基于频度的概念漂移检测算法
2013-07-05侯传宇李耀红武以敏
侯传宇,李耀红,赵 娟,武以敏
分类是有指导的学习[1-6],其目的是构造一个分类模型,来预测未知类别标签的样本所属的类别,分类是数据挖掘的一个重要部分。通过分类可发现训练数据中蕴含的概念,概念可以看作是一个分类规则或贝叶斯概率表,即从属性到类别的映射。
由于数据流快速、连续、多变的特性,其所蕴含的映射关系会或多或少发生变化,从而导致目标概念的变化即出现概念漂移。概念漂移主要有三种形式、突变式、渐进式以及取样变化[7-11]。
1 基于频度的概念漂移
1.1 数据流中概念的频度
数据流中所隐含的概念漂移,存在概念的重复出现也就是相似的映射关系的不断重现,其出现的次数可称为概念的频度,如:季节中天气的变化,阴天、多云、晴天等天气出现的次数可看作是频度,频度小于一定阈值的概念可视为低频概念,反之则为高频概念。对于天气情况:“阴天”、“晴天”可当作高频概念;“六月雪”、“太阳雨”等则可当作是低频概念。
1.2 适用于隐含概念漂移的数据流分类算法
很多学者[12-13]对隐含概念漂移的数据流分类算法进行了研究,如:CVFDT,WCE等。这些算法在处理数据流中的概念漂移问题时,大多采用不断更新分类模型,对原始概念与新概念之间的联系在未做研究。则在当前分类模型不适用而新的分类模型正在构造的时段,分类时间性能以及准确度也会降低。Yang Ying等人提出的RePro算法[14],根据数据流中概念漂移的特征,用已有的分类模型序列组织概念序列,把每一个分类模型视为马氏链的一种状态,分类模型的改变过程看作是马尔可夫链。通过概念序列构建体现概念转移的规律的概念转移矩阵,用于对新模型进行预测,并用已有分类模型对新训练的分类模型进行进行检测判断是否是已有概念的重现。当检测到概念漂移则根据概念转移矩阵迅速产生分类模型,这对于基于频度的概念漂移来说,分类的时间性能和分类精度得到了提高。
1.3 基于频度的概念漂移检测的必要性
对于分类算法,识别一个原有模型要比新建一个模型要省时。而基于频度的概念漂移的特点是部分已有概念的重现,可利用此特点对概念漂移进行检测,再利用概念变换的规律来提高分类的时间性能和分类的精度。RePro算法,在分类的过程中采用滑动窗口来检测触发器,每遇到概念漂移,都要检验训练的概念是否是已有概念的重现。该算法对于基于频度的概念漂移来说,较为适用。这样可以充分训练概念转移矩阵,更好的发现概念漂移的规律,用以预测将要出现的概念,能节省时间提高分类精度。而对于非基于频度的概念漂移是耗时的,且会导致概念转移矩阵的无限增长,当遇到触发器时只需对模型进行更新即可,无需对更新的模型进行相似度检验。因此,对概念漂移是否是基于频度的进行检测是十分必要的。
2 FCD算法
2.1 FCD算法的组成
基于频度的概念漂移的特点是已有概念的重现,可通过对其变换过程的研究发现概念变化的规律,从而能提高分类精度和时间性能。FCD算法由以下几部分组成:一是基本分类算法,决策树分类算法、K-最邻近分类算法、朴素贝叶斯分类算法等,用来构造基础分类器;二是触发器的检测算法,主要用来判定是否发生概念漂移;三是概念的等价度量算法,用来判定新出现的概念是否是已有概念的重现;四是概念频度检测模型。
2.2 基于频度的概念漂移的检测模型
FCD算法的前3个组成部分,许多学者提出了很好的算法,本文主要介绍概念频度的检测模型。
基于频度的概念漂移的主要特点是部分概念重复出现,概念频度识别模型由以下组成部分:构造历史概念序列,用于判断新出现的概念是否是已有概念的重现;同时训练概念转移矩阵,用于记录概念漂移的规律,概念重现则更新其对应于概念转移矩阵的行列的值,全新的概念则增加概念转移矩阵的行列并更新矩阵对应行列的值;基于频度的概念漂移的检测。采用滑动窗口的方法,设定概念序列的长度为Max,互异概念的总数为n,每个互异概念出现的次数为Xi,概念频度的阈值为ER。若Xi/n>ER,则可视为基于频度的概念漂移。基于频度的概念漂移的检测模型见图1。
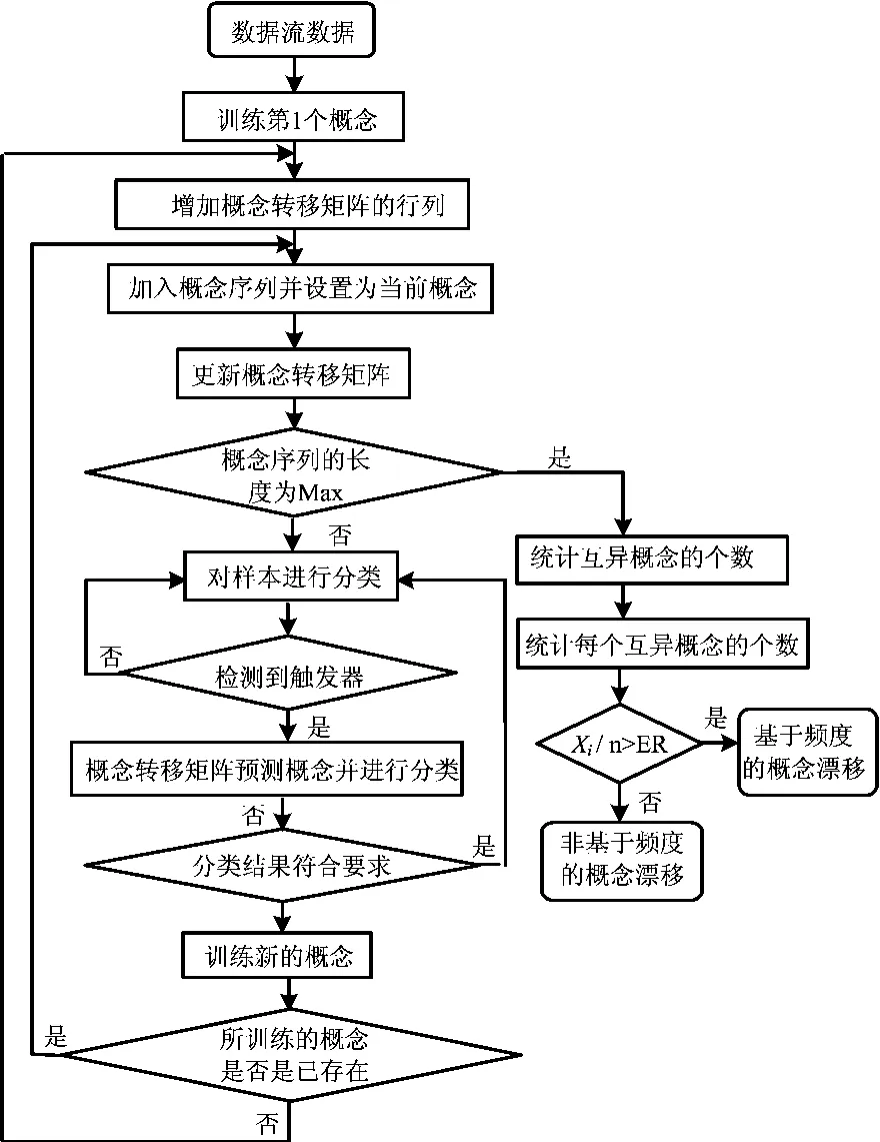
图1 基于频度的概念漂移的检测模型
3 实验结果
Stagger Concept方法广泛用于测试隐含概念漂移的数据流分类算法[15],采用 Stagger Concept方法产生实验测试数据。为了测试方便,设置每个样本的属性为5个,分别为:Fir,Sec,Thi,Fou,Fif,每个属性取值区间设定为{a,b,c}。类别标签分别为:0,1。可使用一定的规则产生对应的概念,如:Fir=a∧Sec=a∧Fou=c→classify=0,Fir=b∧Thi=b∧Fif=c→classify=1等。构造概念序列:T1,T2,T1,T2,T1,T2,T1,T2,T1 ,T2,T3,T1,T3,T1,T3,T1,T3,T1;设定频度阈值Er为:0.3,用户可接受的概念序列的最大长度 Max为:40,误差阈值Cr为:0.4。实验为检验模型处理概念漂移的能力,添加了噪音数据在测试数据中。
实验在PC机上运行,操作系统为 Windows XP,CPU为Pentiun(R)3.0GHz的,内存为2G。适当调整触发器窗口和学习窗口的大小,可得到序列如表1所示。

表1 概念识别模型所获取的序列
经比较,概念T1,T2,T3与表1中的概念Y1,Y2,Y9相对应,其出现的频率均大于Er,分别是:0.588,0.529,0.412。分类错误率小于误差阈值Cr为0.331。根据实验结果可确定此概念漂移为基于频度的概念漂移。
表1中出现的概念 Y3,Y4,Y5,Y6,Y7,Y9,Y10,Y11,Y12,Y13,Y14,Y15,Y16,Y17,不是预先生成的,可视为异常概念。部分异常概念是由于分类误差所产生的,部分是由于噪音数据造成的,而学习窗口的大小以及触发器窗口的大小对分类精度都有影响,目前分类的绝对准确没有好方法来确保。从表1也可看出这些异常概念出现的频率均为0.059,较低,对概念频度的检验不造成影响。
4 结束语
本文参考RePro算法,设计出检测基于概念频度的概念漂移的算法FCD,对基于频度的概念漂移,当检测到触发器时,可通过训练的概念转移矩阵对将要出现的概念进行预测,而对于非基于频度的概念漂移,当检测到触发器时,只需直接构造新的分类模型,这样可提高分类的时间性能。
[1] Littlestone N.Learning quickly when irrelevant attributes abound:a new linear-threshold algorithm[J].Machine Learning,1988(2):285-318.
[2] Fisher D H.Knowledge acquisition via incremental conceptual clustering[J].Machine Leaning,1987(2):139-172.
[3] J.Schlimmer and R.Granger.Beyond incremental processing:Tracking concept drift[C]//Proceedings of the 5th NationalConference on Artificial Intelligence,Philadelphia:Morgan Kaufmann,1986:502-507.
[4] Shafer J,Agrawal R,Metha M.SPRINT:A scalable parallel classifier for data mining[R].IBM Almaden Research Center,San Jose,California,1996.
[5] Mehta M,Agrawal R,Rissanen J.SLIQ:A fast scalable classifier for data mining[R].IBM Almaden Research Center,San Jose,California,1995.
[6] Yang Ying,Wu Xindong,Zhu Xingquan.Combining proactive and reactive predictions for data streams[J].In SIGKDD,2005,(8):710-715.
[7] Lanquillon C,Renz I.Adaptive information filtering:Detec-ting changes in text streams.[C]//Proc.of 8th ACM Intl'Conf.on Information and Knowledge Management,Kansas City:ACM Press,1999:538-544.
[8] Stanley K O.Learning concept drift with a committee of decision trees[R].Department of Computer Sciences,University of Texas at Austin,USA,2003.
[9] Tsymbal A.The problem of concept drift:definitionsand related work[R].Trinity College Dublin,Ireland:Computer Science Department,2004.
[10] Widmer G,Kubat M.Learning in the presence of concept drift and hidden contexts[J].Machine Learning,1996,23(1):69-101.
[11] Salganicoff M.Tolerating concept and sampling shift in lazy learning using prediction error context switching[J].Artificial Intelligence Review,1997,11(1):133-155.
[12] Domingos P,Hulten G.Mining high-speed data streams[C]//In Proceedings of the Association for Computing Machinery Sixth International Conference on Knowledge Discovery and Data Mining,Boston:ACM Press ,2000:71-80.
[13] Wang H,Fan W,Han J.Mining concept-drifting data streams using ensemble classifiers[C]//In Proc.of 9th SIGKDD,Washington DC,USA,2003:226-235.
[14] Yang,Y.,Wu,X.,and Zhu,X.Dealing with predictive-but-unpredictable attributes in noisy data sources[C]//In Proceedings of the 8th European Conference on Principles and Practice of Knowledge Discovery in Databases,Pisa,Italy,2004:471-483.
[15] Kolter J Z,Maloof M A.Dynamic weighted majority:a new ensemble method for tracking concept drift[C]//In Proceedings of the 3rd International IEEE Conference on Data Mining,Los Alamitos,USA:IEEE,2003:123-130.
