基于关联规则的利润加权并行算法
2013-10-16石正喜葛科奇曹财耀
石正喜 葛科奇 曹财耀
(宁波城市职业技术学院信息学院浙江宁波315100)
1 引言
随着海量数据的积累,及时快速的从这些庞大的数据中抽取出决策者所需的信息,为企业获得更高的经济效益使得数据挖掘的应用越来越受到企业界的重视。在数据挖掘技术中,APriori 算法是关联规则挖掘的经典算法,该算法存在明显的不足,因为它默认的前提是事务数据库中的所有数据项在挖掘过程中是等价值的,实际上,不同的数据项往往重要性是不同的,也就是说不同的商品给商家带来的利润不一样。因此在分析APriori 算法的基础上,提出改进的新算法十分必要。
2 Apriori 算法
从本质上来讲,Apriori 是一种宽度优先算法,它的本质是多次对数据库D 进行扫描进而发现所有的频繁项目集,在每一次的扫描中只是单一的考虑拥有同一长度k(也就是项目集中所涵盖的项目的个数)的所有k- 项目集。在第一趟扫描当中,Apriori 算法首先计算出数据库D 中所有的单个项目的支持度,进而生成所有长度为L 的频繁项目集(记为L1),然后利用L1 来挖掘L2,也就是频繁2- 项集;如此连续不断的循环下去,直至不能够找到频繁k- 项集为止,其中在发现每一个Lk 的过程当中都需要对整个事务数据库扫描一遍。
总之,Apriori 算法比较适用于处理小数据量的数据库,对于大型的数据库和数据仓库,执行效率会很低。从当今的发展形势来看,数据库中的数据量正在以指数级上升,Apriori 算法很难被广泛运用于实际生活中,因此对于Apriori 算法的改进也就很有必要[1、2]。
3 对Apriori 算法的改进
3.1 算法的改进思路
Apriori 算法的最本质的思想就是需要多次扫描数据库,但是这样的做法会带来不小的弊端,因为当数据库或者数据仓库的容量很大时,扫描数据库所花费的时间代价以及I/O代价都很大,这会降低算法的性能,也会降低数据挖掘的效率。由此提出了如下的改进思路:
①尽量减少需要扫描的事务集以及交易的个数:它的原理是当一个事务不包含长度为M 的大项集,那么它必然也不会包含长度为M+1 的大项集。就此可以将这些事务移除,在下一次扫描中就可以缩减需要扫描的事务集的个数;
②基于划分的方法:这个算法的核心思想是把数据库从逻辑上划分为一些互相没有联系的块,每一次只考虑单独一个分块,并且对它生成所有的频繁项目集,随后合并这些频繁项目集,用来生成所有可能的频繁项目集。最后是计算这些频繁项目集的支持度。对于这些分块来讲,它们要满足一定的大小限制,也就是它们的大小至少要保证每一个分块可以单独的放入主存当中,这样确实大大地提高了I/O 的效率,因为每个阶段只需要被扫描一次。
由于引入了权值的概念,因此,有必要对加权关联规则的支持度做一番改进,把项目的加权值考虑进去。定义:关联规则形如X=>Y 的加权支持为:
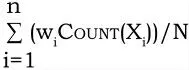
其中,Count (X i) 是时间间隔ti 中包含项目集X 的交易数,N 为加权后的总交易数:
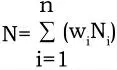
其中,N i 是时间间隔ti 中的总交易数。
因此可以说,对于一个项目集X,如果X 的加权支持度不小于m insup,就称X 为频繁项目集,如果规则X=>Y 的加权支持度和置信度分别大于或等于m insup 和m inconf,则称X=>Y 为兴趣规则。
3.2 改进的新算法
改进的新算法是以2 台计算机并行执行为例进行描述、说明的。算法中部分参数含义:①W:项目权值的集合;②Lk:频繁k- 项目的集合;③CK:由k- 项目集组成的候选集合;④MC(x):项目集X 的支持数;⑤w_m insup:最小加权支持度阈值[3-5]。
改进的新算法的伪代码如下所述:
输入:一个事务数据库D,D 中的每一个数据项ij 有它对应的权值w j;最小支持度;最小置信度。
输出:一个带权值的关联规则集。
计算机1 用于产生所有长度为奇数的频繁项目集。首先生成C1,在进行检查、剪枝后形成L1,然后反复遍历数据库D,执行For(k=3;k≤size;k=k+2)的循环过程,直到没有新的候选产生为止。计算机1 的并行算法如下:


计算机2 的算法与计算机1 相似,计算机2 主要用于产生所有长度为偶数的频繁项目集。首先生成C2,在进行检查、剪枝后形成L2,然后反复遍历数据库D,执行For(k=2;k ≤size;k=k+2)的循环过程,直到没有新的候选产生为止。计算机2 的并行算法如下:

当计算机1、计算机2 各自完成计算后,由计算机1 处理全部结果,并从L=L∪Lk 中生成关联规则。说明:①Choice(MC,w)被用来计算每一个1- 项集的加权支持度,如果大于等于w_m insup,就将其放到L1 当中;反之则将其取消掉;②Count(D,W)用于生成C1;PW_prune_check(Ck,D)用于生成Lk;③PW_Join(Ck- 1,m insup)在算法当中依据Ck- 1 生成Ck的链接方法与Apriori_Gen 函数相同;④Rules_Gen(L)根据L中的频繁项目集生成最低信任阈值的关联规则;⑤SCAN(D)以交易数据仓库D 为处理对象,发现其中频繁项目集的最大可能长度,并返回该数值[6]。
为验证改进的Apriori 算法的性能,在VC++、SQL Server 2005 数据库的环境下,对改进的Apriori 算法及经典的Apriori 算法进行了对比验证。测试数据分别为600、800、1000 条记 录 , 最 小 支 持 度 分 别 为0.01,0.02,0.03,0.04,0.05,0.06,0.07,0.08,0.09,0.10。实验结果表明:当最小支持度增大时,改进算法的运行速度比Apriori算法快;在频繁k- 项集的数量固定的情况下,改进算法的执行效率也远远地高于Apriori 算法;另外,随着数据库中数据量的增大,改进的Apriori 算法的执行效率也明显高于Apriori算法。
4 结束语
基于权值和并行的概念,提出了加权关联规则的并行挖掘算法,通过对新算法与Apriori 算法进行测算,可以发现在设定不同支持度时,新算法在每个阶段的运行时间均要少于Apriori 算法;而固定了频繁k- 项集的数量的情况下,Apriori算法的执行效率也远远地低于新算法。新算法的提出为将来进行海量数据处理提供了一种有效的处理模式。
[1]Sankar K.Pal,Sanghamitra Bandyopadhyay,Shubhra Sankar Ray.Evolutionary Computation in Association Rules:A Review[J].IEEE Transactions on Systems,Man,And Cybernetics- Part C:Applications And Reviews,2006,36(5):601- 615.
[2]Kay C.W iese,Edward Glen.An association rules based genetic algorithm for RNA secondary structure prediction[J].Soft Computing Systems:Design,Management and Application.2002,4(1):173- 182.
[3]刘琦.基于关联规则的数据挖掘算法研究[C.杭州:浙江大学,2008.
[4]谭光明,冯圣中,孙凝晖.一种基于新型的数据挖掘算法研究[J].软件学报,2006,17(7):1501- 1509.
[5]Alain Deschenes,Kay C.W iese.Using different algorithms for improving the Accuracy of Data M ining Algorithm[J].Evolutionary Computation,2004(2):598- 606.
[6]张玉林.一种无冗余的关联规则算法[J].计算机工程与应用,2007,43(3):26- 29.
