基于空间位置关系改进的物体识别上下文模型
2013-10-08李宏伟徐晓滨文成林
李宏伟,徐晓滨,文成林
(杭州电子科技大学系统科学与控制工程研究所,浙江杭州310018)
0 引言
常见的单目标检测器仅仅能够识别图像局部的特定物体种类,检测结果可能在图像上下文中形成语义冲突[1]。大量关于视觉认知和认知神经的研究表明,人类对实际场景的理解总是建立在一定的上下文信息基础之上[2]。针对上下文信息利用的研究已取得很大进展。文献[3]首先利用局部特征来预测每个结点的标签,然后利用同现性关系来来调整已预测的物体标签。文献[1]提出了一种基于树模型表示的上下文模型(Tree-Context),本文在其基础上,进一步考虑了物体的空间位置关系信息,将多种信息源整合到同一个概率框架中,利用树结构图模型高效推理的优势来完成图像中的物体识别,所得到的检测结果能够改进物体的识别性能,并给出了具有一致性的场景解释。
1 基于空间位置改进的物体识别上下文模型
本文模型在Tree-Context模型基础上进一步整合了空间位置关系信息,为区别于文献[1]提出的上下文模型,命名本文所给出的上下文模型为Relation-Context模型。主要由上下文模型建模、模型学习和模型推理3部分组成。
1.1 上下文模型建模
上下文模型由先验模型和量测模型两部分组成。先验模型是由训练得到的先验知识所建立的,借助于树结构图模型来表示,包含同现性先验模型、空间位置先验模型和空间关系先验模型3部分。而量测模型由待检集合学习得到,包括全局图像特征、局部位置和空间关系量测模型。

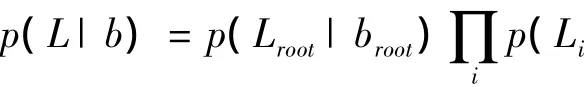
两两物体之间的空间相对位置关系对于目标识别十分重要。文献[4]指出,图像中分割区域的关系可以量化为5种关系:上、下、内、外、周围。本文在此基础上将物体之间的空间关系改为上(UP)、下(DOWN)、周围(AROUND)、重叠(OVERLAP)4种。其中物体的内外关系以及重叠程度均可以由重叠属性来表示,物体的空间关系表示为:

这样物体 i和 j的关系可以表示为一个向量:rij=[wupij,wdownij,waroundij,woverlapij]。
量测模型包括图像全局特征和局部检测器输出两部分。概要描述子(gist descriptor)[5]是图像的一种低维表示,刻画了图像的粗纹理和空间布局。对于待检图像中的每个候选窗口,检测器都给出了一个检测得分sik以及位置变量Wik。图1(b)给出了物体i的量测模型,已将gist和基线(baseline)检测器的输出整合到了先验模型中,阴影框来表示物体i的不同候选窗口。
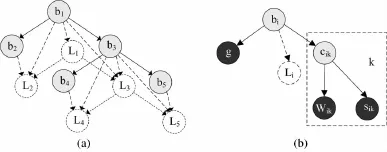
图1 上下文图模型表示
1.2 模型学习
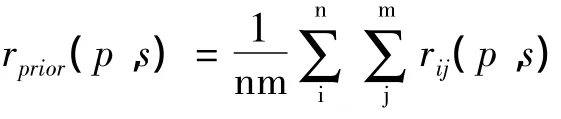
在量测模型中,p(g|bi)可以从训练图像的gist descriptors训练得到。p(cik|sik)可以经由logistic回归训练得到,进而可计算出p(sik|cik)=p(cik|sik)p(sik)/p(cik)。正确检测概率p(cik|bi)可以通过计算训练集合中标签总数和正确检测个数计算得到。
1.3 利用树模型进行交替推理
基于上下文的物体识别任务就是在给定概要描述子g、基线检测器得到的候选窗口位置变量W={Wik}和窗口得分s={sik}以及空间先验关系R={Rijk}条件下,推理得到图像中物体是否出现b={bi}、该检测是否正确c={cik}、以及物体的期望位置L={Li}。该问题可以通过以下优化问题解决:

因为模型中即包含二元变量也有高斯变量,精确推理很困难,需要利用1.2节中树模型推理算法来进行迭代推理求解。在变量b和c已知条件下,位置变量L构成高斯树;而在L和R条件下,变量b和c共同构成二元树模型。因此,可采用交替推理的方式来得到b,c,L。算法推理步骤如下:
(1)在第一次迭代过程中,忽略位置信息W,由空间关系R,gist和窗口评分给出b和c的估计b^,c^=argmaxb,cp(b,c|s,g);
(2)计算b和c的最大后验估计L^=argmaxLp(L|b^,c^,W),以及两两物体的空间关系R^=argmaxRp(R|b^,c^,W)。然后利用高斯树模型推理可得到物体的期望位置;
(3)然后在位置估计L^条件下,可以重新估计变量 b 和 c:b^,c^=argmaxb,cp(b,c|s,g,L^,R^,W);
(4)最后一步,每个计算b和c联合分布的边缘概率。p(bi=1|s,g,L^,R^,W)即为出现预测,而检测变量边缘概率 p(cik=1|s,g,L^,R^,W)即为检测的正误。
2 仿真验证
本文利用SUN09数据集来进行算法评估。将SUN09数据集分为训练集和测试集,首先用基线检测器对训练集和测试集进行物体检测识别,得到的结果包括检测候选窗口和检测评分。部分实验结果示例如图2所示,从左到右依次是基线检测器、Tree-Context和Relation-Context模型的检测结果,通过分析检测结果可看出上下文模型对于物体检测性能的改进。

图2 各种上下文模型检测结果
上下文模型的显著优势在于可将上下文语义冲突的检测结果过滤掉,图2(a)中两个上下文模型都将检测结果中不符合场景上下文的cupboard筛选掉,同样还有图2(b)中rocks等。此外本文算法由于充分利用了物体的位置空间关系,进一步提高了物体检测正确率。例如图2(a)中Relation-Context检测结果6(window[0.04]),根据空间关系模型“窗户”总是位于“楼房”内部,该结果符合这一关系因而具有较高置信度。
模型位置预测精度和出现预测精度的对比如图3所示。由图3可看出,对于物体出现位置预测两种上下文模型改进效果很接近,这是因为基于空间关系改进主要是关注物体的出现是否符合常规位置,而不对位置做预测改进。而在出现预测精度上,Relation-Context模型更加充分的利用了上下文信息,相对于Tree-Context模型取得了较大改进。

图3 模型位置预测精度和出现预测精度的对比
3 结束语
上下文信息包含了场景信息以及物体之间彼此联系的丰富信息,可作为图像低维特征补充来提高目标识别率。本文在原有上下文模型基础上,进一步考虑了物体的空间位置关系信息,将多个信息源整合到同一个概率框架中,并充分发挥树结构图模型高效推理的优势,完成图像中物体的目标识别。此外,本文也存在一些不足和亟待完善的地方,如对于目标空间关系信息的建模利用的是物体在原始图像中的位置,未考虑图像扭曲、图像采集角度等因素,这些问题需要在下一步研究中进行研究与改进。
[1]Choi M J,Torralba A,Willsky A S.A tree-based context model for object recognition[J].Pattern Analysis and Machine Intelligence,IEEE Transactions,2012,34(2):240 - 252.
[2]高常鑫.基于上下文的目标检测与识别方法研究[D].武汉:华中科技大学,2010.
[3]Rabinovich A,Vedaldi A,Galleguillos C.Objects in context[C].Rio de Janeiro:IEEE 11th International Conference on Computer Vision,2007:1 -8.
[4]Galleguillos C,Rabinovich A,Belongie S.Object categorization using co-occurrence,location and appearance[C].Anchorage:IEEE Conference,Computer Vision and Pattern Recognition,2008:1 -8.
[5]Murphy K,Torralba A,Freeman W.Using the forest to see the trees:a graphical model relating features,objects and scenes[J].Advances in neural information processing systems,2003,16:1 499 -1 507.
