面向移动警务应用的云计算平台设计与实现
2013-10-20计春雷
肖 薇,计春雷
0 引言
随着科技的不断发展与金盾工程的全面启动,公安部门也越来越重视科技强警工作。常住人口、重点人口、逃犯库、指纹系统、被盗抢车辆、驾驶员信息等一系列公安基础数据库在不断完善[1],使得大规模数据不断产生。公安民警在执行警务活动的时候,通过电台、手机等通讯工具与留守在单位的同事来查询、验证数据的方式,已经不能适应目前的公安工作[2]。本文提出了Android平台的功能模块开发与云计算平台有机整合的思想,通过高效的网络接入Libev远程调用Spark云计算服务平台,以解决海量数据的图像检索问题;通过构建图像特征索引技术,提高了图像检索的效率,从而提升了移动警务的执行能力。
1 研究意义
我国目前的移动警务系统主要存在以下几个方面的问题:
(1)系统性能低。以前的移动警务系统是围绕实现小数据集来构造的,而对于日趋庞大的公安部数据源,如何能在多个结点之间快速的运行就成为一个难点。
(2)系统结构稳定性低。系统的性能差直接导致系统结构稳定性差,随着移动警务数量和服务质量要求的不断提升,势必导致系统内部结构稳定性下降。
(3)系统复用性低。目前的移动警务系统过分依赖于操作系统或网络系统等环境提供的服务,系统中的一些模块往往不能在其他应用环境中重复使用,并且与其他系统进行交互时存在很大的困难。
本系统的实现能够为一线移动警务工作现场提供了强大的数据信息支持,促进业务综合、信息关联,满足公安快速反应、及时行动的工作要求,提升公安交警执法的能力和水平。
2 系统设计
本系统研究的移动警务云计算平台,主要由移动终端、移动通信网络、服务接入网关、分布式文件系统、数据库系统和文本检索服务器等组成,通过这些模块实现了系统数据信息注入、服务请求处理、海量数据存储和处理三大内容,是服务系统的核心,如图1所示:
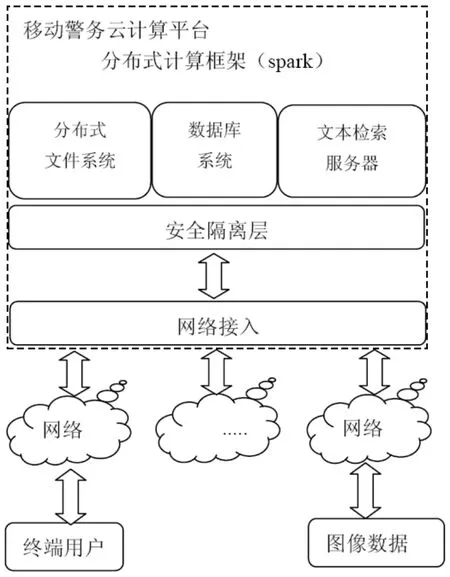
图1 系统整体架构
基于云计算平台的移动警务应用,在技术上主要面临的问题包括:高效的网络通信处理与系统交互实现;高性能的集群运行;海量数据的存储。为了解决这些问题规划了研究路线:
(1)对于移动终端数据的导入及系统交互,依靠于成熟可靠的 Libev、Thrift技术,实现高性能且稳定可靠的运行环境。
(2)高性能集群框架Mesos。Mesos支持分布式数据集上的迭代作业,为分布式应用程序的资源共享和隔离提供了有效的平台[3]。
(3)分布式计算框架Spark。Spark运行在Mesos集群框架上,通过启用内存分布式数据集,能够提供交互式查询和优化迭代工作负载。
(4)在海量图像数据的一体化存储管理研究方面,针对非结构的图像数据、半结构的标注数据,可统一管理分别存储。其中元数据信息可存储在关系数据库中;半结构的标注数据根据数据性质,可以以文件的形式存储在分布式文件系统GlusterFS中或NoSQL数据库中;图像数据可以存储在GlusterFS中,GlusterFS通过扩展能够支持数PB存储容量和处理数千客户端。
3 云计算平台模块介绍
(1)分布式计算框架spark
Spark是一种可扩展的数据分析平台,它为集群计算中特定类型的工作负载而设计,即那些在并行操作之间重用工作数据集(比如机器学习算法)的工作负载。为了优化这些类型的工作负载,Spark整合了内存集群计算的基元,可以在内存集群计算中将数据集缓存在内存中,以缩短访问延迟,如图2所示:
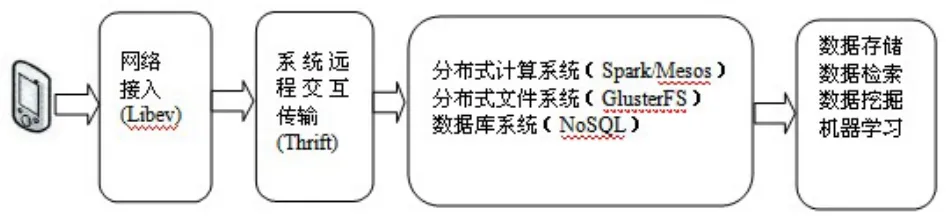
图2 移动警务云服务平台的研究路线
因此,相对于 Hadoop 的集群存储方法,它在性能方面更具优势[4]。Spark还引入了弹性分布式数据集(RDD)。RDD允许在大型集群上执行基于内存的计算,与此同时还保持了MapReduce等数据流模型的容错特性。RDD 是分布在一组节点中的只读对象集合。这些集合是弹性的,如果数据集有一部分丢失,则可以对它们进行重建。重建部分数据集的过程依赖于容错机制,该机制可以维护基于数据衍生过程重建部分数据集的信息。为了实现有效地容错,RDD提供了一种高度受限的共享内存,即RDD是只读的,并且只能通过其他RDD上的批量操作来创建。RDD在迭代计算方面比Hadoop快20多倍,同时还可以在5-7秒的延时内交互式地查询1TB的数据集[5]。
(2)高性能集群框架Mesos
Mesos是Spark在文件系统中并行运行的一种分布式集群框架。它支持Spark在分布式数据集上进行迭代运行,如图3所示:
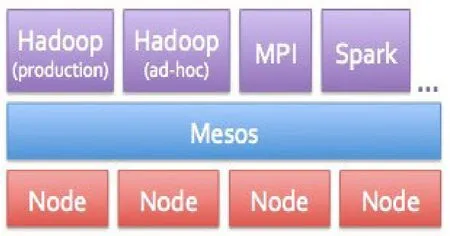
图3 Mesos集群管理器实现资源共享和隔离
它不仅可以在动态分享的结点集上运行 Hadoop, MPI,Spark和其他结构,还能在相同集群上运行多个实体或者多版本的Hadoop来隔离任务。此外,在一批应用和共享资源中,它还可以在相同结点上执行长时间的服务(如Hypertable,HBase),在创建一个新的集群计算结构时,不用重塑低级任务就能与现有的兼容。
(3)并行编程模型MapReduce
Spark主要采用MapReduce模型。MapReduce是Google提出的一个软件架构,用于大规模数据集(大于1TB)的并行运算。MapReduce的设计理念是通过把一个大的任务分成多个小的任务分发到多个机器上进行一个并行的数据处理,通过这种方式可以处理TB级的数据,而且保证数据不会出错,具有可靠的容错性。
MapReduce是一个 master/slave的架构,由一个JobTracker和多个TaskTracker组成。JobTracker主要负责任务分发,把一个任务分解成多个小的任务分发到多个TaskTracker上。当某个TaskTracker发生故障导致任务无法继续执行时, JobTracker 需要进行任务的调度和监控,重新分配任务的执行。TaskTracker只进行任务的处理。一般情况下,TaskTracker和DataNode是同一个节点,这样实现执行任务的数据本地化,提高任务的执行效率。
MapReduce的任务执行[6]分为Map和Reduce两个步骤,如图4所示:
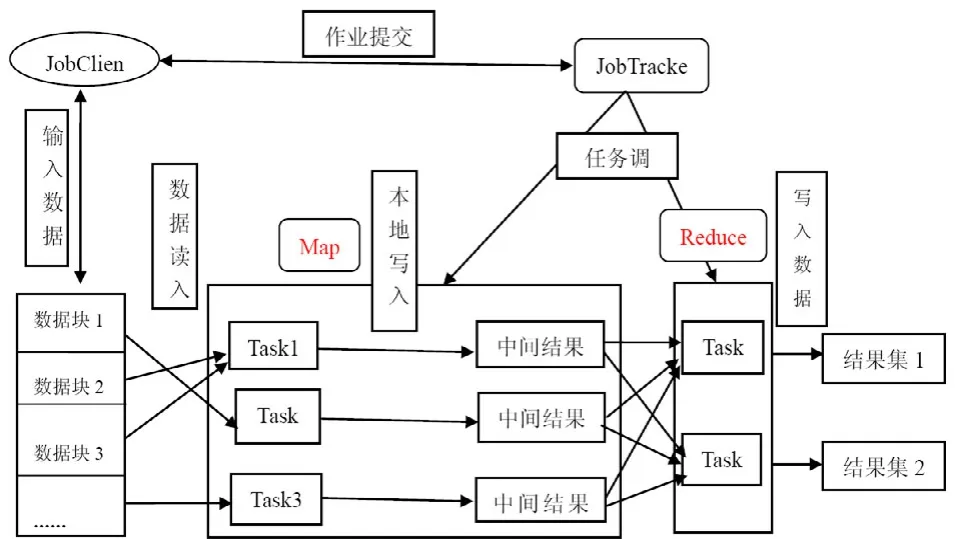
图4 Map/Reduce整体运行框架
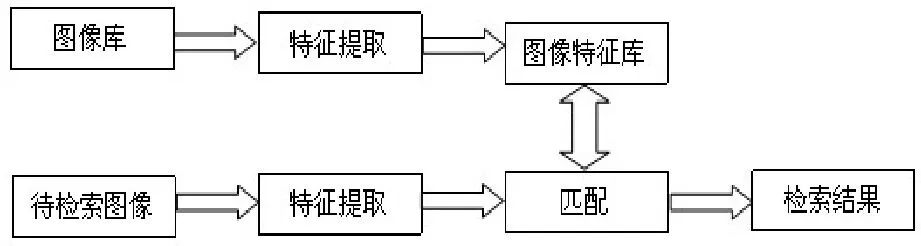
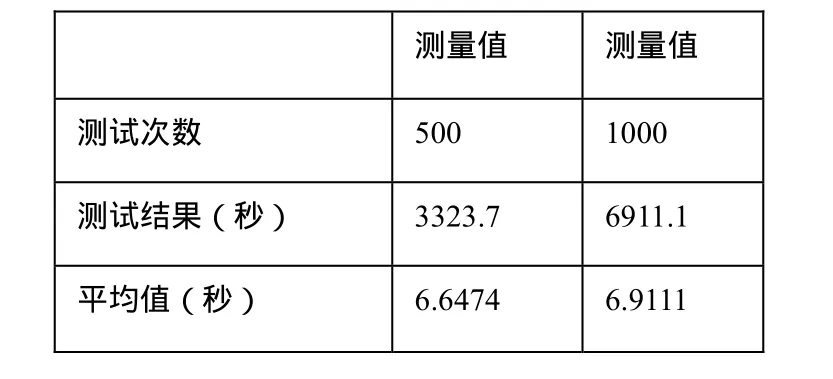
Map把mapper()函数的输入进行一些处理,然后将结果输出到一些数据集中。Reduce接收Map输出的数据集作为输入,通过相关的聚合运算,把聚合后的结果输出。在MapReduce任务中,数据的输入和生成是以多组 (4)分布式文件系统GlusterFS GlusterFS是一个开源的分布式文件系统,具有强大的横向扩展能力,能够支持数PB存储容量和处理数千客户端[7]。GlusterFS 架构中没有元数据服务器组件,这是其最大的创新点,对于提升整个系统的性能、可靠性和稳定性都有着决定性的意义。它可以把多个不同类型的存储块通过Infiniband RDMA或TCP/IP汇聚成一个大的并行网络文件系统,聚集在一个单一的全局命名空间中,来管理磁盘和内存资源及数据。GlusterFS是基于一个可堆叠的用户空间设计,可以为不同的工作负载提供优异的性能,它的模块化架构允许管理员堆叠模块,以满足用户需求。 本设计是基于MPEG-7标准的车辆图像检索。车辆图像中包含大量有意义的局部特征信息,如颜色,纹理,形状等。这些特征信息以一定的形式分布在车辆图片中,从一张图片中抽取相关的信息并以尽可能有效的方式表示出来,然后将这种方式表示的图片与存储在车辆图片模型库中的相比较,从而获得匹配的车辆图片信息。 为了提高图像检索的速率,我们提出了创建索引方法,并采用了K-Means聚类算法的思想。K-Means聚类算法根据对象与各聚类质心之间的距离,将所有特征对象划分为k个簇,每个簇至少拥有一个对象,每个对象只属于一个簇。每个簇中对象之间的相似度最高,不同簇之间的相似度最低。 通过抽取和选择能代表这个模式的特征,然后用这些特征构成的特征向量占有特征空间的一个点。通过相似性度量方法,求出提取的特征向量之间的相似度,进而确定待分类识别的车辆属于某一已知类别。在此,我们选择ColorLayout,ColorStructure作为索引的特征对象。通过相似度度量方法,我们可以将多维空间的聚类转换成二维空间聚类,从而能够方便快速的建立索引。 将ColorLayout,ColorStructure设置成二维空间坐标中的X和Y,通过将他们与设定的坐标原点(即选定的初始值)比较,可以得出相应的X和Y的值,以对象到簇的中心点的距离作为相似度的衡量标准,相似度计算采用欧基米德距离计算公式为: 在聚类过程中,作为每类数据中心的一簇图像的特征信息被保存在高速NoSQL数据库中,每一个聚类结果集都作为一个单独的文件存储在分布式文件系统中。当有新的图片检索请求时,通过计算待匹配图像的 ColorLayout,ColorStructure的值,然后与存储在高速NoSQL数据库中的每一个聚类中心进行比对,根据结果可以得知待检索图像与哪个聚类最为相似。选定聚类后就可以再次通过分布式计算框架实现对这个聚类中的图像的特征值的比对,从而得到图片检索的匹配结果。 创建 K-Means聚类索引,先通过检索存储在高速NoSQL数据库中的特征信息,找到一个聚类中心,缩小图像检索范围,然后对聚类范围中的图像信息进行特征值对比,这样缩短了图像检索的次数,提高了检索的效率。 移动警务人员在治安巡逻、现场执法等场景下采集车辆图片信息,然后将照片及其标注描述信息通过3G网络上传到服务接入网关;服务接入网关将请求的图像信息发送给云计算平台中的后端服务进程,服务进程启动分布式计算框架运行处理作业,运行结束后将计算结果反馈给警务终端人员。 (1) 客户端发送服务请求:客户端程序开启之后,根据服务器端的IP和端口号,发送业务请求。主要实现代码如下: (2) 服务器端接收服务请求:服务器端程序开启之后,通过调用 Me sos Handler Iterator() 方法接收客户端的服务请求。主要实现代码如下: (3) 服务器端接收到图像请求后,根据提取的特征值,调用Distributed Cbir.iterator Compare()方法与已经存储在数据库中的图片特征信息进行匹配,图像检索的流程,如图5所示: 图5 图像检索的流程图 如下是调用iterator Compare()方法代码, (4) 服务器端将Spark云计算平台中查找到的匹配信息返回给客户端,客户端接收到从云服务端返回的匹配图片信息,如图6所示: 图6 客户端接收到图片返回信息 主要实现代码如下: 测试结果表明,当客户端和服务器端成功开启之后,通信传输可以正常运行。客户端模拟终端设备开始发送一个图片请求,Libev接收到数据与服务请求后,通过Thrift远程调用Spark云服务端数据,云服务端通过图像特征的计算与匹配,检索到数据库中相应的匹配信息,将正确的结果返回给客户端。客户端正常显示所有检索的结果,从而实现了整个通信传输与云计算平台的结合。 通过在模拟客户端不断的发送数据请求,测试从发送信息到客户端收到返回信息的时间。系统的性能测试结果,如表1所示: 表1 系统性能测试时间 通过上表可知,系统进行压力测试,性能仍然保持基本稳定。客户端每次从发送信息到收到反馈信息的平均时间大约为6.9秒,对于公安内部这样的海量信息对的图像检索,其性能优势表现更加明显。 本文在云计算平台的基础上,实现了面向移动警务应用的图像检索业务。使用高效的网络接入Libev远程调用Spark云计算服务平台的解决方案,解决海量数据的图像检索问题;通过构建图像特征索引技术,提高了图像检索的效率。本系统尤其对于处理公安部内部等海量数据时,系统性能体现良好,具有很强的实用性。 [1]朱时清.公安移动警务应用研究, [J]电子科技大学,2012,6. [2]毛冬霞.移动警务系统的应用研究, [J]华东师范大学,2009,4. [3]Apache Mesos.http://incubator.apache.org/mesos/. [4]Tim.Jones.Spark,一种快速数据分析替代方案.[M]2012,01,04. [5]弹性分布式数据集:基于内存的集群计算的容错性抽象.http://bbs.sciencenet.cn/cn/hom.php?mod=space&uid=425672&do=blog&id= 520947. [6]王贤伟.基于 hadoop的外观专利图像检索系统的研究与实现.[J]广东工业大学学报.2011年第11期. [7]刘爱贵.GlusterFS集群文件系统研究.http://blog.csdn.net/liuben/article/details/628455.4 图像索引的构建
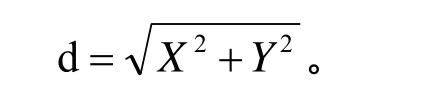
5 图像检索的业务实现与测试
5.1 系统实现



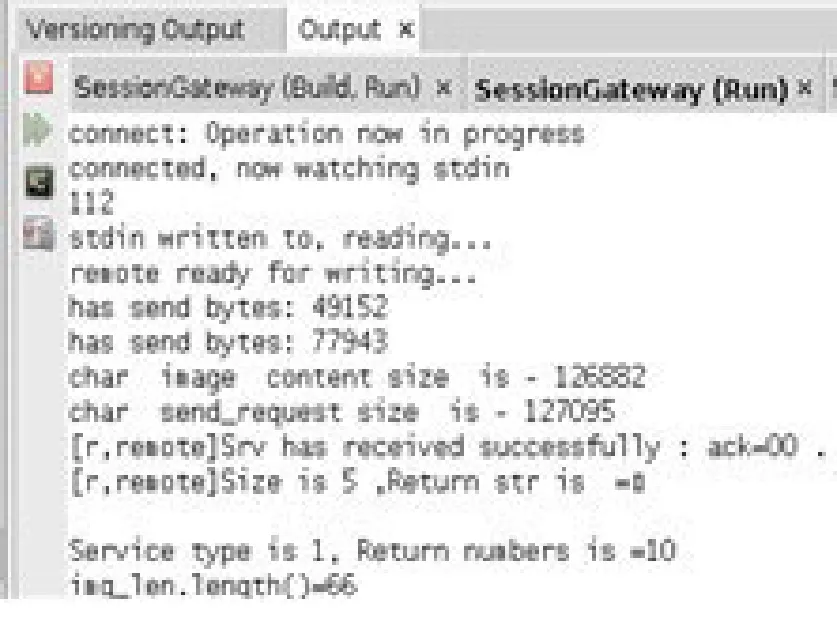
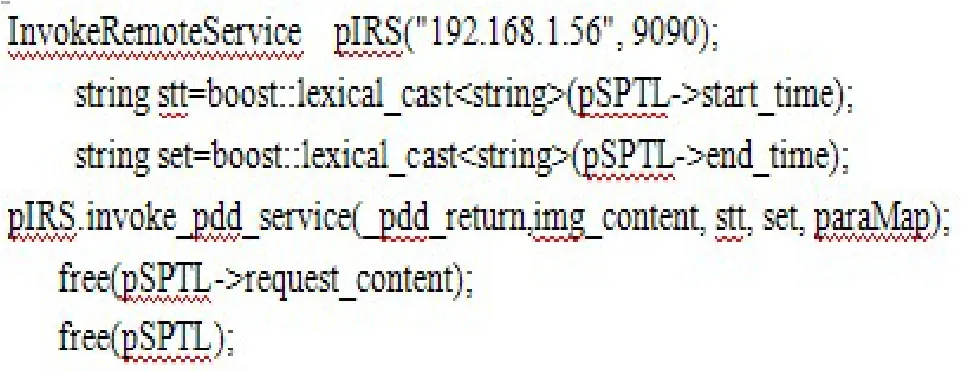
5.2 系统测试
6 结束语
