基于MM-算法的局部常数核加权分位数回归估计及应用
2013-08-16姜云卢袁晶晶
姜云卢,袁晶晶
(1.中山大学数学与计算科学学院,广东广州510275;2.暨南大学经济学院,广东广州510632)
对于线性回归模型,最小二乘方法是估计回归系数的一种最常见的方法,描述了自变量对于因变量的均值影响.如果线性回归模型中的随机误差项服从均值为零且同方差的正态分布,则回归系数的最小二乘估计为极大似然估计.然而,在实际应用中,上述的正态假设经常不能被满足,例如数据经常出现尖峰或重尾的分布,或存在显著的异方差等情形.而且,最小二乘估计对离群点特别敏感,一个“坏”的数据点就可能破坏整个回归线的估计.
1978 年,KOENKER 和 BASSETT[1]首次提出了分位数回归(Quantile Regression)的思想.假设随机变量Y具有分布函数为F(y)=P(Y≤y),则Y的τ(0≤τ≤1)分位数定义为:Q(τ)=inf{y:F(y)≥τ};特别地,Q(0.5)就是中位数.指出了随机变量Y的τ分位数可定义为
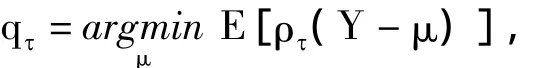
其中 ρτ(r)=τr-rΙ(r<0)称为检验函数(check function).进一步,他们将检验函数推广到分位数回归的情形.分位数回归的假设与均值回归不同,对误差项方差齐性与正态性没有要求,同时善于捕捉分布的尾部特征.注意到把检验函数替换成ρτ(r)=r2即得到传统的均值回归估计,对于异常值其二次增长明显比一次增长受影响更大,所以在稳健性方面分位数回归优于均值回归.另外,分位数回归能给出响应变量Y更为全面的描述,τ取不同的值可以反映解释变量X对不同水平的Y的影响.还讨论了分位数回归估计的一致性与渐进正态性.
有关分位数回归估计的计算,1993年,KOENKER和OREY[2]把线性规划中常用的单纯形法扩展到分位数回归中,该算法所得到的估计虽然具有很好的稳定性,但是,在处理大型数据时效率低下.1996年,KOENKER和PARK[3]用线性规划的内点算法得到了非线性分位数回归的估计.虽然在大型数据下比单纯形算法效率要高,但是,当自变量比较多时效率仍然很低.2000年,HUNTER 和 LANGE[4]首次提出MM(Majorization-Minimization)算法,它概念简单,数值稳定,且易于执行,并将其用于非线性分位数回归中.他们的数值结果表明,在许多非线性分位数回归问题中,MM-算法优于内点方法.
分位数回归的理论研究和实际应用发展迅速,其中理论已经拓展到二元响应模型、非参数模型、时间序列、极值理论、面板数据、久期模型、非线性模型和多元分析等诸多方面[5].在其他学科领域包括环境科学[6]、生态学[7]、生存分析[5]、医学[8]、经济学[9]、金融学[10]等已得到广泛应用.
本文主要考虑非参数分位数回归模型Y=mτ(X)+ ετ,其中 ετ是随机误差,其分布满足 τ分位数为0.此模型关注于在给定X=x条件下,Y的条件 τ分位数函数 mτ(x)=argmin E{ρτ(Y-mτ(X))|X=x}(0≤τ≤1).在非参数分位数回归模型下,常用的回归估计方法包括局部常数核估计和局部线性核估计.YU和JONES[11]比较了这2种估计的内部点渐进均方误(MSE)和边界点渐进均方误(MSE),指出在内点情形下,两者的实际差距并不显著.然而,对于非参数分位数回归,检验函数并不光滑,使得非参数分位数回归的计算成为一个重要的挑战.使用局部线性的方法,YU 和 JONES[12]利用 MM-算法对分位数回归逐点进行估计.但是,这种方法有2个缺点:(1)计算量繁重;(2)即使分位数回归函数是光滑的,基于局部线性方法的估计仍可能不光滑甚至不连续.
本文利用MM-算法对局部常数分位数回归进行估计,所得到的目标函数具有MM-算法的下降性质,保证了所得估计的数值稳定性.同时,所提出的算法不仅成功地减轻了计算负担,而且,在适当的条件下,得到的估计保持了回归函数连续光滑的性质.
1 局部常数核加权分位数回归
1.1 局部常数估计
假设一组随机样本{(Xi,Yi)(i=1,2,…,n)}来自如下的非参数分位数回归模型
Y=mτ(X)+ ετ(0≤τ≤1),
其中ετ是随机误差项,满足第 τ分位数为0,协变量X和ετ是独立的.在分位数回归中,我们的任务是在给定X=x的条件下,估计响应变量Y的τ条件分位数函数 mτ(x).
在Y的τ分位数处取得最小值.类似地,在非参数分位数回归中,通过最小化目标函数

来估计mτ(x).为了使估计具有光滑性,我们采用格点x附近的局部常数估计来近似条件分位数函数,即mτ(X)≈β0,然后最小化核加权的目标函数
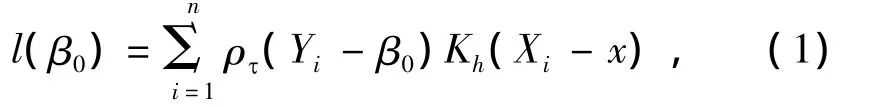
此处Kh(Xi-x)=h-1K((Xi-x)/h)是一个核函数.
对一个给定的格点x,式(1)是非光滑的,其最小优化可通过一个MM迭代算法实现,即构造凸函数包,将不光滑函数的优化问题转化为光滑凸函数的优化.现给定β(l),并定义ri(β)=Yi-β,这些函数有以下几个性质.
性质1 局部加权的二次函数
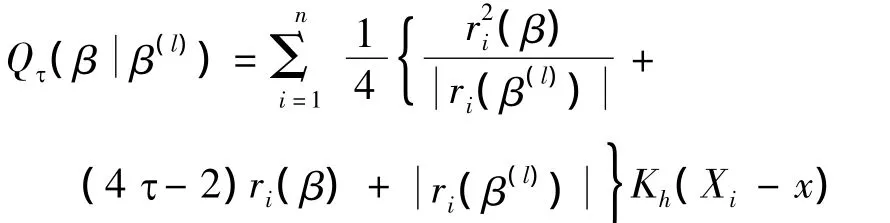
在β(l)处是l(β)=Σni=1ρτ(Yi- β)Kh(Xi-x)的一个优超函数.即在给定 β(l)下,对所有的 β,有 Qτ,并且 Q
证明 令

因为
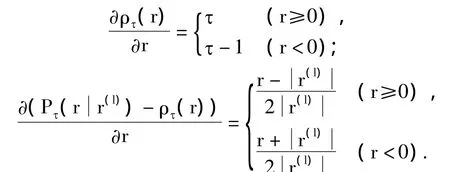
MM-算法的第l+1次迭代值β(l+1)是二次函数的最小值点,通过微分,得到
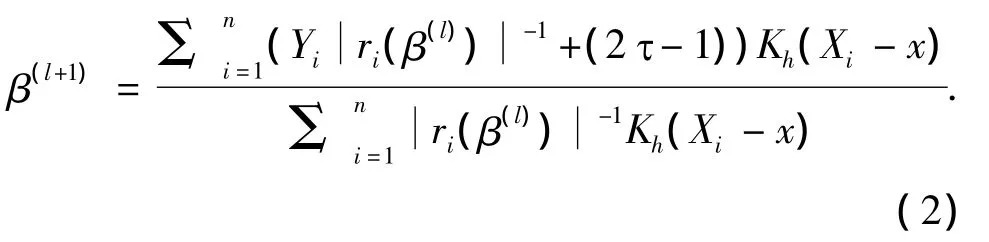
性质2 由式(2)定义的序列{β(l)}满足l(β(l+1))≤l(β(l)),等式成立当且仅当
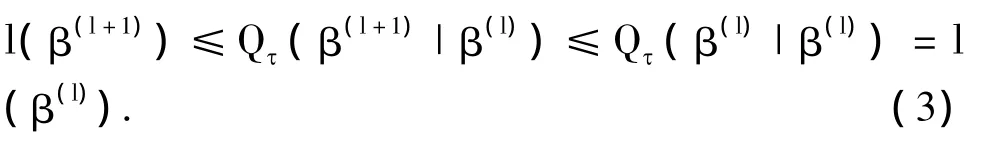
证明 事实上,由性质1可知若 Qτ(),即此时二次函数))在β(l+1)和β(l)处均取得最小值,也就是说 β(l+1)=β(l),于是
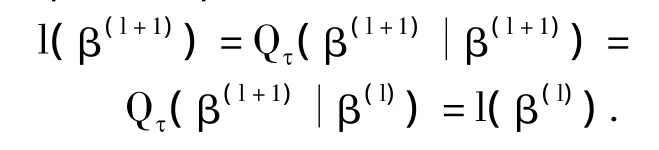
反过来,由式(3),结论显然成立.
性质3 假设MM-算法在有限次迭代后收敛,并且在每次迭代中,对所有i{1,2,...,n}都有ri(β(l))≠0,则得到函数mτ(x)的估计连续且光滑.
由于ri(β(l))≠0,Kh(Xi-x)=h-1K((Xi-x)/h)是x的连续且光滑函数,所以对任一次迭代β(l+1)(x)也是x的连续且光滑函数.
1.2 具有扰动的局部常数估计
在性质3中,需要在每次迭代中都有ri(β(l))≠0的条件,才能保证回归估计连续且光滑.然而,这个条件在实际数据处理时很难保证.
受 HUNTER 和 LANGE[4]的启发,在优超函数)的二次项系数的分母中增加一个很小的扰动项ε.于是,定义改进的分位数目标函数为
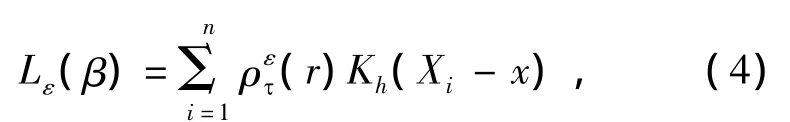
现在,构造Lε(β)在 β(l)处的优超函数

性质4 β(0)是R R上任意一点,定义紧集
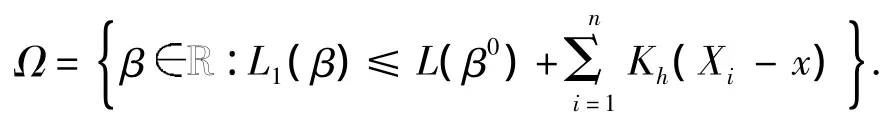
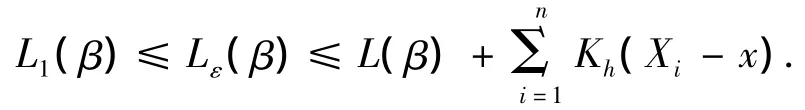
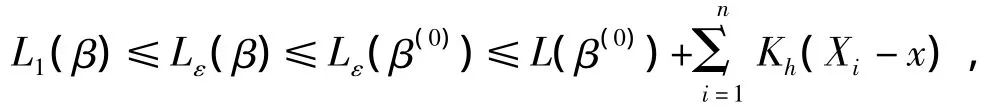
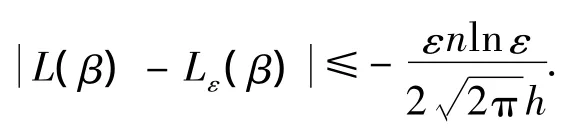
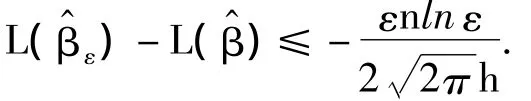
证明 由ri(β)=Yi-β的连续性和Ω集合的紧致性可知,其上界d是有限的.如果ε+|r|≤1,则有.如果 ε+>1,由于 ε<d-1,那么由d的定义可得 ln(ε+<ln d<-lnε.因此,

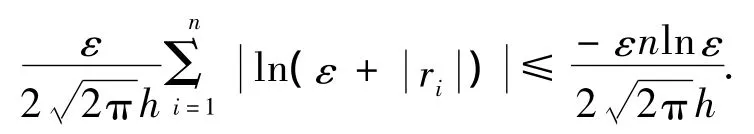

2 窗宽的选取和数值模拟
2.1 窗宽选取
对于非参数核光滑方法来说,窗宽h的选取至关重要.交叉验证(Cross-Validation)是选择光滑参数最流行的一种方法,它将整个数据集做多次划分,每次划分将数据分为2个部分:训练集与检验集,训练集数据用来做估计,检验集数据用来做验证.本节的数据模拟采用缺一交叉验证(Leave-One-Out Cross-Validation)的方法来选择窗宽,也就是每次验证时检验数据集中只有一个样本点,并且把所有样本点都充当一次检验数据.缺一交叉验证标准为

2.2 数值模拟
模拟的数据来自模型:Y=sin(2πX)+ε,其中X~U[0,1],误差项 ε 与 X 独立.误差项 ε 的分布取标准正态 N(0,1)和 t1分布.对 τ=0.25、τ=0.5、τ=0.75这3种不同的分位数水平,基于我们提出的MM迭代算法,计算了局部常数估计、最小二乘局部常数估计,并且基于估计积分平方误差(ISE)的中位数进行了比较.在样本数n=100、n=200、n=500的情形下分别模拟100次,每次采用交叉验证法选出最优窗宽.所得到的结果见表1,其中LS、QR0.5、QR0.25、QR0.75分别表示最小二乘核估计、MM-算法下的中位数、1/4、3/4分位数局部常数估计.误差项ε在标准正态N(0,1)和t1分布下的均值、中位数均为0,这2种模型下LS和QR0.5均为真实模型的估计,而 QR0.25和 QR0.75是真实模型的一个平移估计,预计 QR0.25和 QR0.75的 ISE 要高于 QR0.5.

表1 各估计积分平方误差的中位数Table 1 Median ISE of these estimators
结果显示,在正态误差情形下,QR0.5的ISE略高于LS的ISE,两者差别不大.但是,在重尾的t1误差分布下,前者的ISE远低于后者,这说明我们提出的方法得到的估计在重尾分布的误差下是稳健的.另外,在t1误差分布下,n=500时,我们画出了中位数局部常数分位数回归(MLCQR)的估计拟合曲线、最小二乘局部常数(LSLC)的估计曲线以及真实模型(RM).从图1看到在重尾误差的情况下,提出的方法能刻画真实模型.

图1 n=500时中位数回归估计曲线及LS估计曲线Figure 1 Median regression estimated curve and LS estimated curve when n=500
2.3 实证研究
应用所提的方法去分析一份青少年骨密度的数据.该数据最早出现于文献[13].随后,在文献[14]中也被作为一个范例进行分析.数据下载网址为:http://www-stat.stanford.edu/~ tibs/ElemStatLearn/,包含了4个变量:idnum、age(测量时孩子的平均年龄)、gender(男或女)和spnbmd(相对的脊椎骨密度测量值),共有458个观测值.本文所关注的是相对的脊椎骨密度测量值随年龄的变化情况.
由于事先并不知道相对的脊椎骨密度测量值随年龄的变化情况,所以采用非参数回归模型去拟合其变化情况.运用本文所提出的基于MM算法的局部常数核加权分位数回归去估计非参数回归函数.这里年龄为自变量X,相对的脊椎骨密度测量值为因变量Y.
在MM-算法中,首先采用核回归获得均值函数的估计,即

在常数方差的假设下,进一步计算方差的估计:

由正态近似,取MM算法中的迭代初始值为
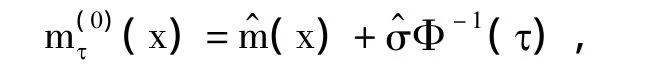
其中Φ-1(τ)是标准正态经验分布函数的反函数.MM算法中的迭代终止条件是前后2次迭代估计之差小于10-6.在 τ=0.1、τ=0.25、τ=0.5、τ=0.75 和 τ=0.9的分位数水平下,通过缺一交叉验证法则选出的最优窗宽分别是 h0.1=0.59、h0.25=0.59、h0.5=0.60、h0.75=0.52 和 h0.9=0.55.其估计的结果见图 2.
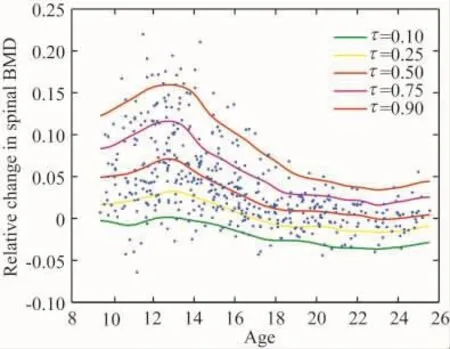
图2 局部常数核加权分位数回归的估计曲线Figure 2 Local constant kernel-weighted quantile vegression estimated curves
图2表明,所提出的方法得到了光滑的回归曲线.在12~13岁之间相对的脊椎骨密度达到最大.在此之前,相对的脊椎骨密度随着年龄的增大而增加;在此之后,随着年龄的增加反而降低.同时,随着分位点τ的增加,相对应的回归曲线起伏越大.这说明,对不同水平的相对的脊椎骨密度,所反映的趋势各不相同,也就是说,不同的相对的脊椎骨密度随年龄的变化不一样.特别地,相对的脊椎骨密度的分位数为10%左右的人群,其相对的脊椎骨密度随年龄的变化不大;而分位数为90%左右的人群,其相对的脊椎骨密度随年龄的变化幅度比较大.
3 总结
本文针对非参数分位数回归模型,提出了一种新的基于MM-算法的局部常数核加权计算法.在某些条件下,由此计算出的非参数估计是连续光滑的.同时,利用缺一交叉验证法则来选择协调参数.虽然本文只考虑了非参数回归模型,但是所提出的方法同样适用于半参数回归模型.
[1]KOENKER R,BASSETT G W.Regression quantiles[J].Econometrica,1987,46(1):33-50.
[2]KOENKER R,OREY D.Algorithm AS 229:Computing regression quantiles[J].Appl Stat,1987,36(3):383-393.
[3]KOENKER R,PARK B J.An interior point algorithm for nonlinear quantiles regression[J]. J Econometrics,1996,71(1):265-283.
[4]HUNTERD R,LANGEK.Quantile regression via an MM algorithm[J].JComput Graph Stat,2000,9(1):60-77.
[5]KOENKER R,HALLOCK K.Quantile regression:An introduction[J].JEcon Perspect,2001,15:143-156.
[6]CHOCK D P,WINKLER S L,CHEN C.A study of the association between daily mortality and ambient air pollutant concentrations in Pittsburgh,Pennsylvania[J].Journal of the Air& Waste Management Association,2000,50(8):1481-1500.
[7]KOENKER R,SCHORFHEIDE F.Quantile splinemodels for global temperature change[J].Climate Change,1994,28(4):395-404.
[8]COLE T J,GREEN P J.Smoothing reference centile curves:The LMSmethod and penalized likelihood[J].Stat Med,1992,11(10):1305-1319.
[9]GOSLING A,MACHIN S,MEGHIR C.What has happened to men's wages since the mid-1960s[J]Fiscal Studies,1994,15(4):63-87.
[10]BASSETT G,CHEN H.Quantile style:Return-based attribution using regression quantiles[J].Empir Econ,2001,26(1):7-40.
[11]YU K,JONESM C.A comparison of local constant and local linear regression quantile estimators[J].Comput Stat Data An,1997,25(2):159-166.
[12]YU K,JONESM C.Local linear quantile regression[J].JAmer Stat Assoc,1998,93(441):228-237.
[13]BACHRACH L K,HASTIE T,WANFM C.Bonemineral acquisition in healthy Asian,Hispanic,Black,and Caucasian youth:A longitudinal study[J].JClin Endocr Metab,84(12):4702-4712.
[14]HASTIE T,TIBSHIRANL R,FRIEDMAN J.The elements of statistical leavning[M].New York:Springer,2001.
