基于本体的林业领域文档特征权重模型
2013-07-20张乃静鞠洪波
张乃静,鞠洪波,纪 平
中国林业科学研究院 资源信息研究所,北京 100091
基于本体的林业领域文档特征权重模型
张乃静,鞠洪波,纪 平
中国林业科学研究院 资源信息研究所,北京 100091
1 引言
现有林业领域信息检索方法多是以关键词匹配为基础的检索方式,随着林业相关研究的深入,林业领域信息总量在不断增加,传统的检索方法已经无法满足检索需求,例如用户检索“栎树”的相关信息,使用关键词匹配进行检索时无法检索到“栎树”的同义概念“柞树”和“橡树”。如何实现高效的林业领域信息检索成为一个亟待解决的问题。自Tim Berners-Lee[1]提出语义网以来,许多研究尝试将领域本体应用在信息检索上,来提高信息检索的查准率和查全率。文献[2]利用语义标注来改善检索系统的性能;文献[3]提出了一种基于领域本体的语义查询扩展模型,有效提高了农业信息的检索效率;文献[4]建立了基于关键词和基于概念的两层索引结构,使用基于本体的概念扩展和基于语义标注的概念扩展,提高了检索的查全率和查准率;文献[5]利用本体知识库推理实现了语义搜索;文献[6]利用本体改进了向量空间模型中排名算法;文献[7]利用本体中概念的语义距离来计算语义检索相关度。综上所述,多数研究利用领域本体中对象的语义关系和语义推理机制来改善信息检索,获得了一定的效果,但这些方法仍然存在着一些局限性,例如语义关系仅考虑了概念间的语义距离,而忽略了概念在本体中的结构因素,语义推理对本体要求较高,完善的本体是实现语义推理的基础,而构建这样的领域本体是一项巨大的知识工程,难以实现。本文利用本体中概念间的语义关系及结构因素计算概念间的语义相似度,结合特征性频率-倒排文档频率加权法(TF-IDF)[8],提出一种基于本体的林业领域文档特征权重模型,为进一步实现语义层次上的林业领域信息检索提供前提,同时也为林业领域数据挖掘提供了一条新途径。
2 林业领域文档特征权重
本文提出的文档特征权重模型主要包括3个部分:领域本体的构建、文档的预处理、文档特征权重的计算。模型结构如图1所示,主要实施步骤如下:(1)收集林业领域知识并构建林业领域本体;(2)对林业领域文档进行分析并去除停用词;(3)计算领域词汇在文档中的TF-IDF权重;(4)基于林业领域本体计算本体内各概念及实例之间的语义相似度;(5)结合TF-IDF和语义相似度计算基于本体的林业领域文档特征权重。
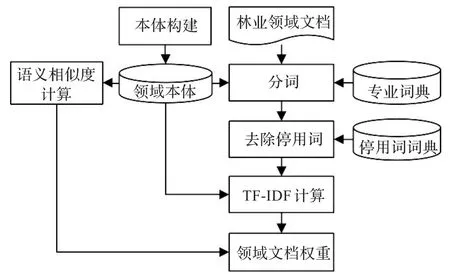
图1 基于本体的林业领域文档特征权重计算流程图
2.1 本体的构建
2.1.1 本体的定义
本体源于哲学上的一个概念,用于描述事物存在的本质。斯坦福大学知识系统实验室的Gruber最早给出了在信息科学领域被广泛接受的本体定义:“本体是概念模型的明确规范说明”[9]。Studer等人在对本体进行深入研究后,提出了一个本体概念界定:本体是共享概念模型明确的形式化规范说明[10]。本体之所以重要的一个原因是它对某个领域的概念的共识有利于知识的表达和传播。一般地,一个本体由概念、关系、函数、公理和实例5个基本的建模元语(Modeling Primitives)构成[11]。领域本体的构建方法如图2所示。
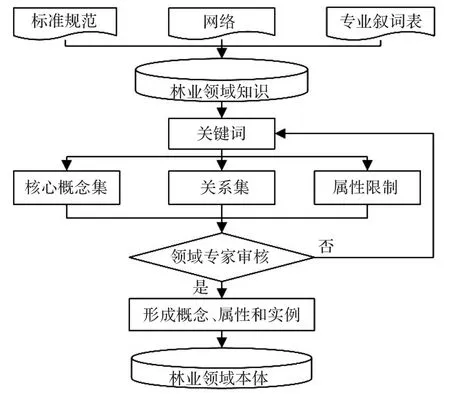
图2 领域本体的构建方法
2.1.2 本体的构建
本体的实质是利用领域概念术语和关系来构建领域模型,本体的构建是一个长期的不断改进补充的过程。本文中本体的构建步骤如下:(1)确定领域知识范围;(2)构建本体中涉及的核心概念集及核心概念关系;(3)构建属性及属性关系;(4)创建实例,使用protégé(http://protege. stanford.edu/)工具对其进行形式化编码,将构建的本体变成人和机器都可以理解的表达形式。基于林业领域标准规范、网络及专业叙词表建立林业领域本体。
图3显示的是关于森林类型的本体描述片段,“Thing”表示万事万物,是所有领域本体的根节点,概念之间的关系均为父子关系(IS-A关系),例如“云杉林”是一种(IS-A)“针叶林”。
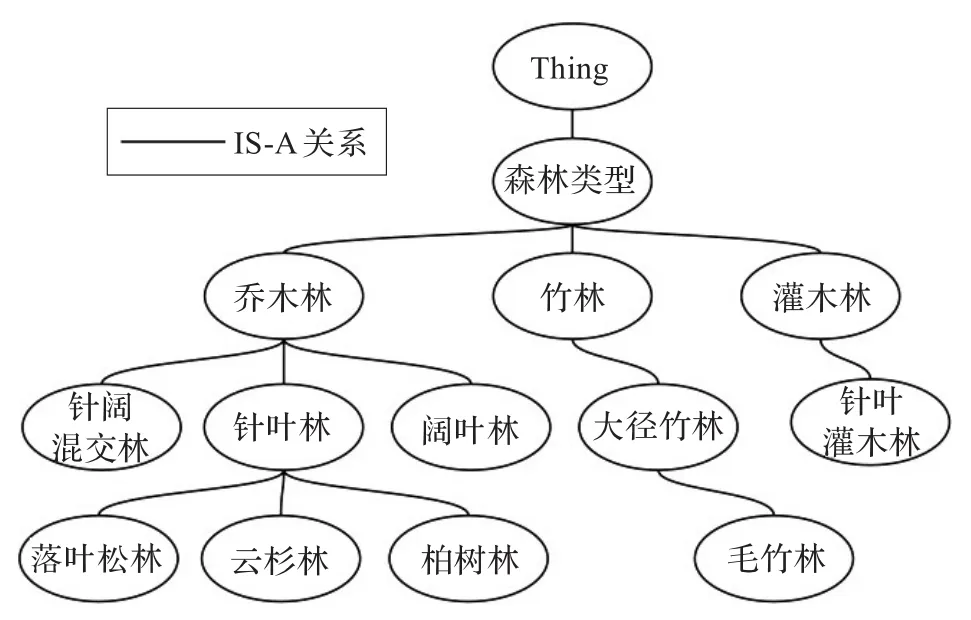
图3 林业领域本体描述片段
2.2 文档预处理
目前较为常用的分词工具是中科院开发的NLPIR汉语分词系统(ICTCLAS2013),该分词系统主要功能包括中文分词、词性标注、命名实体识别和用户词典功能,支持GBK编码、UTF-8编码、BIG-5编码。较多研究证明,该分词工具在国内同类型工具中具有较大的优势[12]。基于NLPIR汉语分词系统开发接口,开发了林业领域文档分词工具,实现了对林业领域文档的批量处理:使用常用词典和领域本体进行分词,在分词结果中自动标注了词性,结合停用词词典和词性过滤无意义词汇,最后生成文本文件备用。
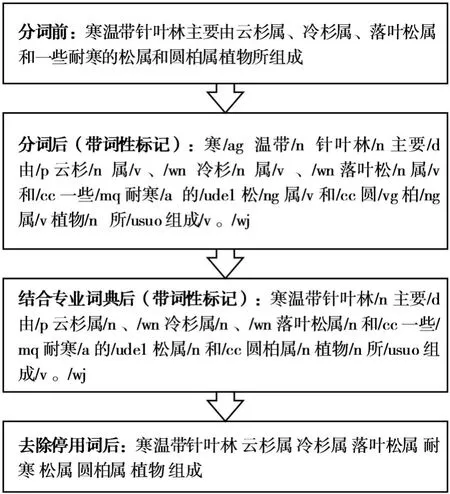
图4 文档预处理结果
文档预处理结果如图4所示,一些领域专有词汇如“寒温带针叶林”被切分为“寒”、“温带”和“针叶林”,失去了该词汇在文档中的原有意义,所以在分词过程中需要结合林业领域本体(或词典),识别出领域内的专有词汇,提高分词的精确度。
2.3 TF-IDF文档特征权重模型
TF-IDF文档特征权重模型是一种用于信息检索与文本挖掘的常用权重计算技术,常用于各类搜索引擎中,衡量文档与用户查询之间的相关程度。对于某一特定文档dj中的词汇ti来说,它的权重可记为:
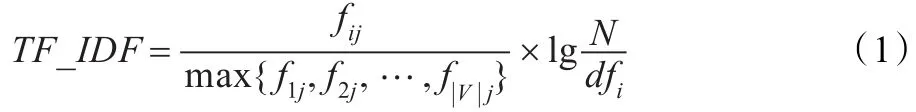
式中fij表示词汇ti在文档dj中出现的次数,max函数表示fij的最大值,如果ti在dj中没有出现,那么fij=0,TF-IDF= 0;|V|为文档数据集的词汇表的大小;N表示文档数据集中文档的总数;dfi为其中含有至少一次词汇ti的文档数目。TF-IDF模型可以降低语料库中出现频率较高词汇的权重,保留重要词汇的权重。
2.4 基于本体的语义相似度
领域本体可用树形结构来描述,其中树的节点表示本体中的概念;节点之间的边表示本体中概念之间的关系,本体树中任何两个节点都通过边(关系)相互连接,处于同一树枝的概念拥有共同的属性。概念表达范畴越广,在树中所处的层次越高;相反,概念表达越具体,在树中所处的层次越低。通过上述分析和前人研究经验的总结,基于领域本体的语义相似度需要考虑语义距离、语义重合度和层次差[13]。
定义1(语义距离)设X,Y是本体中的任意两个概念(或节点),X到Y最短的路径距离表示它们的语义距离,记为Dis(X,Y)。
语义距离是语义相似度计算中的一个基本要素,当两个概念路径距离较远时,语义距离较大,语义相似度较小。例如从图3中可以计算Dis(云杉林,柏树林)=2,Dis(云杉林,毛竹林)=6;也就是说“云杉林”与“柏树林”的语义相似度大(都是针叶林),而与“毛竹林”的语义相似度较小(不同的森林类型)。当两个概念的语义距离为0时,二者为同一概念,语义相似度为1。
定义2(语义重合度)设X,Y是本体中的任意两个概念(或节点),N(X)和N(Y)表示分别从X和Y出发,到达根节点R所经过的节点个数,语义重合度表示为:
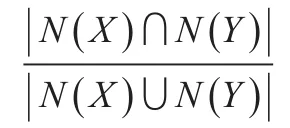
语义重合度表示了两个概念之间的相同程度。在实际计算中,通常使用两个概念到达根节点公共节点的个数与总节点个数的比值表达语义重合度。两个概念拥有的共同节点越多,说明两个概念的相同程度就越高,语义相似度越大。语义距离中的举例同样可以解释语义重合度,“云杉林”和“柏树林”的语义重合度为0.8,而“云杉林”和“毛竹林”的语义重合度为0.14,显然“云杉林”和“柏树林”的语义相似度较高。
定义3(层次差)设X,Y是本体中的任意两个概念(或节点),L(X)和L(Y)分别是概念X和Y所处的层次,层次差记为|L(X)-L(Y)|。
概念在本体树中所处的层次不同,承载的信息量不同,层次差越大,语义相似度就越小。例如图3中“云杉林”和“毛竹林”处于本体树的同一层次,层次差为0,而“云杉林”和“灌木林”的层次差为2,从人为理解上看,“云杉林”和“毛竹林”不仅都是一种“森林类型”,而且都是一个具体“森林类型”的实例;而“云杉林”和“灌木林”的共同属性仅为“森林类型”。所以前者的语义相似度应大于后者。
定义4(语义相似度)设X,Y是本体中的任意两个概念(或节点),二者的语义相似度计算公式如下:
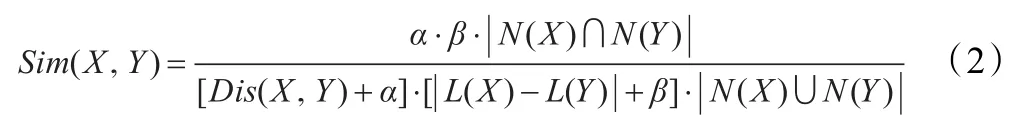
2.5 基于本体的文档特征权重模型
当单独使用TF-IDF模型计算文档特征权重时,仅考虑了关键词本身,其他与关键词相关的词汇便没有考虑。例如词汇“针叶林”在某文档中的TF-IDF值为0.3,但该文档中还包括“落叶松林”和“云杉林”等与针叶林密切相关的词汇,那么这些词汇应该增加“针叶林”在该文档中的权重。所以在计算某词汇的文档特征权重时,应结合文档中词汇之间的语义相关度。结合式(1)和式(2),本文改进的TF-IDF公式如下所示:
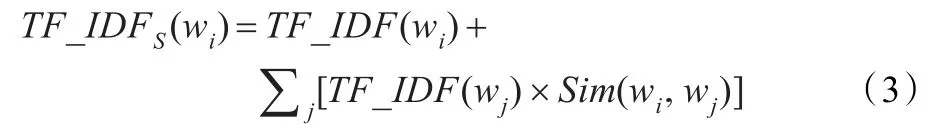
即在基于本体的文档特征权重计算时,将词汇wi与文档中其他相关词汇wj之间在本体中的语义相似度Sim(wi,wj)作为词汇wj对词汇wi的文档特征权重的贡献度。
3 实验分析
3.1 实验设计
实验运行环境:操作系统为Windows 7 Service Pack 1 x64,硬件平台为Intel I5 CPU 3.3 GHz,8 GB RAM,开发工具,Eclipse 4.2+JDK 1.7,本体构建工具为Protégé 4.1。
在林业科学数据中心网站(www.forestdata.cn)内提取相关网页数据,根据HTML语言格式,抽取网页标题和文本主体,将其转化为纯文本文件(txt),接下来依据上文所述文本预处理方法对所有文档进行预处理,为方便统计,最终共整理文本文件100个。根据式(3)计算关键词在每个文档中的特征权重(α=1;β=1)。
为验证基于本体的林业领域文档特征权重计算模型,使用林业领域文档特征权重模型与传统TF-IDF模型进行了检索对比实验。实验采用查准率(precisiοn)和查全率(recall)和F-Scοre作为评价文档特征权重模型的度量。查准率表示被检索到的文档中实际与查询相关的文档所占的百分比;查全率表示与查询相关的文档中实际被检索到的文档所占的百分比;F-Scοre是由查准率和查全率计算得到的评价指标,F-Scοre值越大,表示检索系统表现越好[14]。对某个测试参考集,信息查询实例为I,I对应的相关文档集合为R。假设用某个检索策略对I进行处理后,得到一个结果集合A。令Ra表示R与A的交集。查准率、查全率和F-Scοre的计算公式分别如下:

在实验文档中查询关键词后,配合领域专家,确认集合R的数量,根据特征权重确认集合A的数量,利用式(4)~式(6)计算平均查准率、查全率和F-Scοre,并绘制查准率-查全率曲线(PR曲线)。
3.2 结果与分析
实验结果(表1)表明,本文改进的林业领域文档特征权重模型查准率、查全率和F-Scοre分别为53.8%、100.0%和0.70,均优于传统的TF-IDF模型。
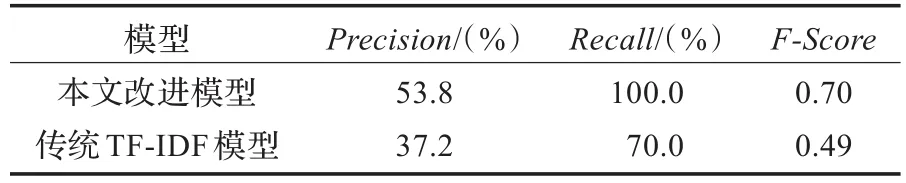
表1 实验结果
从PR曲线(图5)中也可以发现改进的林业领域文档特征权重模型较传统TF-IDF模型在查准率和查全率方面均有显著的提高。改进模型在保证较高查全率的同时依然可以获得较好的查准率,特别是查全率为60%~75%之间时,查准率可达90%以上。传统TF-IDF模型由于没有考虑语义相似度,在实验中无法实现100%的查全率,在查准率方面也表现不佳。
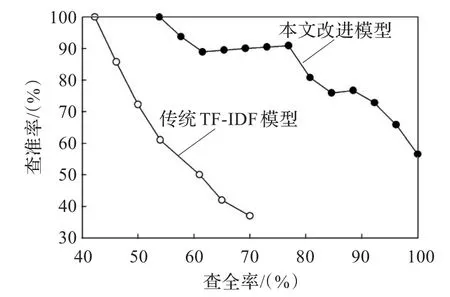
图5 PR曲线
4 结束语
本文提出了一种基于本体的林业领域文档特征权重计算模型。该模型在计算TF-IDF文档特征权重时,结合林业领域本体,增加关键词与文档中其他词汇的语义相关度贡献,提高了文本检索的查准率和查全率,使检索结果更加满足用户的需求。但该模型仍然有以下问题亟待解决。首先,领域本体是该模型的前提,但目前本体采用手工构建,由于本体的异构性,不同研究者构建相同领域本体的结构也不尽相同,所以使用该模型得到的结果也可能不同;其次,该模型基于TF-IDF进行改进,所以分词的质量对结果影响较大,如何改善分词质量是今后的研究方向之一;再次,本体内的所有概念和实例相互均有联系,即本体内的任何两个概念的语义相似度均不为0,领域内的关键词对应的所有领域文档的特征权重同样也不为0,所以在使用该模型计算文档特征权重以及生成倒排索引时需要设置文档特征权重阈值,以获得较高的查准率。因此该模型在使用过程中还需要进一步的改进。
[1]Berners-Lee T.Semantic Web-XML2000[EB/OL].[2013-01-12]. http://www.w3.org/2000/Talks/1206-xml2k-tbl/.
[2]Kiryakov A,Popov B,Terziev I,et al.Semantic annotation,indexing,and retrieval[J].Journal of Web Semantics,2004,2(1):49-79.
[3]陈叶旺,李海波,余金山.一种基于农业领域本体的语义检索模型[J].华侨大学学报:自然科学版,2012(1):27-32.
[4]赵建伟,郑诚,吴永俊.基于语义查询扩展的垂直搜索研究[J].计算机工程,2010(12):97-99.
[5]文坤梅.基于本体知识库推理的语义搜索研究[D].武汉:华中科技大学,2007.
[6]Castells P,Fernandez M,Vallet D.An adaptation of the vector-space model for ontology-based information retrieval[J]. IEEE Transactions on Knowledge and Data Engineering,2007,19(2):261-272.
[7]宋佳,王卷乐,诸云强,等.基于地理空间本体的语义检索相关度研究[J].计算机工程与应用,2011,47(5):114-117.
[8]TF-IDF-维基百科[EB/OL].(2013-03-01).http://zh.wikipedia. org/wiki/TF-IDF.
[9]Thomas R G.A translation approach to portable ontology specifications[J].Knowledge Acquisition,1993,5(2):199-220.
[10]Studer R,Benjamins V R,Fensel D.Knowledge engineering:principles and methods[J].Data&Knowledge Engineering,1998,25(1/2):161-197.
[11]Perez A G,Benjamins V R.Overview of knowledge sharing and reuse components:ontologies and problem-solving methods[C]//Proceedings of the IJCAI-99 Workshop on Ontologies and Problem-Solving Methods(KRR5),1999.
[12]刘群,张华平,俞鸿魁,等.基于层叠隐马模型的汉语词法分析[J].计算机研究与发展,2004,9(8):1421-1429.
[13]甘健侯,姜跃,夏侯明.本体方法及其应用[M].北京:科学出版社,2011.
[14]Liu Bing.Web数据挖掘[M].俞勇,薛贵荣,韩定一,译.北京:清华大学出版社,2009.
ZHANG Naijing,JU Hongbo,JI Ping
Research Institute of Forestry Information Techniques,Chinese Academy of Forestry,Beijing 100091,China
In the traditional feature weight of documents calculating,the model only considers the key word but other more relative words,so that the results of information retrieval are not comprehensive and precise.Aiming to solve these disadvantages above, this paper presents a model that calculates feature weight of document of forestry domain based on ontology.The steps of this model are as follows:calculate the feature weight using TF-IDF model;require the semantic distance,contact ratio and level difference between the key word and other relative words of document based on ontology,and then calculate the semantic similarity;calculate the feature weight using both results of TF-IDF and semantic similarity.The experiment proves that this improved model can increase the precision and recall ratio in documents retrieval,and meets the needs of users satisfactorily.
ontology;forestry domain;document feature;ranking model;semantic similarity
传统文档特征权重模型仅考虑关键词本身,文档内其他相关词汇并没有参与计算,信息检索时无法返回全面和准确的结果。为解决该问题提出了一种基于本体的林业领域文档特征权重模型。该模型计算TF-IDF特征权重;结合林业领域本体,分别获取关键词和林业领域内其他词汇的语义距离、语义重合度和概念的层次差,并计算语义相关度;结合TF-IDF和语义相似度的结果计算特征权重。实验证明该模型可以提高文本检索的查准率和查全率,使检索结果更加满足用户的需求。
本体;林业领域;文档特征;权重模型;语义相似度
A
TP391
10.3778/j.issn.1002-8331.1303-0173
ZHANG Naijing,JU Hongbo,JI Ping.Modeling feature weight of document of forestry domain based on ontology.Computer Engineering and Applications,2013,49(18):20-23.
国家科技基础条件平台建设项目(No.2005DKA32200)。
张乃静(1982—),女,博士研究生,CCF学生会员,研究领域为数据挖掘,信息系统与信息共享;鞠洪波(1956—),男,博士,研究员,研究领域为计算机应用,信息系统与信息共享;纪平(1964—),女,副研究员,研究领域为数据挖掘,信息系统与信息共享。E-mail:naijing.zhang@gmail.com
2013-03-12
2013-06-14
1002-8331(2013)18-0020-04
CNKI出版日期:2013-06-18 http://www.cnki.net/kcms/detail/11.2127.TP.20130618.1559.002.html
