基于MHBT的数据库隔离与恢复模型
2013-10-17赵飞苏忠丁小
赵 飞 苏 忠 丁 小
(1.空军指挥学院 网络中心 北京 100097 2.95865部队 北京 100092)
0 引言
数据库安全一直以来都是信息安全领域的热点问题。随着云计算、物联网等新兴技术的迅速发展,以及社交网络、微博、推特等新型网络应用的快速普及,包括银行、铁路、水电等基础设施要害领域的信息系统的安全受到更加广泛关注,而信息系统是否安全在很大程度上取决于数据库的安全。传统的数据库安全机制侧重于保护数据的保密性、完整性和可用性,但无法满足数据库可生存性要求,即数据库在遭受到非人为系统故障、内部或外部攻击时持续提供关键服务的能力。要实现数据库可生存性,很关键的一点是必须能够快速发现并隔离恶意事务和受污染数据,并且及时恢复相关事务和数据。随着数据库数据规模的急剧增大,事务提交异常频繁,如何能够在恶意事务检测以后,在确保隔离精度的前提下,最大限度的减少隔离和恢复的时间就成为一个重要的研究方向,因为它直接关系着数据库持续提供服务的能力。
1 相关研究
Merkle Hash Tree(MHT)最早被引入到验证服务数据的真实性是在文献[1]中,它解决了指定查询服务结果可靠性的认证问题。Martel 等人在解决在线数据库查询安全认证问题时提出了检索有向非循环图(search directed acyclic graph)的验证方法[2],并引入了MHT结构,提升了检查的效率。Devanbu 等人提出一种基于MHT的验证机制来解决第三方数据发布方的数据完整性和可靠性验证问题[3],在机制中要求数据库所有者为每一个数据表建立MHT,并将MHT根处的信息摘要直接发给用户,以此来实现查询结果的验证。Ma 等人在文献[3]基础上作了修改[4],对单独元组的属性值建立MHT,从而在验证时能够精确到数据元组,提升了验证精度和效率。Pang H 等人从查询结果的完整性和可靠性两个方面对文献[3]中提出的方法作了实验性验证[5],内容涵盖了查询、查询投影、多点查询等数据库常用服务功能,并从通信代价、数据库升级代价等角度对模型进行了量化分析,具有很强的现实意义。
以上基于MHT的方法都是建立在第三方(外包)数据库服务方静态环境条件下(许多是基于理想化模型条件),解决的问题为数据库查询的正确性和完整性要求。Li 等人在文献[2]的基础上,提出了查询事务及时性的验证需求[6],并通过引入B+-tree设计验证索引结构Merkle B-tree,建立验证模型,同时还将设计方法拓展到动态数据库服务中,提出Embedded Merkle B-tree的数据结构,合理的缓解了验证结构存储空间消耗问题。Jain 等人在文献[6]基础上提出了事务完整性的概念[7],设计的基于Merkle Hash B+-Tree(MHBT)模型不仅能够实现验证数据正确性和完整性的要求,还能够通过建立事务执行与数据库状态结构MHBT之间的对应关系,验证事务执行的完整性,并实现攻击数据恢复操作。
2 基本概念介绍
2.1 单列哈希算法
单向哈希函数h()可以把一个变长的输入值x通过函数计算输出为一个定长值y,即:y=h(x),单向哈希函数h()具有单向性、唯一性等特点。单向性是指:给定一个哈希值y和函数h(),不可能找到一个值x,使得h(x)=y;唯一性是指:不可能找到两个不同的值x、y,使得h(x)=h(y)。目前常用的单向哈希函数是SHA-256。
2.2 Merkle哈希树
Merkle哈希树,又被称为哈希树或Merkle树,1979年由Ralph Merkle首先提出,主要用于对特定对象的认证。MHT是一棵完全二叉树,在这棵树中,叶节点为需认证的对象的哈希值,而中间节点则是其左右孩子节点的并置哈希值。图1所示的是一棵Merkle哈希树示意图。
在图1里,Merkle哈希树共有四个叶节点{S1,S2,S3,S4},其值分别为需认证的对象{O1,O2,O3,O4}的哈希值,即Si=H(Oi)(i=1,2,3,4)(H()为单向哈希函数);非叶节点S34可表示为S34=H(S3||S4)。“||”表示并置操作。
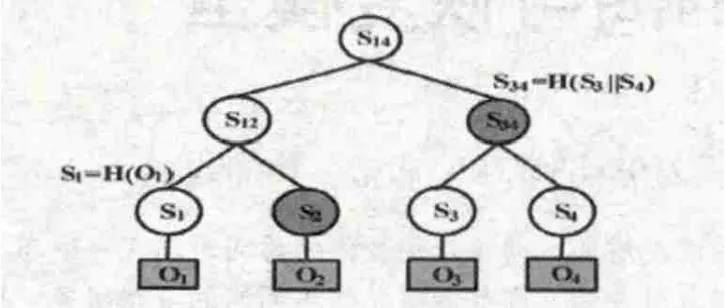
图1 Merkle哈希树
2.3 B+-tree
B+树是平衡多叉树。一棵m阶B+树的定义如下[8]:
树中每个非叶节点最多有m棵子树;
根节点(非叶节点) 至少有2棵子树。除根节点外,其它的非叶节点至少有棵子树;
若根节点同时又是叶节点,则节点格式同叶节点。
有n 棵子树的节点有n个关键码,对应的指向对象的地址指针也有n个;
所有非叶节点中包含下列信息数据( n,K1,P1,K2,P2,… ,Kn,Pn),其中: Ki(i=1,…,n)为关键码,且Ki<Ki+1,Pi(i=0,…,n)为指向子树根节点的指针,n为关键码的个数;
所有的非叶子节点可以看成是索引部分,节点中仅含有其子树(根节点)中的最小(或最大)关键码;
每个叶节点中的子树棵数可以多于m,可以少于m,视关键码字节数及对象地址指针字节数而定。
所有叶节点都处于同一层次上,包含了全部关键码及指向相应数据对象存放地址的指针,且叶节点本身按关键码从小到大顺序链接;
在B+树中有两个头指针:一个指向B+树的根节点,一个指向关键码最小(或最大)的叶节点。图2是一棵3阶的B+树示意图[8]。
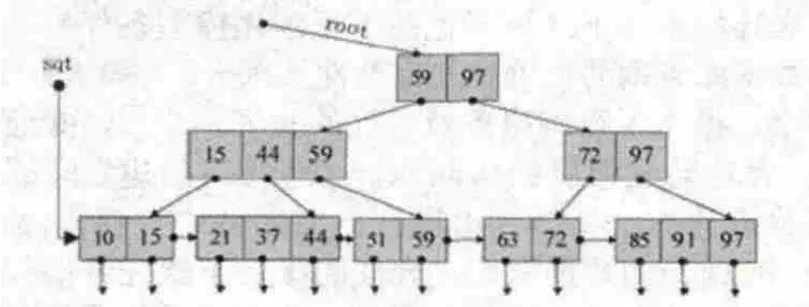
图2 B+树
2.4 Merkle哈希B+树
Merkle哈希B+树(Merkle Hash B+-Tree ,MHBT)就是将MHT中的树结构拓展成为B+树,如同构建MHT一样,对B+树采用分层哈希的模式。一个MHBT的数据结构有着与常规B+树相同的节点构成,所不同的是在每个节点处扩充的加入了节点标记值,每个节点的标记值是孩子节点哈希值的并置哈希值,其计算方法如同MHT:非叶子节点的标记值通过计算子节点标记值的并置哈希值求得;叶子节点的标记值通过计算该节点所包含数据元组哈希值获得。如图3(a)所示,数据库初始化时,对所有的数据元组进行哈希运算后,依据B+树的构建方法,逐级构建此时的证据结构MHBT。具体详细的节点示意图如图3(b)所示,其中kj为节点的关键码值,pj为指针,hj为节点的标记值(其中hi…hk为该节点下属孩子节点标记值的并置哈希值),节点i为非叶子节点,hi为该节点标记值,即节点所指向数据元组哈希值的并置哈希值。
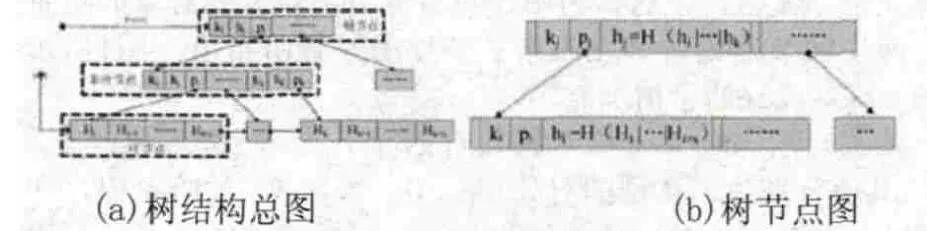
图3 Merkle哈希B+树
3 基于MHBT的隔离与恢复模型
3.1 假设条件
模型自身并不检测恶意事务。本文设计模型本身并不检测一个事务是否为恶意,恶意事务的检测由入侵检测系统完成,模型的主要功能是在恶意事务信息的基础上,快速准确的隔离污染事务及相应的受损数据。
数据库事务的提交是严格串行化的。为了能够确保数据有最严格意义的准确性和完整性,这里我们假设数据库事务的提交是严格串行化的,事务执行的完整性要求每一个事务在提交时数据库必须处于一致的状态,即之前所有的合法的提交事务都已全部有序的提交并修改完相应的数据元组,从而确保数据库状态变化的与事务提交之间的强相关性。
事务本身限定其具有可复制性。事务的可复制性是指事务具有确定性,即在数据库稳定状态上,事务的执行结果完全由读取的数据库值和外部输入的参数值决定,撤销重做执行结果相同。
3.2 系统模型
模型中采用“三方”机制运行,分别是数据库服务端、数据库客户端和MHBT存储端。其中,数据库服务端与客户端采用“一对多”模式,即一个数据库服务端对应有多个数据库客户端,MHBT存储端为一个。系统模型如图4所示。
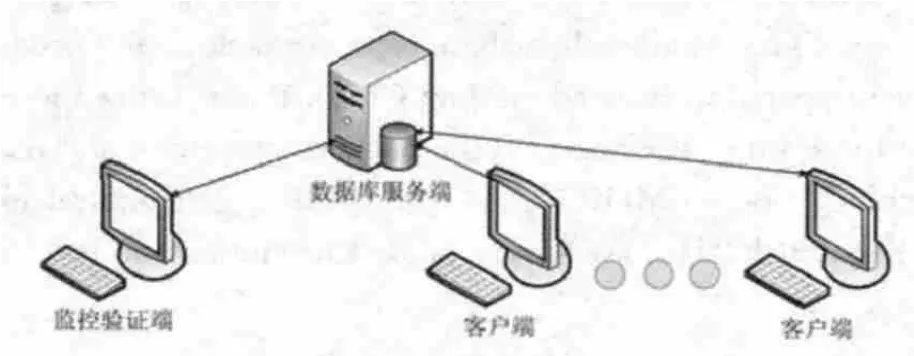
图4 系统模型
3.3 模型描述
在以上假设条件基础上,就可以设计模型使用MHBT来建立事务与数据库状态之间的关系模型:数据库每一次状态变化都可以通过更新MHBT的证据结构来记录,而MHBT的更新又是建立在事务提交的基础上,新的树形结构是在之前树结构应用事务执行结果后计算而来的,这样就能够通过MHBT建立数据库状态和事务提交之间的一一对应关系。
3.3.1 初始化
在数据库开始向用户提供服务前,首先构造数据库初始状态时的MHBT0。MHBT存储端复制初始状态时数据库服务端的所有数据元组,根据2.4节中MHBT构建方法,对此时数据库所拥有的所有数据表,建立初始状态时各自的证据结构MHBT0,证据结构中所有节点的信息通过MHBT存储端建立存储表的形式存储。此后数据库服务端开始正常工作,接收用户发来的请求事务。图5为一个简单的数据库表1在初始化时的示例,为了便于演示,我们将每条数据记录(数据元组)以t1,t2,t3…代号的形式表示,Hi为该条数据元组的哈希值。
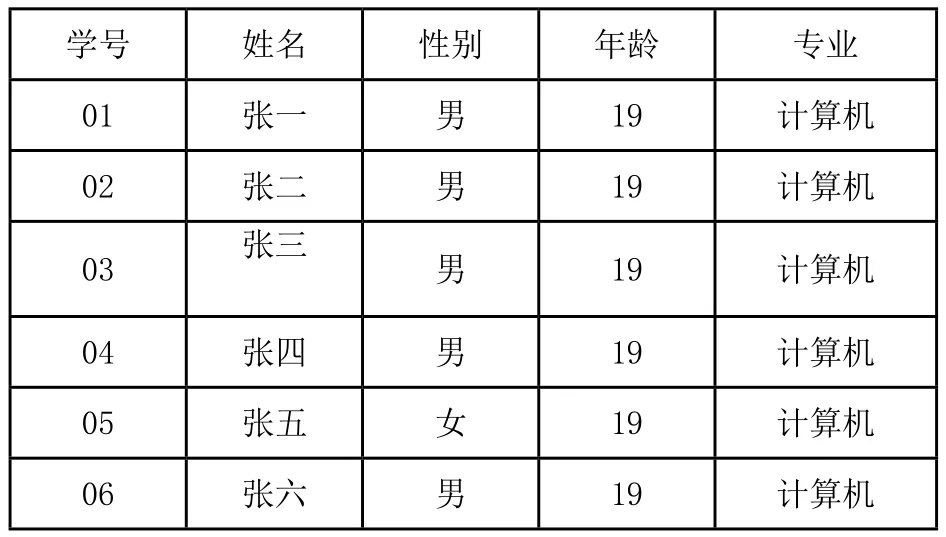
表1 数据库初始化时数
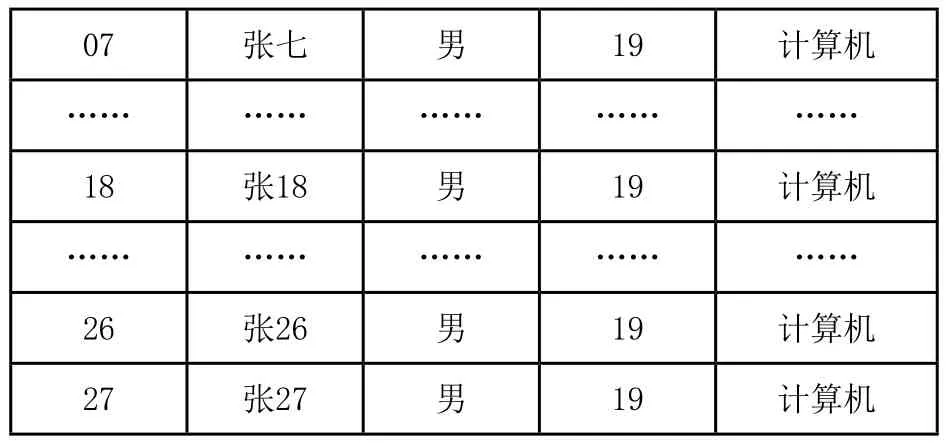
07 张七 男 19 计算机…… …… …… …… ……18 张18 男 19 计算机…… …… …… …… ……26 张26 男 19 计算机27 张27 男 19 计算机

图5 模型初始化MHBT0示例
3.3.2 事务执行
数据库在执行事务时先记录被修改数据元组的信息,如果事务提交成功,数据库就将更新的数据元组和事务标识号(事务在数据库服务端的标识信息)发送到MHBT存储端,而后再将事务执行结果集返回给客户端。MHBT存储端根据事务标识号和修改的数据元组更新证据机构MHBT。具体如图6所示,事务的提交是串行化的,如果i是做为本次提交事务的标识号,数据库就将识别其为事务Ti,即第i个提交的事务,串行化隔离级别能够确保事务Ti的执行是在DBi-1的状态上(之前所有事务全部响应后的一致状态),事务执行后数据库进入下一个一致状态DBi,数据库服务端将修改的数据元组与相应的事务位置号Ti一并发送给MHBT存储端,而后数据库服务端向用户发送响应信息:事务序列号(客户端查证事务)、事务执行结果集。MHBT存储端根据收到的事务标识号和所修改的数据元组计算相应的证据结构MHBTi(从之前的MHBTi-1基础上计算当前的MHBTi:未修改元组直接读取MHBTi-1中记录的节点值,有改动数据元组计算哈希值并存入相应节点后与未修改数据元组节点一起生成新的证据机构MHBTi),做为当前事务执行后的数据库状态信息。

图6 事务执行过程
3.3.3 事务与数据隔离
当入侵检测系统检测到恶意事务后,数据库会根据事务标识号i调取恶意事务的证据结构MHBTi,因为数据库是严格串行化隔离的,所以受影响的事务必定是在事务i提交之后的事务,MHBT通过比对事务i之后的所有证据结构能够快速的确定受影响事务。
证据结构具体比对方法是:
(1)比较根节点的值。在证据结构历史表中存储有数据库历次更新后,各节点的变更信息,依据事务号及节点层级号能够快速实施对根节点的比对:如果根节点值一样,则根据MHBT树结构的特点,可以判定该事务没有修改任何数据元组,为只读事务,不记录到写事务表中;如果根节点值不一样,则能确定该事务对数据元组执行了修改操作,为写事务,记录到写事务列表中,同时,依据证据结构历史表中存储的信息,比对出所有变化的叶结点信息,以此来锁定所有被修改的数据元组。如图7中所示,T(1),T(2),T(3),T(11)都执行了写操作,在首次判定时都会被记录到写事务列表中,而T(12)仅读取了数据,没有修改数据,这里就不做记录。
(2)依次比对写事务列表。依据写事务列表所对应的MHBT树结构,比对出后一事务在之前事务基础上做的数据修改,记录相应改变的数据元组。如果改变数据元组中包含有受损数据元组或污染数据元组,则定义该事务为强相关事务,记录到待恢复事务列表中,所有修改元组记录为污染数据;如果不包含受损数据元组或污染数据元组,则记录为嫌疑事务,进入到下层比对模型。如7图中所示,事务T(1),T(2)对应的证据结构中,比对出的修改元组包含有受损数据X,因为事务T(1) ,T(2)对X执行了写操作,会被判定为强相关事务,记录到待恢复列表中,数据Y记录为污染数据;事务T(3),T(11)与其之前证据结构比对出的修改数据元组不包含有受损数据X及污染数据Y,判定为嫌疑事务,进入到下层比对模型中。
(3)嫌疑事务判定。对2记录的嫌疑事务,MHBT存储端会通过其事务标识号读取数据库服务端事务日志记录中的事务操作信息,如果该事务有读取受损数据或污染数据的操作,则判定为污染事务,记录到待恢复事务列表中;如果该事务没有读取受损数据的操作,则可以判定为正常事务,释放相关的加锁数据元组。如图7中所示,事务T(3)有执行读取数据X的操作,被判定为污染事务,记录到待恢复事务列表中;事务T(11)没有执行数据X的读操作,虽然有修改数据库中数据,但仍就判定为正常事务,释放对数据U的锁定操作。
图8为具体事务的比对流程。
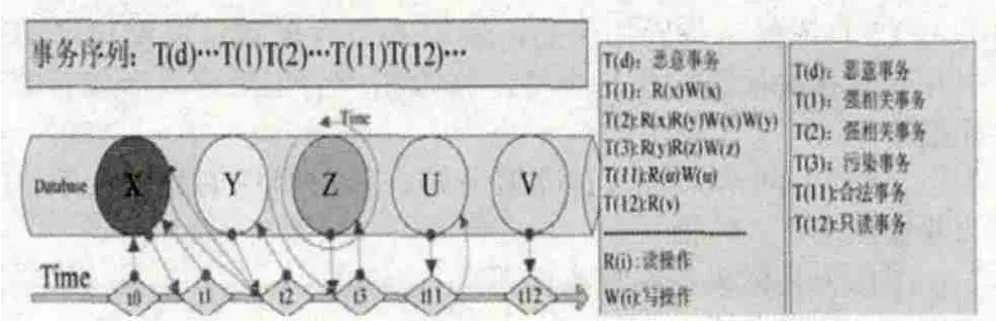
图7 数据库事务分类图
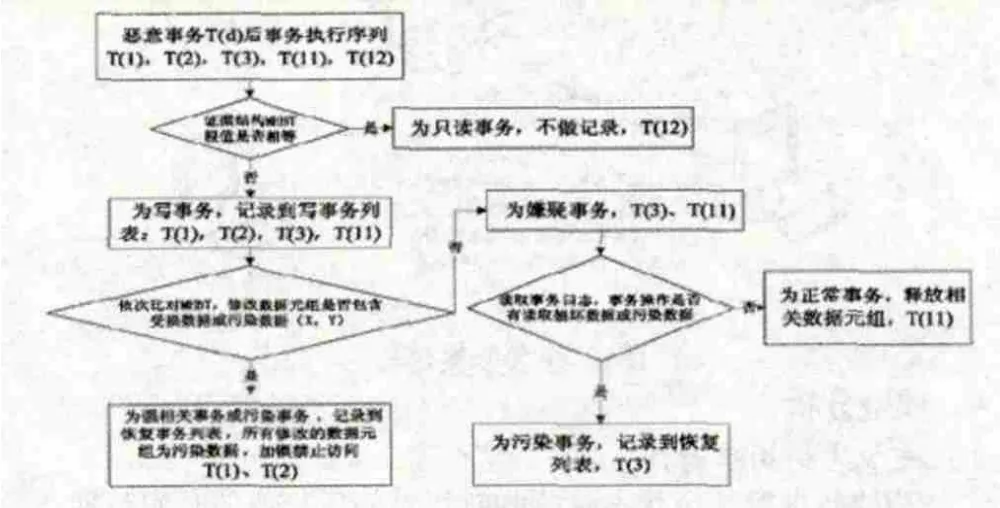
图8 事务比对流程
可生存性保证:MHBT存储端将事务隔离确定的受损数据和污染数据以事务请求方式在数据库服务端加锁(利用数据库中的排他锁,对相关数据实施加锁操作),新事务请求中如果有访问到这两种数据则推迟执行,等待访问数据的恢复操作;如果没有则正常提交事务,按要求生成新的数据库证据结构记录到MHBT存储端相关的数据表中。这样就将正确数据与错误数据合理分割,区别对待,在确保数据库持续提供服务的同时执行受损数据的逐个恢复,最大限度的保证用户的服务请求,如图9所示。
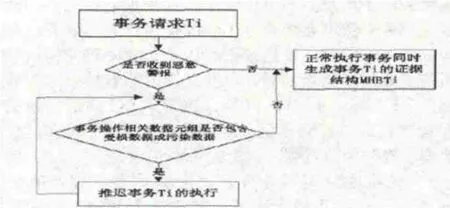
图9 数据库服务端事务执行流程图
3.3.4 数据修复
在数据库服务端的历次更新中,模型运行机的历史表中记录了所有变化的元组值,当需要修复时,MHBT存储端能够通过事务号查到在执行本次事务时,数据库修改元组和节点值时所参照的上一数据库服务端的状态结构信息(参照的相关元组值);待修列表中事务按提交号顺序排列,通过读取事务日志信息,执行事务的重做操作,恢复数据服务端到正确状态。
在数据库服务端的历次更新中,MHBT存储端的数据元组历史表中记录了历次修改的数据元组值,当需要修复时,MHBT存储端能够通过事务号查询到在执行本次事务时,数据库修改数据元组和节点值时所参照的上一数据库服务端的状态结构信息;待修列表中事务按标识号顺序排列,通过读取事务日志信息,执行事务的重做操作,恢复数据服务端到正确状态。具体恢复恢复方法是:
(1)将隔离模型中所确定待修复事务按标识号顺序排列,标识号在数据库服务端是按事务提交顺序依次递增排列的,顺序排列修复事务,能够有效提高读取数据库服务端事务日志记录的效率。
(2)读取数据库服务端事务日志,索取事务具体的操作序列。
(3)依据事务操作信息,读取MHBT存储端证据结构MHBT中存储的相关信息,执行事务,修改相应的记录值,形成新的证据结构。
(4)返回结果给数据库服务端,修改对应的数据元组,解除加锁操作。
图10为具体事务恢复流程图。
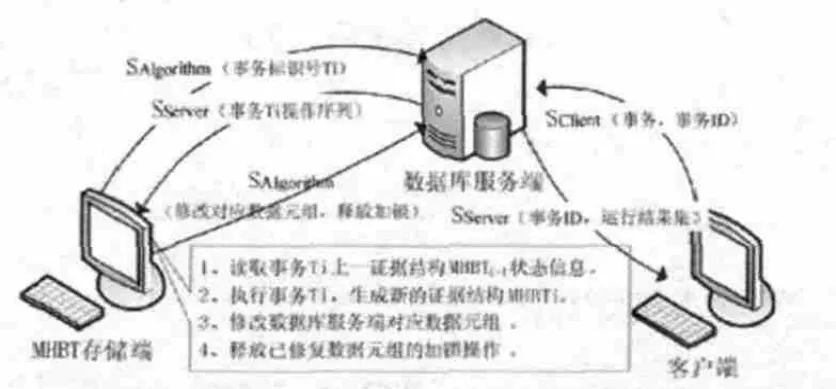
图10 事务修复过程
4 模型分析
4.1 状态结构构建时间
构建数据库某个状态时的MHBT树结构所耗费的时间包括计算每个数据元组的哈希值以及树中每个节点哈希值,另外还有将这些节点信息写入磁盘的时间。
一个数据库拥有n个元组,扇出(fanout,非叶结点平均拥有的孩子节点数)为,如果构建MHBT树的高度为d,那么树中构建的节点为:

则构建树的时间为:

其中,Sn树节点占用存储块大小,St数据元组占有存储块大小,Ch为计算一个哈希值所需要的时间,CIO为一个数据块的IO时间消耗。构建证据树MHBT的时间复杂度为,正比于数据库的存储容量。
4.2 状态结构存储空间分析
所提出的模型模型需要存储数据更新历史中的所有元组和节点的值及更新后的元组和节点值,所以这里所需的存储空间相当于MHBT树的两倍,所以在k次更新后,模型所需要的存储空间为:

模型的空间复杂度为O(n+klog(n)),正比于数据库容量和数据更新次数。
4.3 数据库更新延迟分析
在MHBT树中插入或删除一个元组,相应的从叶子节点到根节点的路径信息都需要更新,并且更新后的结果值还要写入到历史记录表中,所以更新数据所需的时间为:

其时间复杂度为O(logn)
4.4 模型运行效率分析
隔离模型的模型核心是对MHBT树的比对,而MHBT树又以元组的形式记录在数据库表中,故模型相当于是在数据库表中查询和比对相应元组值是否相等,查询时间复杂度为:

5 结束语
传统基于检查点的数据库恢复技术,不论是物理恢复还是逻辑恢复,都需要停止数据库服务,而且要花费相当长的时间(将检查点之后的所有数据重新操作一遍)来恢复,本文提出的模型机制能够在确定恶意事务的前提下,通过比对MHBT中数据元组值的变化情况,并结合日志记录中事务的操作信息,实现对污染数据的精确隔离;同时,通过数据与事务之间的依赖关系,从日志记录中筛选出污染事务,实施精确修复,减少了数据修复时间,提升数据库恢复的效率,最大限度的保证了数据库的可生存性。模型机制的优点是与数据库日志系统相结合,但又不完全依赖于日志系统。在不停止数据库服务的前提下,充分发挥MHBT树的数据结构特点,提升数据库隔离的精度和速度,提高数据恢复的效率。文章最后通过数学分析评估了模型的性能,在下一步的工作中,将针对论文中提出的分析评价参数,展开算法模型的设计与实验性验证,以在实际应用中分析模型的可行性和高效性。
[1]Merkle R C.A certified digital signature[C]//Advances in Cryptology—CRYPTO’89 Proceedings.Springer New York,1990: 218-238.
[2]Martel C,Nuckolls G,Devanbu P,et al.A general model for authenticated data structures[J].Algorithmica,2004,39(1): 21-41.
[3]Devanbu P,Gertz M,Martel C,et al.Authentic data publication over the internet[J].Journal of Computer Security,2003,11(3):291-314.
[4]Ma D,Deng R,and Pang H.Authenticating Query Results From Untrusted Servers Over Open Networks.In Submitted for Publication,2004.
[5]Pang H H,Jain A,Ramamritham K,et al.Verifying completeness of relational query results in data publishing[C]//Proceedings of the 2005 ACM SIGMOD international conference on Management of data.ACM,2005: 407-418.
[6]Li F,Hadjieleftheriou M,Kollios G,et al.Dynamic authenticated index structures for outsourced databases[C]//Proceedings of the 2006 ACM SIGMOD international conference on Management of data.ACM,2006: 121-132.
[7]Jain R,Prabhakar S.Trustworthy Data from Untrusted Databases[C].ICDE,2013.
[8]严蔚敏,吴伟民.数据结构(C语言版)[M].清华大学出版社,2011.
