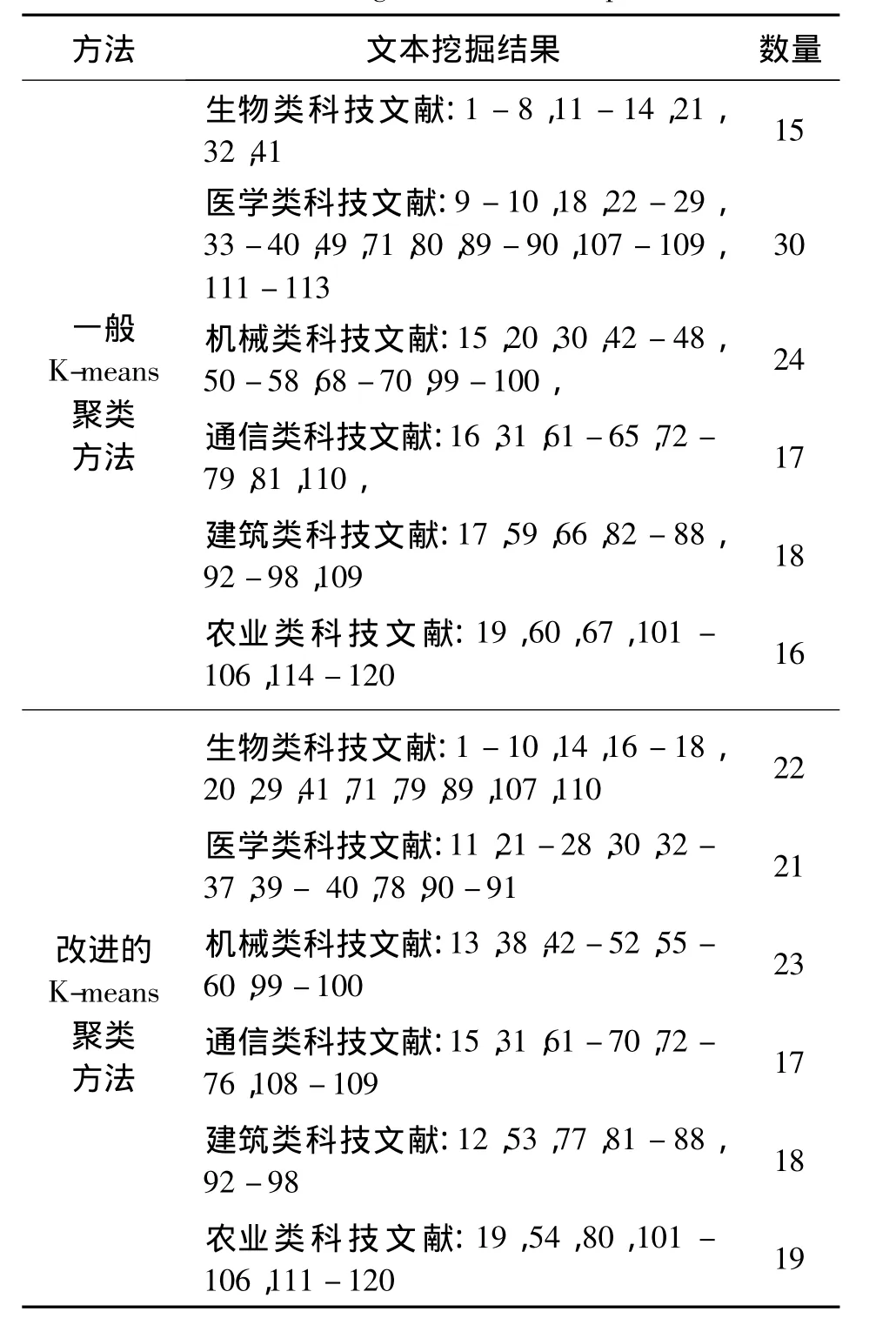
表2 本文实验的聚类结果Tab.2 Clustering results of the experiment
依据表2中的聚类结果,对一般的K-means聚类挖掘方法和改进后的K-means聚类挖掘方法的查准率进行比较,其结果如表3所示。
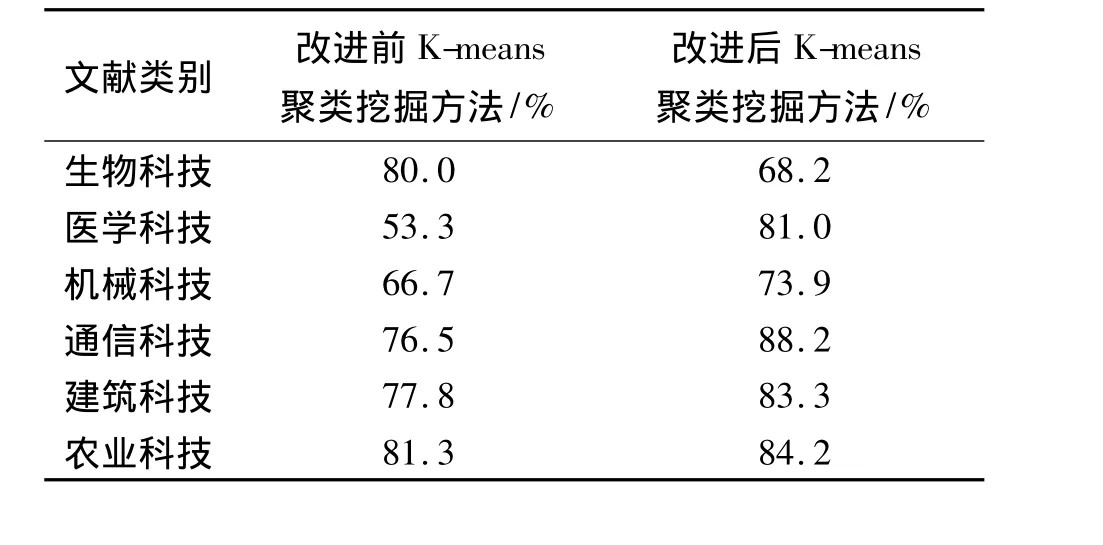
表3 改进前后K-means聚类挖掘方法的查准率Tab.3 Before and after improvement of K means clusteringminingmethod precision
表3中数据用柱状图形式表达如图4所示。
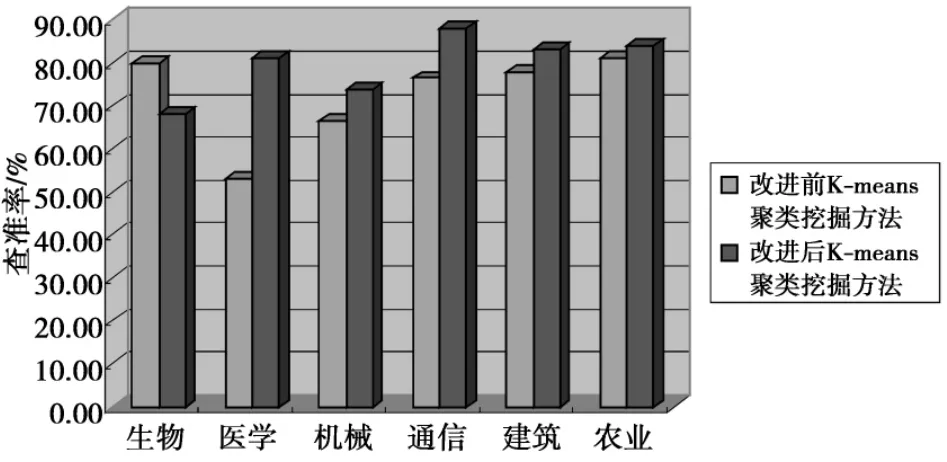
图4 表3数据的柱状图分析结果Fig.4 Histogram analysis of the data in Tab.3
从表3中的数据和图4的图形可以看出,经过本文方法,改进后的K-means聚类挖掘方法对于六大类科技文献的查准率,有5类高于改进前的K-means聚类挖掘方法,从而证实了本文方法改进措施的有效性。
为了进一步比对本文改进方法与其他原理实现文本挖掘方法的性能,本文选取文献[11]中的自组织神经网络聚类方法(self-organizing map feature neural network,SOM)进行横向比对,仍然采用表2所述的数据,比较结果如表4和图5所示。
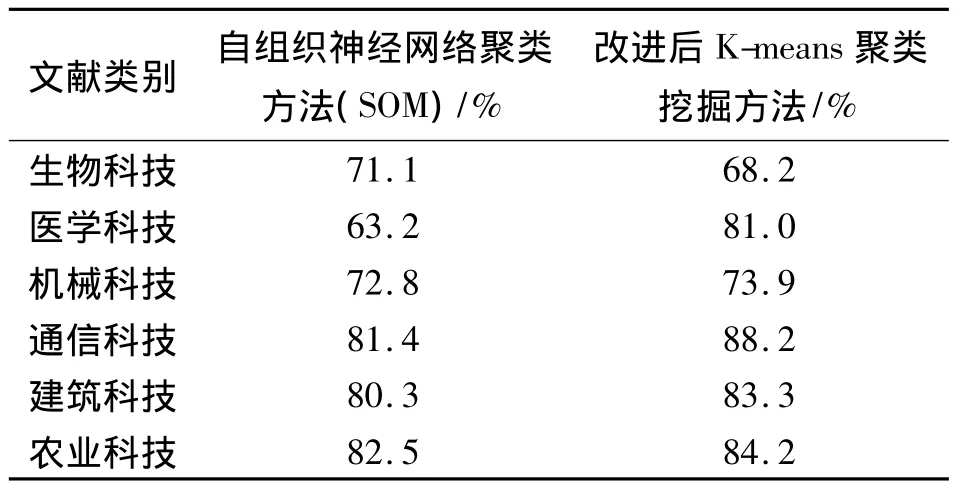
表4 改进前后K-means聚类挖掘方法的查准率Tab.4 Before and after improvement of K means clusteringminingmethod precision
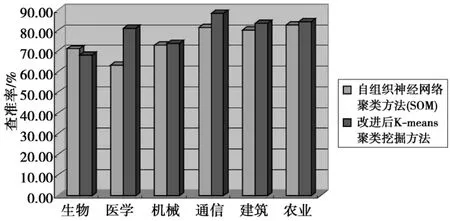
图5 表4数据的柱状图分析结果Fig.5 histogram analysis of the data in Tab.4
从表4中的数据和图5的图形可以看出,SOM比一般的K-means均值聚类方法要优秀,但和本文改进的K-means均值聚类方法相比要稍差一些。综合这2次比较的结果可以看出,本文的改进方法在文本挖掘查准率方面不仅强于一般K-means均值聚类的方法,且与新近流行的自组织神经网络聚类方法相比也具有一定的优势。
4 结束语
本文建立了一种基于均值密度的聚类中心迭代初值求取方法;根据文本数据集合的特征选择性地使用针对性更强的邻域形状;利用均值密度配合阈值策略消除奇异点的影响。实验结果表明,经过本文方法的改进,K-means聚类挖掘方法可以获得更高的文本挖掘查准率。
[1]CHEN Chunling,TSENG F SC,LIANG Tyne.Hierarchical document clustering using fuzzy association rule mining[C]//In proc of the 3rd International Conference on Innovative Computing Information and Control.Dalian Liaoning:Conference Publications,2008:326-329.
[2]赵康,陆介平,倪巍伟.一种基于密度的文本聚类挖掘算法[J].计算机应用研究,2009,26(1):124-126.
ZHAO Kang,LIU Jieping,NIWewei.A kind of text clustering mining algorithm based on density[J].Computer application research,2009,26(1):124-126.
[3]梁文婷,何中市,龙华,等.改进传统文本结构关系图的文本分析[J].微计算机信息,2009,3:213-215.
LIANGWenting,HE Zhongshi,LONG Hua,et al.Improve the traditional text structure diagram textanalysis[J].Microcomputer information,2009,3:213-215.
[4]徐丽,伏玉琛,李斯.一种改进的SVM决策树Web文本分类算法[J].苏州大学学报:工学版,2011,31(5):7-11.
XU Li,FU Yuchen,LISi.An improved SVM decision tree Web text categorization algorithm[J].Journal of suzhou university:engineering science,2011,31(5):7-11.
[5]朱云霞.结合聚类思想神经网络文本分类技术研究[J].计算机应用研究,2012,29(1):155-157.
ZHU Yunxia.Combined with neural network clustering thought text classification technology research[J].Computer application research,2012,29(1):155-157.
[6]赵知伟,顾静航,胡亚楠,等.基于支持向量机分类和语义信息的中文跨文本指代消解[J].计算机应用,2013,33(4):984-987.
ZHAO Zhiwei,GU Jinghang HU Yanan,et al.Based on support vector machine(SVM)classification and semantic information across in Chinese text to refer to eliminate[J].Journal of computer applications,2013,33(4):984-987.
[7]陶余会,周水庚,关佶红.一种基于文本单元关联网络的自动文摘方法[J].模式识别与人工智能,2008,22(3):440-444.
TAO Yuhui,ZHOU Shuikan,GUAN Jiehong.A kind of automatic summarizationmethod based on textunitassociated network[J].Journal of pattern recognition and artificial intelligence,2008,22(3):440-444.
[8]彭京,杨冬青,唐世渭,等.一种基于语义内积空间模型的文本聚类算法[J].计算机学报,2007,30(8):1354-1363.
PENG jing,YANG Dongqin,TANG Shiwei,et al.A model based on semantic inner product space text clustering algorithm[J].Journal of computers,2007,30(8):1354-1363.
[9]李霞,蒋盛益,张倩生,等.适用于大规模文本处理的动态密度聚类算法[J].北京大学学报:自然科学版,2013,49(1):133-139.
LIXia,JIANG Shenyi,ZHANG Qiansheng,et al.Suitable for large-scale text processing dynamic density clustering algorithm[J].Journal of Beijing university:natural science edition,2013,49(1):133-139.
[10]冯汝伟,谢强,丁秋林.基于文本聚类与分布式Lucene的知识检验[J].计算机应用,2013,33(1):186-188.
FENG Ruwei,XIE Jiang,DING Qiulin.Based on text clustering and distributed Lucene knowledge test[J].Journal of computer applications,2013,33(1):186-188.
[11]蔡丽宏.SOM聚类算法的改进及其在文本挖掘中的应用研究[D].南京:南京航空航天大学,2011.
CAILihong.SOM clustering algorithm is improved and its application in textmining research[D].Nanjing:Nanjing university of aeronautics and astronautics,2011.
(编辑:魏琴芳)
