基于Nutch的页面排序算法研究
2013-10-08胡维华曹奇峰
胡维华,曹奇峰
(杭州电子科技大学计算机学院,浙江杭州310018)
0 引言
如何高效、快速、准确地查找所需信息是当前搜索引擎最需要考虑的问题。搜索引擎根据用户提交的检索词会返回海量结果集,找到所需的信息需耗费大量时间。基于随机游走模型的PageRank算法[1]曾经很成功地解决了页面排序问题,但随着互联网几何级的数据增长,经典PageRank算法[2]已经无法满足用户的需求。许多学者根据该算法提出了自己的改进方案。Topic-Sensitive PageRank算法[3]和MP-PageRank算法[4]通过改变平均权值的方式,一定程度上修正了主题漂移问题。Nutch[5]作为开源的搜索引擎为研究人员提供了很好的选择。Nutch的排序算法[6-7]是针对通用搜索引擎设计的一种类似PageRank的在线分析算法。该排序算法有明显不足:平分链出网页的权值;偏重历史网页;忽略网页内容的相关性。这些因素都会影响网页的排序质量。本文做了一些改进:区分站内与站外链接的权值;加入时间因素,加速陈旧页面权值下降速率;基于向量空间模型计算页面内容相似性。
1 相关工作
网页搜索结果排序算法是搜索引擎最关键的技术构成,影响结果排序有多种因素,其中最重要的是用户查询和网页内容的主题相关性以及网页链接权威性。
1.1 向量空间模型
向量空间模型把每个文档表示成向量形式[8]。假如有主题词库K(k1,k2,k3,…kn)和页面Pi(Wi1,Wi2,Wi3,…Win),n为主题词库K中关键词个数,Wij是主题词库中关键词kj在页面Pi中的权值,它反映了kj对文本信息的表达能力。Wij采用Tf-IDF算法计算,其公式为:

由式1知,如果关键词kj在一个文档中出现的频率越高,在其他文档中出现的频率越低,则该关键词包含的信息量高,权重就越大。
1.2 RageRank算法
PageRank算法可以看做用户在网络拓扑图中的随机游走模型来解释。假设用户每次按统一概率d在当前页面提供的超链接中选择下一步要访问的链接,当用户在浏览到某一网页放弃继续点击超链接,以概率1-d开始新的游走行为,在任何时刻,用户在网页P的概率为:

2 基于PageRank算法改进的页面排序算法
2.1 区分站内和站外链接
经典的PageRank算法将网页P的PR值平均的分配给网页P所指向的链接网页,但并不区分链接出去的页面的权威度。也就是说,一个页面P的PR值只与页面P的入度和指向P的页面的PR值有关,因此网络的拓扑结构决定了节点的重要性。然而,一个网页中链出网页的权威度参差不齐。不能很客观的反映出链接内容的重要性。而且,有些网页设计者会利用添加本站的导航和广告网页链接进行作弊行为,用来提高本站的搜索排名。因此经典PageRank算法平均分配页面权值是不合理的。本文对式2进行改进如下:
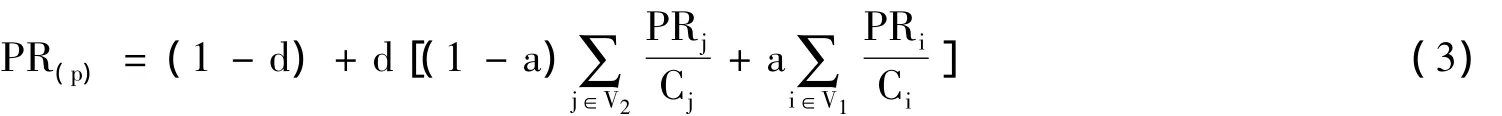
a(0<a<1)为控制站内和站外链接的比重因子。一般站外链接比站内链接更能客观体现链接内容的重要性,a取0.75。V1表示页面P的所有入链中与P不是同一站点的网页集合,Ci,Cj分别表示投票页面i和j的所有链出页面的链接数。V2表示网页P的所有入链中与P是同一站点的网页集合。通过控制站外与站内链接的比重来重新分配权值。避免了经典算法中平均分配权值,考虑设计者通过作弊手段提高本站地址的权重,提高查找质量。
2.2 时间衰减因子
经典的PageRank算法通过链接关系来对网页进行权重分配。在互联网上存在时间越长的页面越容易被更多的页面链接。新的页面即使网页内容比较重要,被其他网页链接也需要一个过程。针对PageRank偏重历史页面的问题,引入时间因子来对旧网页做一个权值衰减过程。在式3的基础上改进如下:
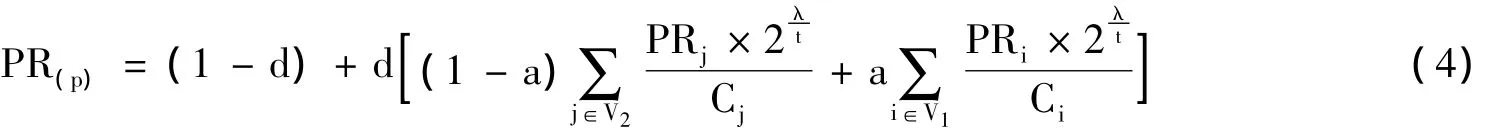
式中,t为页面存在的时间,λ为常数因子。通过加入时间衰减因子λ,能有效抑制互联网上存在久的网站的权重增长的速度,使得新站不被老站埋没。
2.3 内容相似性计算
PageRank算法是利用网络结构中的反向链接信息对网页进行排序,它是一种与主题无关的排序算法。然而用户浏览网页时,一般都选择与当前页面主题相关度较大的链接进行页面跳转。针对经典PageRank存在主题漂移的问题,在算法中加入主题相关度因子来提高主题相关页面的权重。假设有页面 P1(W11,W12,W13,…W1n)和主题向量 P2(W21,W22,W23,…W2n),则网页 P1的主题相似性利用特征向量之间的余弦夹角公式得:
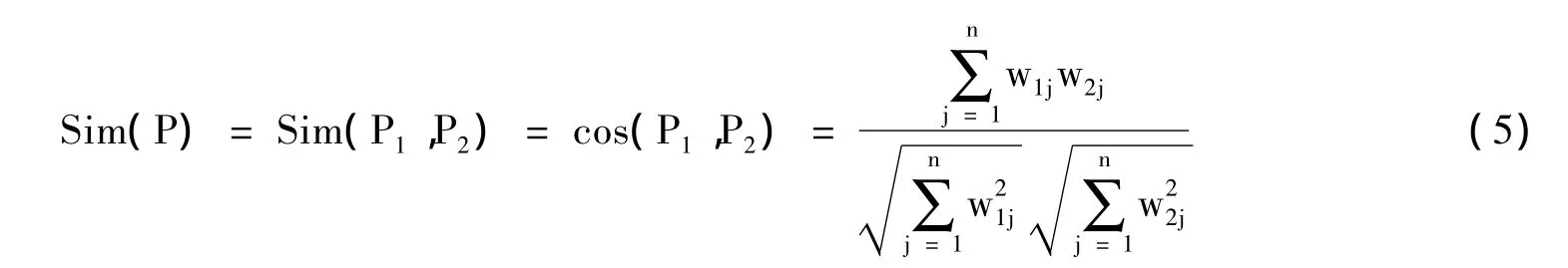
式中,Wij为根据式1计算的相应权值。
最后网页综合排序模型对得到的主题向量和本页面的主题相关度Sim(P)和改进的PR值赋予不同的权重,则网页的相似性评分函数由式4、5得:

r1、r2分别为主题相关度的权重和PR值的权重,r1+r2=1。将主题相关度和链接分析相结合,不仅能够体现链接的权威性,还能体现网站主题的相关性,可以提高排序结果的质量,增强用户的检索体验。
3 实验与分析
实验基于Nutch网络爬虫技术,对互联网上的食品安全信息进行数据采集和正文信息抽取,然后基于Lucene[9]的全文检索工具包,对本地数据进行分词、倒排索引、索引检索和改进的相关度排序等处理,最终设计实现了一个面向食品安全信息垂直搜索引擎。
搜索引擎查询结果的效果通常由查准率来衡量查找过滤不相关文档的能力,本实验重点检查排序算法改进后的查准率,即前N个查询结果中和查询相关的网页数与N的比率。本实验将一些食品安全的网站(中国食品安全网、掷出窗外等)首页地址作为Nutch爬虫的入口地址集合,总共爬取了11 275张网页,把这些网页作为实验文档集。对Nutch网页排序算法改进之后,通过在搜索页面输入查询词,进行Nutch改进前后查准率和排序效果的对比实验。在实验中选择了食品安全方面的4个关键字进行搜索。对每十条记录进行一次查准率分析比较,结果如图1所示。

图1 算法改进后各关键词查准率对比
将4个关键词按算法改进前进行搜索,并计算其平均值,与图1的结果平均值进行比较,比较结果如图2所示。
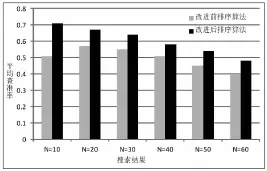
图2 算法改进前和改进后平均查准率对比
从图1可以看出,每个关键词得出的查准率不相同,并且前十条记录的查准率基本上都在0.6之上,说明改进的排序算法能够很好的区分网页,将相关度较高的网页排在搜索结果的前面。
从图2可以看出,通过修改排序算法,Nutch改进后的查准率明显要高于改进前,尤其是搜索结果的前列,改进后的算法要优于改进前。说明该算法优化了排序质量,更符合广大用户的需求,具有现实可行性。
4 结束语
基于Nutch的垂直搜索引擎对网页排序算法的主题相似性要求非常高。经典的PageRank算法平均分配链出的PR值,没有考虑链出页面的权威性,并且忽略查询的主题与内容,容易导致主题漂移等问题。本文在分析和研究原始算法的基础上,区分站内与站外链接的权重,修正算法中偏重历史网页的问题,并且加入内容相似性计算。实验表明,改进后的算法可以明显提高用户的查准率,提高用户搜索的效果。下一步的工作是考虑在Nutch评分中加入用户使用习惯的因素,进一步改进排序效果。
[1]Sergey Brin,Lawrence Page.The PageRank Citation Ranking:Bring Order to the Web[C].Stanford:Computer Science Department,1998:107 -117.
[2]Pasquinelli M.Google's pagerank algorithm:a diagram of cognitive capitalism and the rentier of the common intellect[J].Deep Search,2009(3):152 -162.
[3]Haveliwala.Topic-Sensitive PageRank:A Context-Sensitive Ranking Algorithm for Web Search[J].IEEE Transactions on knowledge and data engineering,2003,15(4):784 -796.
[4]Richardson M,Domingos P.The intelligent surfer:probabilistic combination of link and content informaionin in PageRank[J].Advances in Neural Information Processing Systems,2002,14(3):1 441 -1 448.
[5]张文龙,刘一伟,孙杰.基于Nutch的垂直搜索引擎的研究[J].南开大学学报(自然科学版),2012,45(2):37-44.
[6]陶林,谌超,强保华,等.基于Hadoop的Nutch网页排序算法研究与实现[J].桂林电子科技大学学报,2013,33(2):139-143.
[7]潘涛,梁正友.Nutch中网页排序效果的改进方法[J].计算机工程,2010,26(13):42-44.
[8]Eric J Glover,Kostas Tsioutsiouliklis,Steve Lawrence,etal.Using web structure for classifying and describing web pages[C].New York:Proceedings of the 11th international conference on World Wide Web,2002:562 -569.
[9]李永春,丁华福.Lucene的全文检索的研究与应用[J].计算机技术与发展,2010,20(2):12-15.
