基于集聚度增量的空间聚类算法
2013-08-08陈娱许珺徐敏政
陈娱,许珺,徐敏政
(1.中国科学院地理科学与资源研究所资源与环境信息系统国家重点实验室,北京 100101;2.中国科学院大学,北京 100049)
0 引言
空间聚类的目的是对空间物体的集群性进行分析,将其分为不同的子群[1]。聚类分析研究的经典算法有K-means、DBSCAN算法等,其主要应用于空间聚类分析中。空间聚类算法中常用的有基于划分的方法、基于层次的方法和基于密度的方法[2]。基于划分的方法是指在分类之初预先确定分类个数,创建一个初始划分,然后循环再定位,从而改变节点的归宿,最终得到最优聚类结果,其典型代表是经典的K-means算法[3]。系统聚类就是基于层次的方法,不断地合并空间点直到聚至一个适当的分类个数。基于密度的方法主要思想是只要邻近区域的密度超过某个阈值,就继续聚类,可以发现任意形状的类,DBSCAN是这类算法的代表[4]。
上述算法存在着不同的缺陷,其中一个引起关注较多的问题是:在不知道分类个数的情况下,如何获得最优的聚类结果?例如在K-means算法中,必须确定聚类个数之后,才能利用类内方差这个准则函数判断最优的聚类结果。而在复杂网络研究领域,模块度的概念被提出,用于评价复杂网络中节点聚类质量的好坏,模块度值越大说明聚类结果越优。如此则在复杂网络拓扑结构聚类中无需预先设定类的个数。本文借鉴这个值的定义,构造了评价空间聚类结果质量好坏的标准——集聚度;然后基于该值提出了一个快速的层次聚类算法,可以在不预知分类个数的情况下得到空间点集的最优聚类结果,且时间复杂度较低。
1 集聚度S值的定义
1.1 模块度Q值
复杂网络的研究意在探寻事物之间错综复杂的关系,挖掘出意想不到的规律。例如,城市路网、航线网络、社交网络等都是典型的复杂网络。在复杂网络研究领域中,社区结构挖掘是一个研究热点。将网络划分为若干个群,群内节点间的连接较为紧密,而群与群之间的连接较为稀疏,社区就是指这样的群,社区结构挖掘其实就是复杂网络领域的聚类分析。如图1中的小型网络,它具有较为明显社区结构(图2)。为了得到网络最优的社区结构,提出模块度的概念。模块度即为网络呈现出的模块化的结构,是衡量网络社区结构挖掘质量好坏的标准[5],模块度值越大则这种模块化结构越明显。其公式为:其中,eij表示网络中连接社区i和j的节点的边占所有边的比例,ai表示与第i个社区中的节点相连的边占所有边的比例,其值为eij矩阵的第i行元素之和。模块度的物理意义是:社区内部边的数目占网络总边数的比例减去社区内部边数的期望值占网络总边数的比例。Q值越大(上限为1)表示社区内部连接的稠密程度大于随机分布下的期望值,Q值越接近1,说明网络的社区结构越明显。


图1 小型的网络Fig.1 A small network
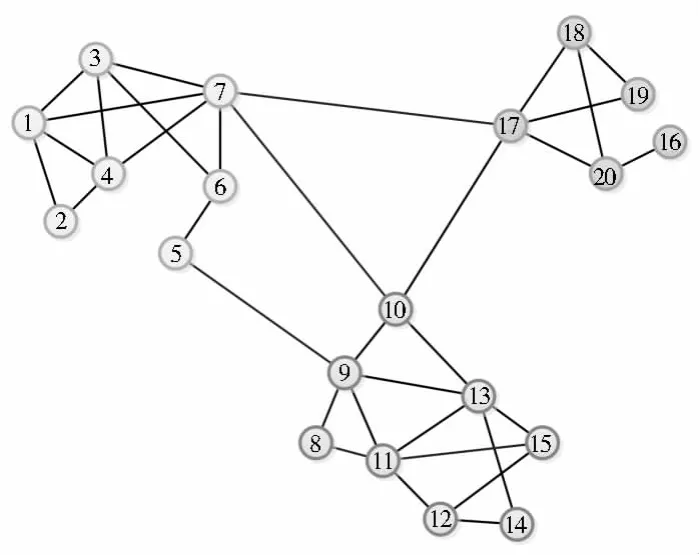
图2 社区结构Fig.2 Community structure
1.2 集聚度S值
对于空间上的点集,聚类的基本思想是:根据点与点之间的空间距离,将点群划分为若干个群,群内的点尽可能集中,不同的点群尽可能分离。不管是网络的社区结构还是空间点集的群簇结构,聚类的目标一致。因此,根据复杂网络理论中的模块度公式构造一个类似的函数S,用来判别空间点群的集聚性。
事物彼此相关,如果把这种影响看成其间的关系,用“连接”表达,就会形成一个网络[6]。因此,把空间上的点集看做是两两相连的网络,而其间的空间距离就反映了连接的强弱,边长即为两点间的空间距离。
首先,获得点集的直径O(点集中相距最远的两点间的距离),dvw表示节点v和w 间的距离,定义δvw=1-dvw/O,该值反映了相距为dvw的两个节点v和w之间的相似度。若两节点相距为0,则相似度为1,若两节点相距为整个点集的直径大小,则相似度为0。由此,定义Dij,它表示群簇i中的点与群簇j中的点的相似度与点集中所有点对之间的相似度之和的比值。

其中,v、w分别表示群簇i和j中的节点,δvw表示其间的欧式距离,M表示点集中所有点对之间的相似度之和。根据式(2),可以构建矩阵Dij。

其中,U表示整个点集。
定义ci为矩阵Dij中每行元素之和:

ci表示群簇i中的点与其他所有群簇中的点的相似度之和与点集中所有点对之间的相似度之和的比值。
由此得到S的表达式如下:

对于不同的点群集合,S值越大代表该集合的集聚性明显(即有更为明显的群簇结构)。
2 基于集聚度S的空间聚类算法
基于模块度的概念,Clauset等提出一个快速社区挖掘算法(CNM算法)[7],该算法的思想是:初始时认为每个节点就是一个社区,不断地合并能得到模块度值增加最大的两个社区,直到网络的模块度值达到峰值。根据CNM算法,本文根据S值提出了一种空间聚类算法,基本思想是:首先将点集中每个节点看做一个群簇,如果合并两个群簇i和j,则S的变化值为ΔSij:

因为S值越大,表示聚类的结果越优,所以合并的方向应该沿着使ΔSij值最大的方向进行,直到S值达到峰值停止合并过程。这种算法是一种基于贪婪算法思想的层次凝聚算法。具体步骤为:
(1)初始化,每个节点为一个独立的群簇。读取节点的坐标,计算两两之间的距离和点集的直径O,初始化Dij和ci如下:

(2)根据式(5)构建初始ΔSij矩阵;
(3)选择最大的ΔSij,合并相应的群簇i和j,标记合并后的群簇为j,同时更新ΔSij矩阵。在本文中,对于空间聚类,当群簇i和群簇j合并,另一个群簇k与合并后的群簇之间的距离不是原本的dik与djk之和,而是k与合并后群簇的距离,为了简便,采取的是二者的均值,因此ΔSij矩阵中ΔS′jk更新为:

由式(9),更新矩阵的第j行和第j列元素,删除i行i列的元素。
(4)记录合并后的S值:

(5)重复步骤3、步骤4,直到归并为一个群簇为止。
3 实验与讨论
3.1 不同点集的S值对比实验
对于不同的空间点集,可以根据S值判断其空间分布是否具有较强的集聚特性。图3为实验的3种不同的空间点集经过本文算法得到的S值。图3a与图3b均为20个点,但图3b的空间集聚度高,它的S值为0.013,大于图3a的0.0076;图3b与图3c相比,虽然图3c空间点数目多(为30个),但二者集聚度相差不大。
为了提供对比,引入空间聚类中类内方差(群内所有点到其质心的距离平方和)和类间方差(群簇的质心之间的距离平方和)概念。在K-means算法中,类内方差值作为准则函数,在ward算法中,直接以类内方差值的增量作为聚类统计量[8]。一类簇的紧凑程度可用类内方差刻画,而对于点集总体可以由类间方差与类内方差之比来度量[9],为了比较不同点集,用其均值之比来衡量。类内均方差SSE和类间均方差SSB表达式为:

其中,N指点的总数,xT和yT是指类T的质心坐标,xC和yC是指整个点集的质心坐标,nT是指类T中的节点个数。
图3中的3个点集都聚为3类时,类内均方差和类间均方差以及类间均方差与类内均方差的比值如表1所示。类间方差越大,类内方差越小(即比值越大)则聚类结果空间上集聚性越明显。从表1看出,本文提出的集聚度S值与该比值一致,都反映出图3b的集聚性最高,其次是图3c。这同时也说明,本文提出的集聚度S不仅仅与类内的紧密度相关,也与类间的差异度相关,S值越大点集的群簇结构越明显。

图3 空间点集及其S值Fig.3 Space point sets and their Svalues

表1 3幅图对应的SSE、SSB及SSB/SSETable 1 TheSSE,SSBandSSB/SSEvalues of the three datasets
3.2 空间聚类算法实验
本文首先用图3a所示的空间点集对算法进行实验,聚类过程中S值的变化曲线如图4所示。发现S值并未出现与CNM算法中模块度一样的变化趋势,而是一直增大,直到整个点集聚合为一类。
在CNM算法中,由于网络的模块度会随着不断合并而达到峰值,再继续合并会带来模块度的下降,因此峰值就对应着最优的聚类结果。这是由于在复杂网络中,有少部分节点的度很高,也有一些节点的度很小,它不是一个两两相连的完全耦合图(如果网络为规则图形,则所有节点聚合为一个社区是最佳的聚类结果)。而本文中考虑的是点集中两两间的距离,相当于将点集看作两两相连的网络,因此根据模块度的定义,其增量值必然不断增大直到合并为一个群簇为止(图5)。如此面临和其他大多数空间聚类算法一样的问题:凝聚过程在何时停止获得的是最优结果。

图4 算法过程中S值变化曲线Fig.4 The Svalue over the course of the algorithm
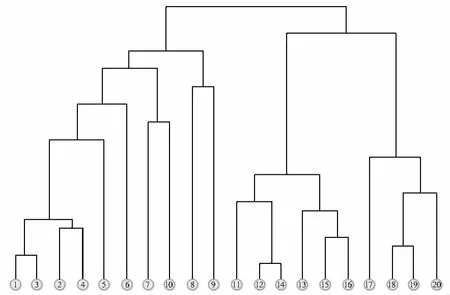
图5 聚类过程的树状图Fig.5 The dendrogram of the algorithm
基于这个问题修改算法:当两点间的距离大于一定值时,其间没有影响力,即没有这种隐藏的边相连接,这时δvw=0。本文将该值作为点集中所有点到点集质心的平均距离¯d。同时不采用网络直径O,而是取小于¯d的距离中的最大值。相应地,修改O值为¯d。具体修改后的算法为:
(1)初始化,每个节点为一个独立的群簇。读取节点的坐标,计算两两之间的距离dij以及所有点到点集质心的平均距离¯d,初始化Dij和ci如下:

其中:
(2)根据式(5)构建初始ΔSij矩阵;
(3)选择最大的ΔSij,合并相应的群簇i和j,标记合并后的群簇为j,同时更新ΔSij矩阵。此时更新分为3种情况:群簇k和群簇i、j间的距离均小于¯d;群簇k仅仅与群簇i的距离小于¯d;群簇k仅仅与群簇j的距离小于¯d。3种情况对应的更新值如下:

由式(16),更新矩阵的第j行和第j列元素,删除i行i列的元素。
(4)记录合并后的S值:

(5)重复步骤3、步骤4,直到S值达到峰值为止。
如图3a中的点集,点9(10,9.5)和11(16,4.5)之间的距离约为7.81,大于(约等于)7.768,定义其初始的Dij为0。根据修改后的算法,得到的S值的变化如图6所示,在第17步合并时,S值达到峰值0.2206,这时对应点集的最优聚类结果(图7),可以得到3个群簇。

图6 算法过程中S值变化曲线Fig.6 The Svalue over the course of the algorithm

图7 聚类过程的树状图Fig.7 The dendrogram of the algorithm
综上所述,S值的优势在于,对于不同的空间点集,可以比较它们的S值,其值越大代表该点集聚类特性越明显。同时,S值的提出解决了空间系统聚类中聚合过程的有效终止时刻的问题。最后,本文借鉴CNM算法提出的基于S值增量矩阵的快速聚类算法时间复杂度较低,经过试验可以快速准确地实现空间点聚类。
4 结语
本文借鉴了复杂网络研究领域的概念,基于空间上事物越接近越相关的定律,将空间点集看做是有边相连的网络,边表示其间的相关度,刻画这种相关度值为距离的函数,从而提出了集聚度S值的概念,用于评价空间点集的群簇结构。对于不同的空间点集,该值可以反映出其中哪个群簇结构更加明显。基于S值的增量矩阵,提出一个快速空间聚类算法能够快速有效地挖掘出群簇结构,且不用事先设定聚类个数。
本文还有值得深入研究之处。在算法中,合并两个群簇,第3个群簇与合并后的群簇间的距离采用的是合并前的距离的均值,此处优化为群簇间质心的距离更为准确。同时,还可以继续探究其与经典算法(如K-means、DBSCAN)相比的优劣。
[1] 郭仁忠.空间分析(第二版)[M].北京:高等教育出版社,2001.93.
[2] 罗可,蔡碧野,吴一帆,等.数据挖掘中聚类的研究[J].计算机工程与应用,2003(20):182-184.
[3] LLOYD S P.Least squares quantization in PCM[J].IEEE Transactions on Information Theory,1982,28:128-137.
[4] ESTER M,KRIEGEL H P,SANDER J,et al.A density-based algorithm for discovering clusters in large spatial databases[A].Proceedings of the 2nd Internatinal Conference on KnowledgeDiscovery and Data Mining[C].Amsterdam:Elsevier Science,1996.226-231.
[5] NEWMAN M E J,GIRVAN M.Finding and evaluating community structure in networks[J].Phys.Rev.E,2004,69(026113).
[6] BARABÁSI A L.徐彬(译).Linked[M].长沙:湖南科学技术出版社,2007.8.
[7] CLAUSET A,NEWMAN M E J,MOORE C.Finding community structure in very large networks[J].Phys.Rev.E,2004,70(066111).
[8] TAN P N,STEINBACH M,KUMAR V.数据挖掘导论(英文版)[M].北京:机械工业出版社,2010.523-524.
[9] 孙吉贵,刘杰,赵连宇.聚类算法研究[J].软件学报,2008,19(1):48-61.
