基于BP模型的KAD网络核心节点识别算法研究
2013-08-07冯伟森邱兴超
王 建,冯伟森,邱兴超,刘 继,卢 林
WANG Jian1,2,FENG Weisen1,QIU Xingchao1,LIU Ji1,LU Lin1
1.四川大学 计算机学院,成都 610041
2.四川大学 锦城学院 计算机科学与软件工程系,成都 611731
◎网络、通信、安全◎
基于BP模型的KAD网络核心节点识别算法研究
王 建1,2,冯伟森1,邱兴超1,刘 继1,卢 林1
WANG Jian1,2,FENG Weisen1,QIU Xingchao1,LIU Ji1,LU Lin1
1.四川大学 计算机学院,成都 610041
2.四川大学 锦城学院 计算机科学与软件工程系,成都 611731
针对在KAD网络中核心节点的识别问题,提出了一种基于BP模型对节点重要程度进行实时判定的方法。结合KAD网络测量的结果,对网络中核心节点的属性特征进行提取和归一化处理,获得了一组可分离度较高特征集合。采用MatLab设计相应的学习算法对BP网络进行训练,使结果收敛于预定误差区间。将完成训练的BP网络模型应用于对测试节点的判定,实验结果表明该方法可以实时地完成核心节点的判定,并且识别准确率可达到约70%。
反向传播算法;KAD网络;核心节点;识别
1 引言
网络节点的排序问题是复杂网络中的一个基本和重要问题,被广泛应用于数据挖掘、网络分析、网络预测、网络安全与控制等领域。随着复杂网络研究的深入发现,大量真实的网络既不是规则的,也非完全随机的。因此,有效地评估和度量网络中节点的重要性,不但是网络数据挖掘的首要问题,也是复杂网络、社会关系网和互联网搜索、系统科学的研究重点[1]。KAD是P2P技术历经10年发展后的新一代DHT网络[2],其去中心化、可测量、易扩展、高容错性等优点使它迅速渗透到文件共享、即时通讯、分布式存储、云存储等领域。这种无中心服务器的设计使得各个节点相对平等,既是服务的提供者,又是服务的请求者。KAD网络的发展使其并发用户已达到数百万级,海量的用户使得对于网络的控制和监管变得十分困难。大量网络测量实验表明,DHT网络中节点负载非均衡性广泛存在[3-5]。可以将那些在KAD网络中为其他节点提供了更多路由服务或下载服务的节点称为核心(重要或关键)节点。如果能利用这种非均衡性,发现和识别网络中发挥了核心作用的节点,则是对KAD网络的监督将有着重要的作用。
2 相关工作
基于链接的节点排序是网络分析中的一个核心任务,它通过图中节点之间链接表现出的重要性不同对节点进行排序。目前国内外研究者对节点排序方法有四种典型的方式[6]:一是基于纯粹网络静态参数指标来进行衡量节点的关键程度,常用评价指标有点中心度、凝聚中心度、子图中心度、网络流中心度等等。基于传统的静态社会分析方法有着明显的缺点,它忽略引起网络状态变化的重要因素[7],从而造成信息缺失问题。例如,不注重个体之间的连接关系、相关个体之间的相互影响以及随时间变化趋势[8]。二是借鉴图分割方法中标准来进行衡量,即找出图中的割点作为核心节点,因为删除该节点后可以将图割裂为多个子图[9]。三是使用搜索引擎中节点排序的思想来进行核心节点发现排序,其主要的思想是基于随机行走模型[10]。四是使用基于统计方法或数据挖掘的算法,如频繁项集[11-12]、隐空间模型[13]、两阶聚类等经典模型。数据挖掘算法中以使用频繁项集的方法最为典型,但目前这些方法存在着节点判断的滞后性这个明显的缺点,即对于节点的重要程度的差别需要较大的时间和空间复杂度为代价才能得到,而无法实时地对一个未知节点进行判定。这在一些实时性要求较高的应用场景下将有着较大的限制。
3 核心节点评价算法
在KAD网络中,核心节点是指那些对网络的基本服务起着重要作用的节点,它们实际提供了更多其他节点的访问、路由工作,其定义表示如下[14]:
定义2(关键字热点)在任一区域Zx中,假设该区域中节点的索引Ia,若每个节点接受的访问数量为Ca。给定一个关键字访问次数阀值c,若Ca>c则称Ia为一个关键字热点。当其共有n个索引时,该节点的访问次数为其所有索引被访问次数之和:

定义3(核心节点)在任一区域Zx中,若节点A是一个路由热点,或节点A是一个关键字节点,若在给定的时间T内,A收到的访问次数R大于给定的阀值c,则A为一个核心节点。
神经网络是一个多学科交叉领域,它通过模仿人的大脑思维来挖掘海量数据背面的潜在规律,已在各个领域中得到了广泛应用,并取得了很多重要的成果。采用BP网络对当前已获取到的样本节点进行学习,期望挖掘出有价值的规律,以便对未知节点进行更加实时准确的判定。图1显示了使用BP神经网络进行训练和测试的整个流程,其中关键的环节在于样本特征提取和处理及网络训练两个步骤。
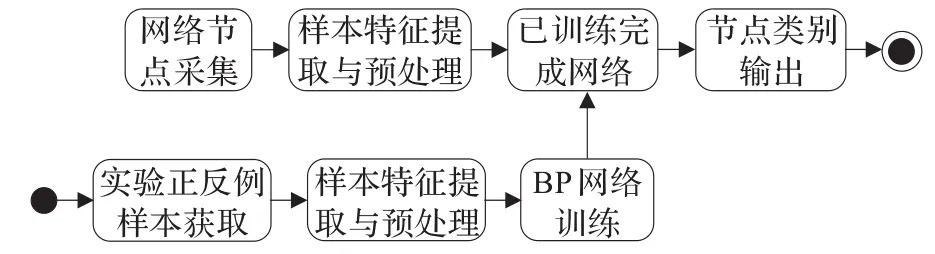
图1 样本数据训练流程图
图1中特征提取是指根据训练目标,从一组特征集合中选取一组最好的子集。为了处理方便,还需对特征数据进行归一化预处理,使其值均在[0,1]区间内变化。下面对KAD中可用的特征属性进行归纳和改进。
(1)R′c:返回节点的有效率
KAD每一次查询中,若该点不为目标节点时,会为请求者返回α个路由表中更靠近的节点。从KAD路由选择算法中可看出,当邻居节点收到请求后,先从对应K桶中选出指定数量的节点,当该桶中节点数量小于指定数量时,则从邻近的K桶中进行选取。那么,只要路由表中的节点总量不小于指定返回的节点数量,就一定会返回指定数量的节点。当各个邻居节点若在线,每次提供的下一跳路由节点的数量均相等。因此,采用数量计算并不能使其具有较好地可分离性,这里使用返回节点的有效率来进行衡量,计算公式如下所示:

其中,Bn表示节点I返回的下一跳的路由节点总数,Ln则为当前仍在线的节点数量。对于Ln值的获取,可以在邻居节点返回信息后,使用Ping操作探测其中仍在线节点数量。该值反映了一个邻居节点返回的路由信息中,仍然有效的节点占所有返回总量的比例。
人像蚕一样拼命织关系的网,但织成之后,却又千方百计逃之夭夭。范坚强给了一杭一个逃离的机会,可以放下一切,每日枕着书香入眠。一杭成为这间石屋实质上的主人以后,范坚强给他送来了书,让他在漫长的白天与黑夜,不至于孤独。但单纯的生活结束了,石屋的门终于打开来。
(2)S′c:平均异或距离
在KAD中以跳数作为度量依据,并不能准确地表明节点之间的距离,这里采用平均异或距离进行度量。此值描述了对一个节点进行询问后,返回结果能更接近目标节点的程度,反映了该点在一次查询过程中所起到的作用。若节点I共返回n个路由节点,则节点I的平均距离值由下列公式计算得到:

式中,ri代表I的一个返回节点,s与d分别代表请求节点与目标节点。从上式容易看出,当返回的距离越大,则表明通过节点I的查询后,与目标节点的位置将更接近。
(3)T′t:处理查询返回时间
该值越大表明了被查询节点处理性能更高。通常将发出消息和接收消息的时间间隔作为其往返时间。为了处理的方便,设定一个固定的TTL基数作为参照物,若小于此值则也近似地认为与此值相等,这里将TTL设定为2 000 ms。则该值由以下公式决定,其中Mt为返回时间中最大的一个值,也可设置一个固定的较大数值:

(4)R′i:节点返回查询数量比
该值反映了一个目标节点返回的文件数量占所有返回结果数量中的比例。采用如下公式进行计算:

其中,Rc表明本次查询所有节点返回的文件总和,但该值仅针对有返回结果的节点才可适用。由于不能保证测试的节点均为有存储结果返回的节点,因此,需要对经过多个节点路由转发得到的R′i进处理,确定每个节点的R′i值的大小。这里的基本思想是按各点的S′c的大小来按比例分配,S′c反映了节点推荐的路由节点接近目标的程度。即节点I推荐节点的距离越大,使得请求节点能更接近目标,则I所分到的R′i值则越多。其值的计算公式如下:

(5)F′d:节点返回查询质量比
该值反映了某点对查询返回结果文件名与查询词的平均匹配程度,它的计算公式如下:

Fi代表了一个返回文件与查询关键字的匹配程度;n代表某点所有返回的文件数量;c为不同节点返回的文件索引数量的总和。其值越大,表明本次查询所返回的值更好地匹配了关键字查询要求。
由于该值也仅适合于计算有返回结果的情况,因此,参照上一特征值处理过程,对其值使用以下公式进行转化:

通过以上的处理过程,可以得到一个归一化后的特征集合<R′c,S′c,N′m,R′i,F′d>。该集合中所有取值都已限定在[0,1]范围中变化。
为了进行训练,需要收集正反例样本进行学习与测试。训练样本的采集工具使用了自设计的软件KFetch[14]对网络拓扑快照进行获取,采用社会网络中凝聚中心度指标和随机行走算法对节点进行评价,将两种算法共同评价为核心和非核心的节点选出。测试的时间开始于2012年2 月4日20:00,采样时间持续40 min。这里选取了已有的核心节点作为正例样本,选择其中60%的节点作为训练样本,将余下的节点作为测试样本,产生了所需的训练样本和测试样本集。
4 实验过程与结果分析
针对不同的目的,可以在上述特征集中选取适合的子集进行训练。从KAD的消息类型可知,其主要有四种基本的RPC(Remote Process Command,RPC)。与查询相关的包括节点查询和关键字查询操作。由于两种消息用于不同的场景,因此其特征值子集也不相同。将两种消息命令与上面的特征集合进行一个映射后,选取适合的特征属性建立对应的特征子集。
将与Find_Node相关的特征集合标记为Cn,选取与其对应的特征有<R′c,S′c,N′m>。因为在以节点为目标的查询中,其返回的结果只有两种可能性,即能命中或不能目标。因此,对于返回结果的处理相对简单,则记为C′n=<R′c,S′c,N′m>。选择与Find_Value相关的特征集合标记为Vn,则与其对应的特征有<R′c,S′c,N′m,R′i,F′d>。该特征集合中含有查询结果索引及索引结果质量,这样可以更全面地考核用户查询后结果的命中情况,记为Vn= <R′c,S′c,N′m,R′i,F′d>。
使用Find_Node采集节点的特征属性。先将该区域划分为∂个部分,在各部分中随机挑选一个节点ID作为待查询目标ID。这样做的目的是更有效地考察某点到各个距离位置的情况。∂个测试服务器分别选定一个ID的邻居来生成客户端ID。开始测试时需保证一定的节点已将∂个节点的加入自己的路由表中。实验中参数∂设定为8,先对通过前面选的核心节点进行特征采集,测试时间持续25 min,完成所有待训练和测试节点的样本所需特征值的获取。
将得到的归一化处理后的样本数据组成为学习和训练样本,格式为:L=T=<R′c,S′c,N′m,E>。E为该节点的对应期望取值,即该节点为核心节点的概率。由于希望输出结果为一个概率值,因此在进行重要程度排序的时候,不能将一个最重要的节点与一般重要节点进行等同,这样将降低结果的精度。因此,需要将上述两种算法得到的核心节点进行相应变换操作。其方法是取两种方式所共同选中的核心节点,按重要程度排序后,对应指定结果的概率范围为[0.6,1]。即将所有核心节点进行5等分,每一部分区域中的节点给定一个对应的概率期望值,对反例样本的处理也是按此方法进行。将这样组成后的训练样本送入网络中进行学习,这里的实验中对学习误差设置为0.001。隐层神经元个数取输入层的1.4倍,即设置为5个,输入层的传递函数设置S型正切函数tansig,输出层的传递函数S型对数函数logsin,采用负梯度权值修正方法。为了降低编码的难度,其学习和测试过程均使用了MatLab[15]工具箱中的神经元组件进行实验,程序清单如下所示,其中输入数据整理为矢量形式,其值对应变量P,输出的期望值也按矢量方式赋值于变量T。

上面代码中minmax(P)是指以输入数据中的最大和最小值为训练数据的变化范围,net_1为训练后得到的输出网络。
通过多步的网络训练可得到了满足误差要求的样本数据拟合情况,实验结果如图2所示。
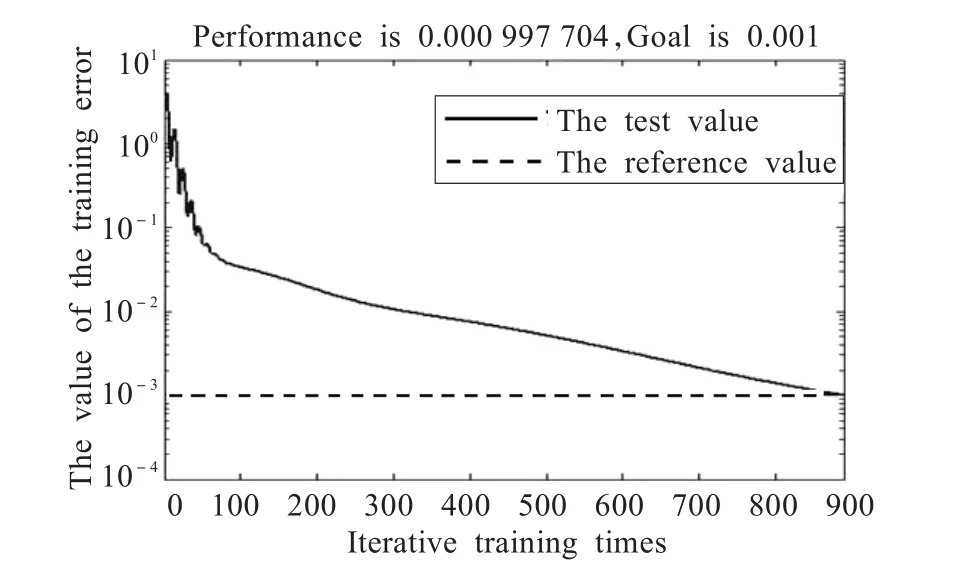
图2 Find_Node特征学习拟合效果图
由图2可以看出,当学习的次数到达889时,则误差已经控制在指定的范围了。将该训练完成的网络输出结果概率与期望值进行对比,将误差范围在0.2之内的均认为成功。那么,其中正例样本识别达到78.3%,反例样本的识别率达到了67.1%。将训练好的网络模型在实际的KAD中进行了验证,采用KFetch工具对节点关系进行获取后,抽取出在线节点的对应属性集送入模型中进行判定。每次实验时间持续30 min,实验共重复5次,对实验结果进行统计和分析。同时,将识别结果与使用凝聚中心度与随机行走算法所筛选出的核心节点进行对比,结果显示采用BP模型的核心节点识别率平均为63.8%。虽然实际网络中识别率略低于训练结果,但仍可证明该方法具有一定的可行性和实用性。
5 小结
本文通过利用测量实验收集KAD节点的属性特征,并根据查询命令选取了对应的特征子集进行实验。从实验结果可以看出,由于网络中节点的动态性命使得识别效率仍有待提高,但这种实时的判定方法可有效地解决判定的滞后性,具有更广阔的应用前景。为了改进识别的准确性,今后,将重点对节点的属性进行更为深入的研究。从上可知,BP网络性能的高低主要取决于两个因素:抽取的节点属性特征数量和选择的属性特征质量。寻找有效的节点属性特征需要更深入地对KAD网络中节点进行分析,抽取出节点有效属性特征来丰富属性集合。其次,尝试采用其他模式识别的方法,如模拟退火算法、Tabu搜索算法和遗传算法等[16],可以对现有的特征属性进行适当地变形、计算和提取,以得到更佳的具有可分属特征值,从而有效地提升核心节点识别的准确率。
[1]何建军,李仁发.改进的随机游走模型节点排序方法[J].计算机工程与应用,2011,47(12):87-89.
[2]Maymounkov P,Mazieres D.Kademlia:a peer-to-peer informaticssystem based on theXOR metric[C]//Proceedings of the 1th International Workshop on P2P Systems,2002:53-65.
[3]蒋君,邓倩妮.eMule系统中的非均匀性分布[J].微电子学与计算机,2007,24(10):153-156.
[4]熊伟,谢冬青,焦炳旺,等.一种结构化P2P的自适应负载均衡方法[J].软件学报,2009,20(3):661-663.
[5]李振宇,谢高岗.基于DHT的P2P负载均衡算法[J].计算机研究与发展,2006,43(9):1579-1580.
[6]周春光,曲鹏程,王曦,等.DSNE:一个新的动态社会网络分析算法[J].吉林大学学报:工学版,2008,38(2):408-411.
[7]Cai Hua,Zhou Chunguang,Wang Zhe,et al.Algorithm research on community mining from dynamic social network[J].Journal of Jinlin University,2008,26(4):380-382.
[8]Berger-Wolf T Y,Saia J.A framework for analysis of dynamic social networks[C]//Proceeding of the 12th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining,2006,12:523-528.
[9]赫南,李德毅,淦文燕,等.复杂网络中重要性节点发掘综述[J].计算机科学,2007,34(12):1-4.
[10]郭军,李明辉,董社勤,等.随机行走的电路分析应用及并行化改进[J].计算机工程与应用,2010,46(18):199-201.
[11]邓忠军,宋威,郑雪峰,等.P2P网络中最大频繁项集挖掘算法研究[J].计算机应用研究,2010,27(9):3490-3492.
[12]宋文军,刘红星,王崇骏,等.以图频繁集为基础的核心节点发现[J].计算机科学与探索,2010,4(1):82-85.
[13]Sarkar P.Dynamic social network analysis using latent space models[C]//ProceedingsoftheACM SIGKDD Explorations Newsletter,2005:31-35.
[14]王建.基于KAD网络监督的关键技术研究与实现[D].成都:四川大学,2012.
[15]飞思科技产品研发中心.神经网络理论与MATLAB7实现[M]// MATLAB应用技术.北京:电子工业出版社,2005:4-90.
[16]边肇祺,张学工.模式识别[M].北京:清华大学出版社,2006:176-208.
1.College of Computer,Sichuan University,Chengdu 610041,China
2.Department of Computer Science and Software Engineering,Jincheng College of Sichuan University,Chengdu 611731,China
In view of the core node recognition in the KAD(Kademlia),a model based on BP is presented to determine whether a node is core node in real time.According to the result of the measurement for KAD,some attribute characteristics extraction and normalization processing is implemented to obtain an attribute set with higher separable degree.An algorithm in MatLab is designed to train the BP network until the results limit in a predetermined error range.In addition,the trained BP model is adapt to test prepared data,the results of the experiment show that the method can judge a node degrees of importance,and the recognition accuracy rate is up to about 70%.
Back-Prorogation(BP);KAD network;core node;recognition
A
TP393
10.3778/j.issn.1002-8331.1210-0276
WANG Jian,FENG Weisen,QIU Xingchao,et al.Study of recognition algorithm for core node in kad network based on BP model.Computer Engineering and Applications,2013,49(7):72-75.
王建(1979—),男,博士,讲师,研究领域为网络安全与应用;冯伟森(1962—),男,副教授,研究方向为网络信息系统。E-mail:wj_98@163.com
2012-10-26
2012-12-28
1002-8331(2013)07-0072-04
