关联数据的消费技术及实现*
2013-12-06夏翠娟刘炜
□夏翠娟 刘炜
1 概述
Web上关联数据的发布正呈井喷之势,截至目前,最新版的DBPedia3.8已发布了377万件事物(Thing)的数据,其中235万基于知识本体组织,包括个人(Person)、地点(Place)、机构组织(Organization)、物种和疾病等实体(Entity),所使用的知识本体包含359个类、800个对象属性、859个数据类型属性、2347种本体映射,提供111种语言的本地化版本。Freebase则有2300余万实体,而语义搜索引擎sameAs.org则抓取了4300万实体,LOD项目中著名的关联数据云已经包含了328个关联数据集(Linked Data Sets),涵盖了生物医学、政府、图书馆、教育机构等多个领域。关联数据已成为整个全球性数据空间不可或缺的一部分,更重要的是,关联数据作为一种分布式环境下,基于语义关系的信息资源集成方式,使得Web上分布着饱含语义的、海量的、相互关联的数据,这些数据如果得到充分利用,会产生难以估量的巨大价值。
如何利用Web上的关联数据,需要对关联数据的消费(Consuming)方式和技术有深入的了解。发布和消费是关联数据相关技术的两个方面,发布的目的即是为了消费,有的是在内部消费,用于资源管理、整序、发现和重用等,典型的例子如BBC的关联数据应用[1];有的是开放给整个互联网进行消费,如DBPedia、Freebase等大型公共关联数据集;有的同时兼具消费者和提供者双重角色,如各种语义搜索引擎。关联数据的消费技术主要涉及关联数据的访问、获取、发现、查询、交换、传输、处理和利用等消费过程中所相关的各类实现方式、技术标准及工具平台。关联数据的消费方式与数据源所提供的消费接口密切相关,目前关联数据源大致可分为两种:语义搜索引擎和关联数据集。本文总结了关联数据的消费技术及相关标准,对上述两种关联数据源所提供的消费接口进行了调研,通过几个案例来说明关联数据消费的实现途径,既考虑到关联数据消费方的技术需求,也为关联数据的发布提供参考方案。
2 研究与应用现状
对于关联数据消费方式和技术的研究与应用主要是国外,国内更多的关注还在关联数据的发布层面,在消费层面的关注较少,黄永文的《关联数据驱动的Web应用研究》一文分析了国内外基于关联数据的7种Web应用类型,最后从用户界面和交互方面、关联关系的有效性、数据融合和模式映射、关联开放数据的许可4个方面讨论了关联数据应用面临的挑战[2]。白海燕的《关联数据与DBPedia实例分析》一文中以DBPedia为例总结出关联数据的三种Web获取方式和建立自动关联的两类常见算法[3]。另外在2012年7月上海图书馆举办的“从文献编目到知识编码:关联数据技术与应用”专题研讨班上,林海青的《关联书目数据:发布、查询、消费及混搭》,对关联数据消费技术如查询和混搭做了普及性的报告[4],夏翠娟的报告《关联数据的实现技术及案例》对关联数据消费的流程、技术、应用体系架构及相关工具平台做了梳理和分析[5]。虽然关联数据的消费在国内的研究层面引起了注意,但进行深入研究与利用的还很少见,较为有影响力的是南京大学Websoft研究团队开发的语义搜索引擎Falcons,可以查询对象、概念、知识本体和文档。
在国外,从研究方面来看,2009年Tom Heath在其LinkedData:EvolvingtheWebintoaGlobal DataSpace一书中,系统地论述了关联数据“消费”的概念、消费方式、构建关联数据应用的技术和原则、在关联数据消费过程中应解决的问题如数据质量等,书中用单独一章来谈关联数据的消费,包括目前关联数据消费的现状、关联数据应用的体系架构及其不同的模式、关联数据混搭应用的开发、数据发布者和数据消费者以及第三方应该如何联合起来以促进 “数据的网络(Web of Data)”的一致性和整体性。在该书中,将关联数据的消费方式分为通用的和领域的两种,通用的消费方式包括浏览和检索,即基于如Disco、Tabulator、Marbles等语义浏览器的浏览,和基于 SWSE、Swoogle[6,7]、Falcons、sig.ma等语义搜索引擎的检索[8]。使用语义浏览器的关联数据消费者一般是人而非机器,而语义搜索引擎则可同时对人和机器服务,大部分的语义搜索引擎都提供面向人的界面和面向机器的数据消费接口。领域的则根据不同的领域数据源所提供的消费方式而多种多样,取决于数据源(包括关联数据集和语义搜索引擎)提供何种消费接口。另一方面,自2010年起,关联数据的消费(Consuming Linked Data,CoLD)作为国际语义网大会(ISWC)的一个专题会议,已连续举行了两届,第三届将在今年继续举行,在CoLD专题会上,与会者主要展示一些消费工具和平台的原理、功能及使用方法,如Christian Bizer等的用于不同词表映射的R2R框架、用于关联关系发现的SILK框架、用于关联数据整合的LDIF框架等;还有应用案例的演示、经验的分享,如探讨联合消费多个关联数据集的技术方案。在2011年的CoLD会上,还提到了封闭(Closed)关联数据和绿色(Green)的关联数据的概念。
从技术标准和工具平台方面来看,关联数据作为语义网的一种轻量级的实现方式,早期的语义网研究成果如RDF数据模型、RDF查询语言Sparql、元数据(Metadata)、知识本体(Ontology)的相关理论和技术是它的基础,致力于语义网研究和应用推广的机构如 W3C、DERI、LATC、还有许多大学研究机构等,不仅参与制定和维护如RDF、Sparql语言、Sparql协议、OWL本体语言等基础的技术标准,近年来基于这些技术标准不断地开发出各种工具和平台致力于关联数据的发布、消费和利用,就消费来说,从语义浏览器如Tabulator、Disco,到语义爬虫和语义搜索引擎如 Sig.ma、SWSE、Swoogle、Falcons,到关联发现整合平台如SILK、LIMES、LDIF等,这些工具绝大部分是开源的,依据一定的开源协议提供免费下载。
从应用方面来看,Web上公开的大型关联数据集如DBPedia、Freebase由于其海量的数据、多样的消费接口,已成为全球性的数据消费中心,在各个领域得到利用,尤其是政府信息公开、地理信息、生命科学、图书馆档案馆博物馆等,不仅作为数据的提供方,更作为数据的消费方,消费来自DBPedia、Freebase和其他领域性关联数据集中的数据,如西班牙国家图书馆的关联书目数据,就用owl:sameAs和rdfs:seeAlso关联到DBPedia和美国国会图书馆的虚拟国际规范档(Viaf)。关联数据的消费也渗入移动领域,一个典型的例子是用于iPhone等智能手机的DBPedia Mobile,它消费DBPedia的地点信息帮助旅行者探索某个城市。不仅集成DBPedia上现有的RDF数据,还支持用户即时发布自己的数据,并以RDF格式保存在DBPedia上,以供其他用户使用。这在很大程度要归功于DBPedia所提供的强大的数据接口,包括数据消费接口和数据输入接口。
3 关联数据的消费技术
从流程来看,关联数据的消费涉及到数据的访问和获取、发现、查询、交换和传输、处理和利用等方面,本文在此对这个过程中所涉及到的基本技术做一个梳理和总结。
3.1 数据的访问和获取
对关联数据的一种简单直接的访问和获取方式是根据关联数据的四原则,直接访问资源对象的URI来获取关于资源对象的信息。关联数据建立在URI、HTTP等基础的互联网技术之上,每一个资源对象(Object)都有全球唯一的HTTP URI,它集标识功能和定位功能于一身,并且是可“解引(Dereferenced)”的,即可通过访问资源对象的URI来获取关于这个资源对象的信息,这些信息可以是一个html页面,也可以是基于某种序列化格式的RDF数据。在《发布关联数据的最佳实践》一文中提到:“解引”可通过 HTTP协议的“内容协商(Content Negotiation)”机制来实现,内容协商机制能根据客户端请求的类型(一般在HTTP Header信息中指定)返回相应格式的数据,若是普通浏览器,服务器会自动返回HTML数据,若是语义浏览器,则返回RDF数据。该文还推荐了两种最佳实践,即带#(Hash)的URI的实现方式和303转向的实现方式,如:http://linkeddata.openlinksw.com/about/Berlin#this就是一个带“#”的URI[9]。图1是用PHP实现303转向的一个例子,首先要保证服务器能接受的MIME类型包含客户端所要请求的类型,如application/rdf+xml,如在浏览器中输入http://lod.library.sh.cn/test303/foaf,返回 HTML数据,输入http://lod.library.sh.cn/test303/foaf.rdf,则返回RDF/XML数据。
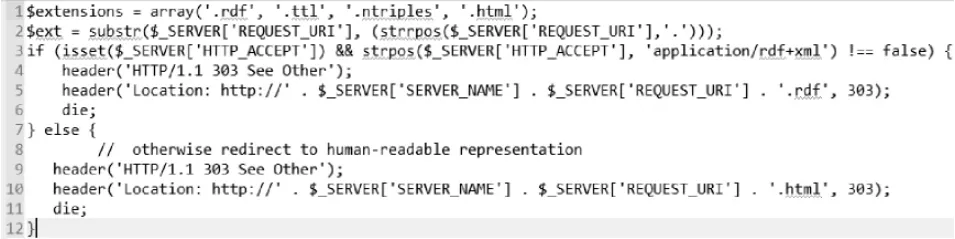
图1 用PHP实现303转向
对关联数据的另一种访问和获取方式是利用数据集或语义搜索引擎提供的消费接口:如Sparql端点、Restful Web Services接口、OpenSearch/SRU、各种客户端开发库、专用API等,将在本文第4部分详细分析。
3.2 数据的发现
通常把同类数据的集合称作一个数据集(Dataset),目前Web上的关联数据大多以数据集的形式发布,当Web上的关联数据集越来越多时,就需要引入一种发现机制,作为数据发布者和数据消费者之间的桥梁,如建立一个注册机构或公开目录,提供关于数据集的数据,即数据集的元数据,就是有助于数据被发现的途径之一,尤其是机器的自动发现。VoID(Vocabulary of Interlinked Datasets)是一个基于RDFs的词表,定义了描述关联数据集的元数据方案[10]。VoID包括四个方面的元数据,其中“访问(Access)”元数据用于描述RDF数据使用何种协议访问,结构性元数据用于描述数据集的结构和模式,利于数据的查询和整合,对数据集之间的关系的描述有助于理解多个数据集之间的关系和不同的数据集之间如何整合利用。thedatahub.org就是这样一个为数据集提供注册机制的公开目录,截至目前,thedatahub.org的子集 LOD(Linking Open Data Cloud)已建立了一个包含328个相互关联的关联数据集的公开目录,每个关联数据集都用VoID描述,如数据打包下载的URL地址,Sparql端点的URL地址,API的URL地址等信息,用于关联数据的发现和消费。DBPedia也有自己的VoID描述。
3.3 数据的查询
根据关联数据的四原则,数据要尽量采用RDF数据模型。RDF数据通常表现为一堆三元组的集合,描述某个资源的一个或多个三元组称为一个RDF图(Graph)。消费方要查询RDF图中的数据单元并对其进行处理,需要借助专用的RDF查询语言,如W3C的Sparql,Sparql已在2008年1月成为W3C的推荐标准,是目前使用最为广泛的RDF查询语言[11]。Sparql允许从RDF库(通常包含多个RDF图)中查询三元组,与关系数据库相比,RDF库是一个庞大无序的三元组集合,RDF数据没有外键和主键,只有URI,Sparql查询通过定义匹配三元组的RDF图模式(Graph Pattern)来完成,RDF图是用一个全球可定位的HTTP URI来唯一标识,而不是物理意义上的数据库名和表名,如查询URI为<http://lod.library.sh.cn:8080/bib>这个 RDF图中dc:creator为“巴金”的所有主语的Sparql语句为:

这种方式简单而直接,无需了解底层的数据结构,甚至可以指定多个不同 URI(RDF图)同时查询:

Sparql查询结果也是URI,而URI是 Web的标准引用格式,通过URI,可以连接到Web上的任何数据,这就突破了关系数据库查询语言一次只能在单个数据库中查询的局限,整个Web于Sparql语言而言是一个巨大的整体的数据空间。基于Sparql语言和Sparql协议的Sparql端点技术,为查询关联数据集提供了标准的接口,可供人机检索,为大部分关联数据集和语义搜索引擎采用,在此基础上,出现了基于多个Sparql端点的联邦Sparql检索引擎,可整合不同的数据源的数据。另外,还有一些非标准的RDF查询语言,如Freebase定义了一种类似于Sparql的查询语言 MQL,专门用于查询Freebase中的数据。Sindice为自己的消费接口定义了专用的查询语言Sindice Query Language。
3.4 数据的序列化
RDF只是一种抽象的数据模型,而不是一种具体的数据格式,要使RDF数据成为机器可读的数据,就需要对其进行序列化(Serialization)。序列化的RDF数据可以通过HTTP协议传输和交换,这样应用程序可以对这些数据进行远程获取和处理,有利于不同的操作系统、程序语言之间的互操作。目前有诸如 RDF/XML,RDFa/JSON/JSONP,N3,Turtle等不同的序列化格式,其中RDF/XML和RDFa是W3C的推荐标准,其他的序列化格式则为满足不同的具体需求而设计。RDF/XML是RDF模型最为经典的序列化方式,与XML Schema配合使用,基于XML编码的RDF甚至能实现不同应用领域之间的互操作,但RDF/XML有着不利于人读和写的缺点。RDFa是将RDF三元组嵌入HTML文档的一种序列化格式,适用于能方便修改HTML文档模板但难以介入系统体系架构的应用,如Drupal等内容管理系统[12],这种序列化方式不能很好地支持内容协商机制。Turtle是一种纯文本的RDF序列化格式,适用于人读和写,N-Triples(N3)是Turtle的一个子集,因其规定每一个三元组中的主体、谓词、客体都必须用完整的URI来表示,如:<http://lod.library.sh.cn:8080/bib/resource/PersonA000001> <http://www.w3.org/2002/07/owl#sameAs> < http://dbpedia.org/resource/Ba_Jin/>。所以与 Turtle和 RDF/XML相比,文件会比较大,但这也是它的优点,因为它的每一行都可以单独解析,同时它也很适合压缩以减少在传输交换过程中的网络流量,这种特性使得N3成为适合传输大型关联数据包的一种序列化格式。JSON(JavaScript Object Notation)是一种适合于程序处理的RDF序列化格式,大部分程序语言本身就提供处理JSON数据的功能,如JavaScript和PHP,将RDF数据发布成JSON格式可使程序开发员无需安装额外的开发包就能处理RDF数据。目前一些关联数据消费接口一般都会提供一种或几种格式的数据以内容协商的方式返回给客户端,如DBPedia的Sparql端点就提供RDF/XML,JSON,N3等多种数据格式。而一些面向机器的消费接口则以JSON格式为主。
3.5 数据的处理和利用
在数据消费的过程中,访问和获取、发现和查询、传输和交换的最终目的是为了将数据拿来为我所用。一般有这样几种利用方式:(1)为本地数据建立外部关联,如上文提到的西班牙国家图书馆的关联书目数据;(2)多种数据混搭建立新的应用和服务,如社会书签工具Faviki,利用DBPedia、Freebase等作为背景知识库,通过关联数据的URI技术来消除歧义,提供分主题组织的标签导航服务;(3)发现数据之间的关联关系建立知识地图,如生命科学领域的关联数据应用Diseasome Map,整合来自不同的生命科学领域的数据资源,生成一个相互关联的病毒基因网络;(4)进行语义挖掘和推理发现有用的信息,如Researcher Map是一个基于FOAF的关联数据应用,通过DBPedia和DBLP关联数据集中的RDF Links来发现德国教授的个人信息。在数据处理和利用的过程中,要对数据查询结果提取和重组、分析和计算,需要基于一些已有的标准规范,也需要一些开发包来支持。在标准规范层面,一些早期的语义网技术的成果如 RDF/XML、Sparql、OWL,其标准的制订和技术的应用已经成熟;在应用开发层面,一些流行的编程语言都有处理RDF数据的开发包,如 Java的 Jena、Sesame、Kowari ,PHP 的RAP,以支持Sparql协议向Sparql端点发起Sparql查询、处理查询结果、读写序列化的RDF数据文件、操作原生RDF数据库等[13]。还有一些集成的客户端开发库如PHP的ARC2,被Drupal等开源平台集成,作为后台关系数据库和前台Sparql端点之间的中间件,提供实时的Sparql查询到SQL查询、SQL查询结果到Sparql查询结果的双向转换。在数据处理的过程中,不可避免会涉及到不同本体或词表间的映射,R2R词表映射框架可以帮助关联数据应用在Web上发现一些未知的术语、术语之间的映射,并利用这些映射将Web上的数据转换到应用的宿主词汇表,有助于发现异构数据之间的关系。数据混搭语言MashQL提供了另一种整合数据的思路,它将整个Web看成一个大的数据库,每个数据源看成是数据库中的一张表,消费者可以不必关心各个数据源所用的词表和技术细节[14]。
4 关联数据的消费接口分析
一个优秀的关联数据集,在发布时就应考虑如何被消费,尽可能地提供便于数据消费者调用的消费接口,大型的关联数据集如DBPedia、Freebase就提供多种方式、多种功能、适应不同需求的数据消费接口。一些语义搜索引擎后台有着不断更新壮大的海量RDF数据,在Web上有供人检索的入口,也有供机器获取数据的开放数据接口。一些数据集成管理平台本身的功能模块可提供不同接口以支持关联数据集的消费。笔者调研的DBPedia、Freebase、Nature.com、Data.gov、VIAF 等典型的关联数据集,<sameAs.org>、SWSE、Sindice、Swoogle、Falcons等流行的语义搜索引擎,CKAN、Openlink Software、Tailis Plateform等大型数据集成管理平台所提供的消费方式和消费接口主要有这几种:批量下载、Sparql端点、RESTful Web Service接口、OpenSearch/SRU、专用 Web Service接口、专用API、专用客户端开发包、插件(Plugin)/小工具(Widget)。目前关联数据所提供的消费接口有如上所列的多种或全部,每个调研对象的详细情况见表1、表2、表3。
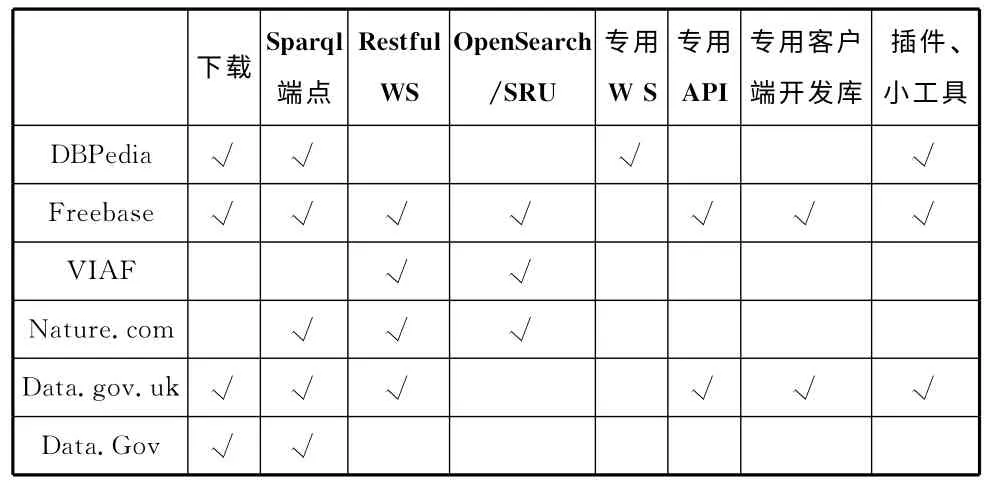
表1 关联数据集(Linked Data Sets)的消费接口
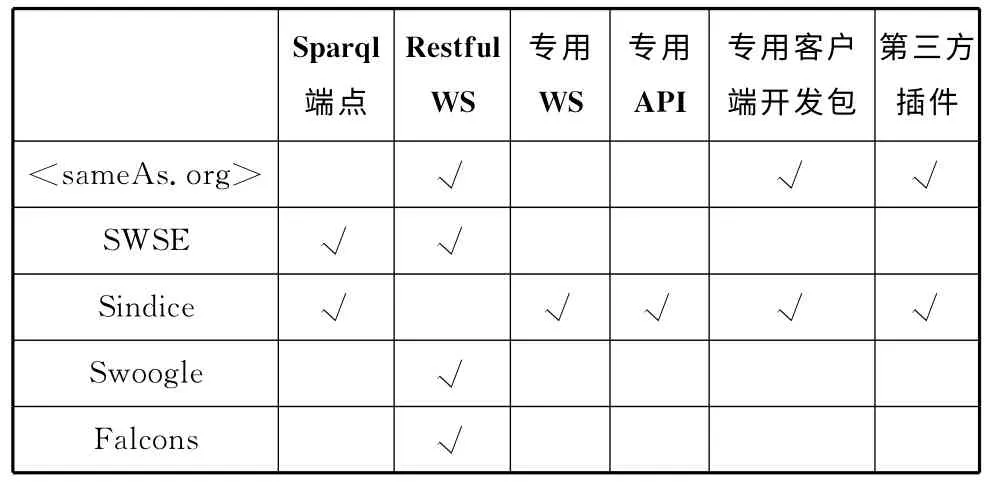
表2 语义搜索引擎(Semantic Search Engine)的消费接口
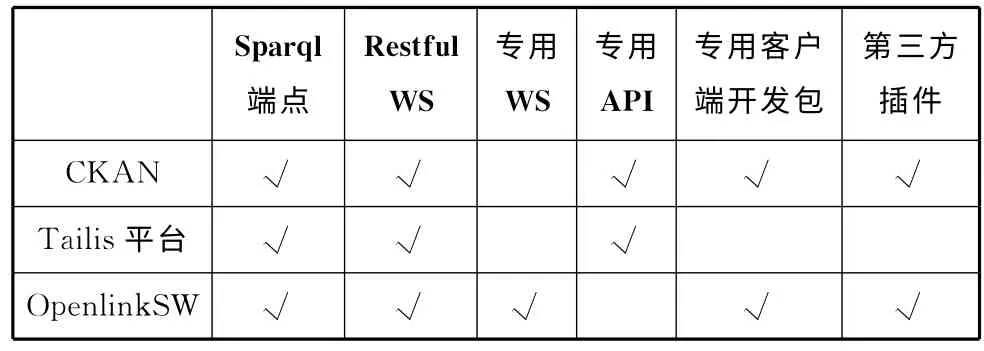
表3 工具/平台所提供的消费接口
批量下载。早期的关联数据集一般会将所有的RDF数据打包,在 Web上提供批量下载地址。作为数据消费方,需要将这些打包的RDF数据下载到本地,在本地存储,供本地系统重用这些数据。目前,仍有许多关联数据集沿用这一做法,如DBPedia、Freebase、CKAN、VIAF、Data.gov.uk等。DBPedia以每2-3个月更新一次的频率发布了多个版本,2012年8月6日发布了3.8版,相较于3.7版,在数据量、数据的内容范围、组织方式上都有一些增加和改进。CKAN则提供几种方式让消费方自己制作CKAN数据的打包文件。VIAF提供RDF/XML,MARC21/XML等多种格式的打包文件批量下载。有的关联数据发布平台提供RDF数据包的打包工具,如D2RServer的Dump-rdf,可将整个关系数据库转换为RDF数据包。这种批量下载的消费方式要求数据提供方和数据消费方都要考虑到数据集的更新频率,发布方要考虑到数据发布的版本管理,消费方要密切关注数据发布的动态,考虑是否需要及时更新本地数据。
Sparql端点是目前最为流行的关联数据消费接口之一,几乎大部分的关联数据集如DBPedia、na-ture.com、BBC都提供这种消费接口,大部分的关联数据发布工具/平台如D2RServer、Drupal、Pubby、LDIF、Virtuoso等都提供Sparql端点的技术支持,可以说Sparql端点是关联数据发布时的标准配置。它既可提供Web界面用于人的浏览,也是机器访问和获取数据的接口,人通过普通浏览器访问关联数据集的 Sparql端点网址(如:http://DBpedia.org/sparql),输入并编辑Sparql查询语言,选择所需的数据编码格式,点击一个按钮即可获得返回结果的RDF数据。对于机器来说,要通过Sparql端点访问或获取某一关联数据集的数据,通常需要借助处理Sparql查询的客户端开发库如Jena的ARQ。相比而言,基于Sparql端点的消费方式对于消费方来说有较高的技术门槛,要求消费方进行一定的编程工作,对于发布方来说则无此顾虑,因为大多数关联数据发布工具、平台都以提供Sparql端点为标准配置。
Restful Web Services是一种轻量级的Web Services,利用URI、HTTP等简单通用的Web标准及技术,对数据进行读取、写入、修改、删除等操作,是目前最为流行的数据接口,大部分的数据集、语义搜索引擎、关联数据管理平台都提供这种数据消费方式,见表1、表2、表3。一种简单的基于Restful Web Services的数据消费方式是数据消费方直接访问某一资源对象的URI,通过内容协商机制,获取该资源对象某种指定编码格式的RDF描述。例如,当数据消费方需要获取VIAF的某一资源对象数据时,可以直接访问该资源对象的 URI:http://www.viaf.org/viaf/75785466/,若需返回 XML 格式 的 数 据,则 访 问 http://www.viaf.org/viaf/75785466.xml,若需返回纯rdf数据,则访问http://www.viaf.org/viaf/75785466.rdf。表4 是VIAF的RESTful Web Service请求和响应的对照表。
更为复杂的Restful Web Services利用URL传递事先定义的参数或专用的结构化检索语言向服务器发送数据查询或处理请求,服务器返回既定或由客户端指定的内容和格式。例如VIAF的AutoSuggest接口,其语法为:http://viaf.org/viaf/AutoSuggest?query=[searchTerms]&callback[optionalCallback-Name],返回数据的格式为JSON。DBPedia的Lookup Service,其 语 法 为:http://lookup.dbpedia.org/api/search.asmx/<API>?<parameters>。其中<API>是指从DBPedia申请的API Key,用于权限控制。还有Freebase的各种Search API如根据关键词查找实体的Search Service、获取一个实体的概要信息的Topic API、获取实体的简单文本型描述信息的Text Service,获取图像实体的拇指图的Image Service。其中Search Service的语法为:https://www.googleapis.com/freebase/v1/search?q=bob&key=<YOUR_API_KEY>。Sindice的Search API(v3)使用自定义的查询语言详细定义了十多种参数,包括关键词、词表及属性、返回结果的格式等,如:http://api.sindice.com/v3/search?q=Rome&fq=class:city&format=json。Sindice基于其自定义的Sindice Query Language的API支持关键字匹配、三元组查询和各种过滤策略。Tailis平台的Augment Service API能对来自不同数据集的返回结果进行合并处理。Tailis平台的Full Text Searching API不仅可以利用自定义的全文检索语言通过在URL传递事先定义好的参数对数据集中的数据进行全文检索,还可以传递Sparql查询语言来查询数据集中的数据,甚至可以对数据集中的数据进行修改和删除。这种方式对于消费方来说使用方便,但发布方需要考虑到数据传输中的安全问题,如是否需要数据加密和权限控制。
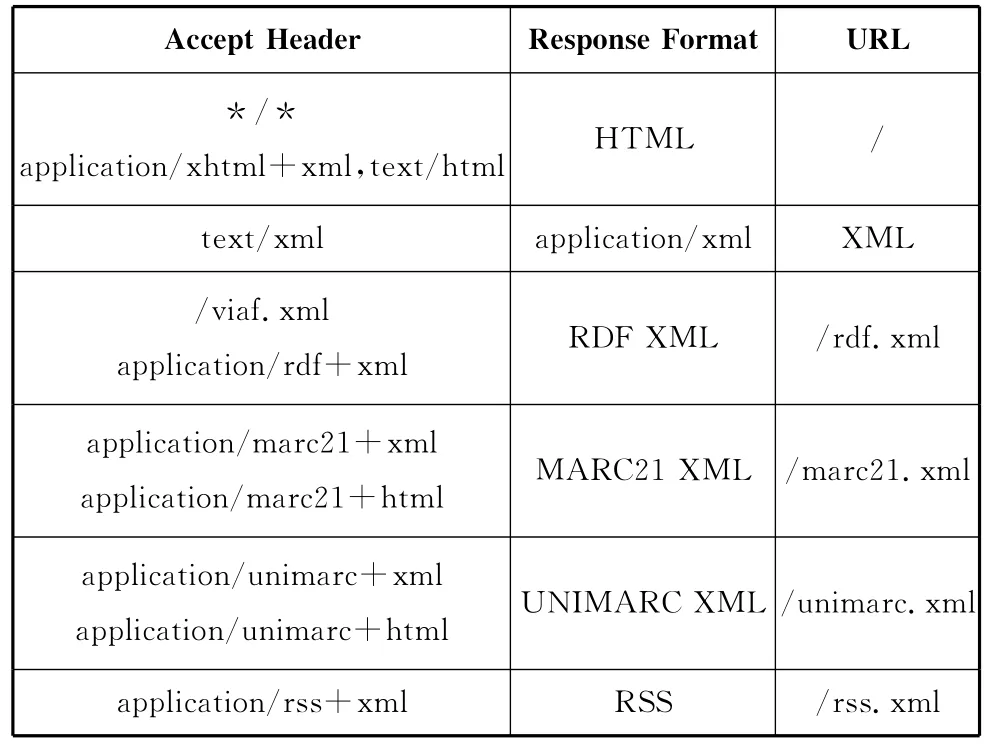
表4 OCLC viaf的请求/响应对照表[15]
OpenSearch/SRU。OpenSearch的是Amazon.com子公司A9公司所提出的一种分享查询结果的简单的格式标准,2005年3月首次在O'Reilly新兴技术会议上提出OpenSearch1.0版本,目前使用版本为1.1版。OpenSearch与国会图书馆的结构化查询规范SRU结合,同样是利用URL传递参数返回指定格式的结果数据,但这里的参数不是自定义而是标准的结构化查询语言CQL,如CKAN和VIAF提供OpenSearch接口,而nature.com则提供OpenSearch和SRU整合的消费接口[16]。VIAF的OpenSearch 查 询 举 例:http://viaf.org/viaf/search?query=cql.any+all+%22[searchTerms]%22+&maximumRecords=100&startRecord=[startIndex]&sortKeys=holdingscount&httpAccept=application/rss%2bxml,VIAF还提供一个可视化的界面,只需要选择一些参数的值,系统会自动生成包含CQL查询的OpenSearch URL。这种方式建立在OpenSearch、SRU、CQL等标准和技术之上,对于消费方来说,无需进行复杂的编程运算,又能灵活方便地直接获取关联数据集中的数据单元,但需要掌握CQL语言。对于发布方来说,可以植入自定义的认证和授权规则,有利于数据的安全和版权控制。
专用Web Service接口。如DBPedia所提供的“公开分面 Web Services 接口”,http://DBpedia.org/fct/service建立在 Openlink Software公司的Virtuoso分面 Web Services接口基础上,该 Web Services接口定义了一系列的HTML标签,在这些标签中可以写入Sparql语言。当在本地Web应用的HTML网页上嵌入这些标签时,服务器会返回所请求结果的XML格式数据,供本地网页用自定义的XSLT为用户提供数据展示界面[17]。
专用API。这种方式是发布方通过API来精心包装自己的数据,甚至定义专用的查询语言,开发出专用于特定数据获取和处理的方法以供消费方在编程时调用。一般会详细定义输入参数和返回结果,还有对返回结果进行处理的方法,同时有可靠的授权控制机制如API Key、Web ID等。如CKAN的各种API,允许消费方传入指定的属性值,返回特定的结果。还有Freebase基于其MQL的各种API。这种方式需要发布方进行大量的开发工作,将数据访问、查询和处理过程封装起来,对用户透明,只根据用户的输入参数按需提供结果数据,而消费方需要深入了解API的使用方法,对发布方和消费方都有较高的技术门槛。
专用客户端开发包。一些大型的关联数据集为了满足不同消费者的个性化需求,为数据消费提供无限的可能,开发出专用的客户端开发包,供程序员编程使用。如Freebase提供JavaScript、Flash、Python、Perl、PHP、Ruby、Clojure、Java、NET、Objective-C 10种语言的客户端开发包,同时提供基于JavaScript的Arce集成开发平台,有着大量利用Freebase的数据构建本地应用的开发工具。CKAN也提供专用的客户端开发库,目前有Java、PHP、JavaScript、Python、Rubby,PERL6种语言的客户端开发库,利用这些客户端开发包,消费方可以灵活地获取、使用、甚至修改CKAN中的数据,进行复杂的计算。语义搜索引擎sameAs.org提供Java开发包sameas4j,Sindice提供Java和Pyhton等简单的工具包。
插件、小工具。在Web2.0时代,插件和小工具以其灵活、小巧,可自由嵌入等特点风行一时,这些优点在语义网世界继续发扬光大,如thedatahub.org的基于Chrome浏览器的插件JSONView for Chrome,可以在Chrome浏览器上浏览它的数据,还有 Google Refine CKAN Extension,DBPedia 的DBpedia Lookup服务插件,可以装在本地服务器上,其功能是通过关键词或简写查找某一实体的URI。Freebase用于移动设备上的App如Freebase Explorer Android App。Sindice的基于Drupal的MOAT module,可以在Drupal站点中消费Sindice提供的数据。
5 技术实现案例
案例1:直接利用外部数据的URI为本地数据添加外链。
要向本地数据集——名人规范档中的实体添加到DBPedia的外链,用owl:sameAs作关联。首先了解到DBPedia中对某一人(Person)的实体的URI命名规则是 “http://dbpedia.org/resource/”+ 人名,若是中国人,人名是姓名的拼音,如巴金的URI是http://dbpedia.org/resource/Ba_Jin/,这样,就可以把本地数据集中的巴金用owl:sameAs链接到DBPedia的巴金,用三元组来表示,即:<http://lod.library.sh.cn:8080/bib/resource/PersonA000001>owl:sameAs<http://dbpedia.org/resource/Ba_Jin/>。其他的人则可以由此规则类推,只要计算出本地数据集中所有人物实体的姓名的拼音,如矛盾的拼音是Mao_Dun,其 URI就 是 http://dbpedia.org/resource/Mao_Dun/,采用这种数据消费方式,需要数据发布方有明晰的URI命名规则或者提供根据关键词查询URI的服务,数据消费方也要对目标关联数据集的URI命名规则或URI获取方式有所了解,才能准确地获知某一资源对象的URI。
案例2:利用Restful Web Services获取数据。
要获取本地数据集中的实体在VIAF中的URI,首先了解到VIAF的URI命名规则是“http://viaf.org/viaf/”+VIAF ID,只要获取了某一实体的VIAF ID,就可以知道这一实体在VIAF中的URI。这时可以用VIAF的AutoSuggest接口,获取本地数据集中某一实体在VIAF中的同一实体的VIAF ID,以巴金为例,在URL中传递参数bajin,http://viaf.org/viaf/AutoSuggest?query=bajin,返回的结果为JSON格式的数据,如下:

上述结果中包括viafid这个属性的值19673501,此即巴金的VIAF ID,由此可知巴金在VIAF 中 的 URI 为 http://viaf.org/viaf/19673501。可以用程序读取所返回的JSON数据,取得VIAF ID的值。
案例3 基于Java利用ARQ客户端编程向多个Sparql端点获取数据。
已知DBPedia的Sparql端点的URL地址为:http://dbpedia.org/sparql。利用 ARQ 开发包,它支持指定关联数据集的Sparql端点的地址,就可以远程访问和获取数据。如下为部分程序片段:


6 总结与展望
基于关联数据技术框架的数据消费可以做到真正意义上的分布式和跨数据源的查询,实现基于语义的全Web集成。各种大型公开的关联数据集和语义搜索引擎提供了海量的富含语义的结构化数据,成为Web上的公共数据中心,多样化的数据消费接口为数据消费者利用数据带来了无限的可能。但是,目前关联数据的消费接口,除了Sparql端点外,其他的方式包括Restful Web Services接口,尤其是各种专用的API,因其使用方法各不相同,有的还异常复杂,尚未形成统一的标准,对消费方来说颇为不便,成为阻止关联数据得到有效利用的障碍之一。在系统和平台的开发上,进入此领域的大型商业公司并不多,为大英图书馆提供关联数据体系架构的Tailis公司在2012年宣布停止提供关联数据相关服务,反而在大学和研究机构,涌现出越来越多的开源项目,但对于普通消费者来说,开源软件的使用仍然存在着较高的技术门槛。随着关联数据的发布越来越呈现出分布式、虚拟化、关联化的特征,关联数据的消费也将更多地依赖于接口的标准化。另一方面,数据来源跟踪和数据质量检测的机制的建立,是来自技术之外的挑战。
1 刘炜.关联数据:概念、技术及应用展望.大学图书馆学报,2011(2):5-12
2 黄永文.关联数据驱动的Web应用研究.图书馆杂志,2010(7):55-59
3 白海燕.关联数据及DBPedia实例分析.现代图书情报技术,2010(3):33-39
4 林海青.关联书目数据:发布、查询、消费及混搭.“从文献编目到知识编码:关联数据技术与应用”专题研讨班.2012,7.[2012-08-21].http://conf.library.sh.cn/sites/default/files/LBD 的 查询消费及混搭_林海青.pdf
5 夏翠娟.关联数据的技术实现及案例.“从文献编目到知识编码:关联数据技术与应用”专题研讨班.2012,7.[2012-08-21].http://conf.library.sh.cn/sites/default/files/LD的技术实现及案例_夏翠娟.pdf
6 Li Ding,etc.Swoogle:A Search and Metadata Engine for the Semantic Web,the Thirteenth ACM Conference on Information and Knowledge Management,November 2004.
7 Li Ding,etc.Finding and Ranking Knowledge on the Semantic Web,in the Proceedings of the 4th International Semantic Web Conference,November 2005
8 Tom Heath,Christian Bizer.Linked Data:Evolving the Web into a Global Data Space.Synthesis Lectures on the Semantic Web:Theory and Technology,1:1,1-136
9 Diego Berrueta,Jon Phipps.Best Practice Recipes for Publishing RDF Vocabularies.[2012-08-31].http://www.w3.org/TR/swbp-vocab-pub/
10 Keith Alexander,etc.Describing Linked Datasets with the VoID Vocabulary.[2012-08-31].http://www.w3.org/TR/void/.
11 Olaf Hartig,Christian Bizer,Johann-Christoph Freytag.Executing Sparql Queries over the Web of Linked Data.Lecture Notes in Computer Science,2009,Volume 5823/2009:293-309.
12 夏翠娟等.关联数据的发布技术及实现——以Drupal为例.中国图书馆学报,2012(1):49-57
13 Christian Bizer,Daniel Westphal.Developers Guide to Semantic Web Toolkits for different Programming Languages.[2012-08- 21 ].http://www. wiwiss.fu-berlin. de/suhl/bizer/toolkits/06062006/
14 Mustafa Jarrar,Marios D.Dikaiakos.A Data Mashup Language for the Data Web.[2012-08-31].http://events.linkeddata.org/ldow2009/papers/ldow2009_paper14.pdf
15 OCLC.Virtual International Authority File:Using the API.[2012-08-26].http://www.oclc.org/developer/documentation/virtual-international-authority-file-viaf/using-api
16 Tony Hammond.nature.com OpenSearch:A Case Study in OpenSearch and SRU Integration.[2012-08-13].http://www.dlib.org/dlib/july10/hammond/07hammond.html
17 Openlink Software.Virtuoso Facets Web Service.[2012-08-24].http://virtuoso.openlinksw.com/dataspace/dav/wiki/Main/VirtuosoFacetsWebService
