基于直方图和FP增长的高维空间离群点挖掘
2013-10-15李龙姣程国达
李龙姣,程国达
(南京财经大学信息工程学院,江苏 南京 210046)
0 引言
一个离群点是这样一个数据,它与数据集中其它数据偏离如此之多以至于让人们怀疑它是由另外一种完全不同的机制产生的[1]。离群点检测是数据挖掘的基本任务之一,其目的是消除噪音或发现潜在的、有用的知识,例如欺诈检测、入侵检测、故障检测、生态系统失调检测等[2]。传统的离群点检测方法主要分为5类:(1)基于统计的方法[3];(2)基于深度的方法[4];(3)基于聚类的方法[5];(4)基于密度的方法[6];(5)基于距离的方法[7]。
随着信息技术的发展,现实数据集的维数和数据的数量显著上升,几十维甚至上百维的数据并不少见。在高维数据空间中,数据非常稀疏,根据数据的相似性,每个点都可被定义为离群点[8]。如何选择合理高效的度量方法处理好高维空间数据点的稀疏问题,并合理解释高维空间离群点的物理意义,是高维离群点挖掘方法的目标。
1 现有高维离群点挖掘方法
高维数据中的离群点并不是在所有维上都离群,在绝大多数情况下,离群数据往往只在少数几个维上出现异常。如果在数据的所有维上进行离群点挖掘,不仅有很大的时间复杂度,而且由于平均作用,使得数据之间差异变得很小[9],为了提高挖掘效率,人们提出了投影变换[9-10]和特征选取[11-12]等基于子空间挖掘的方法。
Aggarwal等[9]提出了用遗传算法来寻找最优子空间的投影变换方法,这种方法将空间划分成等边的网格空间并计算每个网格的稀疏因子,然后利用遗传算法来挖掘子空间中的离群点。在这种方法中,计算每个网格的稀疏因子都要扫描整个数据集,因此具有很高的计算复杂度。Sanghamitra等[13]提出了一种改进方法,可以大大缩短计算时间。上述两种方法采用遗传算法虽然能有效解决数据投影问题,但还存在问题。首先,在初始化阶段,构成染色体的维是随机选取的,这就给离群点挖掘结果带来很大的不确定因素;其次,不同的网格划分存在困难,不同的划分会带来不同的结果。
Angiulli等[11]提出了 HilOut算法,该方法首先利用Hilbert曲线将高维数据映射到一维线性空间,根据数据在一维空间中的前驱和后继找出每个数据的k个最近邻,从而计算每个数据点的权值,最后根据权值排序找出离群点,避免了复杂的距离计算开销。虽然Hilbert曲线可以将复杂的高维问题转化为简单的一维空间计算问题,但是该方法还是有不少缺点。首先,Hilbert曲线也和网格划分方法一样,要不断将每个维2等分,这一点是很难做到的,因为不是每个维的长度都是2的次方;其次,Hilbert曲线虽然能保证一维上相邻的数据点在原高维空间中也相邻,但是高维空间中相邻的点用该曲线映射到一维空间中就不一定相邻了,这就难以保证挖掘结果的准确性。
除了上述两种投影变换方法之外,小波变换也可以用来在子空间上挖掘离群点。它首先通过在数据空间强加一个多维网格结构来汇总数据,然后进行变换,在变换后的空间中发现密集区域[14],消除密集区域后剩下的点就是离群点。Yu等[15]就利用小波变换从原始数据中消除了聚类从而得到离群点。当然,该方法也有网格划分的缺点。
Mohamed 等[16]提出了 PCKA(Projected Clustering based on the K-means Algorithm)特征选取算法。该方法把空间中的维分为两种,一种是密集维,另一种是稀疏维,离群点就在稀疏维上,而聚类就要在密集维上寻找。PCKA的不足之处就是简单地把高维空间中的维划分为密集维和稀疏维,没有考虑有些维既有聚类数据的投影,也有离群数据的投影,这部分维在该算法中很可能被误除从而影响挖掘结果。
此外,Tan等[17]提出的决策树归纳方法和许龙飞等[18]提出的粗糙集方法来挖掘离群点,但这些方法存在和文献[16]一样的问题。
在本文提出的方法中,计算高维数据每一维上的稀疏度,根据稀疏度形成直方图,在直方图上判别该维上离群点;在得到离群点-离群维的对应关系表后,用FP增长方式对离群点-离群维关系表进行分析,像挖掘关联规则一样,挖掘存在离群点的维之间的关系,从而解释离群点不同维之间的关系。通过对实际数据集的实验,表明本方法是有效和有意义的。
2 原理与算法
2.1 KNN(K-Nearest Neighbors)距离的计算
假设DB是一个 d维数据,A={A1,A2,…,Ad}表示数据集的维,X={x1,x2,…,xN}为数据集的 N个数据点,其中 xi={xi1,xi2,…,xid},xij(i=1,…,N;j=1,…,d)对应着数据点xi在维Aj上的值。数据集中任意两点 xu,xv在维 As上的距离为 ds(xu,xv)=|xus-xvs|,其中1≤u,v≤N,1≤s≤d。
定义1 在d维数据集DB中,给定一个参数k,一个数据点的KNN距离是指这个点与其k个最近邻点的距离之和。
KNN距离显示出了一个点的离群程度,KNN距离越大,这个点距离它的k个最邻近点越远,即它是离群点的可能性越高。
算法1(KNN距离计算)
输入:DB:数据集;k:近邻数据点数目;Aj:需要计算的维j;N:每一维的数据数目。
输出:每个数据点在Ai上的KNN距离yij(i=1,…,N;j=1,…,d)(规范化至[0,1])。
步骤1 将DB中Ai对应的N个值存储到一维数组 a[N],b[N];
步骤2 将数组b中元素升序排列,取每个元素b[i](i=0,…,N-1)的前驱和后继元素共2k 个;
步骤3 计算b[i](i=0,…,N-1)与其2k个前驱后继的直线距离,并将这2k个距离从小到大排序;
步骤4 从排序的距离中取前k个距离相加即为KNN距离;
步骤5 将Aj上数值的KNN距离规范化至[0,1];
步骤6 从数组a中获取b中元素在DB中对应的索引号以便将其在Aj上的KNN距离yij保存到相应位置。
2.2 通过直方图判别离群点
Knorr等在文献[19]中这样定义离群点:如果数据集DB中对象至少有pct部分与对象o的距离大于dmin,则称对象o是以pct和dmin为参数的基于距离的离群点。
上述基于距离的离群点定义是全局离群点的定义,除此之外,还有另外的一种离群点,如果一个对象相对于它的局部邻域,特别是关于邻域密度,它是远离的,那它就是局部离群点[20]。
除了上述定义的全局离群点和局部离群点,本文提出一种隐形离群点。
定义2 数据集DB的对象,如果其综合属性分析结果属于某个聚类C,但是在某些维上却不属于任何聚类在这些维上的投影区域,这种对象为隐形离群点。
隐形离群点一般处于所属聚类的边缘,以全局的眼光来看并不离群,使用投影变换或者特征选取方法挖掘离群点时也容易被忽略,本文在数据的每一维上进行分析后才能保证将其辨别,并准确判断其离群维。
如某个数据点在任何一维上离群,则把它当作是离群点并记下它离群的维以便后续分析。根据直方图找出全局离群点、局部离群点以及隐形离群点,其中隐形的离群点并不属于预先设定的离群点集,但也会随着离群点一起检测出,经过FP增长分析后方可确定是否离群,这些离群点是很有分析价值的,提取这些隐形离群点和明显的离群点一起进行后续的离群属性关系分析,将得到很多有用的信息。
KNN 距离规范至区间[0,1],将[0,1]区间分成s份,每份长度为1/s,然后计算 Ai(i=1,…,d)上属于每个区间的数据个数,从而生成KNN直方图。
假设离群点在数据集中所占比例为α(0<α≤5%),数据总数为N,则离群点数目为αN。在直方图中,S1,…,Sm为 s个 KNN 距离区间,|Si|(i=1,…,s)为第i个区间包含的数据点数目。
定义3 在某一维的KNN直方图中,将前m(0<m≤s)个KNN距离区间所包含的数据点数目相加得直至且≥(1-α/2)N,如果|Sm+1|≤αN,则N,如果|Sm+1|≥αN,则,定义直方图中右边β部分的数据点为这一维上的全局离群点。
定义3给出了在直方图中区分全局离群点的规则,其中αN为离群点总数,离群点包含全局离群点、局部离群点和隐形离群点,故定义中将αN/2作为全局离群点的最大值,在直方图中进行具体的计算后,确定β为判定全局离群点的边界值,即把直方图右部β部分数据点判定为全局离群点。
定义4 在某一维的KNN直方图中,从S1至SS取第一个包含数据点小于αN的距离区间Sn(1<n<s),令γ=,则这一维上的局部离群点和隐形离群点存在于γ和β部分数据点之间。
定义4给出了局部离群点和隐形离群点在直方图中存在范围。由于聚类的密度不同,故不同的聚类包含的数据点所处的KNN距离区间不同,本方法定义处于直方图左边γ部分的数据点为该维上密度最大聚类中的数据点,而Sn为该聚类与其余聚类之间的分隔,γ至β部分数据就包含了小密度聚类以及局部离群点和隐形离群点。由于局部离群点存在于不同的聚类之间,隐形离群点处于聚类的边缘,局部离群点和隐形离群点的KNN距离大于聚类中数据点的KNN距离。
定义5 取直方图左边γ部分数据所在KNN区间包含的平均数据点数目为c,即c=|Si|/(n-1),将εc(0<ε≤1)作为聚类包含数据点数目的最小值。
定义6 在某一维的直方图中,对于[γ,β]部分数据所在的KNN距离区间,如果连续3个区间内数据点的数目之和小于εc,则这些区间内的数据点为这一维上的局部离群点或者隐形离群点。
定义5和定义6给出了在直方图中判别局部离群点和隐形离群点的规则。实验表明,处于直方图中[γ,β]部分数据中的聚类,其包含数据点的KNN距离最多分布与3个连续的区间,故如果连续3个连续区间的数据数目之和小于εc,则这些区间内的数据就是疑似局部离群点或者隐形离群点。
算法2 (根据KNN直方图判别离群点)
输入:d维数据集DB;每一维数据在s个KNN距离区间内的数据点数目;离群点在数据集中所占比例α,数据总数 N,ε(0 < ε≤1))。
输出:每一维上的全局离群点所在距离区间集合outlier_Interval以及局部离群点和隐形离群点所在的距离区间集合local_Interval。
方法:对每一维数据Ai(i≤i≤d)。
(1)全局离群点判别。

(2)确定γ。
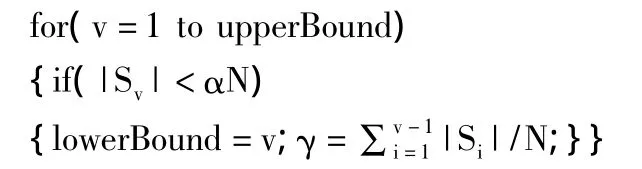
(3)确定局部离群点。

2.3 离群点-离群维关系表
找出数据集中的离群点只是本文的目的之一,更为重要的目的是分析存在离群点的属性之间的关系,为此首先要生成离群点-离群维关系表。
算法3 (离群点-离群维关系表生成)
输入:d维数据集DB;每一维上的全局离群点以及局部离群点和隐形离群点所在的距离区间集合。
输出:每个离群点的离群属性集;将维Ai对应的数据存入一维数组pointValue[N];将维Ai数据对应的KNN距离值存入一维数组pointWeight[N];所有的离群点在pointValue的对应的索引号存入一位数组 Outlier[N]。
方法:
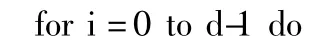
在数组pointWeight中找到属于这些KNN距离区间的KNN距离并把这些距离对应的索引号存入一位数组pointIndex
for j=0 to pointIndex.Count do
if(Outlier中存在 pointIndex[j])
取得pointIndex[j]在Outlier中的索引号index;
将这一维的维数i加入pointIndex[j]对应的数组Att[index];
else
将 pointIndex[j]加入 Outlier
将这一维的位数 i加入 pointIndex[j]对应的数组 Att[Outlier.Count-1];
end for
end for
2.4 离群维的频繁项集分析
频繁地同时出现离群属性组合就是频繁项集,这些离群维之间必然存在某些关联规则,发现这些规则可以发现离群点的离群原因,从而解释离群点的物理意义。为了避免产生大量候选项集合重复扫描数据库,本文选择频繁模式增长(Frequent-Pattern Growth,FP增长)[14]方法对离群属性集进行频繁项集挖掘,找出频繁出现的离群属性组合。
3 实验结果与结论
Aggarwal[9]认为评价一个离群点检测方法的好坏,可以通过在给定的数据集上来运行该方法,并且计算在由该方法所找出的离群点中,真正的离群点所占据的比例,比例越高,则表明该方法的性能越好。本文使用两个数据集对所提出的方法进行测试分析,并分别用该评价方法对实验结果进行评价。
数据1 使用UCI网站的Abalone数据,该数据包含4177个数据,每个数据有9个属性,分别为性别、长度、直径、高度、全重、肉重、可食部分重量、壳重和年轮数。本文将该数据集中年轮数为10圈的成年雄性鲍鱼以及幼龄鲍鱼数据取出作为测试数据集,即数据包含两个类,一类是成年雄性鲍鱼,另一类维幼龄鲍鱼,其中幼龄鲍鱼数据即为离群点。根据找出的离群点数据来分析区分相同年轮数的鲍鱼中成年雄性和幼仔鲍鱼的属性。
本实验设 s=25,α =4‰,ε =0.6,通过对数据第二维至第八维(第一维是预测维,第九维年轮数都为10,故不用计算KNN距离)KNN距离的计算,得到KNN直方图,以长度属性为例,如图1所示。
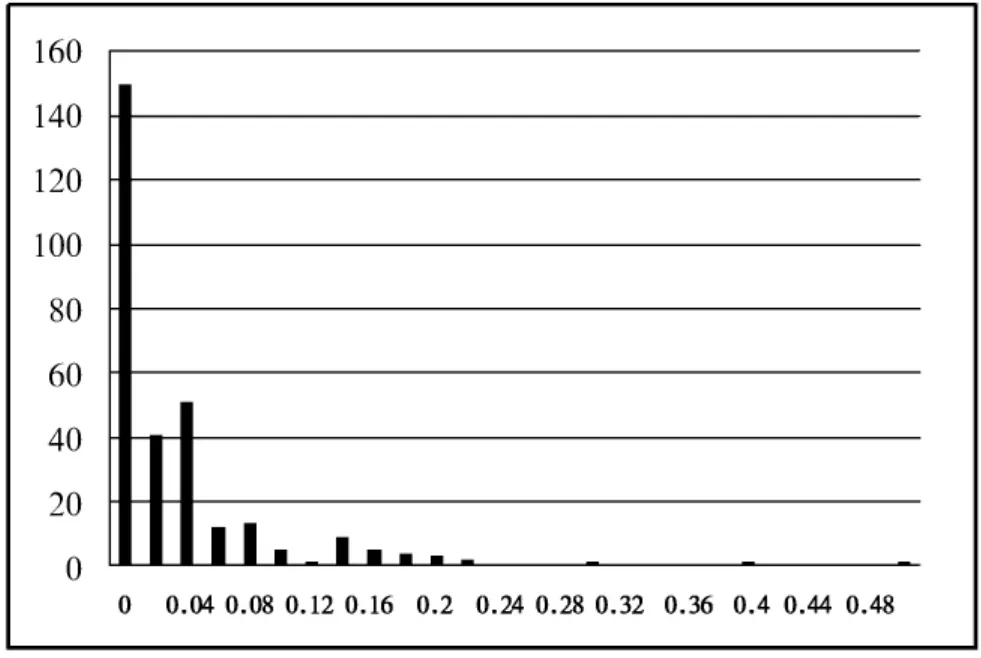
图1 长度属性KNN直方图
通过直方图以及算法分析得到每个离群点以及离群维的对应关系表,如表1所示。
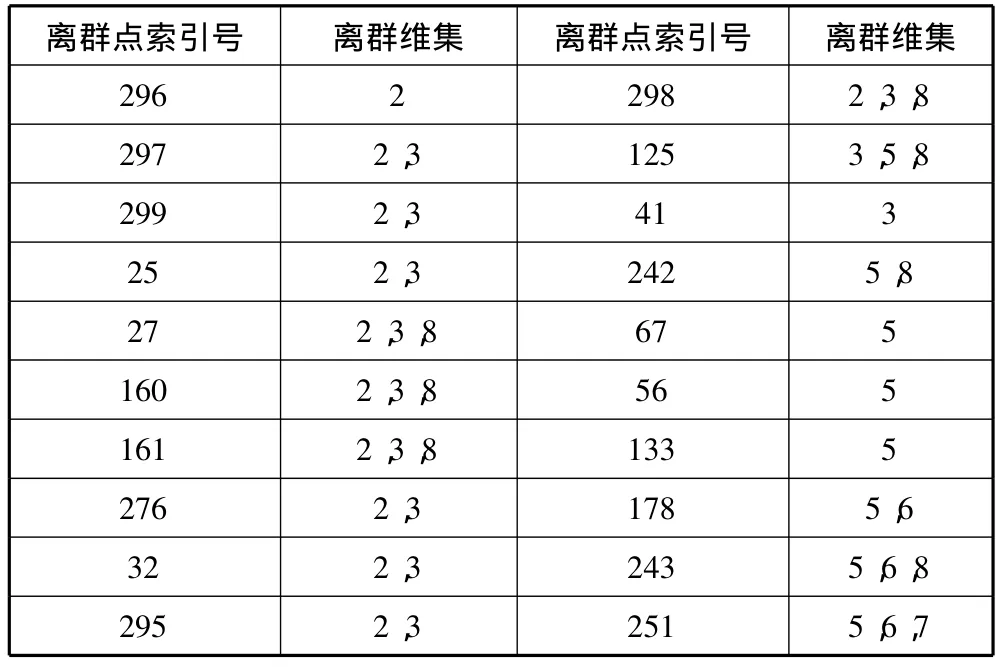
表1 离群点以及离群维的对应关系表
对该离群点-离群维关系对应表进行FP分析以发现离群维之间的关系如表2所示。
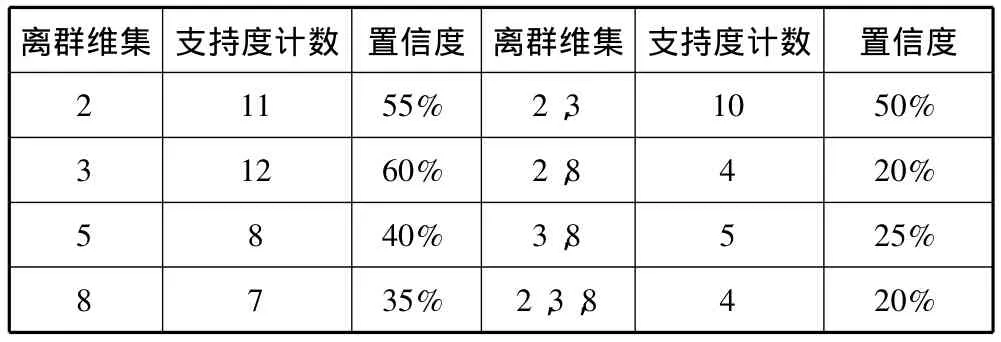
表2 Abalone数据结果分析表
其中属性2为长度,属性3为直径,属性5为毛重,属性8为壳重,经查询可得索引号为295-297的离群点为幼龄鲍鱼,其离群属性主要为长度和直径,由此可知相同年轮的成年鲍鱼和幼龄鲍鱼仔长度和直径上相差较大;其它离群数据点为相同年轮数的成年雄性鲍鱼中的离群鲍鱼,它们主要的离群属性为毛重和壳重,由此可知这些离群的成年鲍鱼是因为“体重超标”才被“孤立”。
实验结果评价如表3所示。
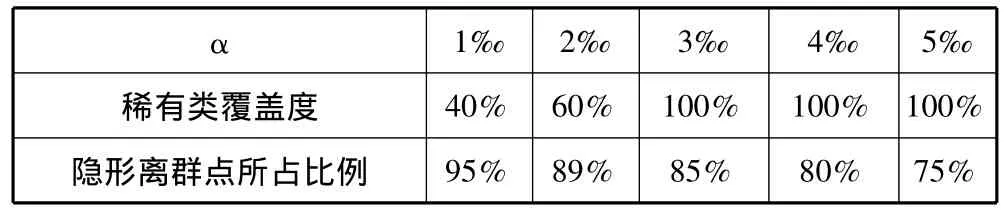
表3 Abalone数据实验结果评价表
数据2 使用UCI网站的SPECTF Heart Data Set,该数据包含265个数据,45个维,每个数据描述一个病人的心脏诊断数据,其中第一维是综合诊断结果,由一个二进制数0或者1表示,其中0表示不正常,1表示正常,即本数据集包含两个类,一类数据为“心脏正常”,另一类为“心脏不正常”,数据中不正常数据即为离群点。实验找出这些离群点并分析病人的哪些属性不正常则可判定心脏不正常。
本实验设 s=25,α=2%,ε=0.6,以第 26维KNN直方图为例,如图2所示。
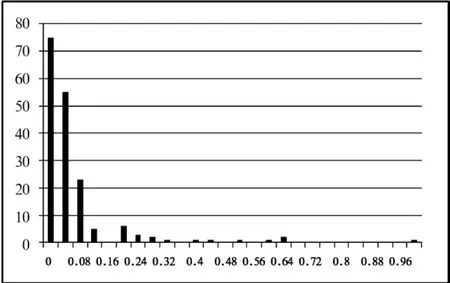
图2 第26维KNN直方图
通过直方图以及算法分析得到每个离群点以及离群维的对应关系表,如表4所示。
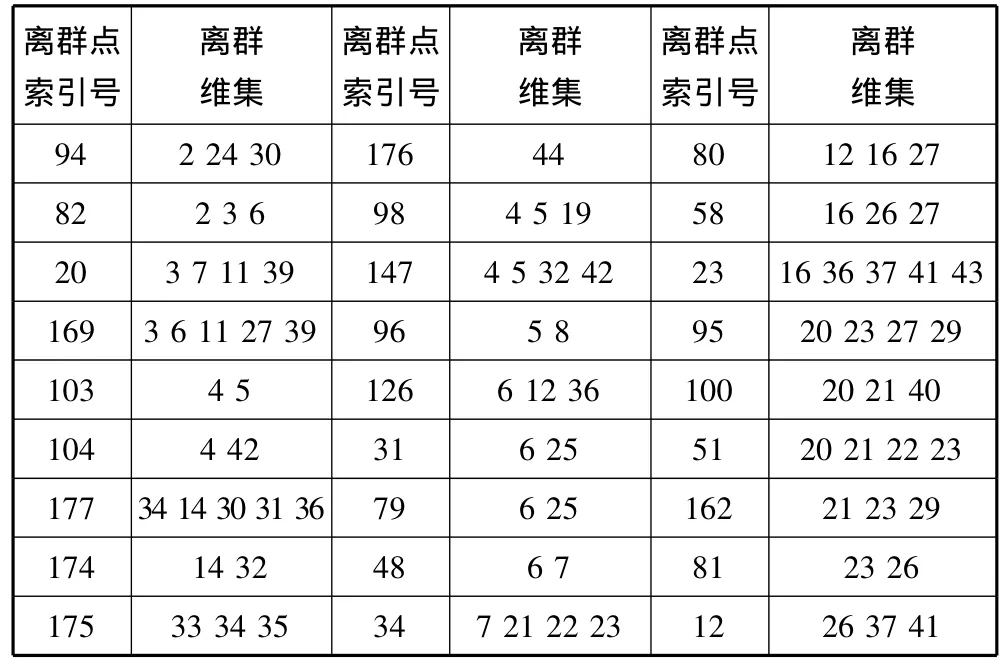
表4 离群点-离群维对应关系表
对该离群点-离群维关系对应表进行FP分析以发现离群维之间的关系如表5所示。
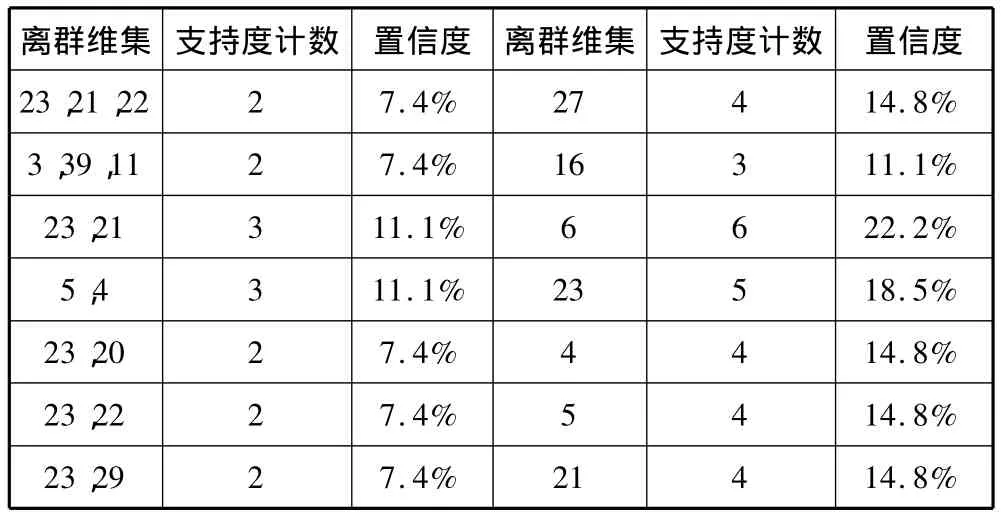
表5 SPECTF Heart Data Set数据实验结果分析表
经数据分析,实验结果中索引号174-177对应的数据为心脏不正常的病人数据,主要在F7R、F16R、F16S、F17R、F17S以及F22R属性出现异常从而被诊断为心脏病;其余数据显示出这些病人虽在某些指标上数据异常,但是对心脏健康影响不大,其中F3R、F11R、F10R、F13R以及F2S属性上出现问题的较多。
实验结果评价表如表6所示。
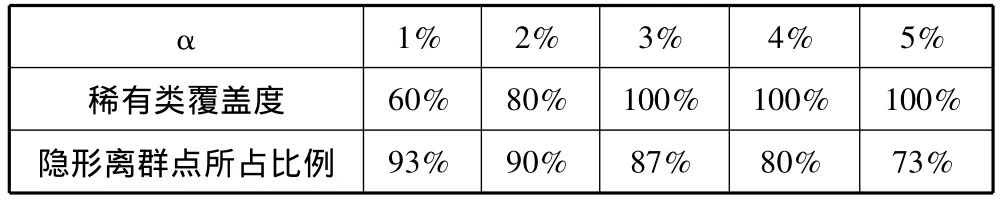
表6 SPECTF Heart Data Set数据实验结果评价表
4 结束语
实验表明,本文提出的离群点挖掘方法能有效地挖掘出数据集中的稀有类即离群点,并且除了全局离群点之外,也能找出隐形离群点,用FP增长算法对离群点的离群维进行分析,得出离群维之间的关联规则,从而合理地解释了离群点的物理意义;实验结果的准确度分析说明挖掘结果准确有效,本方法具有很好的应用价值。
[1]Hawkins D.Identifications of Outliers[M].London:Chapmanand Hall,1980.
[2]薛安荣,姚琳,鞠时光,等.离群点挖掘方法综述[J].计算机科学,2008,35(11):13-18,27.
[3]Rousseeuw P J,Leroy A M.Robust Regression and Outlier Detection[M].New York:John Wiley&Sons,1987.
[4]Johnson T,Kwok I,Ng R T.Fast computation of 2-dimensional depth contours[C]//Proceedings of the 4th International Conference on Knowledge Discovery and Data Mining.New York:AAAI Press,1998:224-228.
[5]Jain A K,Murty M N,Flynn P J.Data clustering:A review[J].ACM Computing Surveys,1999,31(3):264-323.
[6]Breunig M M,Kriegel H P,Ng R T,et al.LOF:Identif-ying density-based local outliers[C]//Proceedings of the 2000 ACM SIGMOD International Conference on Management of Data.Dallas:ACM Press,2000:93-104.
[7]Knorr E,Ng R.Algorithms for mining distance based outliers in large datasets[C]//Proceedings of the 24th VLDB Conference.New York:Morgan Kaufmann,1998:392-403.
[8]Beyer K,Goldstein J,Ramakrishnan R.When is nearest neighbours meaningful?[C]//Proceedings of the 7th International Conference on Data Theory.1999:217-235.
[9]Aggarwal C C,Yu P.Outlier detection for high dimensional data[C]//Proceedings of the ACM SIGMOD International Conference on Management of Data.Santa Barbara,2001:37-47.
[10]Aggarwal C C.Redesigning distance functions and distance based applications for high dimensional data[J].SIGMOD Record Date,2001,30(1):13-18.
[11]Angiulli F,Pizzuti C.Outlier mining in large high-dimensional data sets[J].IEEE Trans.Knowledge and Data Eng.,2005,17(2):203-215.
[12]Angiulli F,Basta S,Pizzuti C.Distance based detection and prediction of outlier[J].IEEE Trans.Knowledge and Data Eng.,2006,18(2):145-160.
[13]Sanghamitra B,Santanu S.A genetic approach for efficientoutlier detection in projected space[J].Pattern Recognition,2008,41(4):1338-1349.
[14]Jiawei Han,Micheline Kamber.Data Mining:Concepts and Techniques,Second Edition[M].Beijing:China Machine Press,2009.
[15]Yu Dantong,Gholamhosein S,Zhang Aidong.FindOut:Finding outliers in very large data sets[J].Knowledge and Information Systems,2002,4(4):387-412.
[16]Mohamed Bouguessa,Shengrui Wang.Mining projected clusters in high-dimensional spaces[J].IEEE Trans.Knowledge and Data Eng.,2009,21(4)507-522.
[17]Tan Pangning,Michael S,Vipin K.Introduction to Data Mining[M].New York:Addison Wesley,2006.
[18]许龙飞,熊君丽.基于粗糙集的高维空间离群点发现算法研究[J].计算机工程与应用,2004,40(7):58-60.
[19]Knorr E M,Ng RT.Algorithms for mining distance-based outliers in large datasets[C]//Proceedings of the 24th International Conference on Very Large Bases.New York,NY,1998.
[20]Markus MBreunig,Hans-Peter Kriegel.LOF:Identifying density-based local outliers[C]//Proceedings of ACM SIGMOD 2000 International Conference on Management of Data.Dalles,TX,2000:93-104.
