基于字体的中文信息隐藏算法
2013-09-10孙新梅黄刘生
孙新梅,孟 朋,黄刘生,3
(1.淮北职业技术学院 机电工程系,安徽 淮北235000;2.中国科学技术大学 计算机科学与技术学院国家高性能计算中心,安徽 合肥230026;3.中国科学技术大学 苏州研究院,江苏 苏州215123)
0 引 言
目前以文本为载体的信息隐藏大体可以分为三类:基于排版,基于语法和基于语义。而基于排版的信息隐藏算法不抗重写攻击,如果隐藏文本被重新排版或重写一遍,那么隐藏信息也随之消失;基于语法的信息隐藏算法通过模仿自然语言的语法结构,生成类似自然语言的文本,在生成文本的过程中隐藏进秘密信息。这类算法主要有基于Markov链的隐藏方法[1],基于句子模板的隐藏方法[2]和基于文章样式的隐藏方法[3]等。这类算法虽然可以抵抗重写攻击,但是算法生成的文本没有完整的意义,并且可以通过统计分析等方法对载体文本实现自动化的检测[4-6]。基于语义的信息隐藏算法通过对载体文本的部分单词进行同义词替换[7-8]、部分或全部句子进行同义转换等方式,虽然目标是尽量保持载体文本语义不变,但实现起来非常困难;所以有必要进一步设计新的信息隐藏算法,以增强信息安全性。本文以经常被混用的繁体字、简化字为例,设计了一种新的中文信息隐藏算法,并研究了算法的嵌入率以及安全性等问题。这种算法主要具有以下优点:一是嵌入方式多样,可以根据需要选择不同的嵌入方式;二是这种算法保证了载体文本的语义完全不变,实现起来简单;三是这种算法对电子文本,打印文本,手写文本等全部适用。
1 背景介绍
汉字的历史悠久,在汉字的演进过程中很多时期同一汉字存在着两种或两种以上的书写形式。就今天来说,日常使用的文字约1/3存在两种或两种以上的书写形式[9]。1964年国务院公布的 《简化字总表》,共包含2236个简化字,是大陆通行的简化字,这2236个简化字有至少两种书写形式:简化字和繁体字。由于特殊的历史和政治原因,当前简化字主要在大陆地区使用,而繁体字主要在台港澳以及海外继续使用。近年来,随着两岸交流的密切展开以及两岸文字统一的需要,大陆民众对繁体字产生了很大的热情,而在台湾等地区学习和使用简化字的人数也不断增多,因此繁体字和简化字混用的显现普遍存在并且有增多趋势。根据 “中国语言文字使用情况调查”的结果,截至上世纪末,有3.84%的人是繁体字和简化字并用[10]。图1显示大陆地区平时使用简化字和繁体字的比例。从网上也可以看到,大量的网页是繁简并用,特别像网络论坛、网上聊天室等对文字格式没有严格要求的网站。
在海外华人地区,繁简混用现象则更加普遍。例如针对新加坡餐馆菜单统计,繁简混用现象约占所有中文菜单的17%[11],如图2所示。
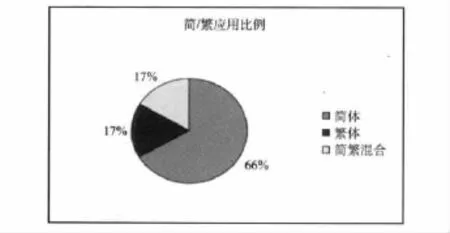
图2 新加坡菜单繁体字和简体字使用比例[11]
随着不同地区的华人交流日益频繁以及互联网的广泛使用,繁简混用的现象很难在短时间内消除,甚至有日益增多的趋势。随着汉字编码方式以及输入方式的进步,采用一种输入法输入简化字和繁体字几乎同样简单,同时输入以及显示简化字和繁体字已经没有任何困难,这为繁体字和简化字的混用提供了便利的条件。这种不规范的繁简混用现象很有可能被用来进行信息以藏。
2 算法描述
我们的目标是对一篇载体文本 (只含简化字或繁体字的普通文本,本文中提到的载体文本假设只含简化字),通过将部分简化字替换为繁体字来实现信息隐藏。
首先构造一个替换字典SD,SD包含经常混用的简化字和繁体字。即SD是一个二元组的集合,每个二元组包括一个经常混用的简化字和其对应的繁体字。
2.1 简单替换的嵌入算法 (SSE)
将待隐藏信息转化为 “0”和 “1”的比特序列,假设规定简化字代表 “0”,繁体字代表 “1”,SSE方式执行过程描述如下:
隐藏过程:对载体文本中每个SD中的文字,根据当前需要隐藏的信息进行替换。如果需要嵌入 “0”,则保持简化字不变;如果需要嵌入 “1”,那么将简化字替换为相应的繁体字;不在SD中的文字保持不变。进行替换后的文本就是一篇含有隐藏信息的载密文本。
提取过程:从载密文本中依次读取文字,如果文字为SD中的简化字则提取 “0”,为SD中的繁体字则提取 “1”,不在SD中的字直接读取下一个字。
例如对字符串 “GB2312码是中华人民共和国国家汉字信息交换用编码”进行信息隐藏,假设需要隐藏的秘密信息为 “01010110”,那么采用简单替换方式隐藏后的载密文本为:“GB2312码是中華人民共和国國家汉字信息交換用編码”。
这种嵌入方式的好处是嵌入率比较高,弊端是嵌入简单,比较容易辨认。例如相邻的 “国國”一个简化字,一个繁体字,生活中很难发生这种情况,因此这种嵌入方式安全性较低。
2.2 高效替换的嵌入算法 (ESE)
对进行保密通信的双方来说,字符串 “GB2312码是中华人民共和国国家汉字信息交换用编码”,可以认为其代表字符串本身表达的信息,也可以认为其代表 “26”(因为其总共含有26个字符),当然也可以认为其代表其它的数字或者符号。只要发送方和接收方采用相同的解释方式,就可以通过对载体文本进行 “解释”达到传递秘密信息的目的。
将一篇载体文本完全不做修改,而只靠 “解释”来实现秘密通信,在通信量很小的情况下,完全可以实现。假设要进行最大通信量为20比特的秘密通信,最简单的解释方式可以用220个不同的载体文本,其中每个载体文本代表一种信息,那么就可以实现对载体文本完全不用修改来传递秘密信息。但是当通信量大的时候,很难只用 “解释”的办法来实现信息隐藏。
下面提出一种折中的方法,首先将待隐藏的信息分解为固定长度的信息段,然后对每个信息段采用 “解释”的办法进行隐藏,以实现在修改尽量少的文本的前提下嵌入秘密信息。
假设待隐藏的信息正好可以分解为n个长为L的分组,“解释”隐藏的方法如下:将隐藏信息的每个分组转化为一个十进制数Di(0<i<n+1),对载体文本从开始位置进行搜索,每经过Di个SD中的简化字,将第Di+1个简化字替换为繁体字。
隐藏算法和还原算法的描述如下所示 (算法假设载体文本足够长,可以容纳秘密信息),图3和图4分别是隐藏算法和还原算法的流程图。
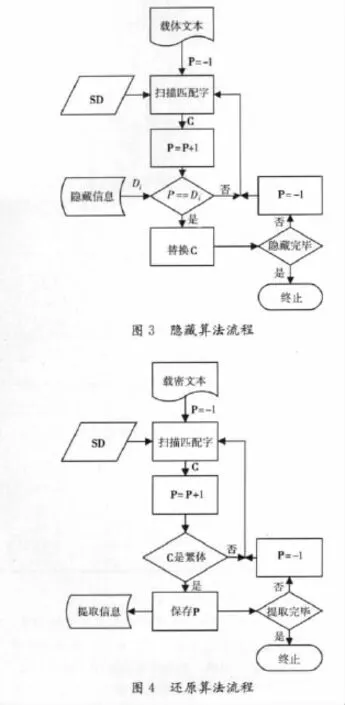
隐藏算法描述:
步骤1 从载体文本开始位置搜索,置P等于-1。
步骤2 从载体文本当前位置开始,找到下一个SD中的字C,并置P等于P+1。
步骤3 如果P等于当前待隐藏的信息Di(0<i<n+1)。那么将C替换为繁体字,否则转步骤2。
步骤4 如果信息隐藏完毕,则算法终止,否则P=-1,转步骤2。
还原算法描述:
步骤1 从载体文本开始位置搜索,置P等于-1。
步骤2 从载体文本当前位置开始,找到下一个SD中的字C,并置P等于P+1。
步骤3 如果C是繁体字,那么将P保存为提取信息,否则转步骤2。
步骤4 如果提取完毕,则算法终止,否则P=-1,转步骤2。
高效替换算法的最大优点就是每替换一个字符,可以隐藏L比特的信息,而且L可以根据需要灵活选择,L越大,载体文本被替换的文字越稀少,载密文本的隐蔽性也越强;L越小,嵌入率越高。
2.3 基于模板的嵌入算法 (TBE)
在SSE算法中,每个字符嵌入一个比特信息,而在ESE算法中,一个字符嵌入多个比特信息。在TBE算法中,我们使用多个字符来嵌入多个比特信息。
首先,假设将载体文本中出现在SD中的字符按顺序分组,每组N个字符。从N个字符中任取m个,则共有种选取方式,每种选取方式可以看成一种模板,如果将这些模板编码,则每个模板对应一种隐藏信息。每N个字符通过替换其中m个至少可以嵌入比特信息,这种嵌入方式记做TBE(N,m)。
例如TBE(5,2)的一种编码方式见表1。
3 嵌入率和安全性分析
3.1 嵌入率分析
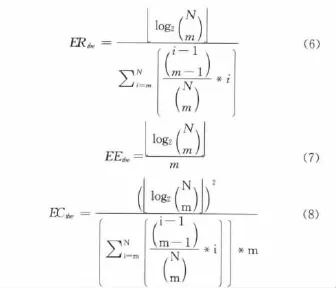
假设一篇载体文本共含有A个SD中的字符,嵌入S比特信息后,修改了其中C个字符,定义嵌入率 (ER),嵌入效率 (EE)如下

表1 基于模板的嵌入方式编码

假设嵌入比特串 “0”和 “1”均匀分布,则SSE的嵌入率为1,平均嵌入效率为2;假设ESE嵌入信息分段长度为L,则其嵌入率为嵌入效率为L。当L大于1时,ESE的嵌入效率高于SSE,但其嵌入率远远低于SSE,并且随L增大嵌入率以指数方式下降。
一个好的嵌入方式,应该既有比较高的嵌入率,又有比较高的嵌入效率,因此给出嵌入能力 (EC)的定义如下

一般来说,希望在嵌入率一定的条件下,有比较高的嵌入效率,或者嵌入效率一定的条件下,有比较高的嵌入率。因此,使用EC可以较好的描述算法的嵌入能力。
下面来分析3种算法的嵌入能力 (EC)。
SSE算法的嵌入率为1,和平均嵌入效率为2,因此

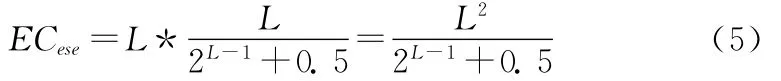
假设TBE算法的模板长度为N,从中选取m个字符进行替换嵌入信息,因为每个模板最后的 “0”比特无需嵌入,则
ESE和TBE的嵌入率、嵌入效率和嵌入能力见表2和表3。

表2 ESE的嵌入率,嵌入效率和嵌入能力数据
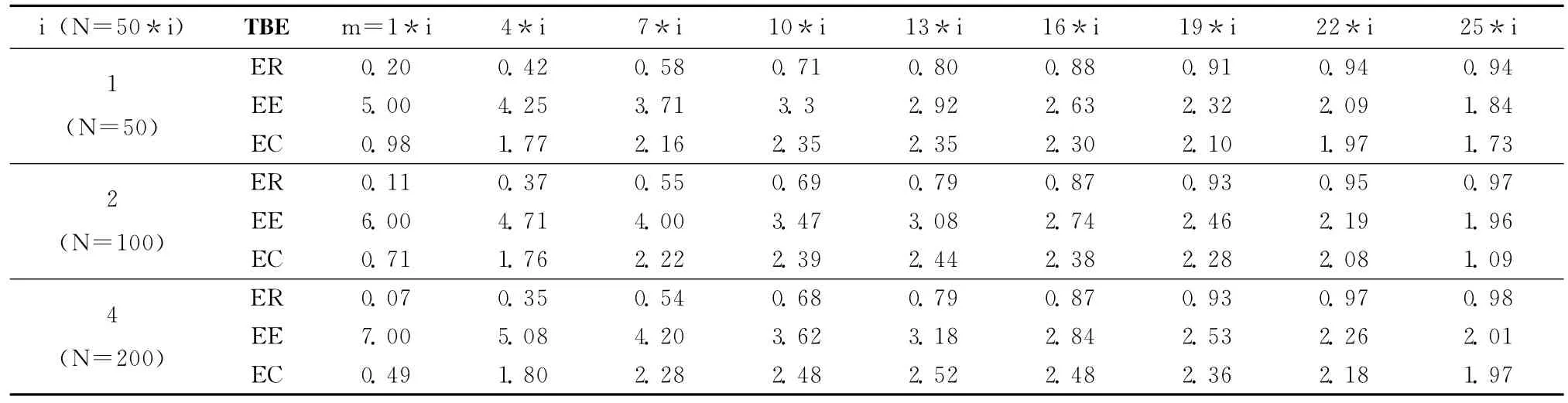
表3 TBE的嵌入率,嵌入效率和嵌入能力数据
对比表2和表3,可以看出,适当的选取N和m,TBE会比ESE有更高的嵌入能力,例如当ESE的嵌入效率为3时,其嵌入率为0.67;而当N等于100,m等于26时,TBE的嵌入效率为3.08,嵌入率为0.79,嵌入效果明显好于ESE。
3.2 安全性分析
本文所设计算法优点是保证载体文本语义完全不变,嵌入率可灵活调整,抗重写攻击,因此传统的攻击方法对本算法是完全无效的。当然,本文的算法使用了两种字体,在对文本字体要求严格的环境,本文的算法并不适用。另外,对本文算法检测的唯一依据是文本是否同时使用了简化字和繁体字,但是由于相当一部分人同时使用两种字体,因此仅根据使用两种字体检测会导致大量正常文本被误判为载密文本,仍然无法准确区分正常文本和载密文本。
为了增加算法安全性,替换辞典 (SD)可以仅选择经常混用的繁体字和简化字,这样载密文本传输过程中如果被修改了部分字符,如果这部分字符并不在SD之中,并不会影响秘密信息的安全。另外采用基于模板的嵌入方式,可以仅对部分模板进行编码,这样仅有部分模板是有效模板,如果载密文本被攻击并修改,这样可能会导致提取过程出现无效模板,从而可以判断载密文本被攻击,并且能判断攻击的位置。
由于文本的冗余空间少,嵌入率低,当前基于文本的隐藏算法很少,文本信息隐藏很少引起大家注意,因此基于文本的信息隐藏成功率也较高。
4 结束语
相对加密技术来说,信息隐藏是一个比较新的研究领域。本文分析了目前文本信息隐藏的研究现状和存在的不足,设计了一种基于中文字体的信息隐藏算法。算法保证了载体文本的语义完全不变,具有实现起来简单、信息传输存储安全、嵌入率高的特点。根据不同的应用需求,作者给出了3种隐秘信息的嵌入算法,并且通过数学计算,对每一种嵌入算法的嵌入率和嵌入效率等进行了分析比较。最后对算法的安全性进行了分析,并给出了增强安全性的手段。
[1]Meng Peng,Huang Liusheng,Chen Zhili.STBS:A statistical algorithm for steganalysis of translation-based steganography [C ]//Proceedings of the Information Hiding Conference,2010.
[2]MaherK. TEXTO. URL: ftp://ftp.funet.fi/pub/crypt/steganography/texto.tar.gz [S].2012-06-05.
[3]Liu T Y,Tsai W H.A new steganographic method for data hiding in microsoft word documents by a change tracking technique [J].IEEE Transactions on Information Forensics and Security,2007,2 (1):24-30.
[4]Chen Zhili,Huang Liusheng,Yu Zhenshan,et al.Linguistic steganography detection using statistical characteristics of correlations between words [G].LNCS 5284:USA:Information Hiding,2008:224-235.
[5]Chen Zhili,Huang Liusheng,Yu Zhenshan,et al.A statistical algorithm for linguistic steganography detection based on distribution of words [C]//Spain, Mar: ARES,2008:558-563.
[6]Chen Zhili,Huang Liusheng,Yu Zhenshan,et al.Effective linguistic steganography detection [C]//Australia:CIT Workshops,2008:224-229.
[7]Ryan Stutsman,Mikhail Atallah,Christian Grothoff,et al.Lost in just the translation [C]//Proceedings of the ACM Symposium on Applied Computing.New York:ACM,2006:338-345.
[8]Meng Peng,Shi Yunqing,Huang Liusheng.LinL:Lost in n-best list [C]//Proceedings of the Information Hiding Conference,2011.
[9]GUO Shulun.Dynamic analysis and comparison of stroke number of simplified Chinese characters and traditional Chinese characters [J].Journal of Beihua University,2009,10 (2):50-56 (in Chinese).[郭曙纶.简化字与繁体字笔画数的动态统计与比较 [J].北华大学学报,2009,10 (2):50-56.]
[10]Chinese Languages Investigation Leading Group Office.The survey data of chinese press about chinese language [M].Beijing:The Chinese Press,2006 (in Chinese).[中国语言文字使用情况调查领导小组办公室.中国语言文字使用情况调查资料 [M].北京:语文出版社,2006]
[11]WANG Hui.The simplified and traditional Chinese characters coexist,use simplified character and know traditional character [D].National University of Singapore,2008 (in Chinese). [王惠.繁简共存,用简识繁 [D].新加坡国立大学,2008.]
