并行点面叠加算法在动态调度和静态调度中的对比研究
2013-08-08邱强曹磊方金云
邱强,曹磊,方金云
(1.中国科学院大学,北京 100049;2.中国科学院计算技术研究所,北京 100190)
矢量数据叠加分析是空间分析中最基础、最重要的分析方法之一。大数据集的叠加分析耗时较长,耗时与数据规模具有正相关性。然而,随着数据采集手段的不断更新和GIS应用的持续深入,矢量数据呈现出海量化和处理实时化的要求,这对叠加分析在计算性能、处理能力等方面提出了新的要求[1]。并行计算将大的数据处理与计算分解为多个可相互独立、同时进行的子任务,并通过这些子任务相互协调的运行,实现快速、高效的问题求解[2]。点面叠加分析存在数据密集、计算量大等特点。由于点数据之间不存在数据加锁,利于划分,并且其归并过程不会带来冗余计算,因此点面叠加分析适用于并行计算环境。本文利用MPI消息传递模型,基于Linux集群实现了高效、鲁棒的并行点面叠加算法。
1 点的包含性测试
点的包含性测试是计算几何的基本问题,其含义是判断一个点是否位于多边形的内部。随着地理信息系统的发展,点与多边形的包含性测试成为空间数据处理的一个基本问题。研究人员提出了一系列点包含性测试算法。一些算法仅仅适用于特殊的多边形,如文献[3]中的方法仅适用于凸多边形,文献[4]中的网格法适合于栅格数据。另外一些算法如射线法、角度之和法、Winding Number法以及基于三角形的方法等[5,6]适用于任何多边形。
这些方法对单个点的包含性测试是高效的,但并不适合处理批量点。对大量点进行包含性测试最有效的方法是基于Cell的方法[4]和基于多边形凸剖分的方法[7]。基于Cell的方法将多边形栅格化,然后判断不含多边形边的栅格在多边形内部还是外部。对点进行包含性测试时,首先计算点在哪个栅格内,若所在栅格不含任何边,则可以在O(1)时间内得到点与多边形的关系;否则需要计算点与当前栅格所包含的边的关系。此方法对部分点的包含性测试时间复杂度是O(1),因此对于简单多边形是高效的。基于多边形凸剖分的方法是将多边形进行凸剖分,并用二叉空间分割(Binary Space Partition,BSP)树管理这些凸剖分,对任何一个点,查询BSP树,计算可能包含该点的凸剖分,然后通过点与凸剖分的关系得到点与多边形的关系。其包含性测试非常迅速,因此适合点集大的情形,该算法缺点是预处理时间较多,尤其对于边数较多的复杂多边形。
本文利用基于平均条带划分的点包含性测试方法[8]作为实现并行点面叠加算法的基础。该方法首先对多边形进行简单预处理,然后采用射线法对每个点进行包含性测试。预处理时,将多边形的最小包围矩形划分为相同大小的竖直条带,并计算每条边在哪些条带中,该预处理过程简单快速。利用预处理信息对点进行包含性测试时,只需用当前点构造的射线和点所在的条带包含的边进行相交测试即可。每个条带内包含的边的数目有限,常常接近一个常数,远远小于多边形的边数,因此相交测试计算次数显著减少,从而可以快速得到点与多边形的关系。
2 基于MPI的并行算法
本文实现了基于静态调度和基于动态调度两个版本,其差别在于数据划分和调度策略上。主要包括输入图层的读取、计算单元的划分、子节点运行点面叠加运算、结果生成4个步骤[9]。
2.1 动态调度
图1为基于主、从结构的点面叠加动态调度体系结构。动态调度流程如图2所示:首先,主节点从文件系统中读取拟求交的点、面图层(ShapeFile文件),完成文件读入后主节点开始对面要素图层建立R-tree[10]索引,并为每个面要素建立一个潜在的相交集合,用以存储与其可能相交的点;然后,主节点开始遍历每个点要素,如果点要素在某个面要素的MBR内部,则将点加入到对应面要素的集合中,作为一个基本的计算单元。算法1的伪代码描述了基于R-tree的数据划分过程。
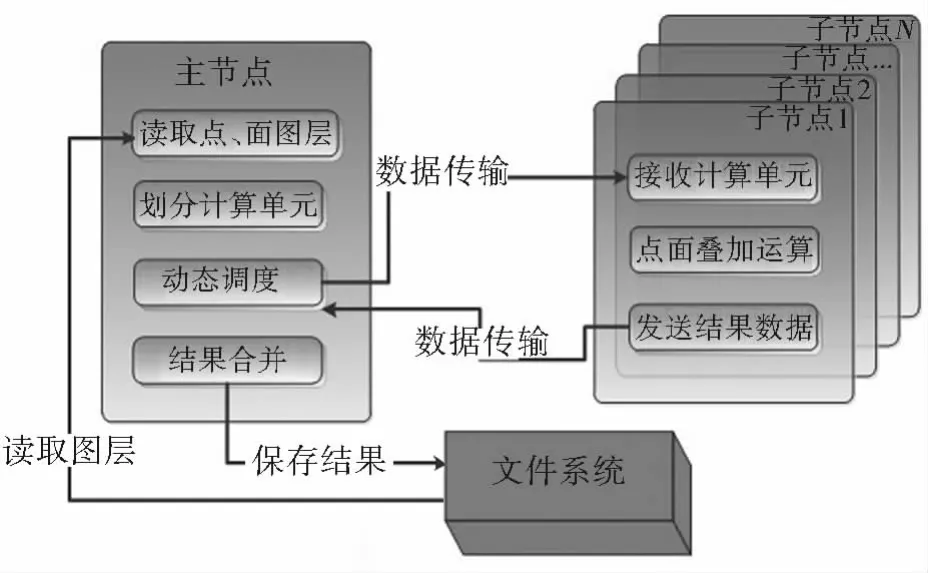
图1 动态调度体系结构Fig.1 Architecture with dynamic load strategy
预处理过程完成后,主节点将所有计算单元加入到任务队列中并开始调度,如图3所示。开始主节点顺次向每个子节点发送一个计算单元,子节点接收计算单元后,运行串行的点面叠加算法,完成计算后子节点暂时保存计算结果,并向主节点继续请求计算单元;主节点接收到请求后,查看调度队列中是否还有计算单元,如果有,就顺次取出下一个向该子节点发送,反之就向子节点发送完成消息;子节点接收到完成消息后,将计算结果全部发送给主节点,主节点接收到所有子节点的计算结果则表明调度完成;最后主节点将计算结果一并写入文件系统。
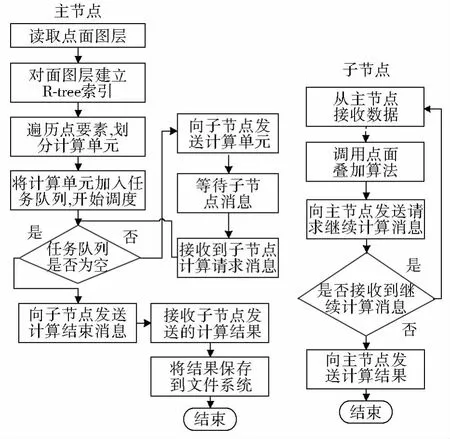
图2 动态调度主、子节点流程Fig.2 Master/slave node process of dynamic load strategy

图3 动态调度过程Fig.3 Process of dynamic load strategy
2.2 静态调度
相比于动态调度,静态调度比较直接和简单,如图4所示。首先,主节点从文件系统中读取要求交的点、面图层;然后主节点根据子节点个数N,将面图层根据要素ID分成N份,算法2描述了基于要素ID的数据划分过程;之后主节点将相应的面要素以及所有的点数据发送到相应的子节点,即子节点i接收数据Di后,运行串行的点面叠加算法,一旦完成计算,子节点便将结果发送给主节点;主节点接收到所有的子节点的数据后,便将计算结果写入到文件系统。
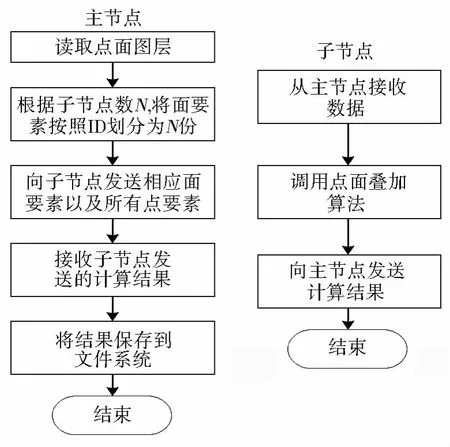
图4 静态调度主、子节点流程Fig.4 Master/slave node process of static load strategy

2.3 动态调度与静态调度对比
2.3.1 数据划分 如算法1所示,在动态调度中,主节点对面要素图层建立R-tree索引,并为每一个面要素建立一个潜在的相交集合,用以存储与其可能相交的点。索引建立完成后,主节点开始遍历每一个点要素,如果点要素在某一个面要素的MBR内部,则将点加入到对应面要素的集合中,作为一个基本的计算单元。
在静态调度中,如算法2所示,主节点根据子节点个数N,将面图层根据要素ID分成N份,然后将相应的面要素以及所有的点数据作为一份发送到相应的子节点。按ID划分的方法相对粗略,不能表达出划分对象的空间特性。当空间数据分布不均衡时,容易造成划分出来的各集合中空间对象分散,邻近性差;虽然各个子任务的要素个数相等,但由于各个要素大小、复杂程度不同,容易导致数量倾斜严重,降低并行运算效率。
2.3.2 调度策略 动态调度中,如图3所示,主节点维护一个任务队列,并动态的根据子节点任务的完成情况,不断地向空闲的子节点发送计算单元,直到任务队列为空;静态调度中,主节点只在一开始向子节点发送数据,一旦发送完成,主节点就等待接收子节点的结果数据。
3 实验与分析
3.1 实验环境与数据
实验所采用的硬件环境为:CPU Intel Xeon,主频3.4GHz,共8核;内存4GB DDR3 1 333MHz ECC;外存500GB 7200RPM SATA硬盘;采用千兆以太网连接各个节点。软件环境:操作系统为64位CentOS专业版;MPI采用OpenMPI版本;集成开发环境为Eclipse+CDT;采用GCC作为编译器。
实验所用的点数据是全国居民点数据,点要素的个数为649 592个,对应的Shapefile文件大小为139MB;面数据是全国县界,面要素的个数为2 449个,对应的Shapefile文件大小为36.8MB。
3.2 动态调度与静态调度对比
图5显示了基于动态调度的并行点面叠加算法的实验结果,节点数分别是1、2、4、6、8。从总时间、I/O时间、计算时间3个维度进行对比。其中,I/O时间包括主节点从文件系统读入点、面数据以及主节点将最终的计算结果写入到文件系统中的时间;计算时间包括主节点的预处理时间、通信时间及子节点的运算时间;总时间是I/O时间与计算时间之和。从图5中可以看出,节点数从1增加到8,总时间下降显著;I/O时间随着节点数的增加,基本保持不变;而计算时间与总时间变化趋势类似,即节点数从1增加到8,计算时间明显降低。
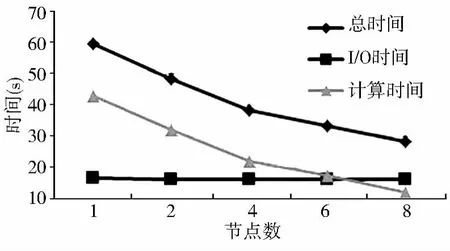
图5 动态调度Fig.5 Dynamic load strategy
图6显示了基于静态调度的并行点面叠加算法的实验结果。总时间、I/O时间以及计算时间的变化趋势与动态调度的趋势类似。

图6 静态调度Fig.6 Static load strategy
图7、图8、图9分别从总时间、计算时间和I/O时间对动态调度和静态调度做了对比。从总时间看,除了1、2个节点外,动态调度都优于静态调度,但优势并不明显。究其原因,一方面是由于动态调度的预处理中构建面要素的计算单元要占用一部分时间,而静态调度几乎不需要预处理,直接根据要素ID顺次分配给子节点即可;另一方面,动态调度每次给子节点发送一个面要素以及可能相交的点要素,而静态调度一次性把子节点所需的所有数据发送完,因此相比于静态调度,动态调度增加了通信开销。由于上述两个原因,虽然动态调度提高了各个节点间的负载均衡,但相比于静态调度,性能提升不明显。对于I/O时间,由于要素的读入与写回都是串行的,因此随着节点数的增加,I/O时间并未减少,这也成为并行点面叠加算法性能提升的瓶颈。

图7 总时间Fig.7 Total time

图8 计算时间Fig.8 Computing time

图9 I/O时间Fig.9 I/O time
4 结论与展望
本文利用MPI实现了基于Linux集群的并行点面叠加算法,并对比了动态调度和静态调度两种调度策略。实验表明,动态调度策略总体优于静态调度,但由于动态调度增加了预处理时间和通信时间,但没有减少I/O时间,因此优势不明显。
由于动态调度每次只给子节点发送一个面要素以及可能相交的点要素,因此增加了通信开销。这种开销在多机多核和集群下的增加更为明显。下一步考虑增大数据划分的粒度,即在动态调度中,主节点一次向子节点传输多个面要素,从而减少通信开销。
由于I/O不可并行,因此随着节点数的增加,I/O时间并没有减少,这成为并行点面叠加算法性能提升的瓶颈。利用并行文件系统减少I/O开销将作为未来工作的重点。
[1] 王结臣,王豹,胡玮.并行空间分析算法研究进展及评述[J].地理与地理信息科学,2011,27(6):1-5.
[2] 陈国良.并行计算:结构·算法·编程[M].北京:高等教育出版社,2003.4-7.
[3] HUANG C,SHIH T.On the complexity of point-in-polygon algorithms[J].Computers & Geosciences,1997,23(1):109-118.
[4] ZALIC B,KOLINGEROVA I.A cell-based point-in-polygon algorithm suitable for large sets of points[J].Computers & Geosciences,2001,27(10):1135-1145.
[5] HORMANN K,AGATHOS A.The point in polygon problem for arbitrary polyogns[J].Computational Geometry:Theory and Applications,2001,20(3):131-144.
[6] FEITO F,TERRES J C,URENA A.Orientation,simplicity,and inclusion test for planar polygons[J].Computers & Graphics,1995,19(4):595-600.
[7] LI J,WANG W,WU E.Point-in-polygon tests by convex decomposition[J].Computer & Graphics,2007,31(4):636-648.
[8] 朱效民,刘焱,廖浩均.基于平均条带划分的点的包含性测试方法[J].高技术通讯,2011,21(8):810-816
[9] AGARWAL D,PURI S,HE X,et al.A system for GIS polygonal overlay computation on linux cluster-an experience and performance report[A].Parallel and Distributed Processing Symposium Workshops &PhD Forum (IPDPSW),2012IEEE 26th International IEEE[C].2012.1433-1439.
[10] GUTTMAN A.R-trees:A dynamic index structure for spatial searching[J].ACM,1984,14(2):47-57.
