基于改进BP算法的RoboCup传球策略研究
2013-10-22周燕艳
周燕艳
(铜陵学院数学与计算机系,安徽 铜陵 244000)
0 引言
机器人世界杯比赛(RoboCup)有多种比赛方式,主要分成实物的机器人足球比赛和软件仿真比赛。软件仿真比赛是提供比赛双方一个实时异步的平台,进行软件仿真研究。由于其相对的方便实现,便于研究,因而从出现以来,得到了极大范围的推广。通过该平台,可以促进分布式人工智能技术、机器人技术的研究与发展。
在RoboCup仿真平台中,每个比赛队伍中的球员是由11个可以自己获取信息、自己决定下一步动作的全自主智能体构成,其中一个还承担着守门员的职责。为了增强系统与现实足球比赛的相似度,在许多信息中主动加入了噪音信息,用来引起智能体所维护的世界模型相关信息的摆动,降低准确度。RoboCup仿真比赛采用C/S体系结构,服务器提供一个实时的环境,并完成现实中的裁判工作,各个比赛队伍实现自己的智能体即Agent功能。服务器通过UDP/IP协议向各Agent发送有关视觉、听觉乃至感知信息,并接受每个Agent发来的动作信息,在服务器中完成有关动作,改变比赛场上的情形。而各Agent通过获取的各种信息,维护自己的世界模型,以此作为决定下一个动作的基础和依据[1-3]。
在比赛中,为了获得比赛胜利,Agent之间的配合极其重要,当本队中一个Agent已经获取对足球的控制权,就要选择合适的队友将球成功传出去。在近几年中,BP算法作为一种有效的方法在该领域获得了很好的应用,但是BP算法也存在着明显的不足:收敛的速度不快,而且容易收敛到局部的最小点。针对BP算法的不足,本文对其进行改进,主要方法是在此算法基础上添加动量项,改进后的BP算法可以提供更可靠的训练策略[4-5]。
1 BP神经网络
20世纪80年代中期,Rumelhart和McCelland提出了一种逆传播算法,也即BP(Back Propaga-tion)网络,是目前应用非常广泛的神经网络模型之一。该算法是在不需要事前揭示描述这种映射关系的数学方程的情况下,BP网络能学习和存贮大量的输入-输出模式映射关系。在反向传播中,根据事实的模型不断调整网络中的相关结点的权值,使得网络和具体的实例误差平方和达到设定的要求,尽可能模拟现实世界。
BP的网络结构由一个输入层、一个输出层和若干个隐含层组成,在具体运算中为了降低运算复杂度,一般隐含层也就是一层,每层由多个神经元结点组成,网络结构如图1所示[6]。
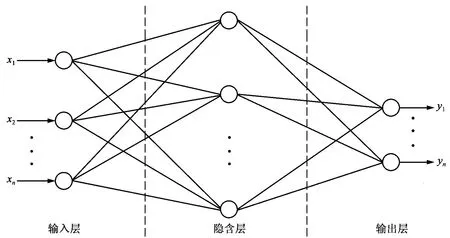
图1 BP网络结构
2 改进的BP算法传球训练
2.1 传球模型分析
为了方便描述,在Soccer Server中,球员和足球均用一个圆表示,用各自一定的半径表示自己的范围。系统要求球员和足球各自的范围不可以重叠,也即两个圆心的距离必须满足不小于系统设定的特定值(该值定义为传球半径)时,该球员可以对足球发出一个踢球(kick)命令,如果该命令获得Sever的支持,操作成功,足球可以获得一个加速度值,改变了球的运动状态[7]。
不失一般性,下面给出传球的几种场景:
(1)如图2(a)所示,Mate2是持球队员Mate1的接应队员,这里两个都是用白色圆圈表示,黑色小圆点用来表示足球;此时没有对方球员。
(2)如图2(b)和2(c)所示,在两个队员中间存在一个对方球员Opp1和Opp1用黑色圆圈表示,此时他俩传球路线需要经过Opp1;有一个对方球员。
(3)如图2(d)所示,在两个球员试图传球的路线上,存在两个对方球员Opp1和Opp2,传球路线需要经过Opp1和Opp2之间。
在四种情形中,最复杂的是图2(d)的情形,为了减少处理问题的规模,前三种情形都可认为是第四种场景的特例。现在的问题变为在已知Mate1、Mate2、Opp1和Opp2的位置和速度量的情况下,让足球获取什么样的加速度,Mate1可以把足球成功地传送给Mate2。同样,为了减少参数的个数,Mate2、Opp1和Opp2的位置和速度均变换为相对于Mate1的位置和速度,那么就可以只有三个位置和三个速度参数输入,一个球加速度值输出。
2.2 传球训练流程
经过上述分析,BP神经网络的节点为6个输入量,即为Mate2、Opp1和Opp2的位置和速度均变换为相对于Mate1的位置和速度,1个球加速度值输出量(即m=6,n=1),在隐含层中设定8个节点,如图 3 所示,设网络输入为 x1,x2,x3,x4,x5,x6,输出为 y。
使用比例系数为1的线性函数作为输入层各神经元的激发函数,网络输入层的输入分别是x1,x2,x3,x4,x5,x6,隐含层神经元的输入为
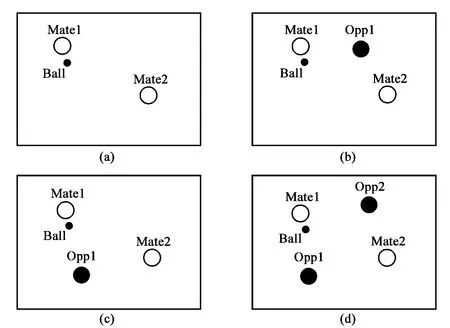
图2 传球多种场景示意图
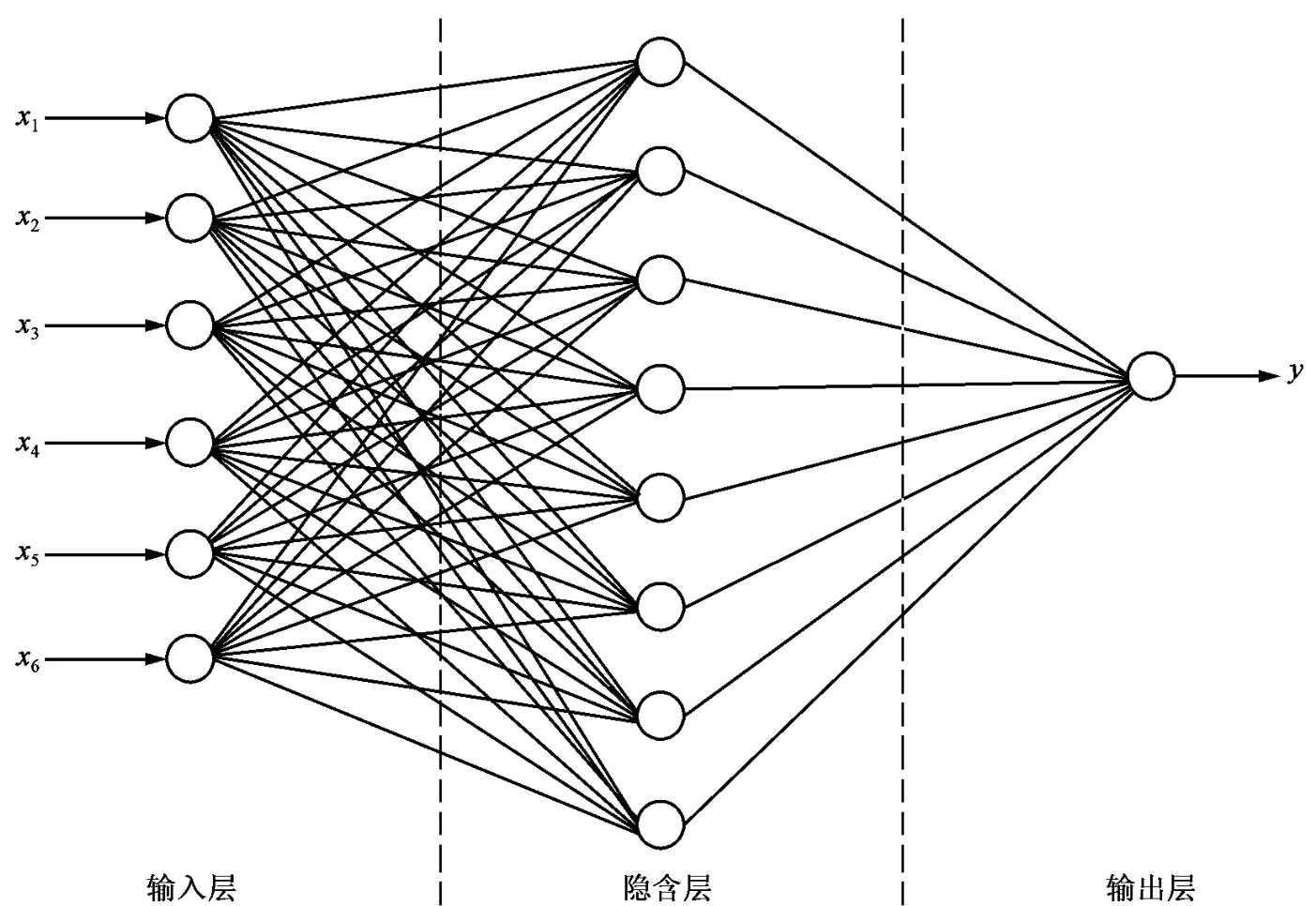
图3 BP神经网络示意图
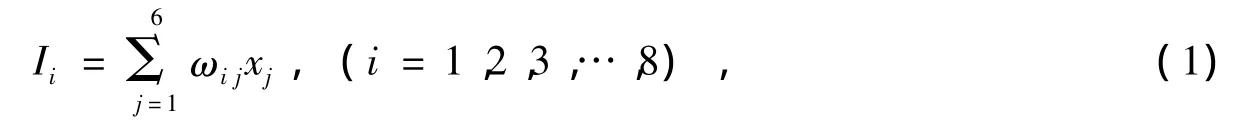
神经元的输出为

设vi为输出层神经元与隐含层神经元i的连接权,则网络输出为

在对由ωij和vi组成的连接权向量W初始化后,就可以在给定一组网络输入后,由上述式子求出网络的输出y,此为正向信号传播。
对于某样本(x1p,x2p,x3p,x4p,x5p,x6p;tp),p 为样本数,由正向计算得到 yp,定义网络输出误差为

误差函数为

随后,沿着误差函数ep随着变化的负梯度方向在反向计算中进行调整后的值为△W(n):

其中:△W(n)为第n次迭代计算时连接权的修正值;η为学习率,取0到1间的某个数。但是在运算中发现,该方法对于某些样本计算时收敛速度慢,并可能存在能量函数局部最小值,为此,对其添加附加动量项,用于进行适当修正,即取
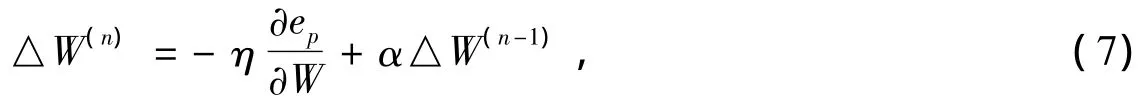
△W(n-1)为前一次迭代计算时所得的连接权的修正值,α为动量因子(在训练中取0.7即可[9]),该值反映了以前积累的经验,对于当期时刻的调整起到抑制的作用,在误差曲面出现剧烈变化时,提高训练的速度。
将以上几个表达式一道计算并加以推导,求得对于样本p时,△W中各元素为
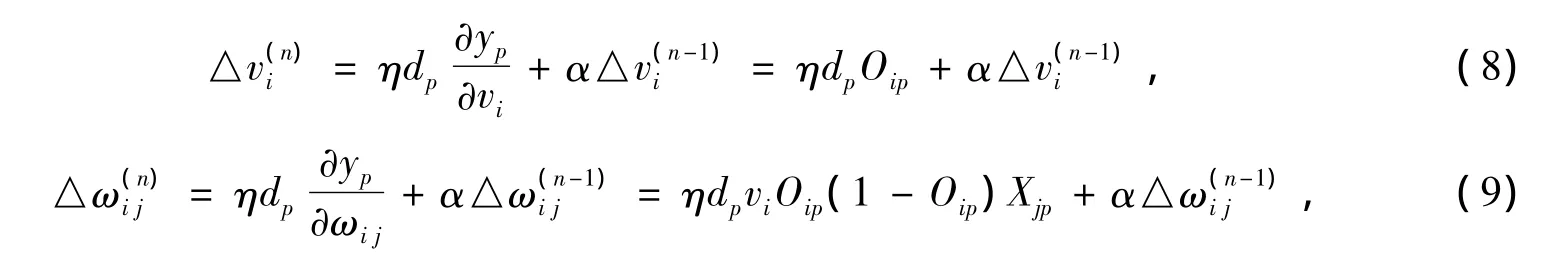
最后采用迭代式W+△W→W对原来的W进行调整,获得新的连接权值W。
对于所有的学习样本,均按照样本排列顺序进行计算,从而求出学习样本的能量函数值为

E是用来确定是否收敛成功的判断依据,当E≤0.000 01时运算停止,否则进行下一次的迭代运算。
在实验训练时,输入成功传球实例中Mate2、Opp1和Opp2相对于Mate1的位置值、速度值以及球获得的加速度值,然后将数据送入神经网络用改进的BP算法进行训练,不断调整网络中的权值和阈值,最终达到满足条件的稳定状态,也即成功收敛。
2.3 实验结果及分析
实验中,系统的客户端平台是基于UVA_Trilearn源码,训练样本库规模分别为150,300,600,1 000,4 000,9 000个(选择了不同的参数),分别使用传统的BP算法和附加动量项的BP算法对样本数据进行训练,统计各自收敛成功的次数,得到结果如表1所示。
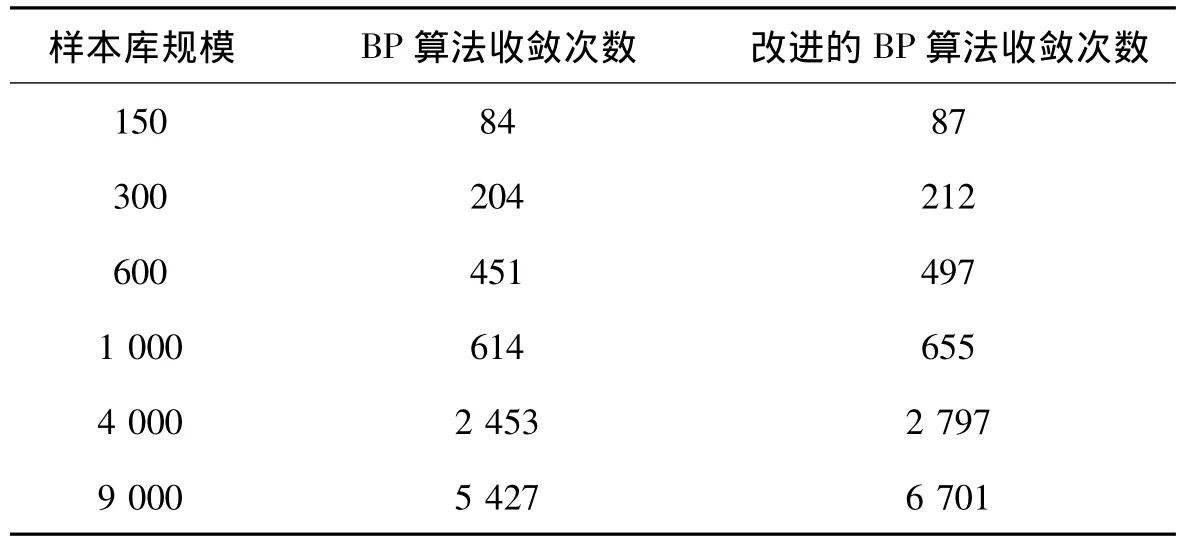
表1 两种BP算法收敛结果比较
从最后的统计数据来看,附加动量项的BP算法比传统的BP算法收敛的成功率有了一定的改善,尤其当样本数增大时,改进的算法收敛的次数有着更为明显的增加。
3 结语
BP算法在不揭示描述映射关系的数学方程的情况下,较好地解决了自动控制等领域的许多问题,但又存在着一定的局限。本文在传球训练中使用BP算法进行处理,为了克服该算法的不足,又进行了局部调整,加入了附加动量项。从最后的实验中发现,调整后训练性能改善明显。
[1]Yan X W.Fuzzy Advantage Learning[J].IEEE,2000:865-870.
[2]Kaelbling L P,Littman M L,Moore A W.Reinforcement learning:A survey[J].Journal of Artificial Intelligence,1996(4):237-285.
[3]刘亮,李龙澍.基于神经网络和遗传算法的RoboCup截球策略[J].计算机工程与应用,2006(33):28-30.
[4]张永怀,刘君华.采用BP神经网络及其改进算法改善传感器特[J].传感技术学报,2002(3):185-188.
[5]崔阳,徐龙,刘艳,等.基于改进BP神经网络的煤催化气化预测模型研究[J].燃料化学学报,2011,39(2):90-93.
[6]郝晓弘,段晓燕,李恒杰.基于BP神经网络的迭代学习初始控制策略研究[J].计算机应用,2009,29(4):1025-1027.
[7]方宝富,王浩,姚宏亮,等.HfutEngine 2005仿真机器人足球队设计[J].合肥工业大学学报:自然科学版,2006,29(9):1085-1089.
[8]周燕艳.改进的 Q学习算法及在其 RoboCup中的应用[J].四川理工学院学报:自然科学版,2011,24(4):417-421.
[9]刘伟.多元地学信息挖掘中分层动量增项自适应BP算法应用研究[J].数学的实践与认识,2011,41(2):85-89.
