Web文本挖掘在智能分类中的应用
2013-08-16张黎黎
张黎黎
(长春工程学院,吉林 长春130012)
1 文本挖掘概述
文本挖掘,又称为“文本数据挖掘”或“文本知识发现”,是从文本数据中抽取隐含的、未知的、潜在且有用信息的过程。它是个分析文本数据、抽取文本信息,进而发现文本知识的过程。文本挖掘的出现为文本信息的整理、分析、挖掘提供了有效手段[1]。
文本挖掘的主要目标是获得文本的主要内容特征,如文本的主题、文本主题的类属、文本内容的浓缩等。文本挖掘主要有特征抽取、文本分类、聚类等技术。从提取特征值作为起始点,将自然语言文本自动分配给预定义的类别,利用文本特征向量对文本进行分类,再将一个数据对象的集合分组成为多个类或簇,从而产生类标记。
2 Web 文本挖掘
Web 文本挖掘是指使用中心词汇来表示文档的方法。利用给出求取中心文档和中心词汇的算法[2],对Web 上大量文档集合的内容进行总结、分类、聚类和关联分析,亦可利用Web 文档进行趋势预测。
Web 文本挖掘过程中[3],关注的是信息元素本身的内容与意义,是以文本、图片、音频、视频或者结构记录等信息内容为对象,从中挖掘知识内容和语义关联模式。
Web 文本挖掘是通过HTML 文档进行信息的采集,将分布在Web 服务器上的待挖掘文档集成在本地文本库中提取有用的Web 文本信息。然后,采用基于词典的逐字二分查找方法自动分词。采用向量空间模型和语义检索技术表示文本,采用评估函数X2统计法对文本的名称、类型、大小等特征进行提取。Web 文本挖掘流程如下图所示:
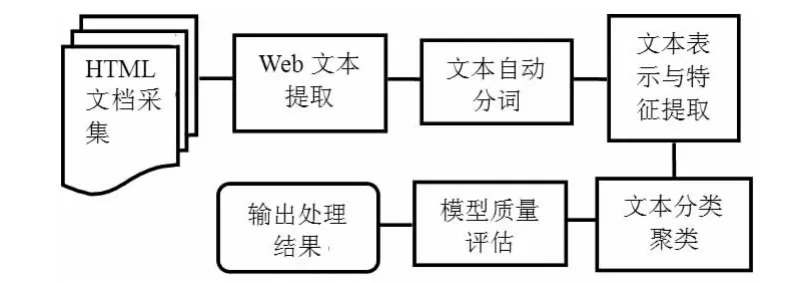
图Web 文本挖掘的基本流程
3 文本分类常用算法
文本分类的算法有很多种,其中最常用到的是TFIDF 方法和Naive Bayes 算法。TFIDF 的主要思想是:如果某个词或短语在一篇文章中出现的频率高,并且在其他文章中很少出现,则认为此词或者短语具有很好的类别区分能力。TFIDF 方法倾向於过滤掉常见的词语,保留重要的词语。
Naive Bayes 算法是以阙值大小对文本数据进行划分[4]。利用:
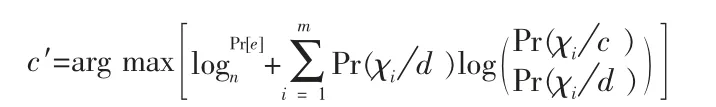
其中,χi指C 类文档第i 个特征,Pr(χi/d )是从C 类文本中得到特征词χi的概率,Pr(χi/d )是从文本d 中得到特征词χi的概率,n 指d 中词的个数,m 是系统词典的大小。若所得阙值大于预先设定的值,则认为文本d 属于C 类别,否则不是。
从概率的大小来研究,Naive Bayes 算法可描述为: 设文档d 的文档向量的分量为相应的特征词在该文档中出现的频度,则d 属于C 类文档的概率公式为:
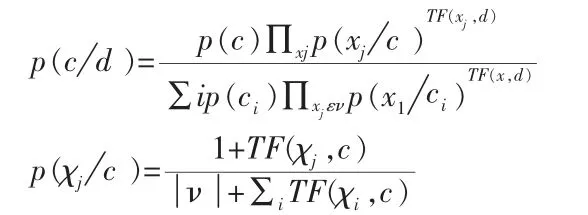
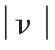
4 实例说明
利用Naive Bayes 算法,通过对用户提交信息的关键字的提取,对专利信息进行智能归类。
现假设已经对用户提交信息提取完毕,形成的样本为: 发明、请求、权利。且已事先给定一组分好类的文本作为训练数据(如表1),完成对新样本的分类。

表1
如上所述,该文本用属性向量表示为d=(发明、请求、权利),类别集合为Y={发明专利、外观专利}。
类“发明专利”下总共有5 个词语,类“外观专利”下总共有3 个单词,训练样本单词总数为8,因此P(发明专利)=5/8,P(外观专利)=3/8。类条件概率计算如下:
P(发明|发明专利)=P(权利|发明专利)=P(请求|发明专利) =(1+1)/(5+)=2/8
P(发明|外观专利)=P(权利|外观专利)=(0+1)/(3+)=1/6
分母中的5,是指“发明专利”类别下文本长度,也即训练样本的单词总数,3 是指训练样本有:发明、请求、权利共3 个单词,是指“外观专利”类下共有3 个单词。
有了以上类条件概率,开始计算后验概率:
P(发明专利|d)=2/8×2/8×2/8×5/8=5/512≈0.0097656
P(外观专利|d)=1/6×1/6×2/6×3/8=2/1728≈0.0011574
比较大小,即可知道这个文档属于“发明专利”类别。即将专利信息都归属到“发明专利”类别下,从而减少了人工操作选择。
5 结束语
Web 文本挖掘有利于文本特征项的提取和特征缩减,Web 的文本分类算法对Web 文档的自动分类有极高的参考价值,对Web 文本挖掘有一定的指导意义。然而,对Web 文本的智能分析涉及Web 数据自动采集、Web 数据自动分析、统计分析、数据挖掘和人工智能以及复杂社会网络等技术,是一个复杂过程。
[1]张群.文本挖掘技术及其在专利信息分析中的应用[J].现代情报,2006(3):209-21.
[2]王继成.Web 文本挖掘技术研究[J].大理学院学报,2011(4):513-520.
[3]张玉峰,何超.基于Web 挖掘的网络舆情智能分析研究[J].实践研究,2011(4):64-68.
[4]王一蕾,林世平.Web 文本挖掘三种技术的比较[J].福建电脑,2003(12):20-21.
