基于Hadoop的社交网络服务推荐算法
2013-10-15梅圣民
李 玲, 任 青, 付 园, 陈 鹤, 梅圣民
(吉林大学 通信工程学院, 长春 130012)
0 引 言
文献[1]对推荐问题进行了如下描述: 用C表示所有用户的集合,S表示所有可能被推荐项目的集合;u为一个效用函数, 表示项目s对用户c的有效性; 对于每个用户c′∈C, 选择一条项目s′∈S使用户c′的效用函数最大。
根据推荐方式的不同, 将推荐系统分为3类: 1) 基于内容的推荐(CBR: Content-Based Recommendation), 根据用户的历史使用记录推测出此用户的偏好, 并向该用户推荐符合其偏好的项目; 2) 协同过滤推荐(CFR: Collaborative Filtering Recommendation), 推测出所有用户的偏好, 具有相似偏好的用户之间互为邻居, 针对特定用户, 根据其邻居的使用情况向其推荐相应的项目; 3) 混合推荐(HR: Hybrid Recommendation), 综合使用上述两种推荐方法。
基于内容的推荐最先应用于信息检索与信息过滤领域, 主要对由文本信息组成的项目进行推荐。推荐之前, 通常需要提取用户和待推荐项目的关键词, 以描述用户的偏好和待推荐项目的特征。在推荐过程中, 通过计算用户偏好和待推荐项目特征之间的相似度, 决定是否向该用户推荐该项目。比较典型的有TF-IDF(Term Frequency-Inverse Document Frequency)算法[2]、 Rocchio算法[3]和贝叶斯分类算法[4]。
协同过滤推荐系统主要应用于电子商务中, 其算法可分成基于记忆的和基于模型的两大类[5]。其中基于记忆的算法根据用户的历史评分集合预测新的评分, 使用朴素贝叶斯或皮尔逊相关进行计算。而基于模型的算法根据所使用的模型不同, 可分为BC(Bayesian Clustering)算法、 AM(Aspect Model)算法、 JMM(Joint Mixture Model)算法、 FMM(Flexible Mixture Model)算法和DM(Decoupled Models)算法等。
然而, 基于内容的推荐不能为新用户提供有效的推荐, 协同过滤推荐不能将新项目推荐给合适的用户。为克服上述问题, 一些研究者将这两种方法进行整合形成了混合推荐。通过不同的方式整合会形成不同的混合推荐方法: 1) 独立使用基于内容的推荐和协同过滤推荐, 整合其预测结果[6]; 2) 将基于内容的推荐加入到协同过滤推荐模型中, 如Fab系统和按内容协作方式[7]; 3) 将协同过滤推荐加入基于内容的推荐模型中; 4) 整合两种方式, 构建一个通用的统一模型[8]。
目前推荐系统多在单服务器上实现, 系统的容错性和可扩展性较差。笔者针对社交网络设计了分布式推荐算法。该推荐算法在Hadoop云平台上实现, 具有更好的容错性和可扩展性。
1 基于Hadoop的社交网络服务推荐系统框架
在云计算平台上实现社交网络服务推荐系统, 可解决超大规模数据集的存储问题, 可处理难题, 并能保证系统的可扩展性。国际上已有一些学者在云计算平台上进行社交网络相关的研究, 其中文献[9-11]在MapReduce上进行社交网络数据分析, 文献[12]在Hadoop平台上实现了基于用户的协同过滤推荐算法。借鉴以上的研究基础, 笔者在开源云平台Hadoop上进行社交网络服务推荐的研究, 其系统框架如图1所示。该系统主要包括数据采集模块、 数据预处理模块、 数据存储模块和服务推荐模块。
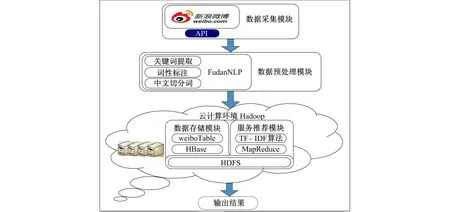
图1 基于Hadoop的社交网络服务推荐系统
1.1 数据采集模块
笔者采用新浪微博API(Application Programming Interface)采集用户数据, 客户端需要下载SDK(Software Development Kit)包进行开发。之后, 客户端通过HTTP(Hypertext Transfer Protocol)协议与新浪微博服务器进行数据交互。
1.2 数据预处理模块
采集到用户的微博信息后, 需要对微博进行中文切分词的处理, 笔者中分词系统的设计原则如下:
1) 具备较强的学习能力, 能进行扩展训练, 便于新词的识别;
2) 响应速度快, 不能让用户感到不可忍受的延时;
3) 易于扩展升级, 便于提升分词能力。
基于以上几点, 笔者选择了复旦大学中文自然语言平台FudanNLP[13]。FudanNLP除了具有分词功能外, 可进行词性标注, 还实现了基于TextRank算法的关键词提取程序。由于微博中的关键词多为名词和动词, 笔者对经过分词的结果进行词性标注, 提取名词和动词。为验证笔者的分布式TF-IDF算法的有效性, 笔者利用FudanNLP中TextRank算法提取关键词, 并与分布式TF-IDF算法的结果进行对比。
1.3 数据存储模块
由于用户频繁更新微博, 导致新浪微博的用户数据量非常大[14], 为实现可靠的、 可扩展的存储, 笔者在HBase分布式数据库中创建weiboTable表, 用于存储经过预处理的用户数据。
为获取更多微博数据, 在实验过程中反复进行微博数据的抓取。由于HBase数据库以追加的方式写入数据, 用时间戳表示数据的不同版本, 因此, 可保证新的数据不会覆盖旧的数据。
1.4 服务推荐模块
笔者在MapReduce模型上实现分布式TF-IDF算法, 利用该算法统计微博中每个词的重要性, 提取微博中的关键词, 并根据这些关键词进行相应的推荐。
TF-IDF采用统计方法评估某一词语在某个文件中的重要性。词频TF是指某个词语在某文件中出现的频率; 逆向文件频率IDF指某个词语在所有文件中的普遍重要性, 它可由文件总数目除以包含该词语的文件数目再取对数得到。TF-IDF的主要思想是: 代表某一文件属性的词语必须具有很高的辨识度, 即这些词语在本文件中出现的频率很高, 而在其他文件中则很少出现。
在TF-IDF方法中, 假设N是文档总数量, 关键词ki在ni个文档中出现,fi,j是关键词ki在文档dj中出现的次数, 则关键词ki在文档dj中出现的频率
(1)
关键词ki的Ii计算如下
(2)
文档dj中关键词ki的重要性通过TF-IDF权重wij定义,wij的计算方法如下
wi,j=Ti,j×Ii
(3)
2 TF-IDF算法MapReduce化

图注: offset: 行偏移量; content: 每行中的内容; filename: 文件名; word: 词语; CiNum: filename中所有词出现的次数之和; TF: word在filename中出现的频率; IDF: word的逆向文件频率; TF-IDF: word的TF_IDF权重。
在MapReduce模型中, 一个任务的执行可分为Map和Reduce两个过程。即执行一个任务时, 需要开发者实现Map和Reduce两个函数。由于Map和Reduce函数的输入输出数据均为〈key, value〉对的形式, 因此需要对TF-IDF算法进行MapReduce化的设计。笔者将TF-IDF算法分解成4个任务顺序执行(见图2), 4个任务主要完成的工作如下所述。
Job1: 以/input目录下的所有文件作为输入, 统计每个文件中所有词语出现的次数之和。
Job2: 以Job1的输出文件作为输入, 统计每个文件中每个词语出现的次数, 用某一词语出现的次数除以该文件中所有词语出现的次数之和, 得到该词语在该文件中出现的频率TF。
Job3: 以Job2的输出文件作为输入, 计算每个文件中每个词语的IDF和TF-IDF。
Job4: 以Job3的输出文件作为输入, 将Job3的输出结果按TF-IDF从大到小的顺序进行排序。
3 分布式TF-IDF算法与TextRank算法的对比
3.1 准确性对比
为验证笔者的分布式TF-IDF算法的准确性和有效性, 用FudanNLP对微博进行关键词提取, 作为对比, FudanNLP中使用的关键词提取算法为TextRank算法。笔者从Job4的输出结果中提取TF-IDF最大的前N个词语, 作为某一用户的关键词; 同时用FudanNLP中的Extractor类提取N个关键词作为对比。实验中将N分别选取为5、10、15, 具体的实验结果如图3~图5所示。其中 “〈〉”中的内容为微博的用户名, 后面的词语为微博中的关键词, 数字表示该关键词的权重。

a 分布式TF-IDF算法 b TextRank算法

a 分布式TF-IDF算法 b TextRank算法

a 分布式TF-IDF算法 b TextRank算法
由图3~图5可看出, 笔者的分布式TF-IDF算法和TextRank算法提取的关键词比较接近, 并且随着关键词数目的增加, 二者的结果变得更加接近。对比证明, 基于MapReduce的分布式TF-IDF算法是准确的、 有效的。两种算法提取关键词的结果稍有不同, 主要表现为关键词的排序不同, 这是由于算法的本质不同所造成的。分布式TF-IDF将在笔者文档中出现次数多而在其他文档较少出现的词赋予较高的权重, 即用辨识度比较高的关键词描述文档的特性; 而TextRank算法只考虑词语在笔者文档中的重要性, 不考虑词语在其他文档中的情况。通过理论分析和实践证明, 采用笔者的分布式TF-IDF算法提取的关键词更能表征用户的个性。
3.2 可扩展性对比
为论证基于Hadoop的分布式TF-IDF算法具有较强的可扩展性, 笔者用TextRank算法作为对比, 通过实验观察两种算法处理不同大小文档时的响应时间。实验中, 笔者选取了10种不同大小的文档集合, 针对每个文档集合分别做5次实验。在5次实验结果中, 去掉最长和最短的响应时间, 余下的结果求平均值, 最后得出的平均响应时间如图6所示。

图6 分布式TF-IDF算法和TextRank算法的响应时间
由图6可看出, 随着文件大小的增加, 两种算法的响应时间均增加, 但分布式TF-IDF算法的增加明显低于TextRank算法。当文件小于0.8 MByte时, 由于Hadoop集群中节点之间的通信需要花费一定时间, 所以分布式TF-IDF算法的响应时间长于TextRank算法; 当文件达到0.8 MByte时, 两者的响应时间几乎相当; 随着文件大小继续增加, 分布式TF-IDF算法的响应时间缓慢增加, 而TextRank算法的响应时间急速增加。由此可见, 分布式TF-IDF算法具有良好的可扩展性, 适合处理大型数据。
4 结 语
为处理社交网络中的海量用户数据, 发现用户的兴趣, 并据此为用户推荐个性化的服务, 笔者设计了一种基于Hadoop的社交网络服务推荐系统, 并在MapReduce模型上实现了分布式的TF-IDF算法。为了验证笔者中分布式TF-IDF算法的有效性, 用TextRank算法对微博进行关键词提取以作为对比。结果表明, 两种算法提取出的关键词比较接近, 并且随着关键词数目的增加, 二者的结果变得更加接近, 充分证明了分布式TF-IDF算法是准确、 有效的。同时, 由于分布式TF-IDF算法考虑到了关键词的辨识度问题, 它在提取微博关键词时, 较TextRank算法表现更优。此外, 通过与TextRank算法进行响应时间的对比, 可看出, 分布式TF-IDF算法具有良好的可扩展性。
参考文献:
[1]GEDIMINAS A, ALEXANDER T. Toward the Next Generation of Recommender Systems: A Survey of the State-of-the-Art and Possible Extensions [J]. IEEE Transactions on Knowledge and Data Engineering, 2005, 17(6): 734-749.
[2]WANG Na, WANG Peng-yuan, ZHANG Bao-wei. An Improved TF-IDF Weights Function Based on Information Theory [C]∥Proceedings of the International Conference on Computer and Communication Technologies in Agriculture Engineering(CCTAE). Chengdu, China: [s.n.], 2010: 439-441.
[3]AGO Guan-yu, GAUN Sheng-xiao. Text Categorization Based on Improved Rocchio Algorithm [C]∥Proceedings of the International Conference on Systems and Informatics. Yantai, China: [s.n.], 2012: 2247-2250.
[4]HE You-quan, XIE Jian-fang, XU Cheng. An Improved Naive Bayesian Algorithm for Web Page Text Classification [C]∥Proceedings of the Eighth International Conference on Fuzzy Systems and Knowledge Discovery(FSKD). Shanghai, China: [s.n.], 2011: 1765-1768.
[5]LIN Kun-hui, ZHANG Lei-lei, DENG Xiang. Optimized Collaborative Filtering Algorithm Based on Item Rating Prediction [C]∥Proceedings of the Second International Conference on Instrumentation, Measurement, Computer, Communication and Control(IMCCC). Harbin, China: [s.n.], 2012: 648-652.
[6]BILLSUS D, PAZZANI M. User Modeling for Adaptive News Access [J]. User Modeling and User-Adapted Interaction, 2000, 10(2/3): 147-180.
[7]PAZZANI M, BILLSUS D. Learning and Revising User Profiles: The Identification of Interesting Web Sites [J]. Machine Learning, 1997, 27(3): 313-331.
[8]SCHUBIGER S, HIRSBRUNNER B. A Model for Software Configuration in Ubiquitous Computing Environments [C]∥Proceedings of the First International Conference on Pervasive Computing. Zurich, Switzerland: [s.n.], 2002: 181-194.
[9]HYEOKJU LEE, JOON HER, SUNG-RYUL KIM. Implementation of a Large-Scalable Social Data Analysis System Based on MapReduce[C]∥Proceedings of the First ACIS/JNU International Conference on Computers, Networks, Systems, and Industrial Engineering. Jeju Island, Korea: [s.n.], 2011: 228-233.
[10]LIU Guo-jun, HANG Ming, YAN Fei. Large-Scale Social Network Analysis Based on MapReduce [C]∥Proceedings of the International Conference on Computational Aspects of Social Networks. Taiyuan, China: [s.n.], 2010: 487-490.
[11]KAI Shuang, YIN Yang, BIN Cai, et al. X-RIME: Hadoop-Based Large-Scale Social Network Analysis [C]∥Proceedings of the 3rd IEEE International Conference on Broadband Network and Multimedia Technology(IC-BNMT). Beijing, China: [s.n.], 2010: 901-906.
[12]ZHAO Zhi-dan, SHANG Ming-sheng. User-Based Collaborative-Filtering Recommendation Algorithms on Hadoop [C]∥Proceedings of the Third International Conference on Knowledge Discovery and Data Mining. Phuket, Thailand: [s.n.], 2010: 478-481.
[13]NORMASLINA JAMIL, ARIFAH CHE ALHADI, SHAHRUL AZMAN NOAH. A Collaborative Names Recommendation in the Twitter Environment Based on Location [C]∥Proceedings of the International Conference on Semantic Technology and Information Retrieval. Putrajaya, Malaysia: [s.n.], 2011: 119-124.
[14]XIA Tian, CHAI Yan-mei. An Improvement to TF-IDF: Term Distribution Based Term Weight Algorithm [J]. Journal of Software, 2011, 6(3): 413-420.
