基于用户反馈的个性化垃圾邮件过滤方法
2014-01-16黄国伟刘云霞
黄国伟,刘云霞,陈 志
(1.深圳信息职业技术学院 广东 深圳 518172;2.天津工业大学 天津 300387)
随着计算机网络的普及,电子邮件得到了广泛应用,已成为人们进行沟通、交流的重要手段。然而随之而来的垃圾邮件泛滥问题,严重干扰着电子邮件用户的日常生活与工作。据相关统计报告[1],2010年第四季度中国垃圾邮件数量已占电子邮件总量的87.2%。面对垃圾邮件的泛滥,研究人员针对如何进行垃圾邮件过滤这一问题进行了广泛而深入的研究,提出了诸如贝叶斯过滤技术[2-3]、支持向量机过滤技术[4]、决策树过滤技术[5]、黑白名单技术[6]等垃圾邮件过滤技术,上述技术在实际应用中取得了较好的过滤效果,在一定程度上抑制了垃圾邮件的影响[7]。
垃圾邮件过滤要求在线对邮件进行二值分类,即在线将邮件判别为正常邮件或垃圾邮件。然而与传统的文本二值分类问题相比,垃圾邮件过滤这一在线二值分类问题具有十分明显的个性化特点。由于用户兴趣、爱好的不同,用户对垃圾邮件的定义可能存在巨大差异[8],不同用户对同一封邮件可能有着截然不同的分类结果。如果采用全局统一的邮件分类标准对所有用户的邮件进行分类而忽略用户间的差异性,将势必造成邮件的误判并导致邮件分类准确性的降低。因此,如何在已有垃圾邮件过滤技术基础上实现垃圾邮件个性化过滤,从而进一步提升邮件分类效果,是当前垃圾邮件过滤技术领域的一个研究热点。
用户个性化邮件分类标准的提取是实现个性化垃圾邮件过滤的关键。电子邮件应用的用户作为垃圾邮件的直接受害者,其对一封邮件的手工分类处理结果则能够反映用户对该邮件的喜恶与倾向。因此,如果用户能够将其邮件分类的相关信息进行反馈,将有助于用户个性化邮件分类标准的提取,进而为垃圾邮件个性化过滤的实现提供有力依据。基于这一思想,文中提出一种基于用户反馈的个性化垃圾邮件过滤方法:一方面借助用户邮件分类反馈信息实现全局邮件分类标准与用户个性化邮件分类标准的提取与更新;在此基础上,实现用户个性化邮件分类标准与全局邮件分类标准在朴素贝叶斯邮件分类过程中的有机结合,以同时从全局和用户个体两个方面综合判别邮件是否为垃圾邮件,提升垃圾邮件过滤的准确性。
1 贝叶斯邮件分类算法简介
贝叶斯分类的基本理论依据是:大多数事件都是相互依赖的,那么一个事件将来发生的概率可以从该事件之前发生的概率进行推断。在传统的贝叶斯邮件分类算法中[2],通常以邮件e属于正常邮件类(Ham)和垃圾邮件类(Spam)的后验概率比值作为邮件分类的依据,其具体计算方法如(1)式所示:

其中,P(Ham)与P(Spam)分别为正常邮件和垃圾邮件的出现概率;P(e|Ham)与P(e|Spam)分别为在正常邮件类和垃圾邮件类中出现邮件e的先验概率。当比值超过预定阈值时,则贝叶斯分类算法将邮件e判定为垃圾邮件,否则判定为正常邮件。
朴素贝叶斯分类算法则在传统贝叶斯分类算法基础之上,应用了“邮件特征词条件独立性假设”[3]:即在给定邮件分类条件下,邮件 e各特征词{w1,w2,…,wn}的出现相互独立,其中n为在邮件e中所提取的邮件特征词个数。将这一假设应用在(1)中,则朴素贝叶斯分类算法的邮件分类依据如式(2)所示:

其中,P(wi|Spam)与 P(wi|Ham)分别代表在垃圾邮件类和正常邮件类中出现特征词wi的先验概率;两者比值P(wi|Spam)/P(wi|Ham)则代表了邮件特征词wi对邮件e分类结果的影响权重。
在传统朴素贝叶斯分类算法对邮件进行分类的过程中,概率比值P(wi|Spam)/P(wi|Ham)并不会随着用户的不同而发生改变,这意味着特征词wi的出现对不同用户邮件的分类影响均相同。因此,传统朴素贝叶斯分类算法忽略了不同用户对特征词wi的喜恶差异,势必对邮件分类的准确性产生影响。如果能够将用户个性化邮件分类标准融入朴素贝叶斯邮件分类过程之中,将有助于垃圾邮件过滤准确性的进一步提升。
2 个性化垃圾邮件过滤方法
基于用户反馈的个性化垃圾邮件过滤方法的邮件处理基本流程如图1所示:过滤方法由邮件分类知识学习与邮件分类两部分组成:一方面,用户的反馈信息将同时应用于全局邮件分类知识和用户个性化邮件分类知识的提取与更新;在另一方面,将上述邮件分类知识有机结合应用于朴素贝叶斯邮件分类之中,同时从全局与用户个体两个方面综合判别邮件是否为垃圾邮件,实现用户邮件个性化分类。
2.1 基于用户反馈的邮件分类知识学习
本文假设垃圾邮件过滤系统已经实现了可用于用户反馈的接口。当接收到一封邮件时,用户可通过该反馈接口手工向系统提供其对邮件进行分类的相关信息。在本文中,用户反馈信息包含3部分内容:邮件的完整内容、邮件分类结果以及邮件的分类时间戳。
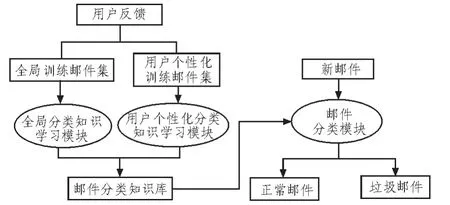
图1 基于用户反馈的个性化垃圾邮件过滤方法工作流程Fig.1 Procedure of the personalized spam filtering method based on users'feedback
2.1.1 全局邮件分类知识学习
用户反馈所包含的邮件将作为邮件样本进入系统的全局训练邮件集中;同时,为保证训练邮件集中的邮件能够反映垃圾邮件的当前变化趋势,全局邮件分类知识学习模块将周期性从训练邮件集中移除时间戳较早的邮件样本。
在训练邮件集的基础上,本文采用基于贝叶斯的邮件内容学习模块,以全局训练邮件集中邮件特征词wi(1≤i≤n)在垃圾邮件类Spam和正常邮件类Ham下的先验条件概率G(wi|Spam)、G(wi|Ham)作为全局邮件分类知识,其中n为训练邮件集中不同邮件特征词的个数。上述概率的计算方法如式(3)、(4)所示:
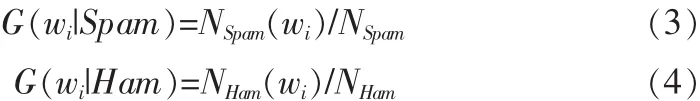
其中,参数Nspam和NHam分别代表全局训练邮件集中垃圾邮件样本和正常邮件样本的数量;参数 Nspam(wi)和 NHam(wi)分别代表在垃圾邮件样本和正常邮件样本中出现特征词wi的邮件数量。 因此,概率 G(wi|Spam)、G(wi|Ham)的取值代表了特征词wi在不同邮件类别中出现的概率差异。
由于全局训练邮件集中的邮件来自系统所有用户的反馈,因此采用上述方式产生的全局邮件分类知识是所有用户邮件分类标准的综合反映。
2.1.2 用户个性化邮件分类知识学习
系统为每一用户维护属于该用户的个性化训练邮件集:用户s反馈的邮件信息在进入系统全局训练邮件集的同时,也将进入用户s的个性化训练邮件集中,以作为用户s个性化邮件分类知识学习的基础。与全局邮件分类知识的学习过程类似,用户个性化邮件分类知识学习模块以用户个性化训练邮件集中邮件特征词wi(1≤i≤m)在垃圾邮件类Spam和正常邮件类 Ham 下的先验条件概率 Us(wi|Spam)、Us(wi|Ham)作为用户个性化邮件分类知识,其中m为训练邮件集中不同邮件特征词的个数。
对于用户 s 而言,Us(wi|Spam)与 Us(wi|Ham)的取值在一定程度上可以反映邮件特征词wi对用户s邮件手工分类结果的影响:当 Us(wi|Spam)值较大而 Us(wi|Ham)值较小时,则表明wi在垃圾邮件中出现的概率更高,用户s更倾向于将包含wi的邮件判别为垃圾邮件;反之,当Us(wi|Spam)值较小而Us(wi|Ham)值较大时,则表明wi在正常邮件中出现的概率更高,用户s更倾向于将包含wi的邮件判别为正常邮件。因此,当 Us(wi|Spam)与 Us(wi|Ham)两者取值相差较大时,则意味着邮件特征词wi在反映用户s的邮件分类标准方面发挥着更为重要的作用,在对用户s邮件进行分类的过程中应给予重视。基于这一思想,本文在用户s个性化邮件分类知识基础上,提取该用户的兴趣特征词集Is与厌恶特征词集Ds,具体方法如式(5)所示:
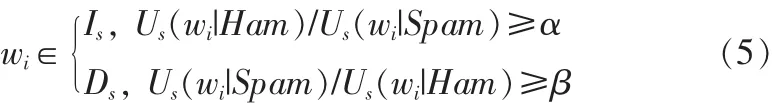
其中α与β分别为兴趣特征词和厌恶特征词的筛选阈值。因此,词集Is与Ds在一定程度上从邮件特征词的角度描述了用户s对邮件内容的主观喜恶。
2.2 邮件分类知识的结合
如前所述,当邮件特征词wi属于用户s的兴趣特征词集Is或厌恶特征词集Ds时,则意味着wi对用户邮件的分类结果具有更大的影响。为此,本文以传统朴素贝叶斯分类为基础,提出一种混合型邮件分类模块,实现全局邮件分类知识与用户个性化邮件分类知识的结合。具体而言,该分类模块将根据用户的不同,在两类邮件分类知识基础上动态调整邮件特征词对邮件分类结果的影响权重,实现邮件特征词在分类过程中的差别化处理。当混合型邮件分类模块在对发往用户s的邮件e进行处理时,其采用的邮件分类依据如式(6)所示:
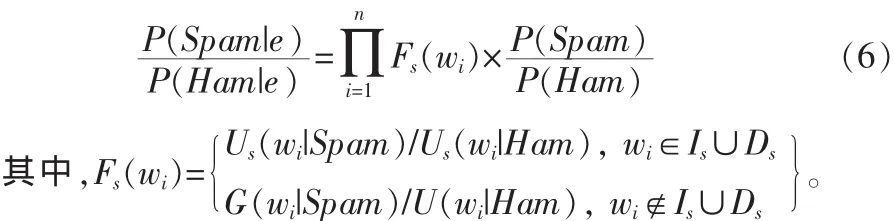
在式(6)中,Fs(wi)代表了邮件特征词 wi对邮件分类结果的影响权重,而其取值取决于wi是否属于用户s的兴趣特征词集和厌恶特征词集:当wi位于Is或Ds之中时,分类模块将根据用户的个性化邮件分类知识确定Fs(wi),以将用户个性化邮件分类标准融入邮件分类过程,在邮件分类中考虑用户对邮件内容的喜恶;反之,当wi不属于Is或Ds时,分类模块将根据全局邮件分类知识确定F(wi),从全局角度衡量wi对邮件分类结果的影响。
3 性能评价
3.1 实验环境
为评估文中提出的基于用户反馈的个性化垃圾邮件过滤方法(Personalized Filtering method based on User’s Feedback,PFUF)在提升邮件分类效果方面的有效性,本文通过仿真实验将该方法与传统朴素贝叶斯分类算法 (Naive Bayesian Classification method,NBC)进行邮件分类性能上的比较。
实验采用的邮件集来自TREC邮件过滤任务2007年公开的邮件数据集trec07p,其中包括25 000封正常邮件和50 000封垃圾邮件。在邮件数据集trec07p中,随机选择5 000封正常邮件与5 000封垃圾邮件构成全局训练邮件集,以供NBC和PFUF方法学习并产生初始的全局邮件分类知识;在另一方面,实验从邮件集剩余邮件中随机选择10 000封邮件作为针对用户s的测试邮件集,以此测试NBC方法和PFUF方法在邮件分类方面的表现。为实现对用户s个性化邮件分类标准的模拟,在实验中用户s会将测试邮件集中符合特定内容特征的垃圾邮件(如特定类型的商业广告邮件)反馈为正常邮件;默认情况下,当用户s接收到一封邮件时,将以40%的概率向系统提供反馈。
实验的其它参数设置如表1所示。

表1 实验参数及其默认值Tab.1 Configuration of experimental parameters
3.2 实验结果
实验将从召回率、查准率和精确率[10]等3方面指标对垃圾邮件过滤技术的邮件分类性能进行评价。
实验1的目的在于比较本文提出的PFUF方法与NBC方法在邮件分类效果方面的差异。实验结果如表2所示:两种方法均取得了较好的邮件分类召回率;而PFUF方法在查准率和精确率方面则优于NBC方法。这一结果表明,PFUF方法在用户s动态反馈基础上所提取的用户个性化邮件分类知识,能够较为准确地反映用户s自身的邮件分类标准;而用户个性化分类知识在邮件分类中的应用,能够减少正常邮件的误判现象,有效改善垃圾邮件过滤的效果。

表2 邮件分类性能比较Tab.2 Comparison of the performance of e-mail classification
实验2的目的在于衡量用户的反馈概率对PFUF方法性能的影响,实验结果如表2所示。与表1结果进行比较可知,当用户的反馈概率较低时,PFUF方法的邮件分类性能接近于朴素贝叶斯分类算法的性能;随着用户反馈概率的增加,PFUF方法的性能将逐渐得到提升;而当反馈概率增加至一定程度后,邮件分类性能的提升幅度将趋于缓和。这一结果表明:用户反馈对于PFUF方法性能的提升至关重要;在另一方面,即使在用户只提供部分反馈时,PFUF方法所提取的用户个性化邮件分类知识仍能较为准确地反映用户的邮件分类标准。
实验3的目的在于衡量兴趣特征词与厌恶特征词筛选参数α、β对PFUF方法性能的影响,在实验中筛选参数α、β取值设置相同。实验结果如表4所示:当筛选参数取值较小或较大时,PFUF方法在查准率和精确率方面的表现并不理想。其原因在于,较小的筛选参数容易致使所选取的邮件特征词过多,不能较为准确地反映用户对邮件内容的喜恶,进而影响邮件分类的效果,导致邮件分类的误判。在另一方面,过大的筛选参数将导致所选取的特征词数量过少,不能较为全面地描述用户自身的邮件分类标准。
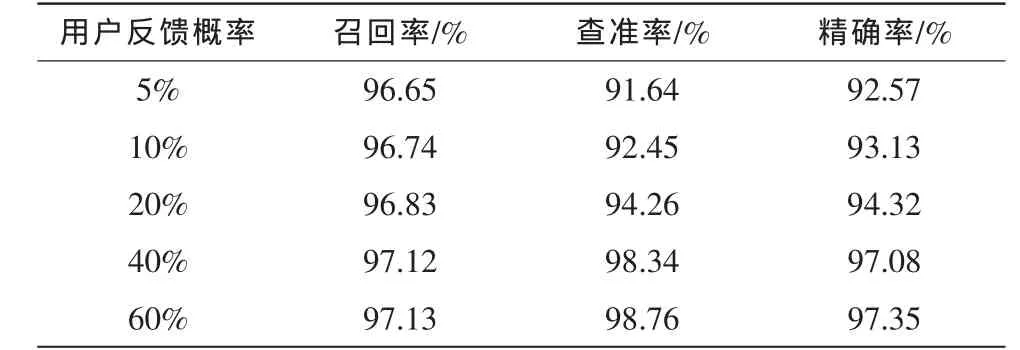
表3 用户反馈概率对PFUF邮件分类性能的影响Tab.3 Impact of the feedback ratio on the performance of PFUF
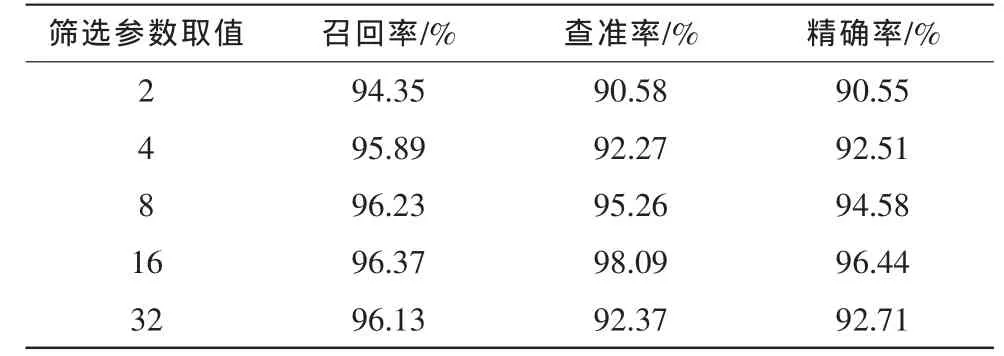
表4 筛选参数取值对PFUF邮件分类性能的影响Tab.4 Impact of the filtering parameters settings on the performance of PFUF
4 结束语
文中提出一种基于用户反馈的个性化垃圾邮件过滤方法,一方面,将用户反馈应用于全局邮件分类标准和用户个性化邮件分类标准的提取与更新;在另一方面,在朴素贝叶斯分类模型基础上实现全局邮件分类标准与用户个性化邮件分类标准的有机结合,同时从全局和用户个体两方面综合判别邮件是否为垃圾邮件。实验结果表明,该方法能够改进传统朴素贝叶斯分类算法在实现用户邮件个性化过滤方面的不足,有效提高邮件分类效果。
文中提出方法的下一步改进方向主要包括:针对电子邮件应用的特点,设计适合互联网环境的电子邮件用户反馈机制等方面。
[1]中国互联网协会反垃圾邮件(信息)中心.2010年第四季度中国反垃圾邮件状况调查报告 [EB/OL].[2010-12-01].http://www.12321.cn/pdf/2010_04_report.pdf.
[2]Friedman N,Geiger D.Bayesian network classifiers[J].Machine Learning,1997,29(2):131-163.
[3]Schneider K.A comparison of event models for naive Bayes anti-spam e-mail filtering[C]//Proceedings of 10th Conference of the European Chapter of the Association for Computational Linguistics.Budapest, Hungary:IEEE Press,2003:307-314.
[4]Drucker H,Wu D,Vapnik V.Support vector machines for spamcategorization[J].IEEETransactionson Neural Networks,1999,20(5):1048-1054.
[5]邓春燕,陶多秀,吕跃进.粗糙集与决策树在电子邮件分类与过滤中的应用[J].计算机工程与应用,2009(6):138-140.DENG Chun-yan,TAO Duo-xiu,LV Yue-jin.Application of rough set and decision tree in e-mail classification and filtering[J].Computer Engineering and Applications,2009,45(16):138-140.
[6]Thiago S,Guzella W.A review of machine learning approaches to spam filtering[J].Expert Systems with Applications,2009 36(7):10206-10222.
[7]Lai C.An empirical study of three machine learning methods for spam filtering[J].Knowledge-based System,2007,20(3):249-254.
[8]王斌,潘文锋.基于内容的垃圾邮件过滤技术综述[J].中文信息学报,2005,19(5):4-5.WANG Bin,PAN Wen-feng.A survey of conten-based antispam email filtering[J].Journal of Chinese Information Processing,2005,19(5):4-5.
[9]Yih W,Mccann R,Kolcz A.Improving spam filtering by detecting gray mail[C]//Proceedings of Third Conference on Email and AntiSpam (CEAS).California, USA:IEEE Press,2007.
