海量数据的MapReduce相似度检测
2014-02-08张敏
张 敏
(河南理工大学 测绘与国土信息工程学院,河南 焦作 454003)
0 引 言
随着数字信息量的几何式增长,数据占用空间越来越大。在过去的几年里,存储系统容量从数十GB发展到数百TB,甚至数PB[1]。随着数据指数级增长,管理保存数据成本及数据中心空间和能耗也变得越来越严重。研究发现,保存的数据中有六成以上是冗余的,而且随着时间的推移,这种问题会更加严重。为了缓解存储系统的空间增长问题,最大程度地利用已有资源,重复数据查找删除技术已成为一个热门的研究课题。一方面,重复数据查找可以对存储空间进行优化,消除分布在存储系统中的相同文件或者数据块。另一方面,可以减少在网络中传输的数据量,进而降低能量消耗和网络成本,并为数据复制大量节省网络带宽。
1 相关工作
相似重复记录的检测主要有排序合并法、建索引法、机器学习法和基于特定领域知识法,其中排序合并和建索引的方法是不依赖于特定应用领域的通用方法;文献[2]采用排序合并的方法,根据用户选定的若干个属性字符串合并作为键进行排序后,采用固定大小的滑动窗口进行聚类来识别相似重复记录;文献[3]介绍的根据不同的属性进行多路排序合并,并采用优先队列取代固定大小的滑动窗口来进行聚类。这两种方法之主要不足在于大数据量记录及排序引起大量IO操作,成为算法运行效率的瓶颈;另一方面由于字符串排序对字符位置敏感,所以不能保证将相似的重复记录放在邻近的位置,因而决定了后来的聚类操作不一定能将相似记录识别出来。采用R树建索引的方法[4]中首先依据Fastmap方法选取若干个记录作为轴(Pivot),各个记录依据这若干个轴计算它本身在多维空间中的坐标,然后采用R树进行多维空间相似性连接来实现相似记录的识别。但是由于Fastmap方法本身不可收缩性(Contractive),因此这种映射方法会造成大量的数据丢失,且由于维度灾难,也就决定了维度不能过高,使得这种方法不具有通用性。文献[5]针对的是数据在线去重问题,它是在有干净参照表的条件下进行数据清洗的方法。
通过向量空间模型(Vector Space Model,VSM)计算相似度,但这种方法存在的问题是需要对文本两两进行相似度比较,无法扩展到海量文本的处理。因此,若能结合海量数据的计算模型和VSM,先对文本进行分词预处理,然后建立文本向量,把相似度的计算转换成某种特征向量距离的计算(如Jaccard相似系数等),则可以实现海量数据相似度检测,从而解决海量数据的去重问题。
2 Simhash算法与云计算
2.1 Jaccard相似度
集合S和T之间的Jaccard相似度是指集合S和T的交集和并集之间的比值,即Jaccard_Sim(S,T)=|S∩T|/|S∪T|。例如:S={a,d},T={a,c,d},则Jaccard_Sim(S,T)=|{a,d}|/|{a,c,d}|=2/3。一篇文档可能包含上成千上万个元素,对大量的文档,保存这些元素需要很大的空间,通过一种方法来减少元素个数,并且通过少量元素依然可以得到原来的Jaccard相似度,过程如下:
假设对元素集E={a,b,c,d,e}上的集合S1={a,d},S2={a,c,d},其特征矩阵为
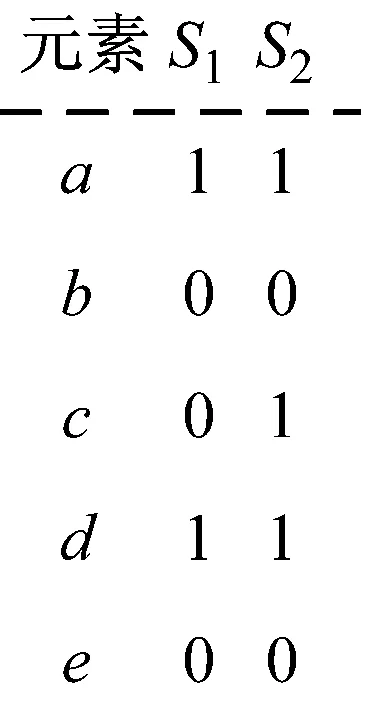
定义f为E上的一个映射关系,将f作用于S1,S2上,其特征矩阵为

取m1为f(S1)中的最小值,即m1=min{f(a),f(d)},m2为f(S2)中的最小值,即m2=min{f(a),f(c),f(d)},则m1与m2相等的概率为:P(m1=m2)=P(min{f(a),(b)}=min{f(a),f(c),f(d)})=|{f(a),f(d)}|/|{f(a),f(c),f(d)}|=|{a,d}|/|{a,c,d}|=Jaccard_Sim(S1,S2)。
因此,令m1为S1的一个签名,m2为S2的一个签名,通过少量的签名,能够得Jaccard_Sim(S1,S2) 的一个近似值。将上面的映射关系f替换为一个E上的随机哈希函数,这个结论依然成立。所以,对一篇文档使用n个随机哈希函数可以得到n个签名,称为文档的最小哈希签名,并且通过比较最小哈希签名可以得到两篇文档间的Jaccard相似度。
对两篇文档[9],如果它们相似,则它们的哈希值有较高的概率是相同的。有了文档的最小哈希签名,就能实现这种哈希方法,将包含b×r个值最小哈希签名分为b等份,每份r个,对两个文档,定义P为两个文档至少含有1个相同份的概率,显然,文档间的Jaccard相似度越高,哈希签名具有相同值的位数就越多,概率P就越大。
2.2 Simhash算法
SimHash通过产生签名用来检测原始内容的相似度。假设输入的是一个文档的特征集合,每个特征有一定的权重。特征可以是文档中的词,其权重可以是这个词出现的次数,SimHash能够将其映射到一个低维向量空间,并根据该低维向量产生一个很小的指纹;算法过程如下:
(1) 将一个f维的向量V初始化为0;f位的二进制数S初始化为0;
(2) 对每一个特征:用传统的hash算法对该特征产生一个f位的签名b。对i=1到f,如果b的第i位为1,则V的第i个元素加上该特征的权重;否则,V的第i个元素减去该特征的权重;
(3) 如果V的第i个元素大于0,则S的第i位为1,否则为0;
(4) 输出S作为签名。
与传统的加密型哈希函数相比,SimHash拥有一个显著特征,即越相似的原始信息会生成越相似的哈希值,也就是哈希值的海明距离越小。而传统的哈希函数,为两个不同的原始信息生成哈希值时,即使它们实际上很相近,计算得出的哈希值之间汉明距离也可能非常大,无法用于度量原始信息的相似度。
2.3 MapReduce
MapReduce[6]是一种高效的分布式编程模型,其工作机制如图2所示,用于处理和生成大规模数据集的实现方式[7]。MapReduce中两项核心操作为Map和Reduce操作,其Map操作独立地对每个元素进行操作;Reduce操作对N个Map结果进行排序收集,也就是Map[1,2,…,N]的结果是Reduce操作的参数。在MapReduce编程模型中,只要没有函数修改或依赖于全局变量,N个Map操作的执行顺序可以是无序的;而且,Map和Reduce都以其他的函数作为输入参数,正是因为可以同其他函数相结合,所以只要把Map和Reduce这两个函数进行并行化处理,就无需面面俱到地把所有的函数全部考虑到,这样便形成了一个以Map和Reduce为基础的编程模型。该模型为用户提供编写与具体应用相关的函数的编程接口,用户把计算需求归结为Map和Reduce操作,通过这个接口提交到MapReduce系统上就可以获得并行处理的能力,所以,这种特性使MapReduce模型非常适合于对大规模数据进行并行处理。
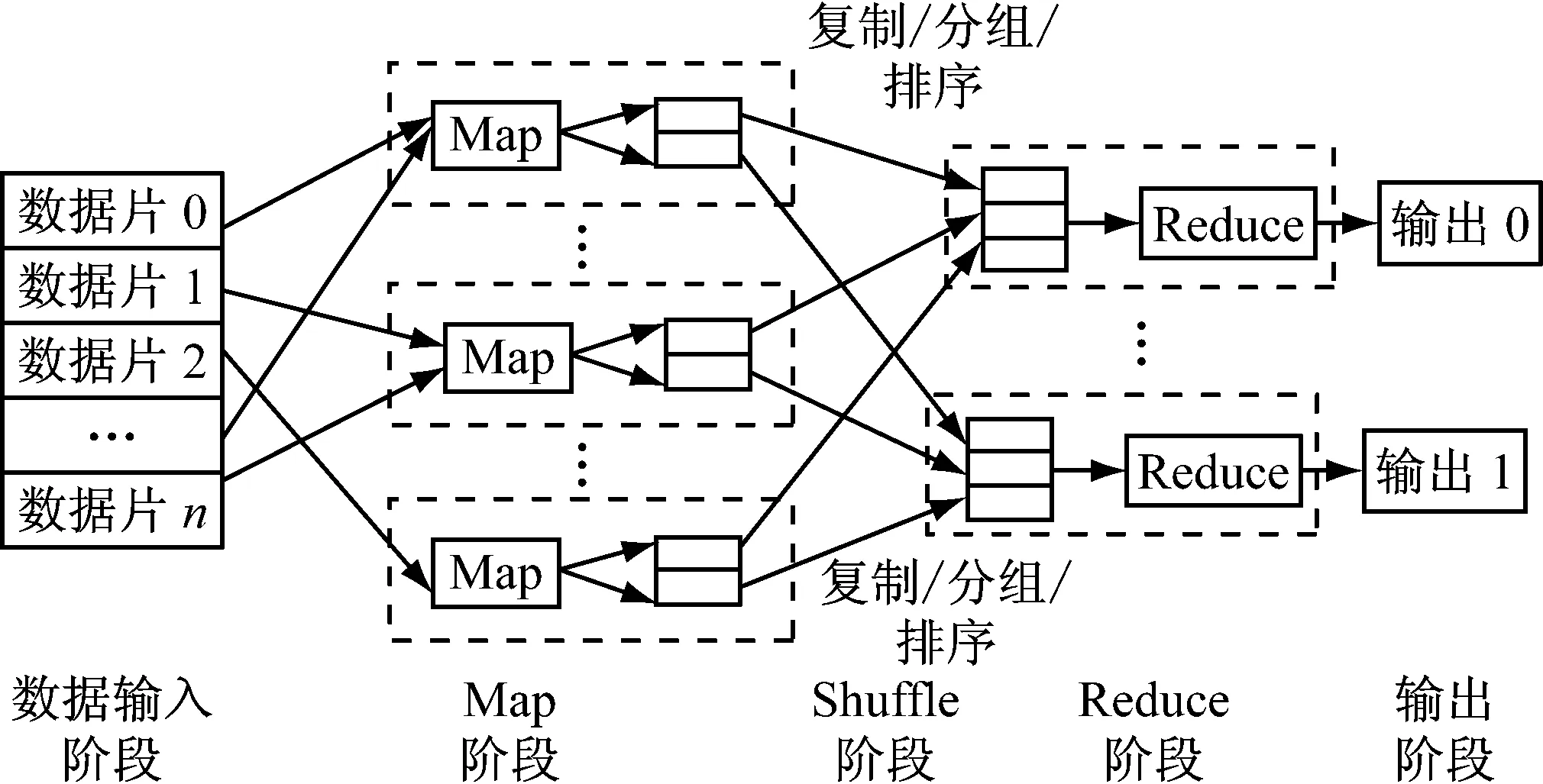
图2 MapReduce工作机制
3 MapReduce下相似文档查找流程及算法
根据MapReduce工作机制,提出MapReduce下以Simhash算法查找近似文本检测流程,如图3所示。海量文档集存储在Hadoop分布式文件系统(HDFS)中,术语集和文本-术语关系集存储在分布式key-value系统HBase中,特征提取算法和相似度计算算法采用分布式计算模型Map/Reduce。此外,由于海量文档集的文本数量众多并且大小相对较小[9-10],使用HDFS提供的SequenceFile InputFormat方法[11],将文件名作为key、文件作为value,以key-value的形式将文本存储在Sequence File。同样,对提取出特征向量或指纹也以key-value的形式存储在另外的Sequence File[12]。
(1) 预处理。主要包括: 预处理文本文件、存储术语集和文本-术语对应关系[13]。由于文本文件的格式多样性,为求统一,将各种格式的文本转化为TXT文件。对术语集和文本-术语对应关系,使用HBase提供的应用程序接口将其存储。
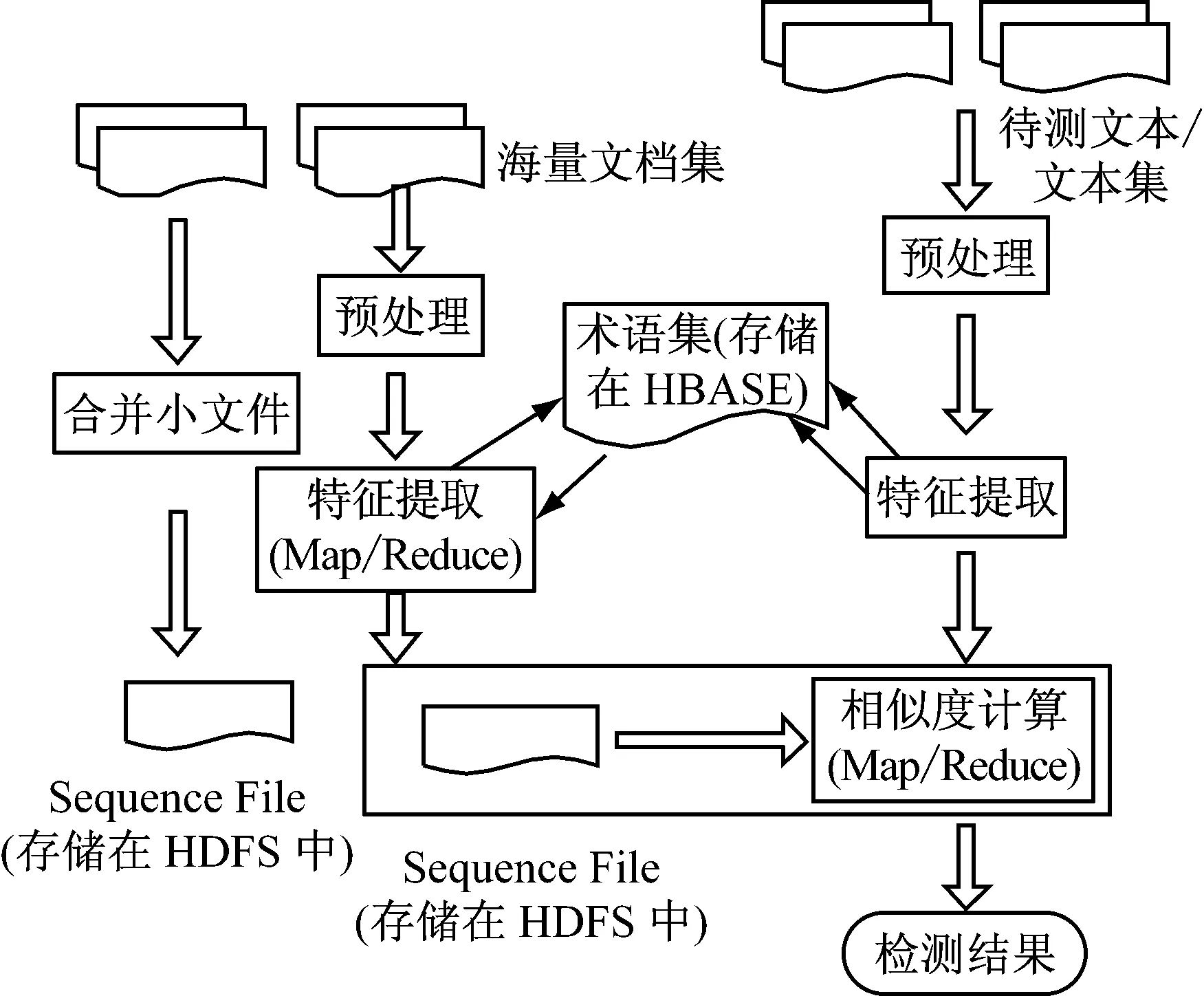
图3 基于MapReduce的文本近似检测流程
(2) 特征提取。首先将文本表示成词频向量,然后计算词频向量指纹。由于学习资源存在领域术语的特征,文本将表示为一个高维术语词频向量,然后再使用SimHash算法生成指纹。为提高特征提取算法的效率,用Map/Reduce模型提取文档集特征。对给定的文档集,特征提取Map/Reduce任务只需运行1次,输入是文档集,输出是Sequence File,其中文件名作为key,文件的指纹作为value。
特征提取过程包括提取词频向量、生成SimHash指纹和生成Sequence File。提取词频向量提取词频向量是将文本转换为一个n维词频向量;SimHash使用SimHash算法计算该词频向量的64 b SimHash指纹;生成SequenceFile得到文本的指纹后,将文件名作为key,其64 b SimHash指纹作为value,写入Sequence File中。
(3) 相似度计算。用于比较待测文本和文档集文本之间的相似度。它使用待测文本的指纹和文档集特征提取输出的SequenceFile作为输入,采用各种相似度度量方法(例如对SimHash指纹则采用海明距离),进行近似检测[14],算法的伪代码如下所示:
Class Mapper{
method map(〈label,txtid〉,Vector)
write(〈label,txtid〉,Vector)
}
Class Reducer{
Matrix matrix;//每一行对应一个类别的向量和
int i=0;
String[]labels;
void setup(){
int i=0;
SequenceFile.Reader reader=new
SequenceFile.Reader(“exameDataSet”);
While(reader.next(key.value)){
matrix.assignRow(i,value);
labels[i]=key;
}
}
void map(〈label,txtid〉,vector){
double sim=0;//最大相似度值
String testLabel;//测试类标
for(int i=0;i〈ma.numRows;i++){
double cos=cos_sim(Vector,ma.getRow(i));
if(max〈cos)max=cos;
testLable=Lables[i];
write(lable,〈testLable,txtid〉;
}
4 实验结果与验证
本实验基于河南理工大学高性能计算平台进行,该平台由曙光刀片机构建,共有共34个节点:1个管理节点,1个IO节点,32个计算节点,千兆存储网络。系统采用RedHat Linux构建高计算集群。单节点配置Intel Xeon E5504 2.00 GHz CPU,8 GB内存,120 GB硬盘。软件配有J2SE 6.0,Hadoop 0.20.2,HBase-0.20.6等。在该环境下,选择1个为NameNode作为控制节点、 6个DataNode参与计算任务。
为验证近似文本检测算法能够适用于海量数据,算法将在两个中文数据集上做实验,第一是谭松波(TanCorp-10)等搜集的文档[15],共14 150篇、29.5 MB、包含10个类别,如表1所示;第二个数据集是搜狗新闻2008年上半年(SogouCS)国内外18个频道[16],提供URL和正文信息,共2 101 582篇文档、3.33 GB、包含15个类别如表1、2所示。
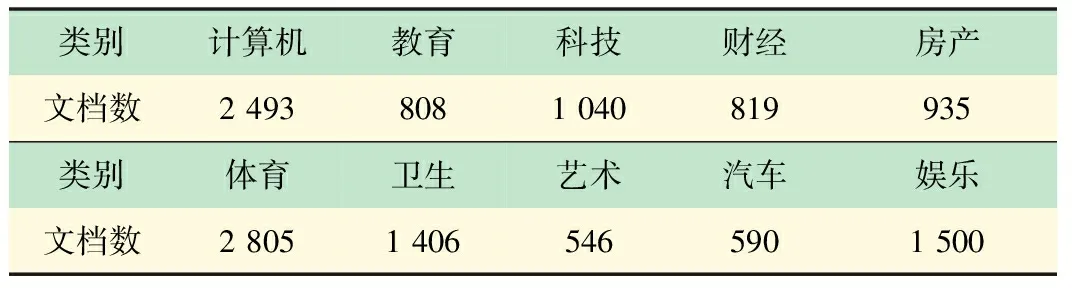
表1 TanCorp-10数据集分布
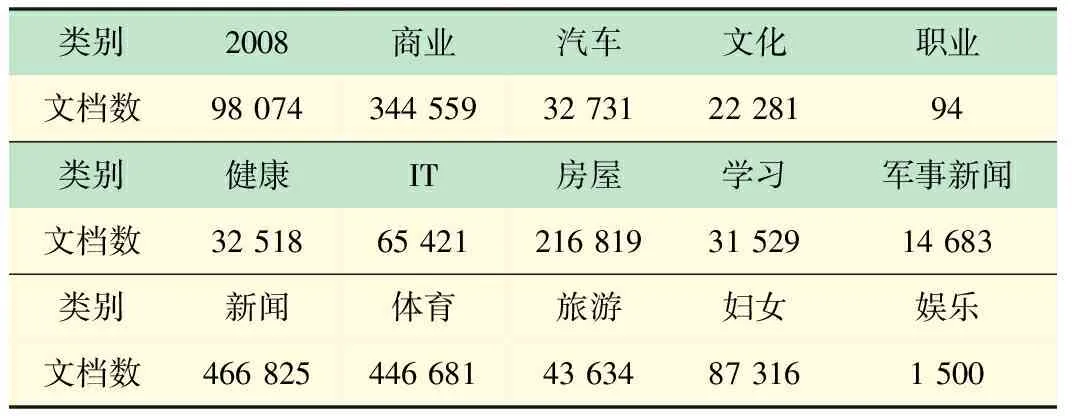
表2 SogouCS数据集分布
4.1 执行时间对比
实验分别在单机和Hadoop的全分布式环境下进行,采用90%作为训练集,10%为测试集,执行时间如图4所示。
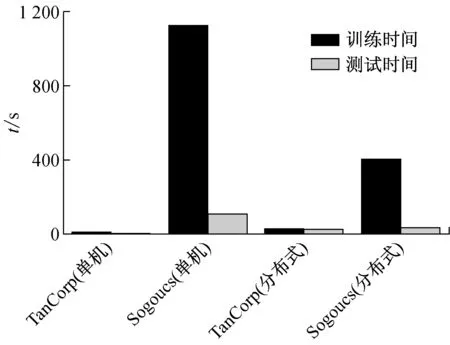
图4 单机和全分布式执行时
从上图可知,对于小数据集(TanCorp)在分布式环境效果不明显,其原因是:在小数据集下,Hadoop对数据是分块处理的,默认64 MB为一个数据块,如果存在大量小数据文件,这样的小数据文件达不到Hadoop默认数据块的大小时,就要按一个数据块来进行处理。这样处理带来结果是:存储大量小文件占据存储空间,致使存储效率不高、检索速度也比大文件慢;而且进行MapReduce运算时,小文件消费计算能力。对于大数据集,设计的算法优势明显突出。
4.2 相似度计算时间对比
分别在上述两个数据集使用Map/Reduce进行实验,对比欧氏距离、余弦相似度、相关系数、SimHash的相似度计算的执行时间,其执行时间如表3所示。
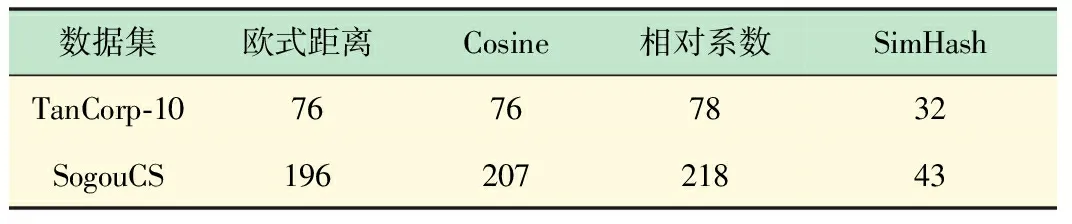
表3 相似度时间对比表
从上表可知,在TanCorp-10中,相对于欧氏距离、余弦相似度和相关系数的相似度计算执行时间,SimHash的相似度计算的执行时间分别减少了137.5%、137.5%、143.8%;在SogouCSS中,执行时间分别减少了355.8%、381.4%、406.9%。这验证了基于SimHash指纹的海明距离比较在时间上优于经典的文本相似度计算方法;也印证5.1节中,在处理大数据集上,MapReduce优势明显突出。
5 结 语
相对于以往相似重复记录的检测方法,本文提出了基于MapReduce的文本近似检测流程,并设计了SimHash相似度算法,最后在实验环境下进行了验证。通过实验可知,SimHash相似度的算法应用在MapReduce下,非常适合海量数据集的文档相似度计算,极大降低了时间开销,为解决海量数据去重问题提供一定的参考价值。
[1] Agrawal D, Bernstenin P, Bertino E,etal. Challenges and opportunities with big data-A community white paper developed by leading researchers across the United States[R/OL]. [2012-10-02]. http://cra.org/ccc/docs/init/bigdata/whitepaper.pdf
[2] 付印金, 肖 侬, 刘 芳. 重复数据删除关键技术研究进展[J]. 计算机研究与发展, 2012,49(1):12-20.
FU Yin-jin, XIAO Nong, LIU Fang. Key technology research progress of duplicate data de-duplication [J]. Computer Research and Progress, 2012,49(1):12-20.
[3] 敖 莉, 舒继武, 李明强,等. 重复数据删除技术[J].电子学报, 2010,21(5): 916-918.
AO Li, SHU Ji-wu, LI Ming-qiang,etal. Duplicate data de-duplication technology [J]. Journal of electronic, 2010,21(5): 916-918.
[4] 韩京宇, 徐立臻. 一种大数据量的相似记录检测方法[J].计算机研究与发展, 2005,42(12):2207-2209.
HAN Jing-yu, XU Li-zhen. A kind of detection approach of duplicate recorder for massive data [J]. Computer Research and Progress, 2005,42(12):2207-2209.
[5] 李星毅,包从剑. 数据仓库中的相似重复记录检测方法[J].电子科技大学学报, 2007,36(6):1273-1276.
LI Xing-yi, BAO Cong-jian. Detecting approach for similar duplicate recorder in data warehouse [J]. Journal of electronic technology university, 2007,36(6):1273-1276.
[6] 李建江,崔 健. MapReduce并行编程模型研究综述[J].电子学报,2011,39(11): 2639-2645.
LI Jian-jiang, CUI Jian. Research review of parallel programming model [J]. Journal of electronic, 2011,39(11): 2639-2645.
[7] 陈 康,郑纬民.云计算:系统实例与研究现状[J].软件学报,2009,20(5):1337-1348.
CHEN Kang, ZHENG Wei-min. Cloud computing: System instance and research situation [J]. Journal of software, 2009,20(5):1337-1348.
[8] 张组斌, 徐 欣, 龙 君,等. 文本相似度检测的参数关联和优化[J] 中文计算机系统, 2011, 32(5): 983-988.
ZHANG Zu-ping, XU Xin, LONG Jun,etal.Parameters correlation and optimization in text similarity measurement[J].Journal of Chinese Computer Systems, 2011, 32(5): 983-988.
[9] 程国达, 苏杭丽. 一种检测汉语相似重复记录的有效方法[J]. 计算机应用, 2005, 25(6): 1361-1365.
CHENG Gou-da, SU Hang-li. A kind of valid method of detecting Chinese similar recorder [J]. Computer application, 2005, 25(6): 1361-1365.
[10] Nature. Big Data [EB/OL]. [2012-10-02]. http://www.nature.com/news/specials/bigdata/index.html
[11] Shahri H H. Eliminating duplicates in information integration: an adaptive, extensible framework [J].IEEE Intelligent Systems, 2006, 12(5): 63-71.
[12] A Verma,N Zea,etal. Breaking the Mapreduce Stage Barrier. Proc of IEEE International Conference on Cluster Computing[C].Los Alamitos: IEEE Computer Society,2010:235-244.
[13] 朱恒民,王宁生.一种改进的相似重复记录检测方法[J].控制与决策, 2006, 21(7): 805-808.
ZHU Hen-min, WANG Ning-sheng. A kind of improved detecting method for similar duplicate recorder [J]. Control and decision, 2006, 21(7): 805-808.
[14] Paul S, Saravanan D V. Hash Partitioned Apriori in Parallel and Distribute Data Mining Environment with Dynamic Data Allocation Approach [C] //ICCSIT'08 Proceedings of the 2008 International Conference on Computer Science and Information Technology. 2008.
