解并行机模糊调度问题的自适应遗传算法
2013-08-07刘文程高家全
刘文程,高家全
解并行机模糊调度问题的自适应遗传算法
刘文程,高家全
针对家纺企业车间调度的实际情况,建立了一种产品优先级约束的模糊车间调度模型。在模型中,完工时间和交货期都是模糊的,交货期平均满意度最大为调度目标。基于此模型,提出了一种自适应的遗传算法,该算法通过比例选择及局部搜索保证种群的优良特性,并通过自动调节变异率和交叉率的方式保证种群的多样性,有效跳出局部收敛。仿真结果表明,自适应遗传算法能有效求解,并优于免疫遗传算法。
并行机;模糊加工时间;模糊交货期;模糊调度;遗传算法
1 引言
家纺企业作为传统的制造企业,在我国的制造业中具有举足轻重的地位。现有的一些研究成果主要集中在对家纺企业确定性车间生产调度问题上[1-2],但在家纺企业实际的生产过程中,不仅有确定性生产调度问题,还具有不确定性生产调度问题。不确定性的生产调度问题一方面是由家纺企业特殊的性能造成的,比如原料的不同特性,操作工人熟练度的差异,机器设备不同程度老化等,这都将影响产品的加工进度,并使得加工时间变得不确定;另一方面是由于同一批次的产品可能来自不同的订单,不同的订单的交货期一般而言是不一样的,这就将使得产品的交货期不同。
现阶段,在车间调度领域针对不确定的生产调度问题的研究,已有一些研究成果[3-12]。这些研究一般针对模糊车间调度问题,大部分是对模糊的加工时间或模糊的交货期这种单一情况下的作业车间的模糊调度问题进行研究。尽管也有部分学者对模糊加工时间和模糊交货期这种较为复杂的情况进行研究,但是他们对满意度函数的考虑存在一定的偏差,没有考虑到对于企业而言,不同客户的重要程度是不相同的,这样将使得调度结果不合理。从而使得家纺企业的生产调度问题无法应用已有的研究成果,需要专门针对其生产特点进行研究。
本文根据家纺企业在实际生产调度过程中所具有的特点,分别对加工时间和交货期进行模糊化处理,在此基础上建立模糊化的生产调度模型,并提出一种改进的自适应遗传算法。该算法能够通过调整变异率和交叉的方式保证种群的多样性,并能够有效跳出局部收敛;仿真结果证实了该算法的有效性和可靠性。
2 模糊生产调度模型
2.1 问题描述
家纺企业的模糊生产调度模型一般可以简单描述为:数量为n的产品在m台机器上分别进行加工,产品分别来自不相同的订单,订单来自不同的客户,因此具有不同的优先级。每个产品都具有模糊的加工时间及与客户满意度相关联的模糊交货期,产品的加工操作必须满足一定的工艺约束,即不是所有的产品都可以在任何机器上进行加工。每个产品在进行加工时,只能在一台机器上进行一次加工并完成产品的加工操作。产品的加工操作在机器上开始进行后,直到产品完成加工之前不能停止产品的加工,中途机器不能对其他产品进行加工,即机器同一时刻只能对一个产品进行加工操作。家纺企业调度的目标是寻找一种可行的方案,使得这种方案既能满足企业特定的工艺要求,又能使得调度目标获得最优解。
2.2 变量描述
为了方便叙述,引入下面的记号。
p˜ij:模糊加工时间。即为产品 j在机器i上的加工时间,其中包括对产品配件进行装配的时间、传输产品的时间、卸载产品时间、加工产品时间及对产品进行清洗的时间等,是在一定区间变化的模糊变量,用三角模糊数表示,为加工时间乐观值,为加工时间可能值,为加工时间悲观值。
Ωj:所有能加工产品 j的机器集合。
c˜j:产品 j的模糊完工时间。这是由产品的加工时间的模糊性决定的,模糊的加工时间必然导致模糊的完工时间。
AI:平均面积满意度。
t˜ij:产品 j在机器i上的开始加工时间。
λj:产品的优先级系数。
设决策变量:

2.3 数学模型

平均满意度最大模型:

图1 模糊的完工时间和交货期满意度
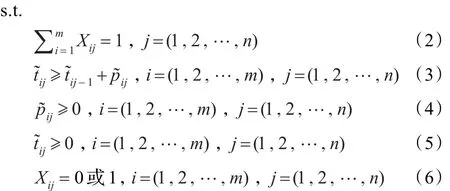
式(1)是问题的目标平均满意度最大;式(2)~(6)是满足目标函数的约束项,依次分别表示为:产品只能够在一台机器上进行加工;机器同一时刻只能加工一个产品,即只有在完成一个产品的加工后,才能开始下一产品的加工;产品在各机器上的加工时间均非负值;产品在各机器上的开始加工时间均非负值;决策变量的取值范围。
3 算法设计
根据家纺企业的实际情况,建立了不确定性生产调度模型,为了对该模型进行求解,设计了一种自适应性的遗传算法。算法基本流程如图2,具体步骤如下:
步骤1将初始种群的规模设定为NG,根据约束条件随机产生初始种群。
步骤2根据采用的适应度函数来计算每个染色体的适应度值。
步骤3运用比例选择机制以及最优保存策略对下一代种群的染色体进行选择。
步骤4让种群中的染色体两两进行交叉,交叉率根据种群的收敛情况进行调整,当种群快速收敛时,适当减小交叉率,当种群趋于发散时,适当增大交叉率,通过控制交叉率来实现对种群收敛速度的控制。
步骤5让种群中的染色体进行变异,变异率同样根据种群的收敛情况进行调整,当种群快速收敛时,适当提高变异率,当种群趋于发散时,适当减小变异率,通过控制变异率来保证种群的多样性和染色体的优良特性。
步骤6局部搜索算法对种群进行优化,使种群保持优良特性。
步骤7重复步骤2到步骤6,当满足设定的终止条件时停止。
3.1 编码设计及适应度函数
向量组编码方式解码简单且能方便地执行遗传操作,更具有不会产生无效个体的优点,因此本算法采用向量组的编码方式进行编码。
适应度函数是作为一种标准用来区分种群中染色体优劣的,一般通过变换原适应度间的比例关系来调节适应度值。对于2.3节中模型的目标函数,这里采用的适应度函数为:

由式(7)可知,分母是固定的值,因此分子越大,则适应度的值越大。

图2 自适应遗传算法流程图
3.2 选择算子
采用比例机制选择相应个体,通过轮盘赌选择方法对正比于个体适应度的概率进行计算。再经过多轮选择,选出需要进行交配的个体。每一轮选择时,首先均匀产生一个[0,1]的随机数,然后将该随机数作为选择指针,对比各个染色体的相对适应度来确定被选中的染色体。若种群的大小为N,染色体i的适应度值为 fi,那么染色体i被选择的概率Pf为:

本文算法不仅采用比例机制,同时将每代的最优染色体进行保存。通过用最优的染色体替换掉适应度值最低的染色体的方式,来提升种群的优良特性。
3.3 交叉算子
本文算法针对向量组编码方法,在部分匹配交叉的基础上提出了一种随机扩展交叉算子。具体过程如下:
(1)产生一个正整数n,在染色体长度的30%~50%之间进行随机选取。交叉的基因位数将由正整数n来决定,比如n的大小为3,那么染色体中将有三位基因进行交叉。
(2)随机产生数量为m的正整数作为需要交叉的基因点。
(3)假设需要将染色体A、B进行交叉,选取染色体A中的基因放入染色体B中的前面,并删除染色体B中相同的基因,从而产生基于染色体B的新染色体。同时,将染色体B中选取的基因放入染色体A中的前面,并删除染色体A中相同的基因,从而产生基于染色体A的新染色体。
下面通过举例说明染色体的交叉过程,假设需要交叉的染色体A、B分别为:

假设n=3,随机产生的基因位分别为4,8,2,那么经过交叉后获得的新染色体分别为:

将新染色体中相同的基因位分别进行删除后,便可获得分别基于染色体A、B的后代染色体:

3.4 变异算子
本文算法的变异方式通过多点插入的形式来实现,这一方式适合向量组编码的特性。下面对这一方式进行说明,先对要变异的基因位gi进行随机选择,再变换gi中第二行的机器号,在每次变换机器后对染色体的适应度值重新计算并做保留。当完成对所有可选机器的插入计算后,选择出最优的染色体作为变异产生的染色体。这种变异方式在保留父代信息的同时,保证了变异后的染色体的质量。
3.5 局部搜索算法
局部搜索算法一方面加快了种群搜索速度,另一方面提高了种群的质量,优化了算法性能。具体算法步骤如下所示。
对种群中的每一个染色体u进行如下操作:
(1)对u进行反转变异,将产生的染色体记为u*;
(2)评价u和u*;
(3)若u*优于u,则u=u*;
(4)若搜索次数达到设定的搜索次数,则停止搜索,否则重复(1)~(3)。
3.6 自适应技术
动态自适应技术通过调整遗传算法控制参数来控制种群的优化,即在种群的进化过程中根据种群收敛情况对Pc、Pm的数值进行适当调整。具体做法为:若种群趋于收敛,则在减小Pc的同时增大Pm,即通过将交叉的概率降低的同时将变异的概率提高来保证种群的多样性,以避免种群早熟;若种群发散,在在增大Pc的同时减小Pm,即通过将交叉的概率提高的同时将变异概率降低来加快算法的收敛速度。
在种群的进化过程中,σ为两代种群最优值的差值,通过让交叉概率Pc和变异概率Pm跟随σ的变换而变化来达到对种群优化过程的控制,使种群的Pc、Pm值能根据σ动态调整。数学描述如下:
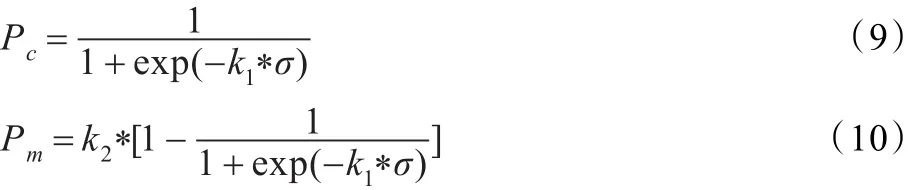
4 仿真及实验分析
在型号为华硕X81SG的计算机上,操作系统为Windows XP,在C++Builder软件环境下采用C++语言对全部算法进行编写。随机产生每种产品的机器集合、对应加工时间和交货期,使其满足均匀分布的要求。
4.1 对模糊完工时间仿真
通过对产品为15,加工机器为4的家纺企业生产调度问题进行仿真示例,来验证本文提出的AGA算法的可行性。表1为算例的具体模糊加工时间,表中纵排为产品号,横排为机器号,表格中的三个数字分别对应乐观值、最可能值和悲观值。
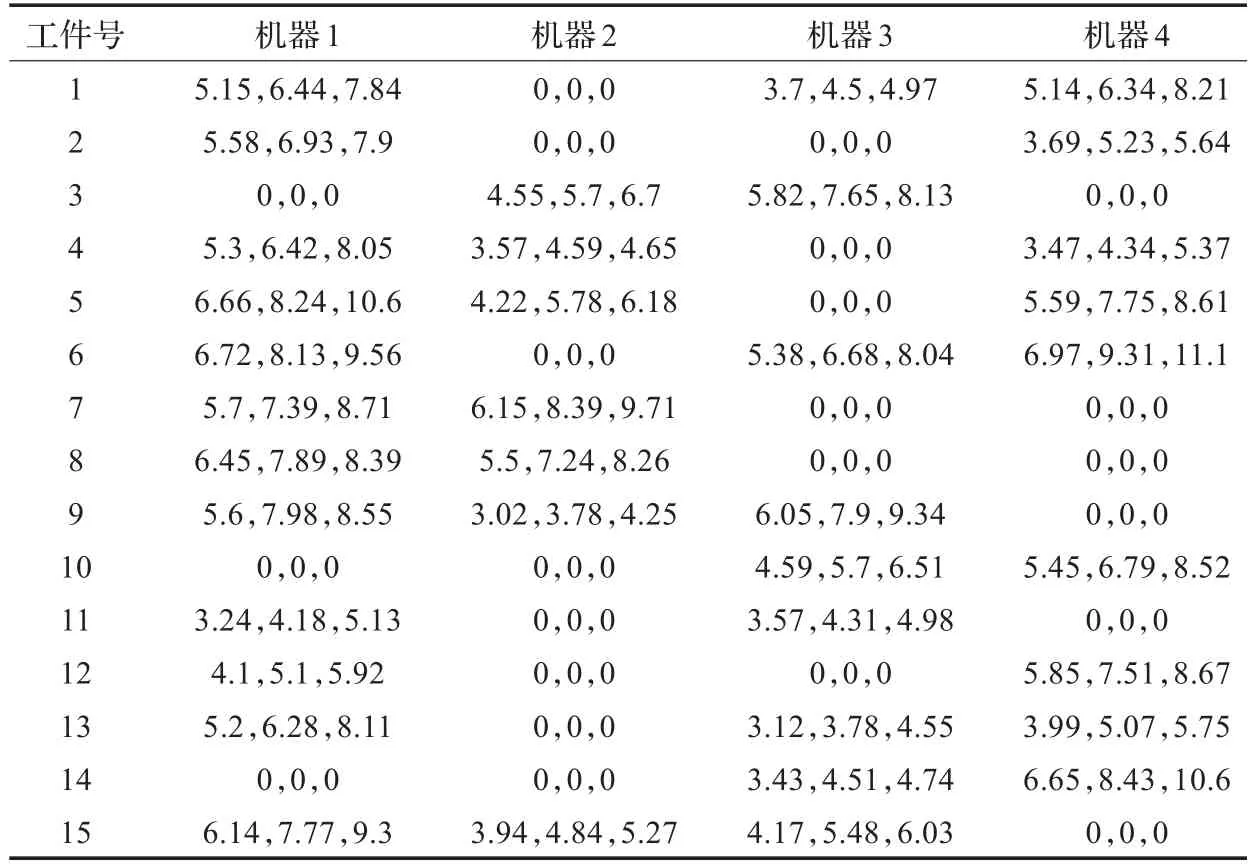
表1 15工件4机器模糊加工时间表
表2为产品模糊交货期和优先级表。设定在提前交货的情况下客户的满意度为1,即只要模糊完工时间能在模糊交货期之前,那么不会对客户的满意度造成影响。不同优先级的产品所具有的优先级系数是不相同的,这里设定优先级为1和优先级为2的产品的优先级系数分别为1和1.2。

表2 产品模糊交货期和优先级表
设置自适应遗传算法的参数,种群数量设为50,局部搜索交换次数设为20,参数k1设为300,k2设为0.1,交叉率和变异率的变化区间分别为0.5~1.0和0~0.05。
仿真可得最优染色体为:
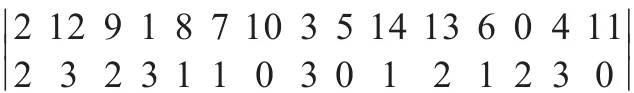
通过对最优染色体分析可得,高优先级客户产品的交货期能够获得高满意度,一般能够达到1;普通产品的交货期也能获得不低的满意度,保证在0.95以上。这证明AGA算法能有效求解问题模型。
4.2 对比实验
为验证本文提出的AGA算法的有效性,与文献[4]提出的克隆选择算法(CAS)和文献[7]提出的人工免疫算法(AIS)进行比较。以客户满意度最大为目标,分别对模糊数据规模为30×10,60×10,80×15和100×10的数据进行仿真,数据结果由算法进行10次运算,然后取其中的最优值并计算出平均值。

表3 算法比较结果
由表3可知,AGA算法的性能要优于CAS算法和AIS算法。针对不同规模的问题,在迭代次数相同的情况下,AGA算法的最优值要优于CAS算法和AIS算法,而且随着问题规模的增加,AIS算法和CAS算法取得的最优值跟全局最优值的差距变大,而AGA算法依然能取得全局最优值或接近全局最优值,说明算法能够跳出局部最优达到全局最优值,从而说明本文提出的AGA算法性能要优于AIS算法和CAS算法。
5 结束语
本文针对并行机模糊调度问题,根据客户满意度最大这一生产目标,建立了模糊生产调度模型,并构建了自适应遗传算法对其进行求解。该算法能够克服一般遗传算法趋于局部最优的缺点,提高了全局寻优能力。与AIS算法和CAS算法进行对比实验,仿真结果表明该算法具有更优的性能。
[1]高家全,赵端阳,何桂霞,等.解特殊工艺约束拖后调度问题的并行遗传算法[J].计算机工程应用,2007,43(27):184-186.
[2]刘文程.家纺企业生产调度模型及优化算法研究[D].杭州:浙江工业大学,2009.
[3]沈兵虎,柳毅.改进微粒群算法求解模糊交货期Flow-shop调度问题[J].计算机工程与应用,2006,42(34):36-38.
[4]Ong Z X,Tay J C,Kwoh K C.Applying the clonal selection principle to find flexible job-shop schedules[C]//Proceedings of the 4th International Conference on Artificial Immunes Systems,2005:442-455.
[5]Masatoshi S.Fuzzy programming for multiobjective job shop scheduling with fuzzy processing time and fuzzy duedate through genetic algorithms[J].European Journal of Operational Research,2000,120(2):393-407.
[6]雷德明,吴智铭.多目标模糊作业车间调度问题研究[J].计算机集成制造系统,2006,12(2):174-179.
[7]Agarwal R,Tiwari M K,Mukherjee S K.Artificial immune system based approach for solving resource constraint project scheduling problem[J].International Journal of Advanced Manufacturing Technology,2007,34:584-593.
[8]李富明,朱云龙.可变机器约束的模糊作业车间调度问题研究[J].计算机集成制造系统,2006,12(2):169-174.
[9]柳毅,叶春明.模糊交货期Flow-shop调度问题的改进微粒群算法[J].哈尔滨工业大学学报,2009,41(1):145-148.
[10]Tang J,Zhang G,Lin B,et al.A hybrid algorithm for flexible job-shop scheduling problem[J].Procedia Engineering,2011,15:3678-3683.
[11]Wang L,Tang D.An improved adaptive genetic algorithm based on hormonemodulation mechanism forjob-shop scheduling problem[J].ExpertSystemswith Applications,2011,38(6):7243-7250.
[12]Ren Q,Wang Y.A new hybrid genetic algorithm for job shop scheduling problems[J].Computer and Operations Research,2012,39(10):2291-2299.
LIU Wencheng,GAO Jiaquan
浙江工业大学 之江学院,杭州 310024
College of Zhijiang,Zhejiang University of Technology,Hangzhou 310024,China
According to the practical job shop scheduling problem subject to priority constraint of products with fuzzy processing time and due time in textile manufacturing industry,a scheduling model with maximization of average satisfaction is proposed. Furthermore,an Adaptive Genetic Algorithm(AGA)is presented to solve the scheduling models.In this algorithm,besides the proportional selection,the self-adapting mutation and cross are proposed to enhance the diversity of the population.Simulation results show that AGA is effective and is advantageous to the artificial immune algorithm.
parallel machines;fuzzy processing time;fuzzy due-date;fuzzy scheduling;Genetic Algorithm(GA)
A
TP301
10.3778/j.issn.1002-8331.1210-0090
LIU Wencheng,GAO Jiaquan.Self-adapting genetic algorithm for solving fuzzy scheduling problem on parallel machines. Computer Engineering and Applications,2013,49(7):60-63.
浙江省自然科学基金(No.LY12A01027)。
刘文程(1984—),男,硕士,研究领域为生产调度优化,算法优化;高家全(1972—),男,博士,副教授,研究领域为智能优化算法及其应用,高性能计算。E-mail:lwc198411@126.com
2012-10-10
2012-12-27
1002-8331(2013)07-0060-04
