数据挖掘工具在医保定点药店非现场监管中的应用
2013-08-15傅松涛熊少华
傅松涛 李 珏 熊少华
(宁波市医保中心 宁波 315010)
1 背景介绍
截至2012年底,宁波市区范围医保定点医药机构已超过500家,其中定点零售药店超过300家,而医保经办机构专职稽查人员仅有6人。显然,单靠人力资源实施监管力不从心。同时,一些药店为追求利润最大化,将保健品、食品甚至化妆品串换成医保药品,记入医保结算,不仅造成医保基金损失,而且对守法经营的药店造成负面冲击,社会影响极为恶劣。因此,如何有效地揪出侵蚀医保基金的“硕鼠”、维护基金安全是医保监管的难点和重点。采用数据挖掘技术,使用非现场监管手段核查药店的经营行为,应是医保稽查着力探索的问题。
2 数据挖掘工具R语言和“购物篮”分析简介
R语言是用于统计分析、绘图的语言和操作环境,是一套完整的数据处理、计算和制图软件系统,同时也是一个免费的开源软件。在学术领域, R语言是国际上统计分析和数据挖掘的标准语言。在数据挖掘语言流行度方面,R语言近年连续排位第一,R语言的计算结果也已被美国FDA(美国食品药品管理局)认可。
关联规则挖掘被用于发现大量数据中项集之间有趣的关联或相关关系,“购物篮”分析是关联规则挖掘的一个典型应用。通过发现顾客购买的不同商品之间的联系分析顾客的购买习惯,了解哪些商品频繁地被顾客购买,并根据关联规则制定营销策略以促进销售。该方法目前在各类电子商务网站已被广泛使用。“购物篮”分析首先找出最小支持度值的频繁项集(支持度大于最小支持度的项集称为频繁项集),然后由它们产生满足最小置信度值A≥B的强关联规则,其中支持度是指购买A和B商品的项集占所有购买项集的比率,置信度是指已经购买A商品的人购买B商品的概率。关联规则挖掘算法中最经典的算法是Apriori算法(一种使用逐层搜索迭代方法找出频繁项集并产生强关联规则的算法)。本文使用R语言和Apriori算法实施“购物篮”分析,所涉数据处理及绘图均在R2.15.2系统下完成。
3 识别违规嫌疑药店思路
宁波医保的个人账户分为当年个账和历年个账,其中当年个账可直接用来在零售药店购买非处方药物。为防止当年个账资金滥用,宁波医保对药店非处方购药的每次购药金额有一定限制(每人每日每次100元限额)。违规药店将自费药品、保健品等出售给参保人员时,必然会串换成医保非处方药记入医保结算。因此,药店一般采取若干种药品的组合来达到或接近购买限额,这样就会造成该若干种药品组合频繁出现,稽查人员可以根据关联规则辨识这些药品组合,若这些药品组合在药理学上没有强关联性且又频繁出现,则可以初步判断药店存在串换药品嫌疑,可在对包含这些药品组合的就诊明细记录进行分析的基础上,现场稽核药店对应药品组合的进销存数据,以及时发现药品串换等违规行为。若一个药店的销售大于药品的进货和存量,极有可能将保健品等商品串换为药品销售。
4 实践过程
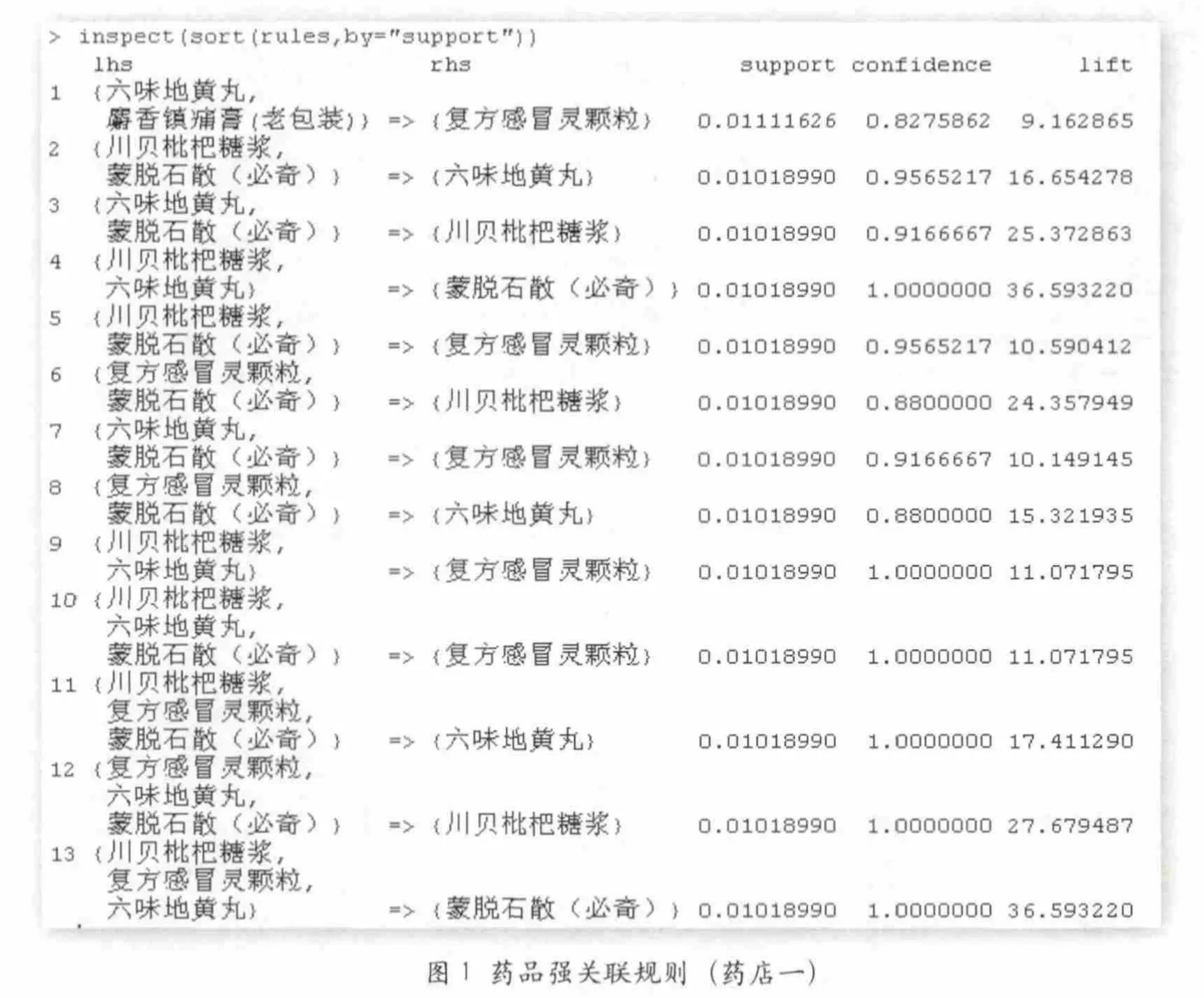
我们采集了3家药店1个月的非处方药购药明细数据进行比对,其中两家已查实为串换药品违规药店,另一家为非处方药购药规模居前的大型零售药店。对这几家药店上传的就诊编号和药品名称数据,应用Apriori算法搜寻置信度大于0.6且支持度大于0.001的关联规则,并根据支持度排序,部分结果如图1所示:
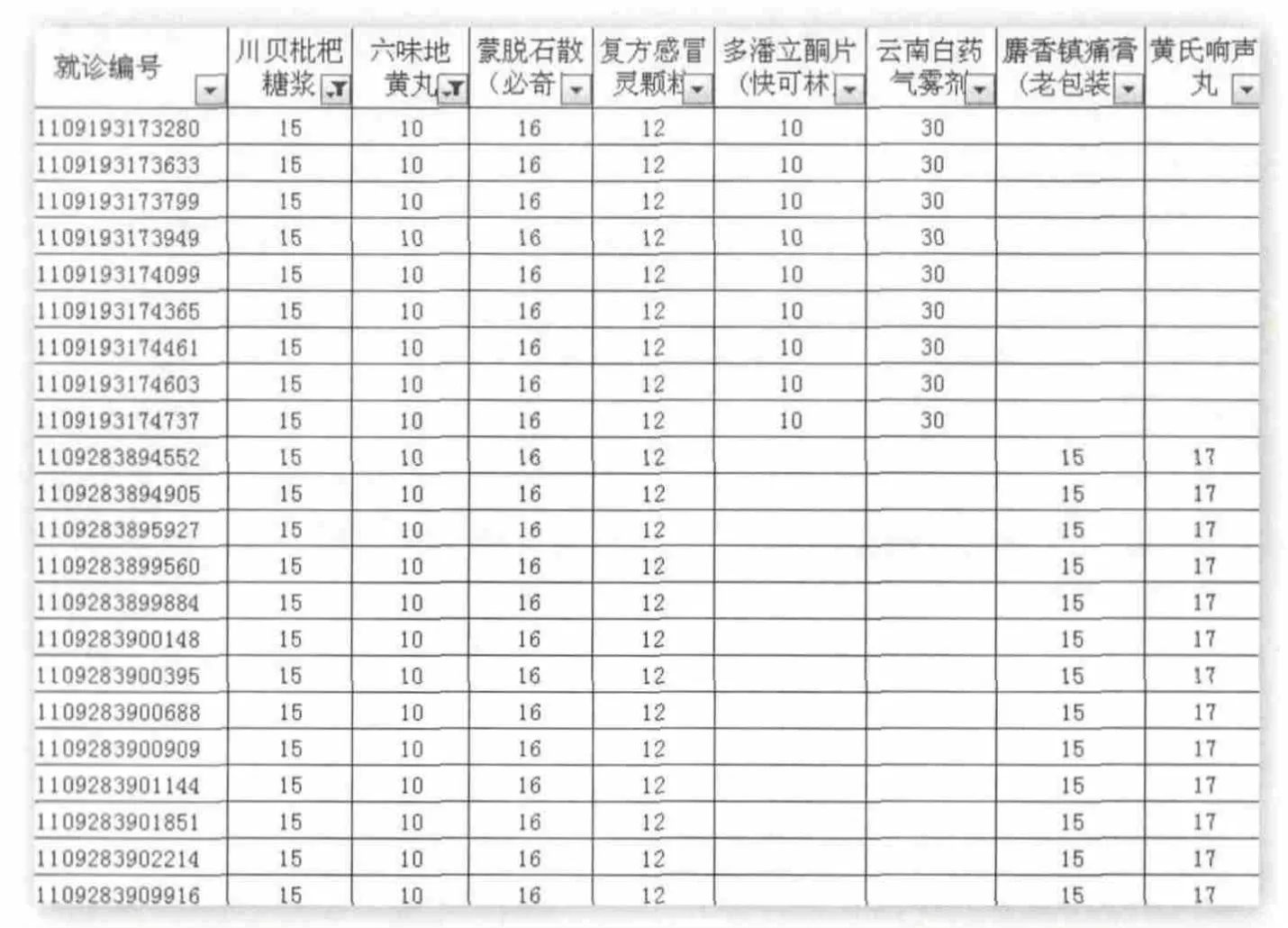
图2 强关联规则药品就诊记录(药店一)

图3 药品强关联规则(药店二)
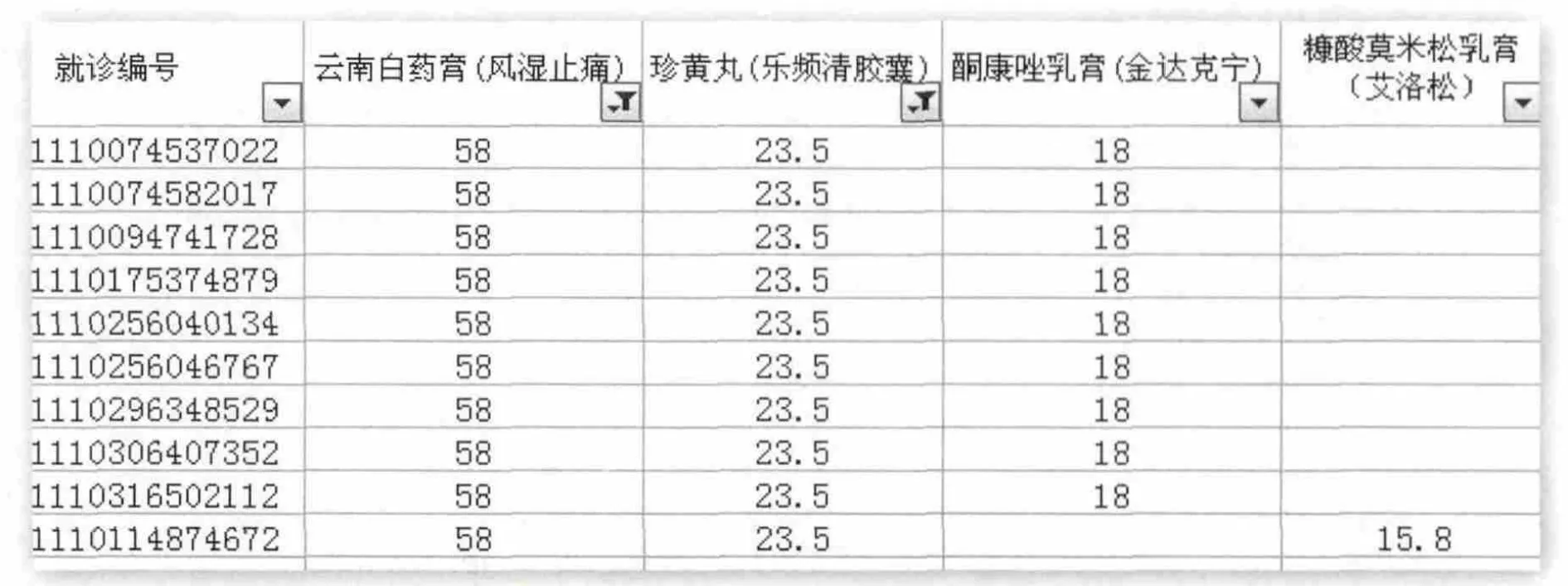
图4 强关联规则药品就诊记录(药店二)
第1家药店违规情形非常明显。第10-13条结果对应的confidence=1和support=0.01018990,含义是:对川贝枇杷糖浆、六味地黄丸、蒙脱石散和复方感冒灵颗粒4种药品而言,购买其中任3种药品的人购买剩余1种药品的概率为100%;购买这4种药品的购药次数占所有次数的比率为1.019%。由于在药理学上这4种药品没有强关联性,因此可以初步判断川贝枇杷糖浆、六味地黄丸、蒙脱石散和复方感冒灵颗粒4种药品存在被串换嫌疑。
通过调取同时购买这4种药品的就诊记录,发现购药行为只发生在9月19日和9月28日两天,其中9月19日当天购买该4种药品的人同时还购买了多潘立酮片和云南白药气雾剂,金额合计均为93元;9月28日当天购买该4种药品的人同时还购买了麝香镇痛膏和黄氏响声丸,金额合计均为85元。在掌握了嫌疑药品明细数据的基础上,通过对药店药品进销存数据的现场稽核,证实了该药店确实存在串换药品的违规行为(见图2)。
第2家药店的嫌疑药品组合是云南白药膏(风湿止痛)、珍黄丸(乐频清胶囊)和酮康唑乳膏(金达克宁),同时购买该类药品的共有10条记录,其中9条记录购买金额均为99.5元,剩余一条记录购买金额为97.3元。酚咖麻敏胶囊(双效)、铝碳酸镁片(达喜)、 云南白药气雾剂和乌灵胶囊则是另一组嫌疑药品组合(见图3、图4)。
我们再来观察没有进行药品串换的药店Apriori算法运行结果,以进行对比(见图5):
该计算结果和违规药店的明显不同之处在于:一是支持度比违规药店更低,最高的也只有0.568%,而置信度大于0.8的寥寥无几。也就是说,如果按照支持度大于0.005和置信度大于0.8对大型零售药店进行计算处理的话,将会得到一个空集,和违规药店计算结果存在较大差异。二是置信度高的药品组合之间存在药理学上的强关联性。

5 思考和建议
从上述实践过程可以得出结论,通过运用R语言工具,采用“购物篮”分析方法,能够识别使用药品组合进行药品串换的行为。这样就可以利用R语言的面向对象程序设计功能,编写代码,在后台定期批量筛选药品串换嫌疑药店进行稽查,争取将药品串换行为遏制在起始阶段,维护医保基金安全。结合“购物篮”分析方法的实际运用,笔者提出以下建议:
5.1 灵活使用算法阈值。由于药店非处方药购药行为集中度较低,如果按照普通标准(支持度0.01,置信度0.5)对药店交易明细进行处理,可能会错失重要信息。建议根据实际情况降低支持度标准,提高置信度标准。
5.2 突破内存使用瓶颈。R语言会把所有的对象读入内存进行计算,当数据量过大时会产生跟内存相关的错误而无法处理,因此建议尽量使用R的数据库连接功能。有条件的可以直接采用数据库厂商提供的R语言企业级应用产品,这样不仅可以突破R语言内存使用瓶颈,而且因为是在数据库内部使用R语言,从而免去了变量映射、数据存储等最易犯错和最费时的前期数据准备工作。
5.3 立体化数据源。对于药品明细项这样的原始层数据,由于多种同类药品分散购买,使得强关联规则很难发现。建议在数据准备期建立多个概念分层(对药品进行大分类,如感冒类、心血管等分类),自顶而下随层次从高到低逐步递减支持度,通过多层关联规则发现更具普遍意义的知识。条件成熟时还可以考虑在购药明细中加入购药者年龄、性别等数据,对多层多维关联规则进行数据挖掘。
[1]Jiawei Han, Micheline Kamber. Data Mining: Concepts and Techniques [M].范明,孟小锋译.北京:机械工业出版社,2005:149-172.
[2]Robert I.Kabacoff .R In Action:Data Analysis and Graphics With R [M].高涛,肖楠,陈钢译.北京:人民邮电出版社,2013.
[3]Luis Torgo.Data Mining With R:Learning With Case Studies [M].李洪成,陈道轮,吴立明译.北京:机械工业出版社,2013.
