基于SVM的并行网络流量分类方法
2013-09-11陶晓玲李平红
裴 杨,王 勇+,陶晓玲,李平红
(1.桂林电子科技大学 计算机科学与工程学院,广西 桂林541004;2.桂林电子科技大学信息与通信学院,广西 桂林541004)
0 引 言
网络流量分类是实现网络可控性的基础技术,它能够帮助网络管理人员分析网络中的流量分布,有效地对网络状况进行监控,使因特网服务提供商 (internet service provider,ISP)为网络业务提供良好的服务质量 (quality of service,QoS)保障。由于越来越多新型网络应用采用动态端口、伪装端口和应用层净荷加密等网络技术,导致传统的基于端口和特征字段的网络流量分类方法失效[1]。基于流统计特征的机器学习流量分类方法不依赖匹配协议端口或解析协议内容识别网络应用,不受动态端口、载荷加密、网络地址转换等网络技术的影响[2]。与传统网络流量分类方法相比,其在分类性能、灵活性以及可扩展性等方面的表现更好,基于流统计特征的机器学习方法已经成为近年来研究的关注重点[3,4]。SVM算法具有良好的泛化能力,优良的分类准确率和稳定性[5]。彭勃[6]对基于流统计特征的六种分类算法进行比较,实验表明SVM算法具有较高的整体准确率和较好的计算性能,适合用于网络流量分类。许孟晋,张博锋[7]研究了SVM网络流量分类中分类效果和特征选择对分类效果的影响,实验结果表明,SVM对网络流量分类问题具有较高分类精度和稳定性,同时通过特征选择可以节省计算开销,在一定程度上提高分类效果。但SVM算法在处理大样本数据集时,计算复杂度高,训练速度慢。因此,许多研究学者针对SVM算法在大规模网络流量分类中存在的问题,提出了各自的改进方法。
Ning Jing等人[8]提出一个基于SVM的多级网络流量分类方法,组织多个二分类SVM形成一个淘汰赛结构进行分类,可极大地减少训练样本数量,同时对每个SVM进行单独的特征选择和参数选择;与传统方法相比,可减少7.65倍计算量,同时错误率降低2.35倍,唯一的缺点在于分类器缺乏稳定性。Xiang Li等人[9]提出一种基于半监督SVM的网络流量分类方法,采用一致性原则 (CBF)和信息增益原则 (IG)来选取流统计特征,实验证明半监督SVM方法与传统方法相比具有:①高分类精度;②高泛化性能;③快速的计算性能。邱婧等人[10]用SVM决策树进行网络流量分类,利用SVM决策树在多类分类方面的优势,解决SVM流量分类存在无法识别区域和训练时间较长的问题,实验表明SVM决策树比普通SVM有更短的训练时间和更好的分类性能,准确率达到98.8%。
以上研究学者的相关工作对SVM算法的时间消耗和准确率进行优化改进,但都没有彻底解决计算性能瓶颈问题。SVM算法的计算复杂度为O (n3),n为支持向量数量,其数量一般与样本集大小相关[11]。随着网络应用不断增加和网络速度不断提高,采集到网络流量样本规模不断增大,而单一节点的计算资源有限,面对大样本数据集时,其计算复杂度和时间消耗也会成倍增长,不能满足实时分类的要求,在很大程度上限制了SVM算法的应用。因此本文采用并行化方法,利用云计算平台多节点可扩展的强大计算能力,从根本上解决单一节点存在的计算资源不足的问题,在保证分类准确率的前提下,提高SVM算法在大样本数据集下的训练速度,减少网络流量分类的时间消耗。
1 基于SVM并行网络流量分类
SVM对训练集进行训练的过程实际上就是找出与最优分类函数有关的支持向量,而支持向量在整个训练样本集中所占的比例很小。利用这个特点,可以对训练数据集进行分块划分为多个子训练数据集,对每个子训练数据集单独进行训练,再收集各个子训练数据集得到的支持向量集,最后通过进一步的训练得到SVM分类模型。在这个过程中,多个子训练数据集的训练过程是独立且可以并行的,采用云计算平台对该训练过程进行并行化处理,可以有效地提高训练速度,又不会显著降低分类准确率。
在训练数据集分块划分为多个子训练数据集的过程中,如果进行随机划分,那么划分出的子训练数据集样本中可能只有很少的类别或者只有一个类别,在此情况下,子训练数据集进行训练时就会损失一些支持向量或者得不到支持向量,这会极大地降低分类准确率。为了避免这种极端情况的出现,在数据集分块划分时做一个预处理,对其按照类别比例随机抽样,再将抽取的样本划分给子训练数据集,这样就保证每个子训练数据集中都存在一定数量的各个类别的样本,在训练时尽量避免支持向量的损失,保证分类准确率不会显著降低。
1.1 并行网络流量分类模型
采用云计算平台Hadoop和MapReduce模型设计了一个两层架构的SVM并行网络流量分类模型,如图1所示。首先,将训练数据集上传至Hadoop分布式文件系统(HDFS)中进行预处理,按照前述的预处理过程抽取样本并划分成多个子训练数据集,即多个数据块,在图1中用数据块1到数据块n来表示。接着,创建第一层MapReduce任务,读取数据块内容,将数据按行组织成键值 (key,value)对发给Map函数,Map函数负责将对应数据块进行SVM训练,得到支持向量;Reduce函数将Map函数输出的支持向量进行合并等处理,再输出支持向量集,第一层的MapReduce过程在图1中用 MR′1到 MR′n来表示,MR′1到MR′n的SVM训练过程是相互独立且并行执行的。最后,创建第二层MapReduce任务MR′′1,Map函数将收集第一层的MapReduce过程中所有Reduce函数输出的支持向量集,在图1中用支持向量集1到支持向量集n来表示,对它们进行合并等处理,转发给Reduce函数;Reduce函数将经过Map函数处理的支持向量集作为训练样本进行SVM训练,生成并输出支持向量机分类模型用于分类。

图1 基于SVM的并行网络流量分类模型
1.2 方法步骤
根据提出的并行网络流量分类模型,结合MapReduce模型的编程思想,就可以设计一个基于SVM的并行网络流量分类方法,步骤如下:
(1)训练数据集上传到HDFS进行数据预处理,按照类别比例随机抽样,划分成n个子训练数据集;
(2)创建n个第一层MapReduce任务。每个任务分配一个子训练数据集,作为Map函数的输入;
(3)Map函数对输入子训练数据集进行SVM训练,Reduce函数将Map函数的输出进行合并等处理,并输出支持向量集;
(4)再创建一个第二层 MapReduce任务,将 (3)中全部n个Reduce函数输出的支持向量集作为Map函数的输入,进行汇总合并等处理;
(5)Map函数将处理好的支持向量集发给Reduce函数进行SVM训练,输出SVM分类模型;
(6)对得到的SVM分类模型,使用测试数据集进行分类测试,得到分类结果。
2 实验与分析
2.1 实验环境与数据集设置
本文中所使用的SVM算法来自于Weka机器学习库中的SMO算法,并对其进行了扩展、配置和打包生成MapReduce作业,使其可在Hadoop云平台上进行实验。本实验所用Hadoop集群共有3个节点,将Hadoop配置为全分布模式,其中一个节点配置为主节点,其它两个配置为从节点,集群的配置情况如表1和表2所列。
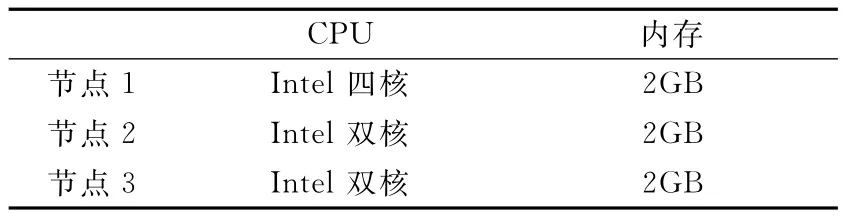
表1 Hadoop集群硬件配置情况

表2 Hadoop集群软件配置情况
为了测试网络流量分类的性能,本文采用网络流量数据集Moore_set,它是由剑桥大学计算机系Moore教授的流量分类实验室提供的10个网络流量分类数据集组成,是目前网络流量分类最为权威的测试数据集[12]。我们从Moore_set中选取了Moore_set1来进行网络流量分类实验,该数据集中的样本是从真实的TCP双向流中提取的,每条记录包含248项流特征属性,并在每条记录的最后标注了该样本流量类型,分为12种不同应用类型。Moore_set1中样本信息统计情况如表3所列。
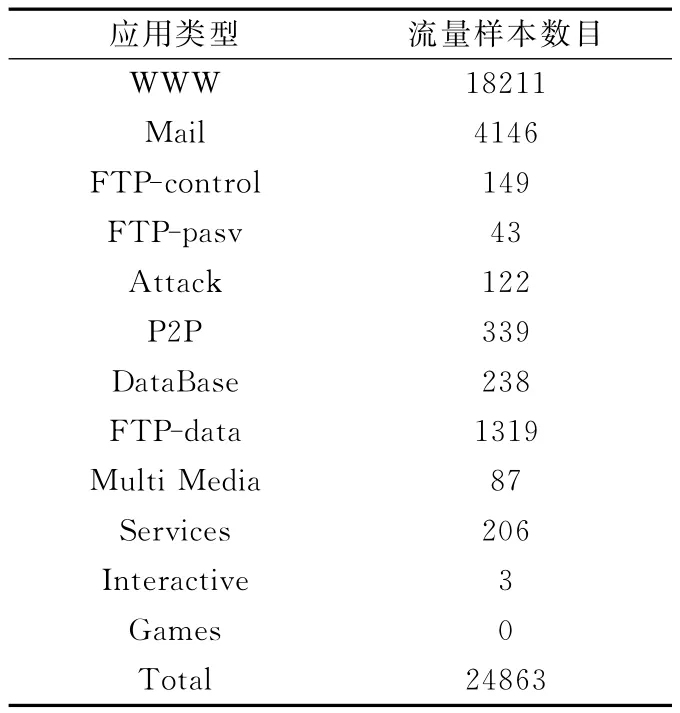
表3 Moore_set1样本信息统计
由于Interactive项样本数量过少,不具有代表性,因此将该类型样本删除掉,Games项在Moore_set1中样本数量为0,也将其去除,保留其余10项应用,共24860条流量样本,作为实验测试数据集Test_set。
2.2 网络流量分类时间性能的比较
并行SVM网络流量分类方法和传统的单机SVM方法的性能比较要从时间和精度两方面进行评估。首先进行时间性能的比较实验,将Test_set采用按类别比例随机抽样的方式,抽取一部分样本数据组成训练数据集进行训练,通过改变训练数据集样本的数目,对单机SVM算法和并行SVM算法的训练时间进行比较,所得到的实验结果如图2所示。
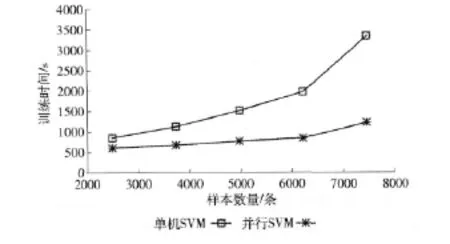
图2 单机SVM算法和并行SVM算法的训练时间
由图2可知,并行SVM算法训练时间远小于单机SVM算法,当训练样本数量较少时,单机SVM算法的时间消耗并不多,但随着样本数量增加,单机SVM算法的时间消耗显著地增加,与此同时并行SVM算法的时间消耗却增加不多,两者之间的时间消耗差距逐渐增大。这是因为当训练样本数量较少时,得到的支持向量数量较少,计算复杂度较低,所以单机SVM算法和并行SVM算法的时间消耗差距并不大;但是当训练样本数量变多时,得到的支持向量数量也增加,计算复杂度大幅度提高,此时单机SVM算法由于计算性能所限,导致时间消耗显著地增加,而并行SVM算法由多个节点并行处理计算任务,时间消耗增加就不多。
为了更精确地衡量并行SVM算法在时间性能上的提升,使用加速比r,即单机SVM算法运行时间 (TSingleSVM)与并行SVM算法运行时间 (TParallelSVM)的比值,来比较并行SVM算法相对单机SVM算法的时间效率

加速比曲线如图3所示。
由图3可知,随着样本数量的增加,加速比逐渐增大,这表明并行SVM算法相对单机SVM算法的时间消耗比例逐渐变小,在时间性能上的优势越明显。因此,并行SVM网络流量分类方法适合处理大规模网络流量样本,可以有效地加快训练速度,在较短的时间内对网络流量进行分类。
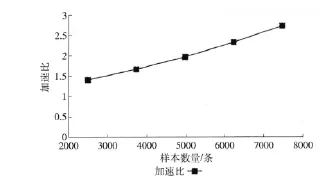
图3 加速比曲线
2.3 网络流量分类精度的比较
接着对单机SVM算法和并行SVM算法进行分类精度上的评估,为此要用合适的分类精度评价指标来衡量网络流量分类的效果,一次网络流量分类能产生4种不同结果,如表4所列。
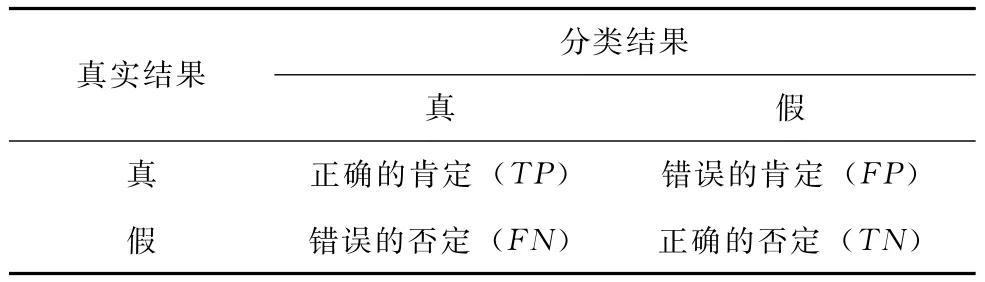
表4 网络流量分类结果类型
基于表4所列的网络流量分类结果类型,本文所使用的分类精度评价指标如下:
(1)准确率P:正确肯定流数量占正确肯定和错误肯定流数量总和比例。即正确分类该类成员占分类为该类的全部成员的比例

(2)召回率R:正确肯定流数量占正确肯定和错误否定流数量总和比例。即正确分类的该类成员占真正属于该类的全部成员的比例

(3)F-Measure:在某些情况下,准确率和召回率是矛盾的,所以需要根据二者的情况给出一个综合评价指标,即F-Measure。这里采用F1-Measure
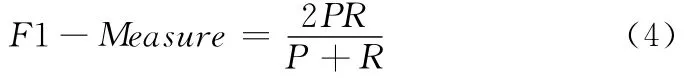
将实验测试数据集Test_set按类别比例随机抽样并分为三等份,选择其中1/3作为训练数据集,其余作为测试数据集。首先使用训练数据集分别采用单机SVM算法和并行SVM算法进行训练得到分类模型,再用该分类模型对测试数据集进行网络流量分类,得到单机SVM算法和并行SVM算法在每种应用类型中的准确率和召回率对比分别如图4和图5所示。
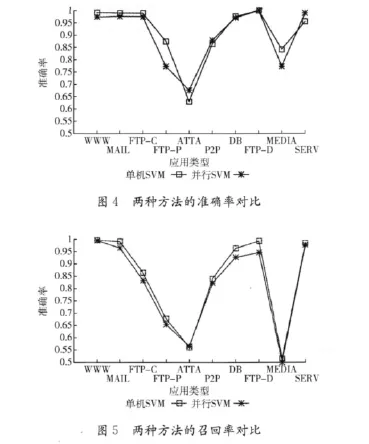
通过准确率和召回率这两种分类精度评价指标的对比可以看出,有的应用类型单机SVM分类算法精度高,有的应用类型并行SVM分类算法精度高,在大部分情况下二者的分类精度都是接近的。
对分类精度结果进行统计和总结,并用F1-Measure进行综合评价,两种网络流量分类方法整体上的分类精度结果如表5所列。从整体上看,并行SVM算法在分类精度上略低于单机SVM算法,但并无明显降低。
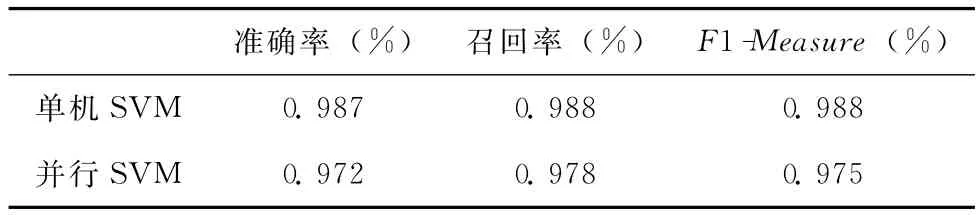
表5 两种网络流量分类方法的分类精度
以上实验从时间性能和分类精度两方面比较了单机SVM算法和并行SVM算法,由实验结果可知,并行SVM网络流量分类方法有效地减少了训练时间,提高了网络流量分类速度,适合处理大规模网络流量样本,虽然在分类精度上略低于单机SVM方法,但是仍然保持了较高的分类精度。
3 结束语
本文提出基于SVM的并行网络流量分类模型,并通过云计算平台Hadoop验证了其进行网络流量分类的性能,在保证了较高分类精度的前提下,有效地提高了SVM算法的训练速度,能应用于大规模网络流量分类。云计算的一个显著优点就是支持异构的计算环境,能在大量具有不同处理能力普通计算机上实现高性能计算,然而当前云计算平台Hadoop在负载调度上仅实现了先进先出和公平调度两种算法,不能很好地满足异构云环境下负载均衡的要求。因此,未来我们将设计一个基于异构云环境的负载调度算法,优化云计算平台处理网络流量分类的性能。
[1]Este A,Gringoli f,Salgarelli L.Support vector machines for TCP traffic classification [J].Computer Networks,2009,53(14):2476-2490.
[2]LIU Qiong,LIU Zhen,HUANG Min.Study on internet traffic classification using machine learning [J].Computer Science,2010,37 (12):35-40 (in Chinese).[刘琼,刘珍,黄敏.基于机器学习的IP流量分类研究 [J].计算机科学,2010,37(12):35-40.]
[3]Kim H,Claffy K,Fomenkov M,et al.Internet traffic classification demystified:Myths,caveats,and the best practices[C]//ACM CoNEXT Conference.Madrid:ACM,2008:1-12.
[4]Yuan R,Li Z,Guan X,et al.An SVM-based machine learning method for accurate internet traffic classification [J].Information Systems Frontiers,2008,10(2):149-156.
[5]XU Peng,LIU Qiong,LIN Sen.Internet traffic classification using support vector machine [J].Journal of Computer Research and Development,2009,46 (3):407-414 (in Chinese).[徐鹏,刘琼,林森.基于支持向量机的Internet流量分类研究 [J].计算机研究与发展,2009,46 (3):407-414.]
[6]PENG Bo.Comparison research on the algorithms of network traffic classification [J].Computer & Digital Engineering,2012,40 (5):12-14 (in Chinese). [彭勃.网络流量分类算法比较研究 [J].计算机数字与工程,2012,40 (5):12-14.]
[7]XU Mengjin,ZHANG Bofeng.Classification of internet traffic based on machine learning [J].Journal of Computer Applications,2010,30 (1):80-82 (in Chinese).[许孟晋,张博锋.基于机器学习的Internet流量分类 [J].计算机应用,2010,30 (1):80-82.]
[8]NING Jing,MING Yang,SHAO Yin,et al.An efficient SVM-based method for multi-class network traffic classification[C]//Performance Computing and Communications Conference,IEEE 30th International.Chengdu:IEEE,2011:1-8.
[9]XIANG Li,FENG Qi,DAN Xu,et al.An internet traffic classification method based on semi-supervised support vector machine[C]//IEEE International Conference on Communications.Kyoto:IEEE,2011:1-5.
[10]QIU Jing,XIA Jingbo,BAI Jun.Network traffic classification using SVM decision tree [J].Electronics Optics & Control,2012,19 (6):13-16 (in Chinese). [邱婧,夏靖波,柏骏.基于SVM决策树的网络流量分类 [J].电光与控制,2012,19 (6):13-16.]
[11]WANG Tao,CHENG Lianglun.Large-scale network traffic classification with fast support vector machine method [J].Application Research of Computers,2012,29 (6):2301-2305(in Chinese).[王涛,程良伦.基于快速SVM的大规模网络流量分类方法 [J].计算机应用研究,2012,29(6):2301-2305.]
[12]Moore A W,Zuev D.Internet traffic classification using Bayesian analysis techniques[C]//Proc of ACM International Conference on Measurement and Modeling of Computer Systems.Banff:ACM,2005:50-60.
