基于改进MGR融合算法的视频信息融合框架
2013-10-26樊刘娟
李 梅,王 晶,樊刘娟
(1.太原理工大学 计算机科学与技术学院,太原 030024;2.中国邮政储蓄银行 山西省分行,太原 030024)
近年来,随着计算机技术和信息化进程的发展,各种类型的信息逐渐遍及于我们的工作、学习和生活中。大量的信息一方面极大的丰富了我们的工作和生活,但是另一方面如何从众多信息中快速寻找到我们需要的信息也并非易事。藉此,国外有研究人员提出了多媒体信息检索(MIR)的概念,所谓多媒体信息检索就是从各种类型的资源(包括文本、图像、视频、音频等)中寻找到所需信息的过程[1]。早年的多媒体信息检索通常采用基于计算机视觉的算法[2],它聚焦于多媒体各种不同特征(例如图像、音频等)的相似性研究。不久,该类检索也开始应用于基于网络的图像搜索引擎及企业型数据库中。20世纪90年代中期,发展为基于内容的多媒体检索。21世纪初,研究人员注意到未来演变的系统需要了解语义查询,并不仅仅在低维空间计算潜在的特征,这就是我们常说的“语义鸿沟”。要跨越“语义鸿沟”就必须获取更多有效的信息,分析出原始数据的语义。这就需要对视频数据中各种有效信息进行融合分析,以便提取出可以表示语义信息的关键信息。
Jana Kludas认为多媒体信息的多模态性质产生了信息融合的本质需要[3],然而进行信息融合时,同处一个空间的事实也会影响到其他任务,比如对象的识别。在过去几十年间,信息融合只建立在狭窄独立的研究领域里,至今仍未有一个通用的描述信息融合的理论框架。现有的视频分析工具大多只分析多媒体信息的一种模态特征,然而,关于同一信息点的多种模态特征在很大程度上具备关联性。因此,需要一种方法对视频的多模态信息进行有效的融合分析,增加对视频信息分类检索的准确性。笔者提出了一种改进的MGR分类器融合算法,并采用这一改进后的算法通过实验进行融合分析,仿真结果表明该方法能够有效提高分类识别的效率,提升系统的整体。
1 分类器融合算法
由于多媒体信息的多模态性,分类器融合对处理多媒体信息具有十分特殊的意义。在处理多媒体信息的过程中,会产生很多不同的分类,且描述这些类具有复杂、高维的特性,兼具一定的变化性,这就导致相关分类器有较高的错误率。有相关研究表明,不同模态所固有的一些相关性信息与待分析的被标注图像的视觉及文字特征具有一致性。因此,有效的信息融合算法和框架可以极大地提高检索、索引或分类方法的性能。
1.1 MGR分类器融合算法
目前,常见的融合算法有:BC融合算法(Borda Count)[4]、HR 融合算法(Highest Rank)[5]、LR 融合算法(Logistic Regression)[6]和元分类策略 MC融合算法(Meta-Classification)[7]等。
BC融合算法在区分各分类器的性能和专长方面很欠缺,在实际应用中有些刻板、不灵活。HR融合算法虽然不需要训练过程,但是对噪声的考虑不够全面。MC融合算法(Meta-classification)虽然适用于任何需要进行多个分类器融合的情形,但是由于各分类器产生的概率或相似度分数并不能保证传送所有信息。和HR融合算法一样,LR融合方法需要一个训练过程,该算法能动性较好,可以主动学习,并能综合考虑到所有的分类器,但该算法对训练样本要求比较高,如果选择不恰当就会严重影响融合效果;且LR算法不论序号值大还是小,序号值发生变化时对融合结果的影响是一样的。而实际应用中,当序号值较大时,序号的变化对置信度的影响较小;相反,当序号值较小时,序号的变化对置信度的影响较大[8]。
后来,Melnik等人又提出了一种MGR(Mixed Group Ranks)融合算法[9]。该融合算法高度总结了HR,LR和BC三种算法的设计规则,尝试着平衡置信度和优先权,该方法通过设置各个分类器的优先权,使不同的分类器对融合结果的影响不同,增强了小序号值对融合结果的影响。
MGR算法在置信度和优先权两方面达到了较为理想的折中,该算法将排序空间分成两个部分,一部分使得ANM优于UMD的分类器排序,另一部分则刚好相反。另一方面,它给序号值较小的分类器设置一个较大的权重。这一策略比LR和HR算法更具有一般性和普遍性,更有利于接收确定的分类器信息,合理整合不同分类器的信息。
1.2 改进的MGR分类器融合算法
MGR算法分数函数的每一项都是一个子集,随着分类器数量的增多计算量也将大大增加,在分类器较多的情形下,不具备现实的实现意义。刘明等人提出了一种双目标排序层融合算法[8],该算法对MGR算法进行了改进,减少了算法中的参数个数,简化了分类器间的关系,在基本分类器相互独立的情况下能够取得非常不错的融合效果,其融合规则为:
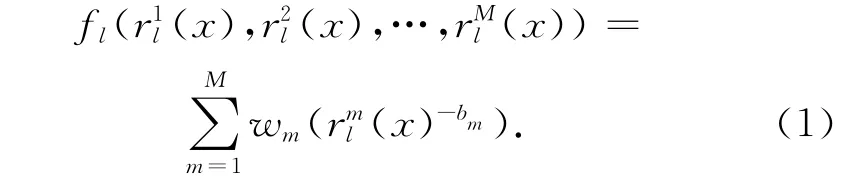
但当各分类器间存在相关性时,该算法的融合效果并不明显,甚至差于其他融合算法。在视频处理过程中,各个分类器通常是相关的,一般表示同一事物的不同特征。为此,我们在Melnik等人设计的融合框架的基础上,尝试在置信度和优先权方面进行优化,提出了一个基于融合分数函数改进的MGR算法。该算法较其他融合算法相比,优势在于增强了小序号对置信度的影响。
改进后的MGR算法融合规则如下:
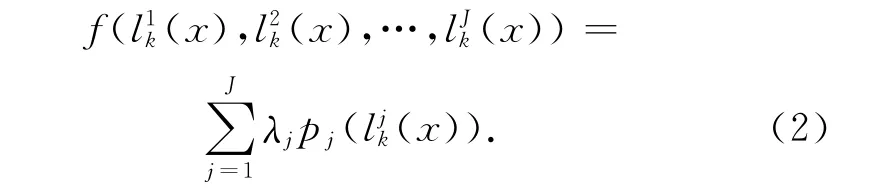
其中,权值λj≥0,函数是单调递减的凸函数。
容易证明改进后的算法符合融合框架的性质,所设计的函数是单调递减的凸函数,且置信度函数仅与对应的序号值相关。

上式中0<cj<1,且cj是待确定的未知参数。
具体到融合函数中,有:

该函数不仅顾及到了分类器权值,而且倾向于序号值小的置信度,基本上满足Melnik等人对融合框架的要求。
2 视频融合分析框架
2.1 视频特征提取
处理视频数据,首先需要对原始的视频数据进行结构化处理。视频融合分析的流程如图1所示。

图1 视频融合分析处理过程
提取视频特征需在原视频的数据里对所属视频进行数据子集的提取[10]。其所具有的特征有视听信息和语义信息,所以在对视频进行特征提取过程中,需要对底层特征及高层语义特征进行区分。底层特征的内容有视觉、听觉和文字内容。高层语义的特征需要建立在对底层特征提取的基础上,对原视频所包含的语义进行分析。当下作为监督模式的分类问题对视觉语义特征提取,通常可以采用分类模式或者机器学习的方法。不过对底层特征尤其是视频,所涉及到的多模态特性必须要有效率较高的算法达到高效的特征选取,通过高效的融合算法将底层特征映射,对于不同的情况选择不同的融合算法,才能高效的识别视频。
2.2 降维过程
多媒体存储过程中,势必带来海量存储,而在存储以及使用过程中涉及到的计算以几何倍数增加,而且所需存储空间复杂度也非常大。现在普遍用来解决此问题的方法需要对高维空间进行分解,映射在低维空间,并且在降维过程中,不能破坏原始数据的结构分布,我们把此方法叫做降维。Shuicheng Yan等人针对此问题引入了一种图嵌入框架[11],这个框架涉及到了较为全面的降维算法,对于其中所包含的降维算法都认为是一种特例,在限定条件下,考虑为特例。通过使用该框架下的类内紧凑和类间分离准则可以解决之前存在的一种缺陷:LDA的数据都依赖于高斯分布。在这个情况下,Yan等人提出了边际fisher分析算法[12]。fisher分析法中有内在图以及惩罚图,内在图用来表示类内紧凑,惩罚图用来表示类间分离。内在图用来对类内点的邻接关系进行描述,其中的样本与所属同类的K1最近邻。惩罚图用来对不同类之间所关联的边缘点的联系进行描述。这样就不用必须获取数据分布所附属的先验信息,同时在映射方面上比LDA要更加好用,比LDA等算法更具有普遍性。
3 实验
3.1 实验数据
本文中采用的实验数据集来自公共视频网站www.open-video.org中的公开视频,我们选择下载关于吉他guitar,水water,人people等为主题的6类视频,并采用IBM公司的自动过媒体分析检索系统(MARS)自动为视频片段划分镜头并提取镜头中的关键帧进行标注。
3.2 实验设计原理
实验中将原始视频数据分为训练集、检验集和测试集三个集合,测试集占40%,其他各占30%。训练集用来训练基本分类器;检验集用来训练融合算法;测试集全部用做测试样本。考虑到颜色直方图(color histograms)在全局及局部分布上能有效的刻画图像颜色,我们采用颜色直方图256维的色度、饱和度和亮度三个分量描述关键帧。我们把颜色空间划分为较小的颜色区域——箱(bin),通过计算每个箱内的像素数量确定其颜色直方图。我们用8个箱量化色度和饱和度,用4个箱量化亮度。我们采用灰度共生矩阵(Co-Occurrence)描述图像的纹理,在常用的0°方向,45°方向,90°方向和135°方向上计算其各自的灰度共生矩阵。通过提取Mel频率倒谱系数表示视频语音特征信号。提取数据25维、第1维为类别标识,后24维为语音特征信号。
每一种底层特征都分别采用边际fisher分析(MFA)进行降维,转化成24维的特征样本,再采用SVM分类器进行分类,通过交叉验证获得其惩罚参数c和核函数参数g。这样,根据输入数据和特征种类可以设计8个SVM分类器,三个数据集共可获得24个基本分类器。对于任意的输入样本,每个基本分类器计算该类样本和每类样本的最近邻距离,并根据距离的大小将各个类进行排序,输出一组序号,全部基本分类器的输出序号综合起来构成一个序号矩阵。经过各个分类器处理得到的校验集样本序号矩阵构成融合算法的训练集,测试集样本序号矩阵构成测试集。
3.3 实验结果及分析
用SVM分类器分别对提取的颜色直方图特征、纹理特征、音频特征进行分类,对比不同的降维和融合组合识别率结果识别率有很大差别,不同的特征对待不同类的样本各有优势。具体的识别效果如图2所示。
为了对比,再从分类器中选择4个基本分类器,分别来源于不同的数据源,然后进行独立分类器的实验。对比实验的融合结果如图3所示。
再次验证我们采用的降维综合融合算法的有效性。分别采用LDA降维算法和LR融合算法的组合,以及LDA降维算法和MGR融合算法的组合,MFA+MGR算法的组合并对比MFA算法和我们改进后的MGR算法的组合。对比我们前面分类手工标注的四类视频进行识别率对比,结果如表1所示。
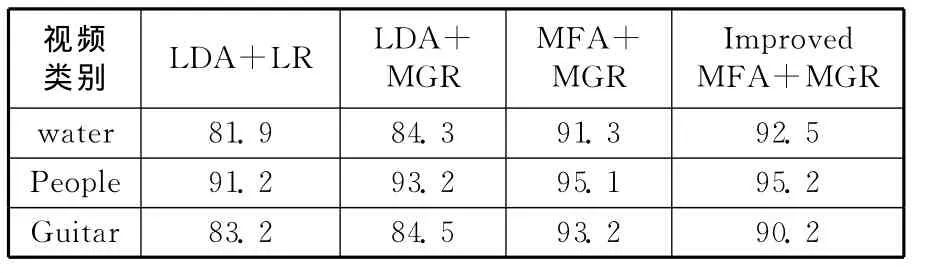
表1 分类器识别率 %

图2 各种组合策略的识别准确率
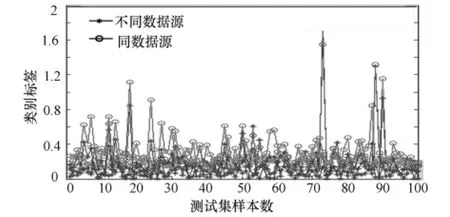
图3 同数据源与不同数据源的识别错误率对比
笔者在设定条件下与方法进行了实验,结果表明普遍情况下,用本文所述的改进算法进行分类时准确率优于现存的融合方法,通过和Melnik所提出的算法结果进行比较,发现也有提高。此分类算法降低了涉及到的分类器所具有的错误率。通过实验可以认为在MGR的各分类器进行融合实验时,所组成的分类器体现的性能明显好于LR融合算法和BC融合算法。采用笔者所提到的方法融合基本分类器时,在分类准确率上比其他逻辑同归和MGR方法要好,尤其是在非独立关系的基本分类器之间,此方法比起双目标排序融合算法要更好一些。通过融合视频所具有的特征多种模态,所获得的平均效果比起单模态情况要好很多。
4 结束语
笔者根据视频特征的多模态性质以及分类器融合的理论,提出了一种基于改进MGR融合算法的视频信息融合框架。该框架提取出视频关键帧图像的颜色特征、纹理特征及视频的音频特征,进行统一的降维处理后输入到分类器中进行分类,然后对分类器的输出结果进行融合分析,并在融合分析中对融合算法MGR进行了改进,减少了融合函数的参数并降低了融合算法的计算复杂度。实验证明整体框架比传统的方法拥有了更高的分类正确率。
[1]许源.视频语义特征提取算法研究[D].上海:复旦大学计算机科学与工程系,2006.
[2]Michael S Lew,Nicu Sebe,Chabane Djeraba,et al.Content-Based Multimedia Information Retrieval:State of the Art and Challenges[J].ACM Transactions on Multimedia Computing,Communications and Applications,2006,2(1):1-19.
[3]Jana Kludas,Eric Bruno,Stephane Marchand-Maillet.Information Fusion in Multimedia Information Retrieval[J].Adaptive Multimedial Retrieval:Retrieval,User,and Semantics,2008:147-159.
[4]Tin Kam Ho.A Theory of Multiple Classifier Systems And Its Application to Visual Word Recognition[D].New York:Graduate School of State University of New York,1992.
[5]李辉,李存华,王霞.基于特征选择的网页排名算法[J].计算机工程,2010,36(13):37-39.
[6]邓妍,张卫强,刘佳.语种识别中基于局部多样性建模的向量空间模型[J].清华大学学报(自然科学版),2011,51(2):161-165.
[7]Ding Guo,Yu Bei,Ghosh,et al.EPIC:Efficient prediction of IC manufacturing hotspots with a unified meta-classification formulation[C]∥In ASP-DAC 2012-17th Asia and South Pacific Design Automation Conference,2012:263-270.
[8]刘明,袁保宗,苗振江.一种双目标排序层分类器融合方法[J].自动化学报,2007,33(12):1276-1282.
[9]Ofer Melnik,Yehuda Vardi,Cun-Hui Zhang.Mixed Group Ranks:Preference and Confidence in Classifier Combination[J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2004,26(8):973-981.
[10]冯大淦,萧允治,张宏江.刘晓冬译.多媒体信息检索与管理[M].北京:清华大学出版社,2009.
[11]Shuicheng Yan,Dong Xu,Benyu Zhang,et al.A General Framework for Dimensionality Reduction[J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2007,29(1):40-51.
[12]Jun Yan,Benyu Zhang,Shuicheng Yan,et al.A scalable supervised algorithm for dimensionality reduction on streaming data[J].Information Sciences,2006,176(14):2042-2065.
