求解Hermite方程组的GPU并行算法
2013-01-06长江大学信息与数学学院湖北荆州434023水资源与水电科学国家重点实验室武汉大学湖北武汉430072廖文军中国石油集团东方地球物理勘探有限责任公司物探技术研究中心河北涿州072751
张 涛 (长江大学信息与数学学院,湖北 荆州434023水资源与水电科学国家重点实验室 (武汉大学),湖北 武汉430072)廖文军 (中国石油集团东方地球物理勘探有限责任公司物探技术研究中心,河北 涿州072751)
在工程计算中,经常需要对Hermite方程组进行求解,而且由于需要保证求解的精确性,一般都采用直接法进行求解,在问题规模较大的情况下,该方程组的求解时间开销很大。如果单纯在CPU上进行计算,计算效率往往满足不了实际生产的需要。随着GPU技术[1]的出现,利用GPU众核处理能力,采用CUDA计算[2-3]架构,利用GPU多核并行实现Hermite方程组的求解,将对解决其计算瓶颈提供契机。
1 Hermite方程组解法的GPU并行化分析
笔者所讨论的Hermite方程组解法是一种类似LU分解的直接法,本质上仍然是Gauss消去法,其主要的计算过程是消元操作。无论Gauss消去法还是LU分解法及其他消去类的直接法,以按列选主元为例,在每一次消元过程中,各列的消去操作是独立的,是可以并行进行的,而且在每一列内,各行元素的消去操作也是可以并行进行的。因此,可以采用GPU来加速Hermite方程组的求解。
2 Hermite方程组解法的GPU并行算法
2.1 算法设计
为了达到好的加速比,预测算子计算的GPU并行算法应遵循GPU的SIMD体系结构特点,并且充分发挥其众核计算能力,整个算法采用三级并行模型,其具体设计过程如下:
1)方程组集之间的并行 定义多个Hermite方程组为一个方程组集 (每个集包含相同个数的多个Hermite方程组),把一个方程组集的求解设计为一个GPU Kernel,由于Fermi架构的 GPU支持16个GPU Kernel同时并行处理,为充分利用GPU的流处理器 (SM),可以设计多个GPU Kernel使其并行处理多个方程组集的求解,假设一个GPU Kernel只利用了7个SM资源,一个Fermi GPU有14个SM,那么一块GPU可以并行求解2个Hermite方程组集,其并行对应关系如图1所示。
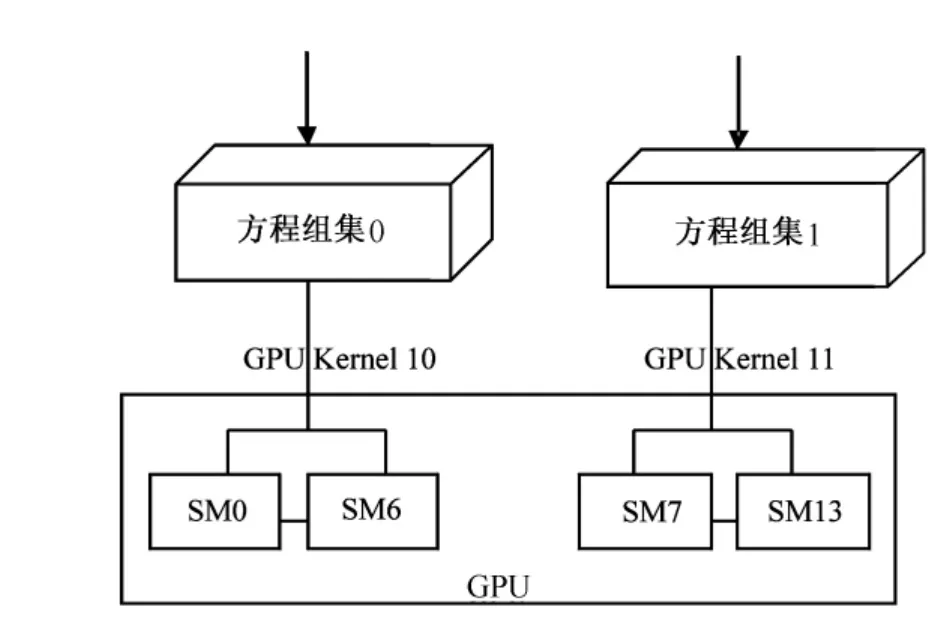
图1 Hermite方程组集的并行对应关系
2)每个方程组集内多个Hermite方程组并行 每个方程组集包括N个Hermite方程组,由于每个Hermite方程组的求解是独立的,彼此之间不存在数据依赖性,方程组之间可以并行求解。把每一个Hermite方程组的求解设计为一个GPU Block,即每一个GPU Block负责求解一个Hermite方程组,那么对于一个GPU Kernel而言,它有N个GPU Block,由于GPU Block运行于SM内,每个Hermite方程组的求解与GPU SM之间的对应关系如图2所示。
3)每个Hermite方程组内的并行 笔者所讨论的Hermite方程组的解法最耗时的地方为消元操作,可以利用GPU Thread并行进行消元操作。一个GPU Block包括多个Warp(32个GPU Thread),一个Warp负责一列的消元,多个Warp并行消去多列;一个Warp内一个Thread负责一列中一行的消元,32个Thread实现并行多行消元。每一个 Warp的32个Thread运行于SM内的GPU Core(一个SM包括32个GPU Core)内,系数矩阵的行列与GPU Core并行对应关系如图3所示。

图2 Hermite方程组的求解与GPU SM之间的对应关系
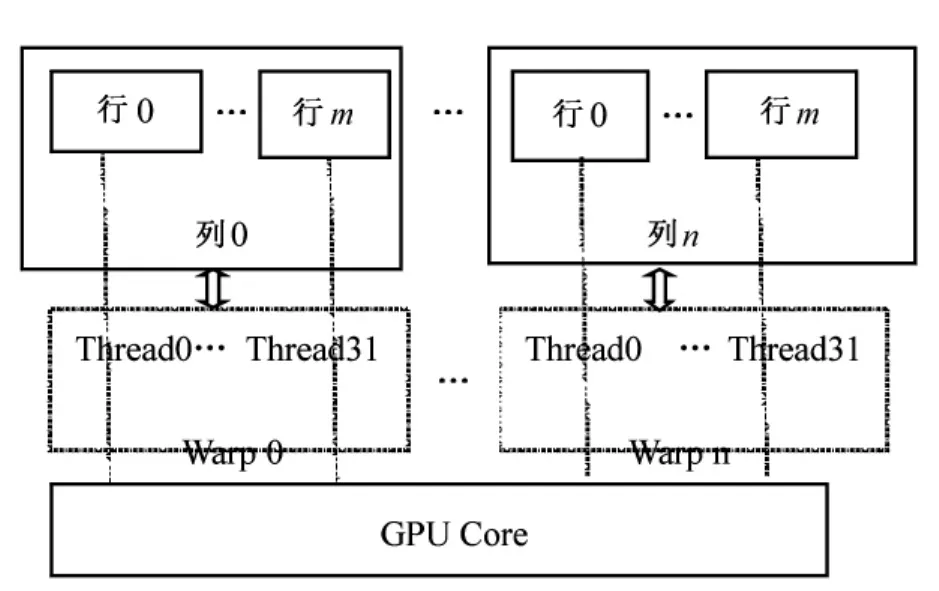
图3 系数矩阵的行列与GPU Core并行对应关系
2.2 CUDA线程模型设计
线程模型是用来明确CUDA程序内核的执行配置,根据GPU硬件资源,如寄存器个数、共享内存大小等,来定义网格和线程块,好的线程模型会使程序的并发度最优,实现计算与访存之间的相互隐藏,使程序性能达到最优。
1)网格 (Grid) 即如何对所有线程进行分块,定义线程块数和线程块间的组织方式。笔者把一个空间窗的一个频率当成一个线程块,定义为dimGrid(N),其中N为一个方程组集的Hermite方程组个数。
2)线程块 (Block) 即定义一个线程块有多少个线程和线程的组织方式。由于实际生产中,多个应用的Hermite系数矩阵的阶是不同的,因而GPU Kernel所需要的寄存器数、共享内存数量也不同。针对不同的阶,为使性能最优,每一个线程块的线程数是变化的,其具体定义为dimBlock(M,W),一个线程块的总线程数为M*W,其中W随系数矩阵的阶的不同而不同。
3)线程模型 每个Grid划分为N个Block,即计算一个方程组集内的N个Hermite方程组;每个Block求解一个Hermite方程组,它划分为W个Warp。假设Hermite系数矩阵为二维矩阵H[n,m],每一个Warp负责一列的消元,W个Warp一次并行消去W列,每一个Warp需要循环m/W次。一个Warp内每一个GPU Thread负责一列中一行的消元,M个GPU Thread一次并行消去M行,则每一个Thread需要循环n/M次。
2.3 CUDA内存使用设计
根据GPU并行算法、数据访问特点及GPU内存资源特性,选择不同的内存存放不同的数据,以达到性能最优。
1)Global memory使用 Fermi GPU是按照Warp方式来访存的,为了实现对Global Memory合并访问,使其访存性能达到最优,一个Warp内的32个Thread应同时访问Global memory内的连续内存。由于系数矩阵H是按照列优先方式存放的,每一列内元素数据是连续存放的,所以在消元操作时32个线程应同时访问同一列内的32行数据元素,提高访存性能。
2)Shared memory使用 由于Shared memory为GPU的片上内存,访问速度快,对于一个Block块中公共的数据,如消元操作时的公共列元素,可以放入共享内存中,将提高访存性能。
3)L1Cache使用 Fermi GPU提供L1Cache,其为GPU的片上内存,由于资源受限,L1Cache与Shared memory大小之和仅为64K,可以把L1Cache动态配置为16K或48K2种方式,这样可以进一步提高访存性能。
3 性能测试
测试环境包括硬件环境 (CPU:Intel® CoreI i7CPU 920@2.67GHZ;内存:2.67GHZ,8GB;GPU:Tesla C2050)和软件环境 (OS:64位Linux RedHat 4.5)。选取某实际工业生产中产生的 Hermite方程组,每个方程组集包含1000个Hermite方程组,每个Hermite系数矩阵的阶分别为350、700、1700,对这3种Hermite方程组的求解分别运行单线程串行程序和GPU并行程序进行性能比较测试。为了保证测试性能结果的稳定性,每次测试10个方程组集,然后取其平均时间,并且每个测试重复进行3次,测得CPU单线程串行程序平均每个方程组集计算时间 (CPU_Aver_Time)和GPU并行程序平均每个方程组集计算时间 (GPU_Ave_Time),性能对比如表1所示。从表1不难看出:①GPU并行程序的性能较CPU单线程串行程序提升明显,加速比达到18.55~26.35倍;②由于Hermite方程组的求解计算量随着系数矩阵的阶数增大而增加,笔者设计的GPU并行算法性能加速比越来越高,表明系数矩阵阶越高,Hermite方程组的求解计算越密集,采用GPU并行算法效果将更好。

表1 2种算法性能结果比对表
4 结 语
针对Hermite系数矩阵方程组求解计算效率低的问题,笔者首先对一种Hermite方程组直接解法进行GPU并行可行性分析,再基于GPU利用CUDA技术对该解法进行并行化设计。经测试其性能较原串行算法提升18.55~26.35倍,很好地解决了该直接解法的计算瓶颈。
[1]张浩,李利军,林岚.GPU的通用计算应用研究 [J].计算机与数字工程,2005,33(12):60-62.
[2]郭境峰,蔡伟涛 .新一代高性能运算技术——CUDA简介 [J].现代科技,2009,8(6):29-30.
[3]吴连贵,易瑜,李肯立 .基于CUDA的地震数据相干体并行算法 [J].计算应用,2009(3):294-296.
